 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Beyond Backpropagation: a Photonic Co-Processor for Direct Feedback Alignment
Dec 11, 2020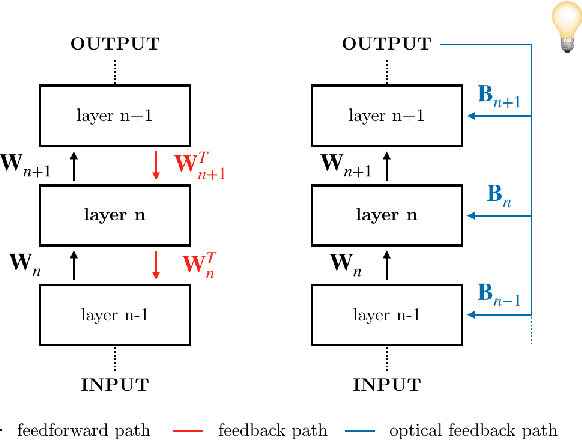


The scaling hypothesis motivates the expansion of models past trillions of parameters as a path towards better performance. Recent significant developments, such as GPT-3, have been driven by this conjecture. However, as models scale-up, training them efficiently with backpropagation becomes difficult. Because model, pipeline, and data parallelism distribute parameters and gradients over compute nodes, communication is challenging to orchestrate: this is a bottleneck to further scaling. In this work, we argue that alternative training methods can mitigate these issues, and can inform the design of extreme-scale training hardware. Indeed, using a synaptically asymmetric method with a parallelizable backward pass, such as Direct Feedback Alignement, communication needs are drastically reduced. We present a photonic accelerator for Direct Feedback Alignment, able to compute random projections with trillions of parameters. We demonstrate our system on benchmark tasks, using both fully-connected and graph convolutional networks. Our hardware is the first architecture-agnostic photonic co-processor for training neural networks. This is a significant step towards building scalable hardware, able to go beyond backpropagation, and opening new avenues for deep learning.
Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures
Jun 23, 2020



Despite being the workhorse of deep learning, the backpropagation algorithm is no panacea. It enforces sequential layer updates, thus preventing efficient parallelization of the training process. Furthermore, its biological plausibility is being challenged. Alternative schemes have been devised; yet, under the constraint of synaptic asymmetry, none have scaled to modern deep learning tasks and architectures. Here, we challenge this perspective, and study the applicability of Direct Feedback Alignment to neural view synthesis, recommender systems, geometric learning, and natural language processing. In contrast with previous studies limited to computer vision tasks, our findings show that it successfully trains a large range of state-of-the-art deep learning architectures, with performance close to fine-tuned backpropagation. At variance with common beliefs, our work supports that challenging tasks can be tackled in the absence of weight transport.
Light-in-the-loop: using a photonics co-processor for scalable training of neural networks
Jun 03, 2020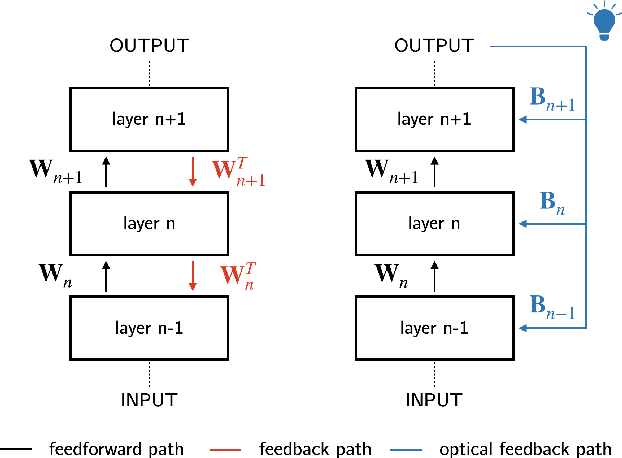
As neural networks grow larger and more complex and data-hungry, training costs are skyrocketing. Especially when lifelong learning is necessary, such as in recommender systems or self-driving cars, this might soon become unsustainable. In this study, we present the first optical co-processor able to accelerate the training phase of digitally-implemented neural networks. We rely on direct feedback alignment as an alternative to backpropagation, and perform the error projection step optically. Leveraging the optical random projections delivered by our co-processor, we demonstrate its use to train a neural network for handwritten digits recognition.
Principled Training of Neural Networks with Direct Feedback Alignment
Jun 11, 2019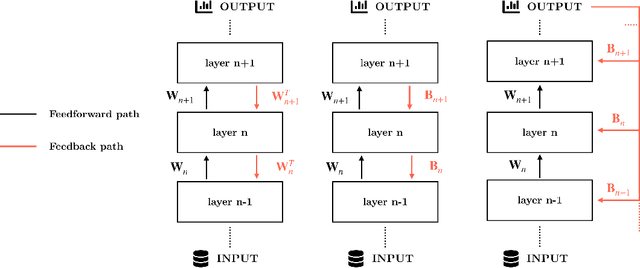
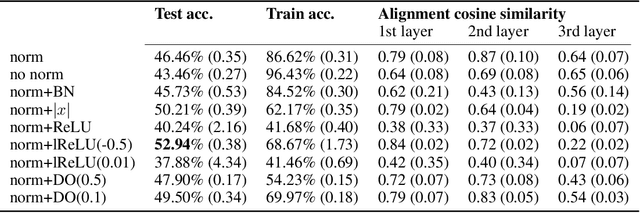
The backpropagation algorithm has long been the canonical training method for neural networks. Modern paradigms are implicitly optimized for it, and numerous guidelines exist to ensure its proper use. Recently, synthetic gradients methods -where the error gradient is only roughly approximated - have garnered interest. These methods not only better portray how biological brains are learning, but also open new computational possibilities, such as updating layers asynchronously. Even so, they have failed to scale past simple tasks like MNIST or CIFAR-10. This is in part due to a lack of standards, leading to ill-suited models and practices forbidding such methods from performing to the best of their abilities. In this work, we focus on direct feedback alignment and present a set of best practices justified by observations of the alignment angles. We characterize a bottleneck effect that prevents alignment in narrow layers, and hypothesize it may explain why feedback alignment methods have yet to scale to large convolutional networks.