 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Forward and Backward Learning of Evolving Tasks with Performance Guarantees
Oct 24, 2023



For a sequence of classification tasks that arrive over time, it is common that tasks are evolving in the sense that consecutive tasks often have a higher similarity. The incremental learning of a growing sequence of tasks holds promise to enable accurate classification even with few samples per task by leveraging information from all the tasks in the sequence (forward and backward learning). However, existing techniques developed for continual learning and concept drift adaptation are either designed for tasks with time-independent similarities or only aim to learn the last task in the sequence. This paper presents incremental minimax risk classifiers (IMRCs) that effectively exploit forward and backward learning and account for evolving tasks. In addition, we analytically characterize the performance improvement provided by forward and backward learning in terms of the tasks' expected quadratic change and the number of tasks. The experimental evaluation shows that IMRCs can result in a significant performance improvement, especially for reduced sample sizes.
Uncertainty in Fairness Assessment: Maintaining Stable Conclusions Despite Fluctuations
Feb 02, 2023



Several recent works encourage the use of a Bayesian framework when assessing performance and fairness metrics of a classification algorithm in a supervised setting. We propose the Uncertainty Matters (UM) framework that generalizes a Beta-Binomial approach to derive the posterior distribution of any criteria combination, allowing stable performance assessment in a bias-aware setting.We suggest modeling the confusion matrix of each demographic group using a Multinomial distribution updated through a Bayesian procedure. We extend UM to be applicable under the popular K-fold cross-validation procedure. Experiments highlight the benefits of UM over classical evaluation frameworks regarding informativeness and stability.
A Survey on Preserving Fairness Guarantees in Changing Environments
Nov 14, 2022



Human lives are increasingly being affected by the outcomes of automated decision-making systems and it is essential for the latter to be, not only accurate, but also fair. The literature of algorithmic fairness has grown considerably over the last decade, where most of the approaches are evaluated under the strong assumption that the train and test samples are independently and identically drawn from the same underlying distribution. However, in practice, dissimilarity between the training and deployment environments exists, which compromises the performance of the decision-making algorithm as well as its fairness guarantees in the deployment data. There is an emergent research line that studies how to preserve fairness guarantees when the data generating processes differ between the source (train) and target (test) domains, which is growing remarkably. With this survey, we aim to provide a wide and unifying overview on the topic. For such purpose, we propose a taxonomy of the existing approaches for fair classification under distribution shift, highlight benchmarking alternatives, point out the relation with other similar research fields and eventually, identify future venues of research.
Minimax Classification under Concept Drift with Multidimensional Adaptation and Performance Guarantees
May 31, 2022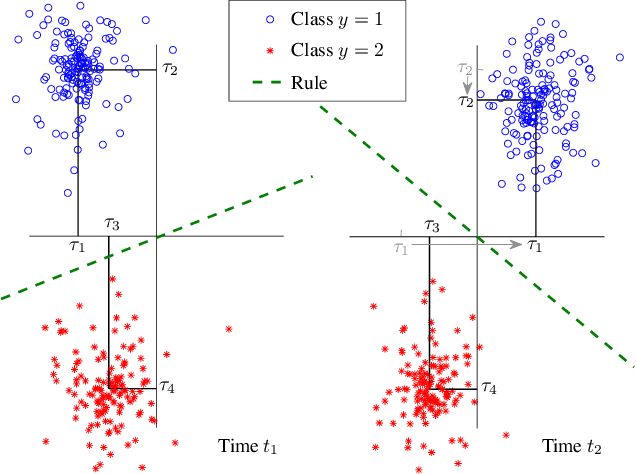
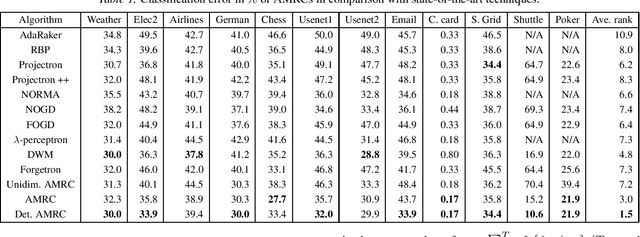
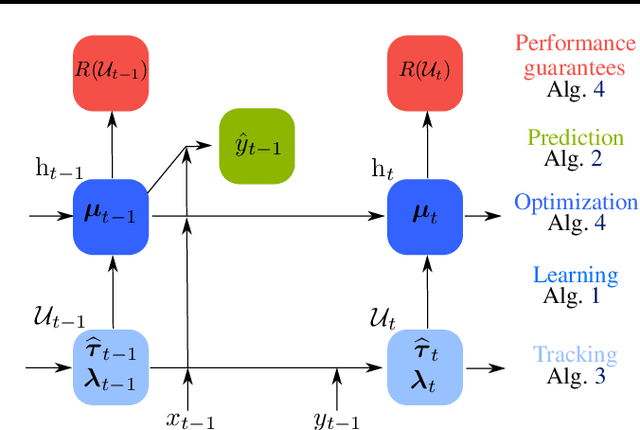
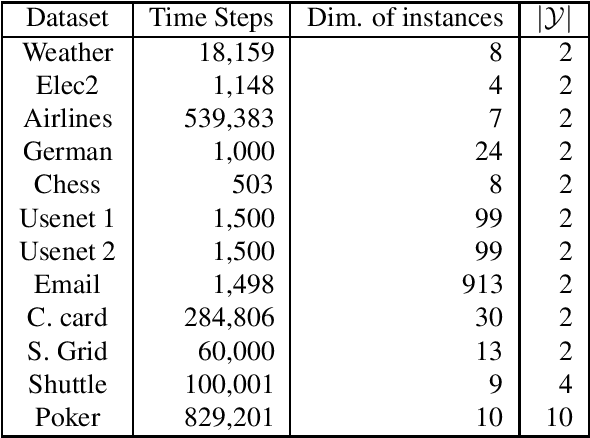
The statistical characteristics of instance-label pairs often change with time in practical scenarios of supervised classification. Conventional learning techniques adapt to such concept drift accounting for a scalar rate of change by means of a carefully chosen learning rate, forgetting factor, or window size. However, the time changes in common scenarios are multidimensional, i.e., different statistical characteristics often change in a different manner. This paper presents adaptive minimax risk classifiers (AMRCs) that account for multidimensional time changes by means of a multivariate and high-order tracking of the time-varying underlying distribution. In addition, differently from conventional techniques, AMRCs can provide computable tight performance guarantees. Experiments on multiple benchmark datasets show the classification improvement of AMRCs compared to the state-of-the-art and the reliability of the presented performance guarantees.
When and How to Fool Explainable Models with Adversarial Examples
Jul 05, 2021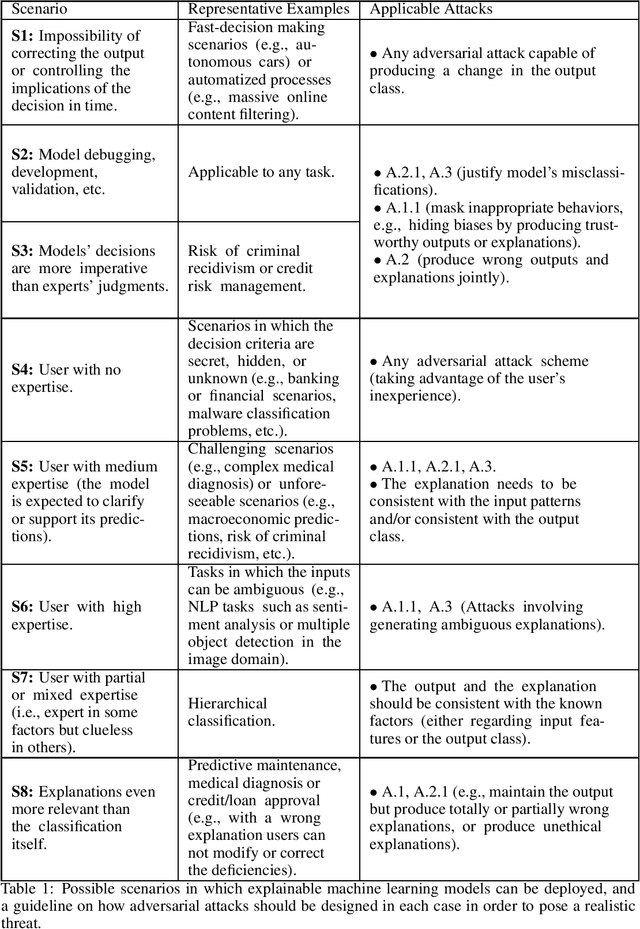
Reliable deployment of machine learning models such as neural networks continues to be challenging due to several limitations. Some of the main shortcomings are the lack of interpretability and the lack of robustness against adversarial examples or out-of-distribution inputs. In this paper, we explore the possibilities and limits of adversarial attacks for explainable machine learning models. First, we extend the notion of adversarial examples to fit in explainable machine learning scenarios, in which the inputs, the output classifications and the explanations of the model's decisions are assessed by humans. Next, we propose a comprehensive framework to study whether (and how) adversarial examples can be generated for explainable models under human assessment, introducing novel attack paradigms. In particular, our framework considers a wide range of relevant (yet often ignored) factors such as the type of problem, the user expertise or the objective of the explanations in order to identify the attack strategies that should be adopted in each scenario to successfully deceive the model (and the human). These contributions intend to serve as a basis for a more rigorous and realistic study of adversarial examples in the field of explainable machine learning.
Analysis of Dominant Classes in Universal Adversarial Perturbations
Jan 11, 2021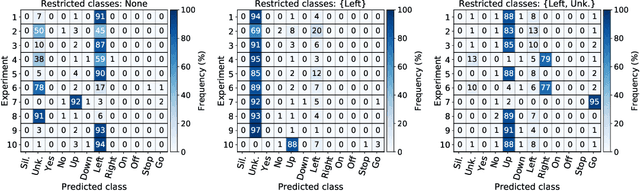
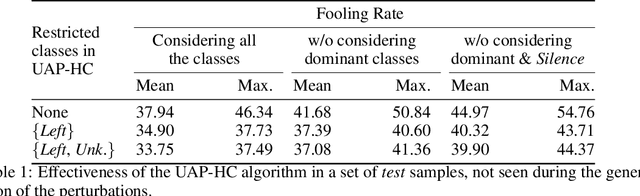
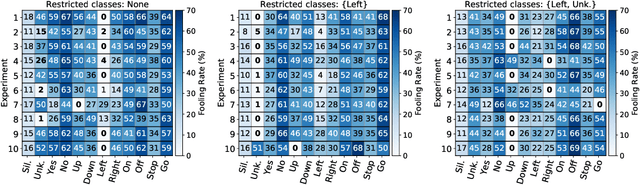
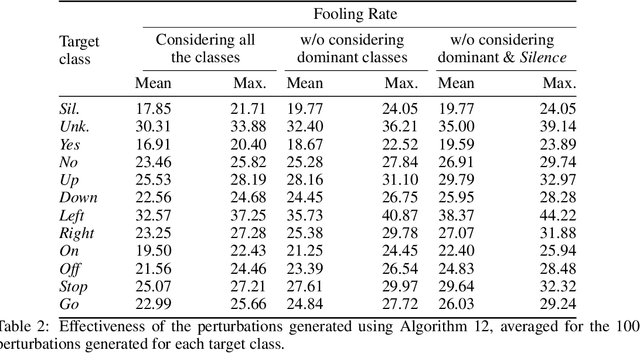
The reasons why Deep Neural Networks are susceptible to being fooled by adversarial examples remains an open discussion. Indeed, many different strategies can be employed to efficiently generate adversarial attacks, some of them relying on different theoretical justifications. Among these strategies, universal (input-agnostic) perturbations are of particular interest, due to their capability to fool a network independently of the input in which the perturbation is applied. In this work, we investigate an intriguing phenomenon of universal perturbations, which has been reported previously in the literature, yet without a proven justification: universal perturbations change the predicted classes for most inputs into one particular (dominant) class, even if this behavior is not specified during the creation of the perturbation. In order to justify the cause of this phenomenon, we propose a number of hypotheses and experimentally test them using a speech command classification problem in the audio domain as a testbed. Our analyses reveal interesting properties of universal perturbations, suggest new methods to generate such attacks and provide an explanation of dominant classes, under both a geometric and a data-feature perspective.
Extending Adversarial Attacks to Produce Adversarial Class Probability Distributions
Apr 14, 2020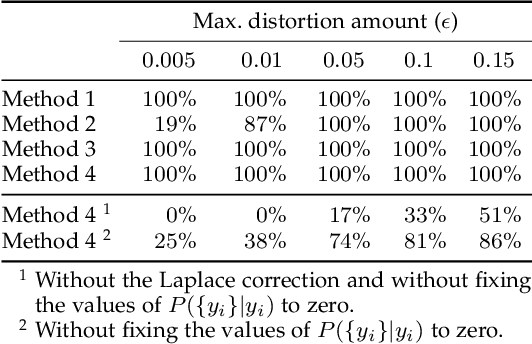
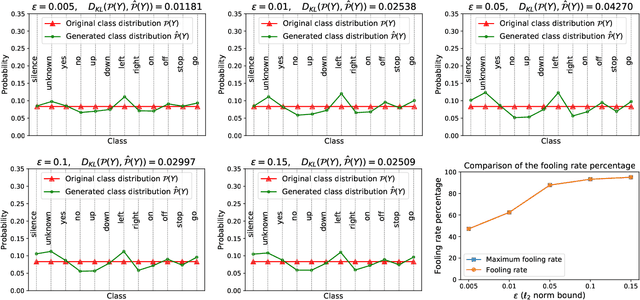
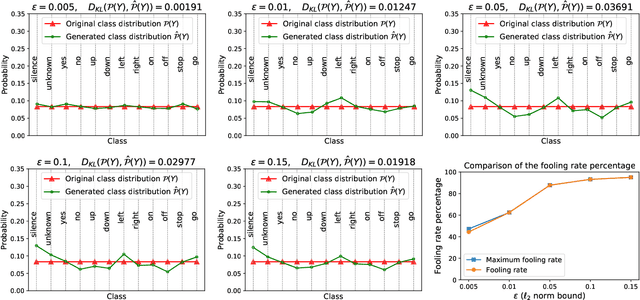
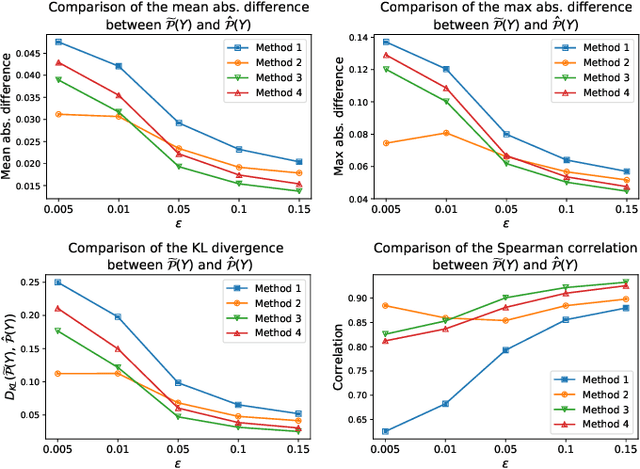
Despite the remarkable performance and generalization levels of deep learning models in a wide range of artificial intelligence tasks, it has been demonstrated that these models can be easily fooled by the addition of imperceptible but malicious perturbations to natural inputs. These altered inputs are known in the literature as adversarial examples. In this paper we propose a novel probabilistic framework to generalize and extend adversarial attacks in order to produce a desired probability distribution for the classes when we apply the attack method to a large number of inputs. This novel attack strategy provides the attacker with greater control over the target model, and increases the complexity of detecting that the model is being attacked. We introduce three different strategies to efficiently generate such attacks, and illustrate our approach extending DeepFool, a state-of-the-art attack algorithm to generate adversarial examples. We also experimentally validate our approach for the spoken command classification task, an exemplary machine learning problem in the audio domain. Our results demonstrate that we can closely approximate any probability distribution for the classes while maintaining a high fooling rate and by injecting imperceptible perturbations to the inputs.
A review on outlier/anomaly detection in time series data
Feb 11, 2020

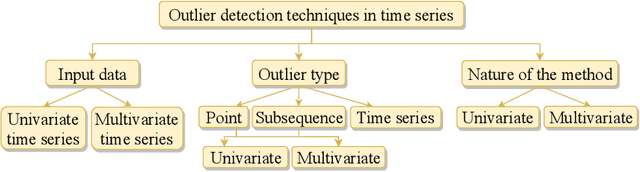
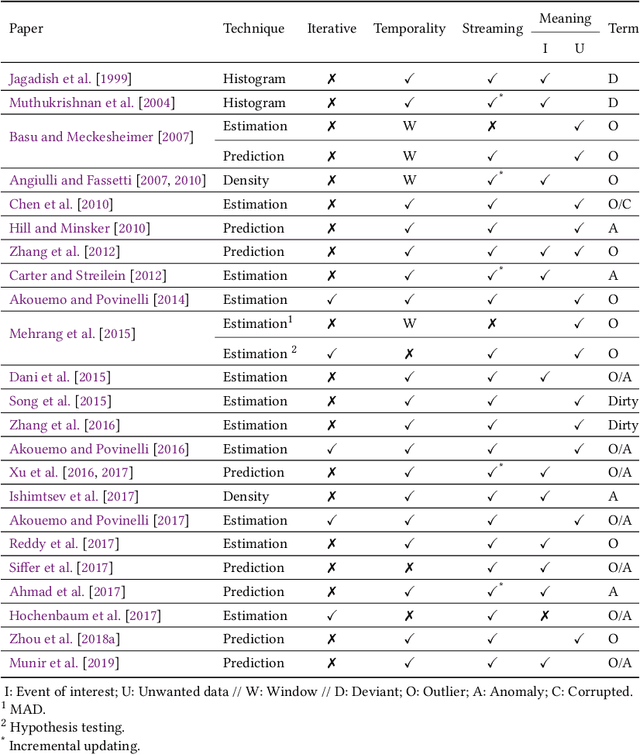
Recent advances in technology have brought major breakthroughs in data collection, enabling a large amount of data to be gathered over time and thus generating time series. Mining this data has become an important task for researchers and practitioners in the past few years, including the detection of outliers or anomalies that may represent errors or events of interest. This review aims to provide a structured and comprehensive state-of-the-art on outlier detection techniques in the context of time series. To this end, a taxonomy is presented based on the main aspects that characterize an outlier detection technique.
Evolving Gaussian Process kernels from elementary mathematical expressions
Oct 14, 2019
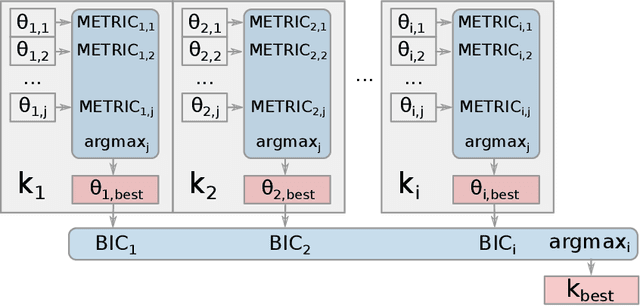
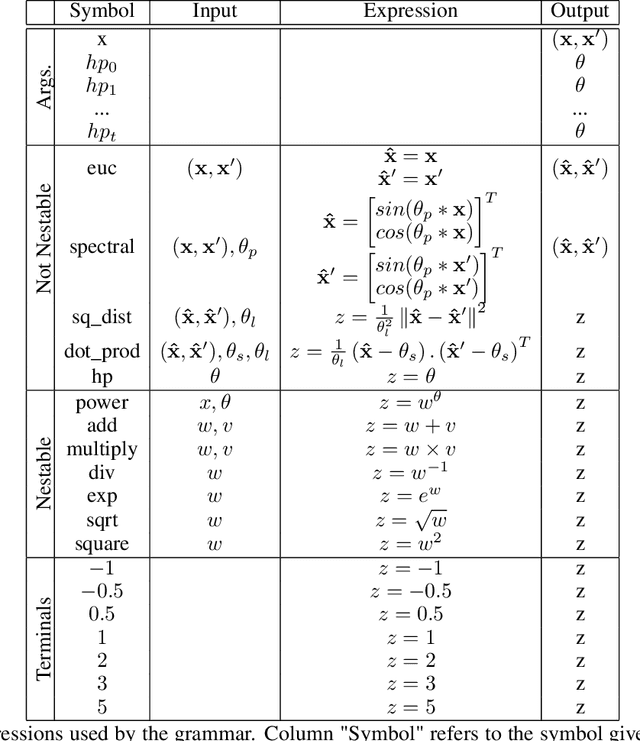
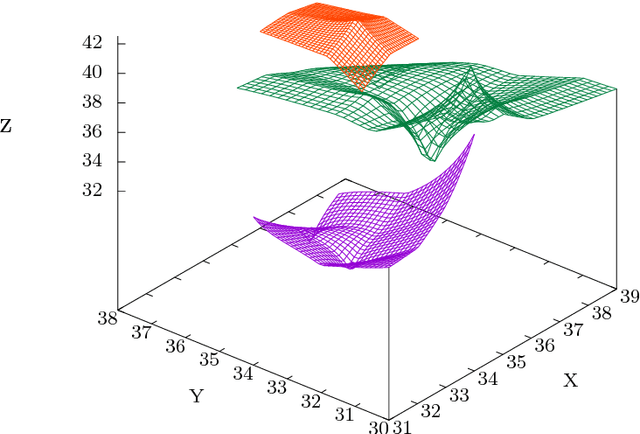
Choosing the most adequate kernel is crucial in many Machine Learning applications. Gaussian Process is a state-of-the-art technique for regression and classification that heavily relies on a kernel function. However, in the Gaussian Process literature, kernels have usually been either ad hoc designed, selected from a predefined set, or searched for in a space of compositions of kernels which have been defined a priori. In this paper, we propose a Genetic-Programming algorithm that represents a kernel function as a tree of elementary mathematical expressions. By means of this representation, a wider set of kernels can be modeled, where potentially better solutions can be found, although new challenges also arise. The proposed algorithm is able to overcome these difficulties and find kernels that accurately model the characteristics of the data. This method has been tested in several real-world time-series extrapolation problems, improving the state-of-the-art results while reducing the complexity of the kernels.
Merge Non-Dominated Sorting Algorithm for Many-Objective Optimization
Sep 17, 2018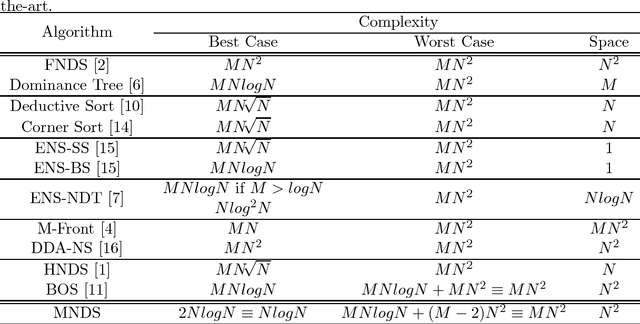
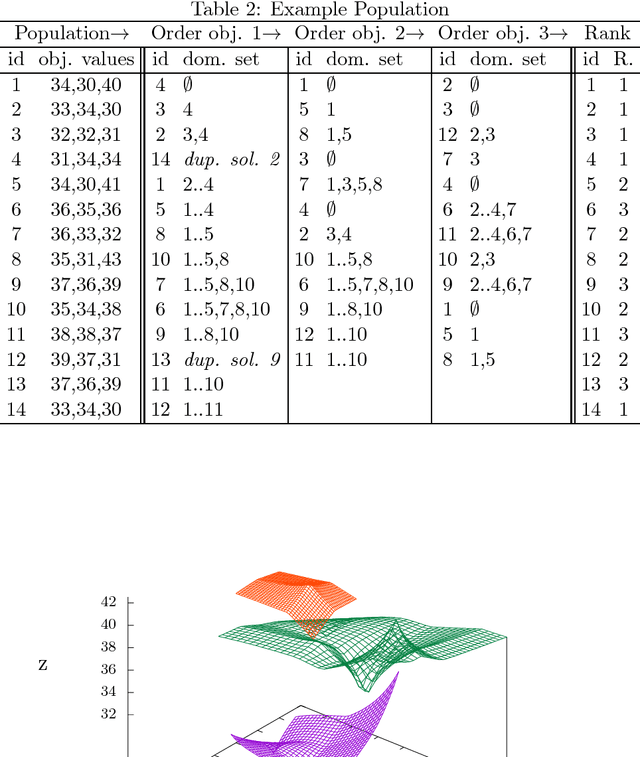
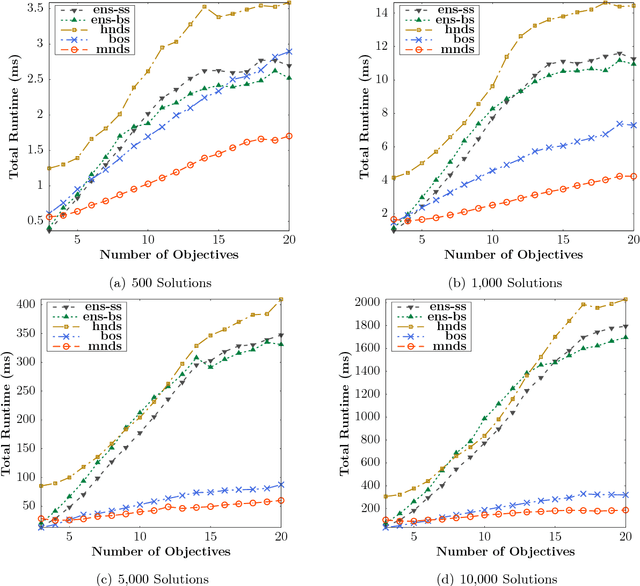
Many Pareto-based multi-objective evolutionary algorithms require to rank the solutions of the population in each iteration according to the dominance principle, what can become a costly operation particularly in the case of dealing with many-objective optimization problems. In this paper, we present a new efficient algorithm for computing the non-dominated sorting procedure, called Merge Non-Dominated Sorting (MNDS), which has a best computational complexity of $\Theta(NlogN)$ and a worst computational complexity of $\Theta(MN^2)$. Our approach is based on the computation of the dominance set of each solution by taking advantage of the characteristics of the merge sort algorithm. We compare the MNDS against four well-known techniques that can be considered as the state-of-the-art. The results indicate that the MNDS algorithm outperforms the other techniques in terms of number of comparisons as well as the total running time.