 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech, Head, and Eye-based Cues for Continuous Affect Prediction
Jul 23, 2019
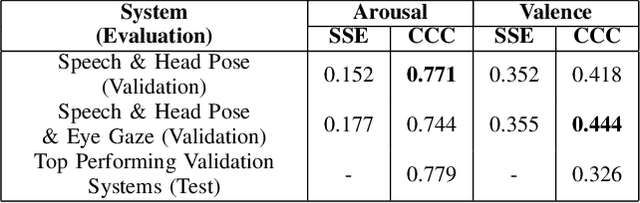
Continuous affect prediction involves the discrete time-continuous regression of affect dimensions. Dimensions to be predicted often include arousal and valence. Continuous affect prediction researchers are now embracing multimodal model input. This provides motivation for researchers to investigate previously unexplored affective cues. Speech-based cues have traditionally received the most attention for affect prediction, however, non-verbal inputs have significant potential to increase the performance of affective computing systems and in addition, allow affect modelling in the absence of speech. However, non-verbal inputs that have received little attention for continuous affect prediction include eye and head-based cues. The eyes are involved in emotion displays and perception while head-based cues have been shown to contribute to emotion conveyance and perception. Additionally, these cues can be estimated non-invasively from video, using modern computer vision tools. This work exploits this gap by comprehensively investigating head and eye-based features and their combination with speech for continuous affect prediction. Hand-crafted, automatically generated and CNN-learned features from these modalities will be investigated for continuous affect prediction. The highest performing feature sets and feature set combinations will answer how effective these features are for the prediction of an individual's affective state.
Eye-based Continuous Affect Prediction
Jul 23, 2019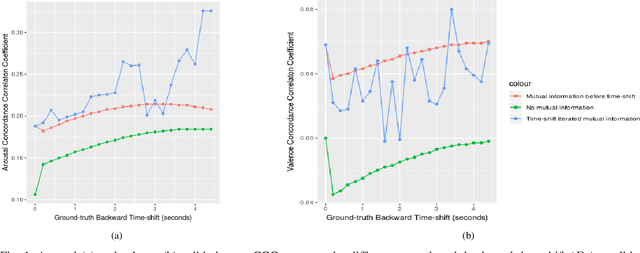



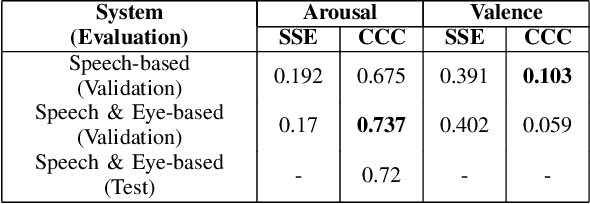
Eye-based information channels include the pupils, gaze, saccades, fixational movements, and numerous forms of eye opening and closure. Pupil size variation indicates cognitive load and emotion, while a person's gaze direction is said to be congruent with the motivation to approach or avoid stimuli. The eyelids are involved in facial expressions that can encode basic emotions. Additionally, eye-based cues can have implications for human annotators of emotions or feelings. Despite these facts, the use of eye-based cues in affective computing is in its infancy, however, and this work is intended to start to address this. Eye-based feature sets, incorporating data from all of the aforementioned information channels, that can be estimated from video are proposed. Feature set refinement is provided by way of continuous arousal and valence learning and prediction experiments on the RECOLA validation set. The eye-based features are then combined with a speech feature set to provide confirmation of their usefulness and assess affect prediction performance compared with group-of-humans-level performance on the RECOLA test set. The core contribution of this paper, a refined eye-based feature set, is shown to provide benefits for affect prediction. It is hoped that this work stimulates further research into eye-based affective computing.