 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Model Construction and Evaluation
Mar 13, 2013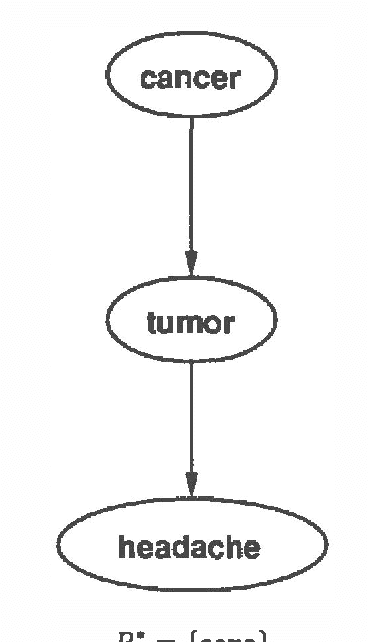
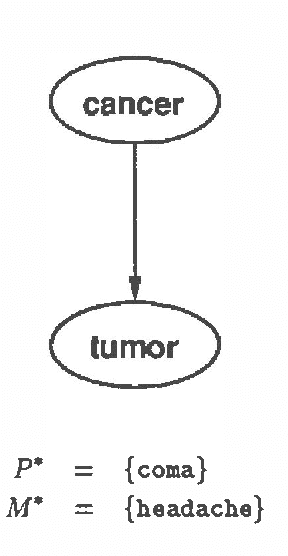
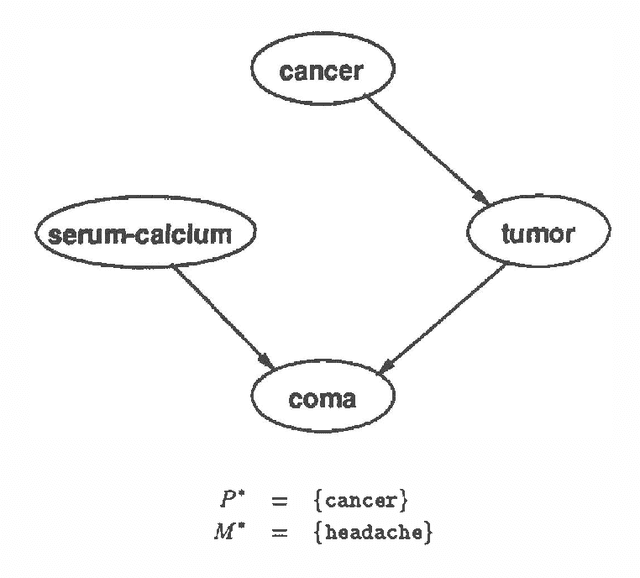
To date, most probabilistic reasoning systems have relied on a fixed belief network constructed at design time. The network is used by an application program as a representation of (in)dependencies in the domain. Probabilistic inference algorithms operate over the network to answer queries. Recognizing the inflexibility of fixed models has led researchers to develop automated network construction procedures that use an expressive knowledge base to generate a network that can answer a query. Although more flexible than fixed model approaches, these construction procedures separate construction and evaluation into distinct phases. In this paper we develop an approach to combining incremental construction and evaluation of a partial probability model. The combined method holds promise for improved methods for control of model construction based on a trade-off between fidelity of results and cost of construction.
Automating Computer Bottleneck Detection with Belief Nets
Feb 20, 2013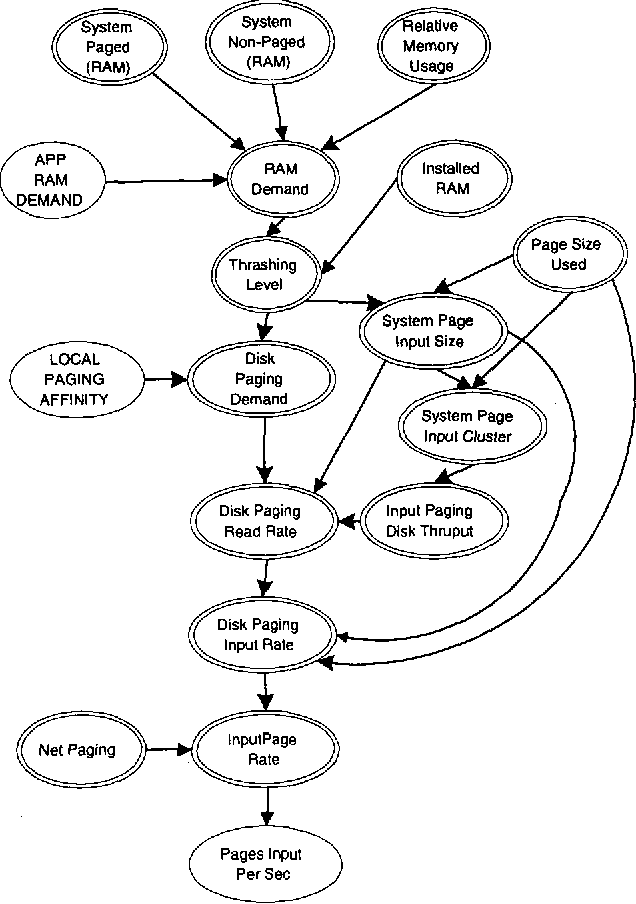
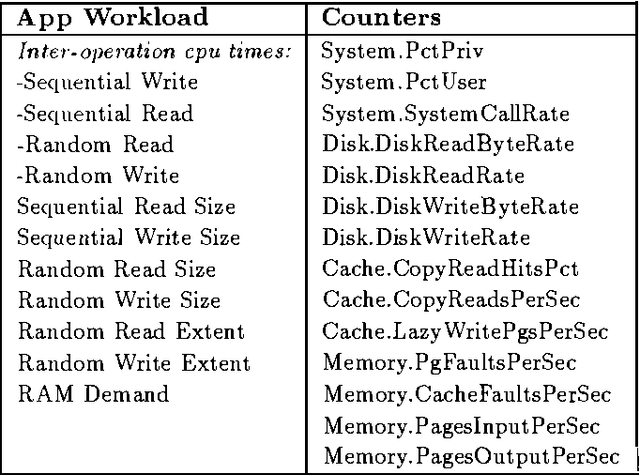
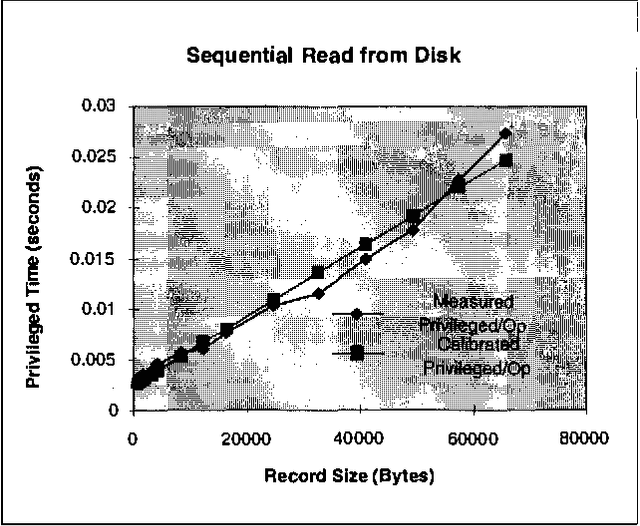
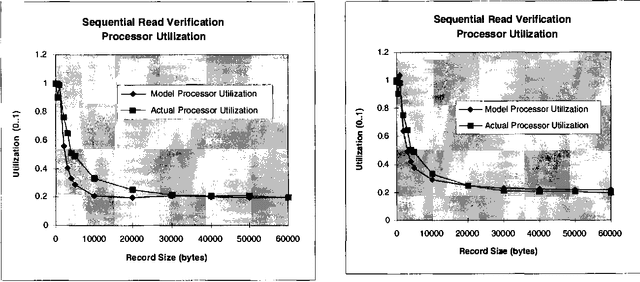
We describe an application of belief networks to the diagnosis of bottlenecks in computer systems. The technique relies on a high-level functional model of the interaction between application workloads, the Windows NT operating system, and system hardware. Given a workload description, the model predicts the values of observable system counters available from the Windows NT performance monitoring tool. Uncertainty in workloads, predictions, and counter values are characterized with Gaussian distributions. During diagnostic inference, we use observed performance monitor values to find the most probable assignment to the workload parameters. In this paper we provide some background on automated bottleneck detection, describe the structure of the system model, and discuss empirical procedures for model calibration and verification. Part of the calibration process includes generating a dataset to estimate a multivariate Gaussian error model. Initial results in diagnosing bottlenecks are presented.
The Lumiere Project: Bayesian User Modeling for Inferring the Goals and Needs of Software Users
Jan 30, 2013
The Lumiere Project centers on harnessing probability and utility to provide assistance to computer software users. We review work on Bayesian user models that can be employed to infer a users needs by considering a user's background, actions, and queries. Several problems were tackled in Lumiere research, including (1) the construction of Bayesian models for reasoning about the time-varying goals of computer users from their observed actions and queries, (2) gaining access to a stream of events from software applications, (3) developing a language for transforming system events into observational variables represented in Bayesian user models, (4) developing persistent profiles to capture changes in a user expertise, and (5) the development of an overall architecture for an intelligent user interface. Lumiere prototypes served as the basis for the Office Assistant in the Microsoft Office '97 suite of productivity applications.
Empirical Analysis of Predictive Algorithms for Collaborative Filtering
Jan 30, 2013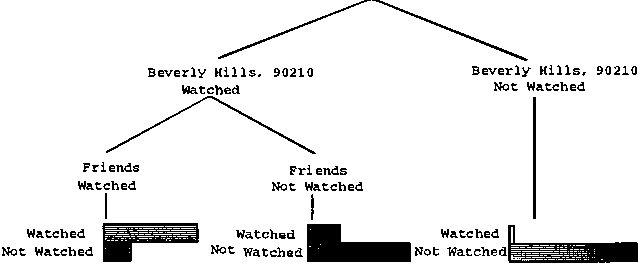
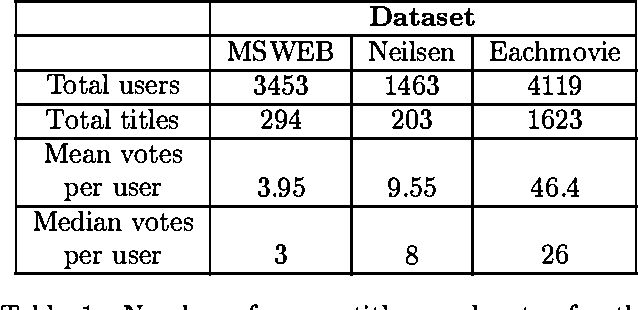
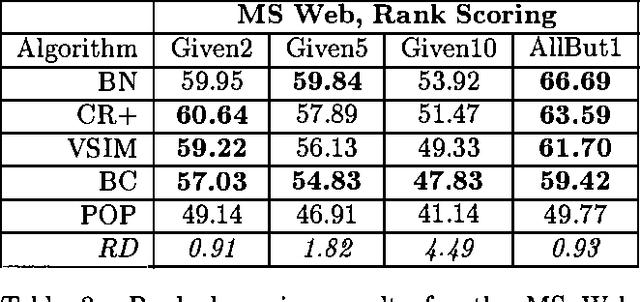

Collaborative filtering or recommender systems use a database about user preferences to predict additional topics or products a new user might like. In this paper we describe several algorithms designed for this task, including techniques based on correlation coefficients, vector-based similarity calculations, and statistical Bayesian methods. We compare the predictive accuracy of the various methods in a set of representative problem domains. We use two basic classes of evaluation metrics. The first characterizes accuracy over a set of individual predictions in terms of average absolute deviation. The second estimates the utility of a ranked list of suggested items. This metric uses an estimate of the probability that a user will see a recommendation in an ordered list. Experiments were run for datasets associated with 3 application areas, 4 experimental protocols, and the 2 evaluation metrics for the various algorithms. Results indicate that for a wide range of conditions, Bayesian networks with decision trees at each node and correlation methods outperform Bayesian-clustering and vector-similarity methods. Between correlation and Bayesian networks, the preferred method depends on the nature of the dataset, nature of the application (ranked versus one-by-one presentation), and the availability of votes with which to make predictions. Other considerations include the size of database, speed of predictions, and learning time.