 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Concise, Machine-discovered Proofs of Gödel's Two Incompleteness Theorems
May 06, 2020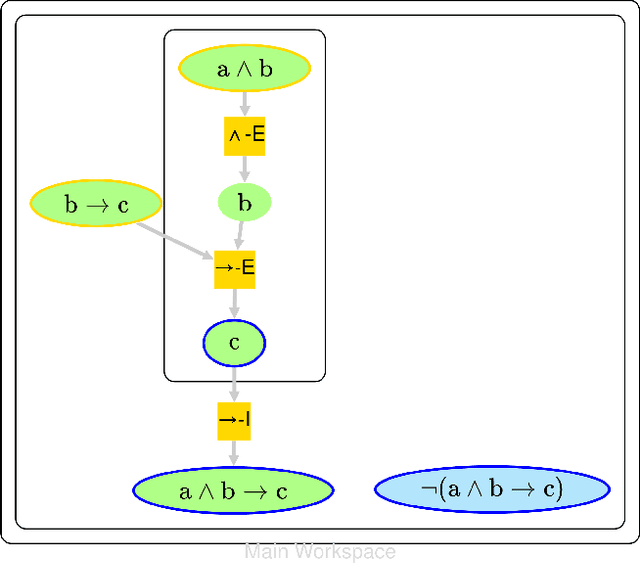
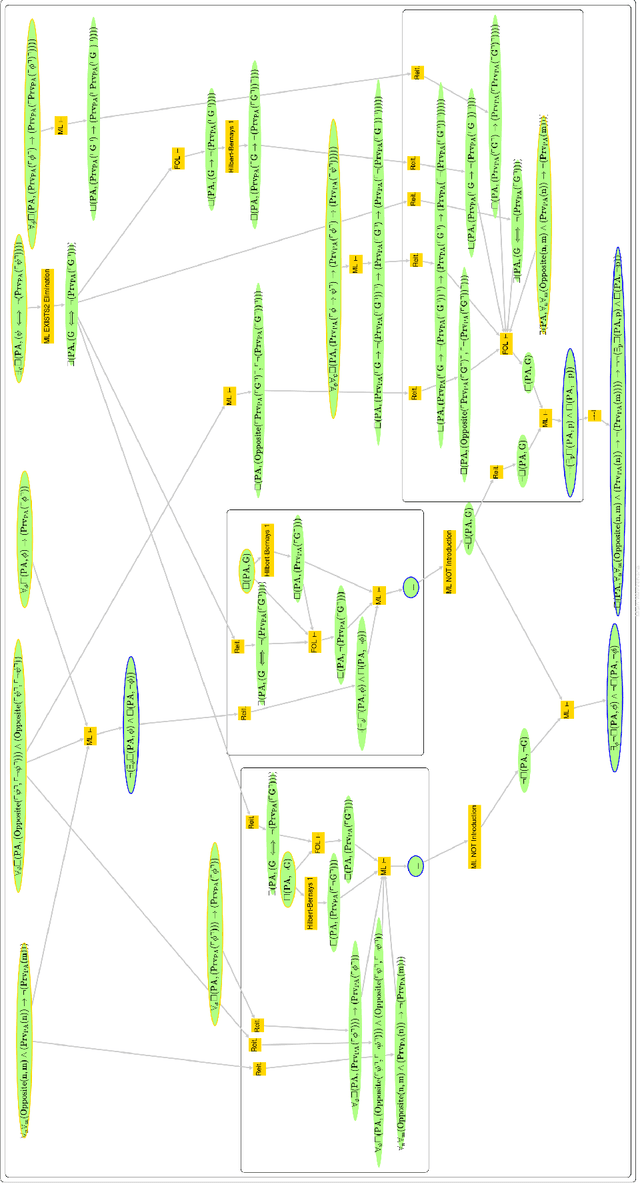
There is an increasing interest in applying recent advances in AI to automated reasoning, as it may provide useful heuristics in reasoning over formalisms in first-order, second-order, or even meta-logics. To facilitate this research, we present MATR, a new framework for automated theorem proving explicitly designed to easily adapt to unusual logics or integrate new reasoning processes. MATR is formalism-agnostic, highly modular, and programmer-friendly. We explain the high-level design of MATR as well as some details of its implementation. To demonstrate MATR's utility, we then describe a formalized metalogic suitable for proofs of G\"odel's Incompleteness Theorems, and report on our progress using our metalogic in MATR to semi-autonomously generate proofs of both the First and Second Incompleteness Theorems.
Probing the Natural Language Inference Task with Automated Reasoning Tools
May 06, 2020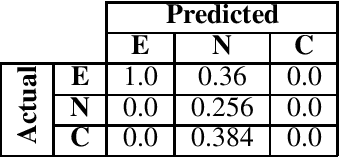
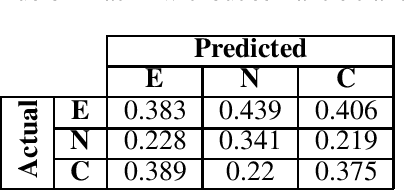
The Natural Language Inference (NLI) task is an important task in modern NLP, as it asks a broad question to which many other tasks may be reducible: Given a pair of sentences, does the first entail the second? Although the state-of-the-art on current benchmark datasets for NLI are deep learning-based, it is worthwhile to use other techniques to examine the logical structure of the NLI task. We do so by testing how well a machine-oriented controlled natural language (Attempto Controlled English) can be used to parse NLI sentences, and how well automated theorem provers can reason over the resulting formulae. To improve performance, we develop a set of syntactic and semantic transformation rules. We report their performance, and discuss implications for NLI and logic-based NLP.
Scenarios and Recommendations for Ethical Interpretive AI
Nov 05, 2019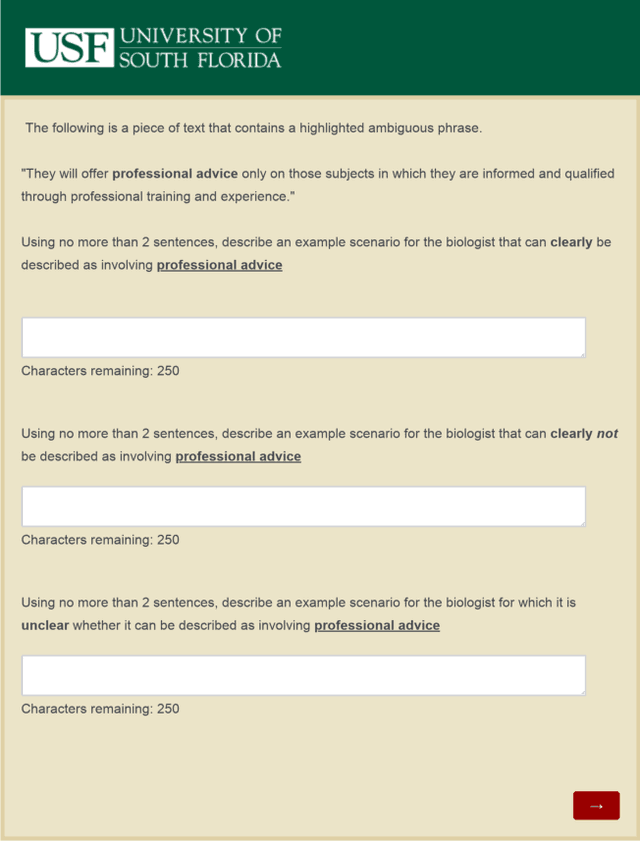
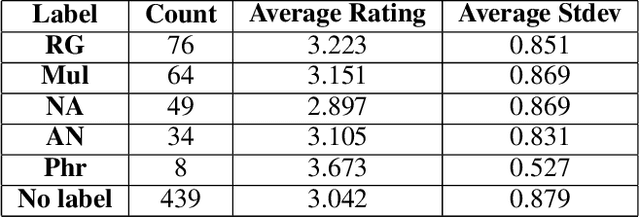
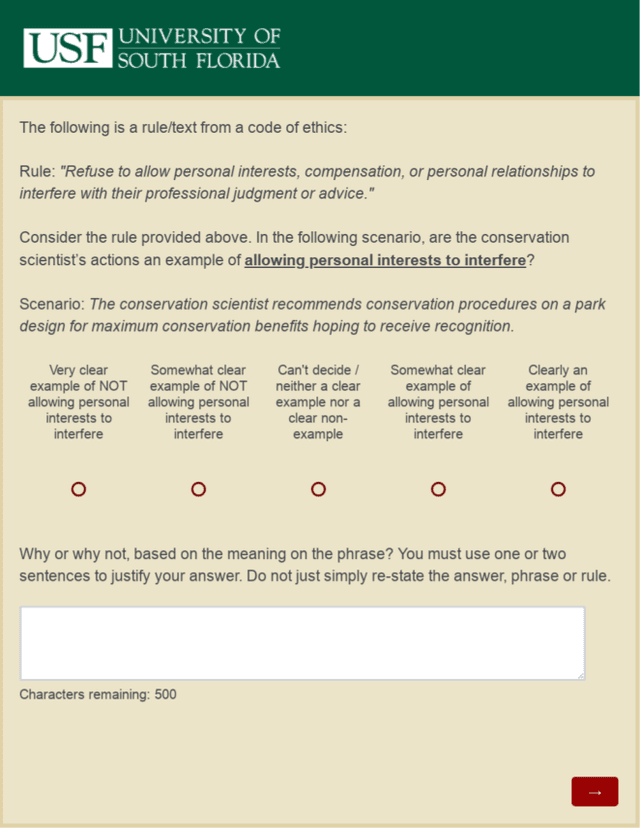
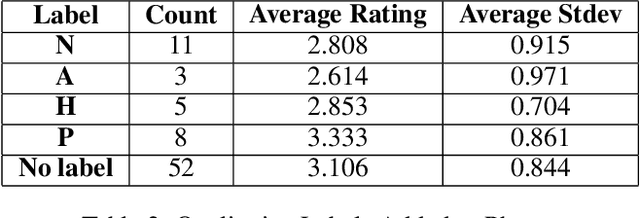
Artificially intelligent systems, given a set of non-trivial ethical rules to follow, will inevitably be faced with scenarios which call into question the scope of those rules. In such cases, human reasoners typically will engage in interpretive reasoning, where interpretive arguments are used to support or attack claims that some rule should be understood a certain way. Artificially intelligent reasoners, however, currently lack the ability to carry out human-like interpretive reasoning, and we argue that bridging this gulf is of tremendous importance to human-centered AI. In order to better understand how future artificial reasoners capable of human-like interpretive reasoning must be developed, we have collected a dataset of ethical rules, scenarios designed to invoke interpretive reasoning, and interpretations of those scenarios. We perform a qualitative analysis of our dataset, and summarize our findings in the form of practical recommendations.