 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Models for Media Bias Detection and Subcategorization
Dec 16, 2024We present improved models for the granular detection and sub-classification news media bias in English news articles. We compare the performance of zero-shot versus fine-tuned large pre-trained neural transformer language models, explore how the level of detail of the classes affects performance on a novel taxonomy of 27 news bias-types, and demonstrate how using synthetically generated example data can be used to improve quality
BiasScanner: Automatic Detection and Classification of News Bias to Strengthen Democracy
Jul 15, 2024



The increasing consumption of news online in the 21st century coincided with increased publication of disinformation, biased reporting, hate speech and other unwanted Web content. We describe BiasScanner, an application that aims to strengthen democracy by supporting news consumers with scrutinizing news articles they are reading online. BiasScanner contains a server-side pre-trained large language model to identify biased sentences of news articles and a front-end Web browser plug-in. At the time of writing, BiasScanner can identify and classify more than two dozen types of media bias at the sentence level, making it the most fine-grained model and only deployed application (automatic system in use) of its kind. It was implemented in a light-weight and privacy-respecting manner, and in addition to highlighting likely biased sentence it also provides explanations for each classification decision as well as a summary analysis for each news article. While prior research has addressed news bias detection, we are not aware of any work that resulted in a deployed browser plug-in (c.f. also biasscanner.org for a Web demo).
Experiments in News Bias Detection with Pre-Trained Neural Transformers
Jun 14, 2024The World Wide Web provides unrivalled access to information globally, including factual news reporting and commentary. However, state actors and commercial players increasingly spread biased (distorted) or fake (non-factual) information to promote their agendas. We compare several large, pre-trained language models on the task of sentence-level news bias detection and sub-type classification, providing quantitative and qualitative results.
Which Country Is This? Automatic Country Ranking of Street View Photos
Jun 11, 2024In this demonstration, we present Country Guesser, a live system that guesses the country that a photo is taken in. In particular, given a Google Street View image, our federated ranking model uses a combination of computer vision, machine learning and text retrieval methods to compute a ranking of likely countries of the location shown in a given image from Street View. Interestingly, using text-based features to probe large pre-trained language models can assist to provide cross-modal supervision. We are not aware of previous country guessing systems informed by visual and textual features.
Challenges and Opportunities of NLP for HR Applications: A Discussion Paper
May 13, 2024

Over the course of the recent decade, tremendous progress has been made in the areas of machine learning and natural language processing, which opened up vast areas of potential application use cases, including hiring and human resource management. We review the use cases for text analytics in the realm of human resources/personnel management, including actually realized as well as potential but not yet implemented ones, and we analyze the opportunities and risks of these.
Control in Hybrid Chatbots
Nov 20, 2023


Customer data typically is held in database systems, which can be seen as rule-based knowledge base, whereas businesses increasingly want to benefit from the capabilities of large, pre-trained language models. In this technical report, we describe a case study of how a commercial rule engine and an integrated neural chatbot may be integrated, and what level of control that particular integration mode leads to. We also discuss alternative ways (including past ways realized in other systems) how researchers strive to maintain control and avoid what has recently been called model "hallucination".
Data-to-Value: An Evaluation-First Methodology for Natural Language Projects
Jan 19, 2022Big data, i.e. collecting, storing and processing of data at scale, has recently been possible due to the arrival of clusters of commodity computers powered by application-level distributed parallel operating systems like HDFS/Hadoop/Spark, and such infrastructures have revolutionized data mining at scale. For data mining project to succeed more consistently, some methodologies were developed (e.g. CRISP-DM, SEMMA, KDD), but these do not account for (1) very large scales of processing, (2) dealing with textual (unstructured) data (i.e. Natural Language Processing (NLP, "text analytics"), and (3) non-technical considerations (e.g. legal, ethical, project managerial aspects). To address these shortcomings, a new methodology, called "Data to Value" (D2V), is introduced, which is guided by a detailed catalog of questions in order to avoid a disconnect of big data text analytics project team with the topic when facing rather abstract box-and-arrow diagrams commonly associated with methodologies.
Detecting ESG topics using domain-specific language models and data augmentation approaches
Oct 16, 2020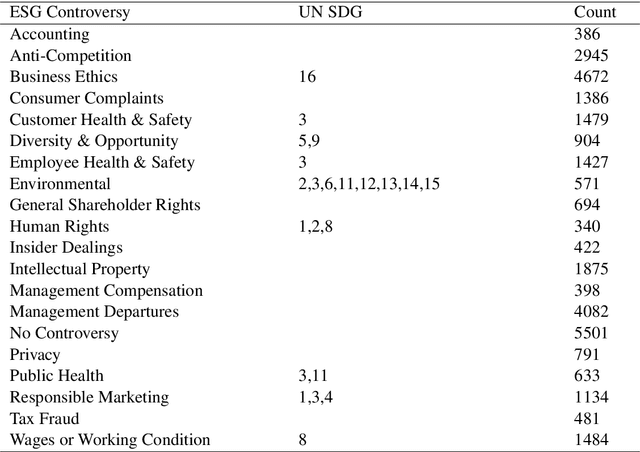
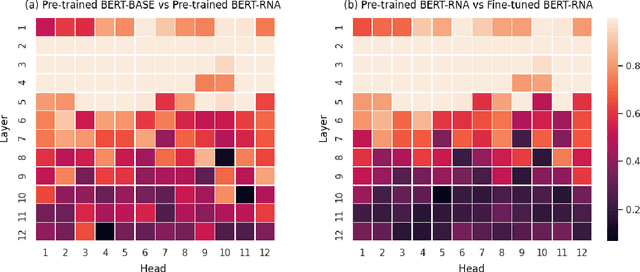

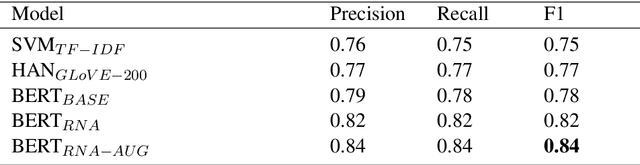
Despite recent advances in deep learning-based language modelling, many natural language processing (NLP) tasks in the financial domain remain challenging due to the paucity of appropriately labelled data. Other issues that can limit task performance are differences in word distribution between the general corpora - typically used to pre-train language models - and financial corpora, which often exhibit specialized language and symbology. Here, we investigate two approaches that may help to mitigate these issues. Firstly, we experiment with further language model pre-training using large amounts of in-domain data from business and financial news. We then apply augmentation approaches to increase the size of our dataset for model fine-tuning. We report our findings on an Environmental, Social and Governance (ESG) controversies dataset and demonstrate that both approaches are beneficial to accuracy in classification tasks.
Topic Grouper: An Agglomerative Clustering Approach to Topic Modeling
Apr 13, 2019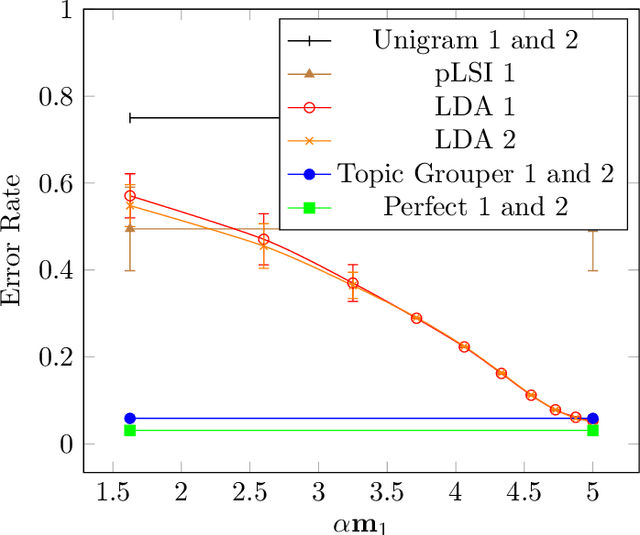
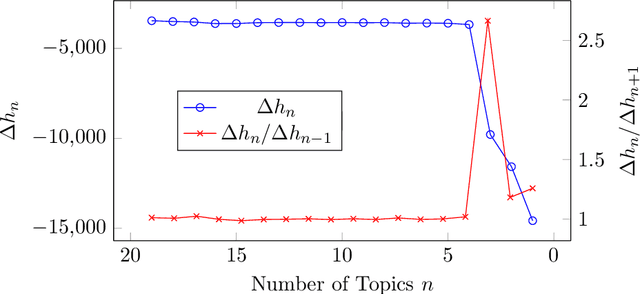
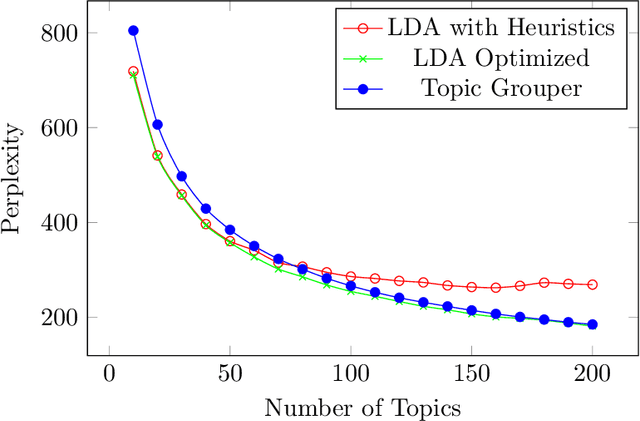
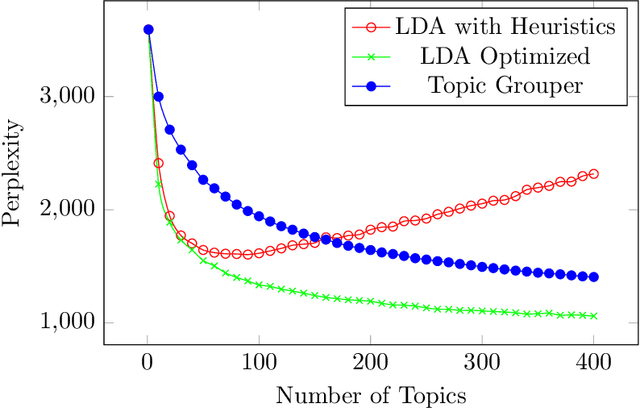
We introduce Topic Grouper as a complementary approach in the field of probabilistic topic modeling. Topic Grouper creates a disjunctive partitioning of the training vocabulary in a stepwise manner such that resulting partitions represent topics. It is governed by a simple generative model, where the likelihood to generate the training documents via topics is optimized. The algorithm starts with one-word topics and joins two topics at every step. It therefore generates a solution for every desired number of topics ranging between the size of the training vocabulary and one. The process represents an agglomerative clustering that corresponds to a binary tree of topics. A resulting tree may act as a containment hierarchy, typically with more general topics towards the root of tree and more specific topics towards the leaves. Topic Grouper is not governed by a background distribution such as the Dirichlet and avoids hyper parameter optimizations. We show that Topic Grouper has reasonable predictive power and also a reasonable theoretical and practical complexity. Topic Grouper can deal well with stop words and function words and tends to push them into their own topics. Also, it can handle topic distributions, where some topics are more frequent than others. We present typical examples of computed topics from evaluation datasets, where topics appear conclusive and coherent. In this context, the fact that each word belongs to exactly one topic is not a major limitation; in some scenarios this can even be a genuine advantage, e.g.~a related shopping basket analysis may aid in optimizing groupings of articles in sales catalogs.
Question Answering over Unstructured Data without Domain Restrictions
Jul 18, 2002
Information needs are naturally represented as questions. Automatic Natural-Language Question Answering (NLQA) has only recently become a practical task on a larger scale and without domain constraints. This paper gives a brief introduction to the field, its history and the impact of systematic evaluation competitions. It is then demonstrated that an NLQA system for English can be built and evaluated in a very short time using off-the-shelf parsers and thesauri. The system is based on Robust Minimal Recursion Semantics (RMRS) and is portable with respect to the parser used as a frontend. It applies atomic term unification supported by question classification and WordNet lookup for semantic similarity matching of parsed question representation and free text.