 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJintang Li
Spectral Adversarial Training for Robust Graph Neural Network
Nov 20, 2022
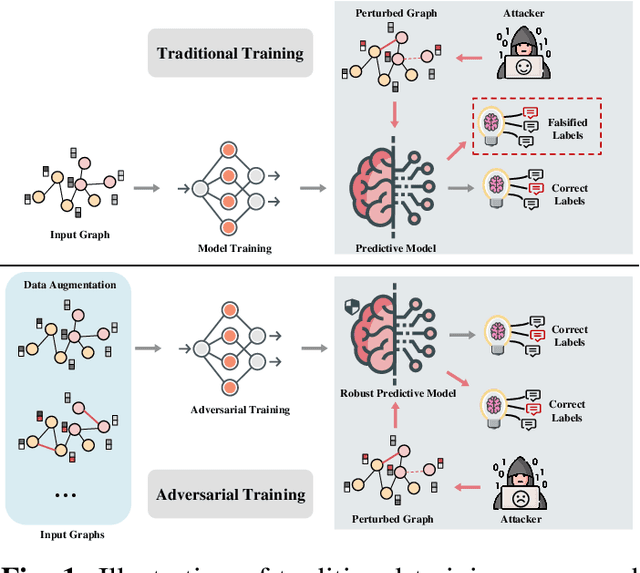
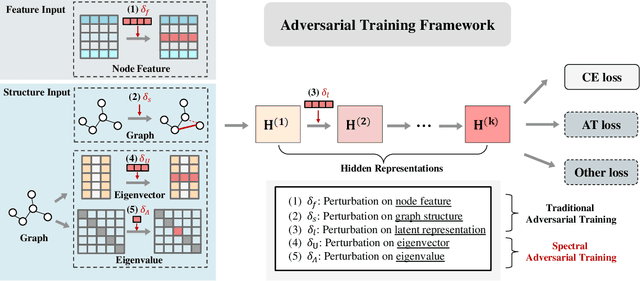
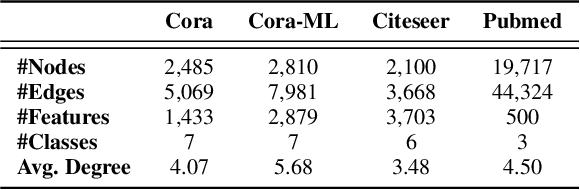
Recent studies demonstrate that Graph Neural Networks (GNNs) are vulnerable to slight but adversarially designed perturbations, known as adversarial examples. To address this issue, robust training methods against adversarial examples have received considerable attention in the literature. \emph{Adversarial Training (AT)} is a successful approach to learning a robust model using adversarially perturbed training samples. Existing AT methods on GNNs typically construct adversarial perturbations in terms of graph structures or node features. However, they are less effective and fraught with challenges on graph data due to the discreteness of graph structure and the relationships between connected examples. In this work, we seek to address these challenges and propose Spectral Adversarial Training (SAT), a simple yet effective adversarial training approach for GNNs. SAT first adopts a low-rank approximation of the graph structure based on spectral decomposition, and then constructs adversarial perturbations in the spectral domain rather than directly manipulating the original graph structure. To investigate its effectiveness, we employ SAT on three widely used GNNs. Experimental results on four public graph datasets demonstrate that SAT significantly improves the robustness of GNNs against adversarial attacks without sacrificing classification accuracy and training efficiency.
Are All Edges Necessary? A Unified Framework for Graph Purification
Nov 09, 2022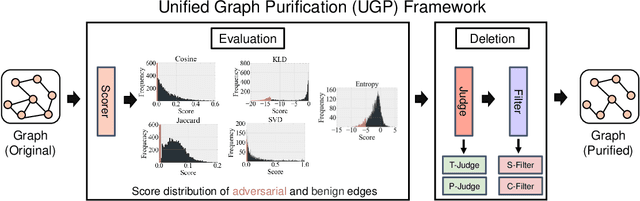
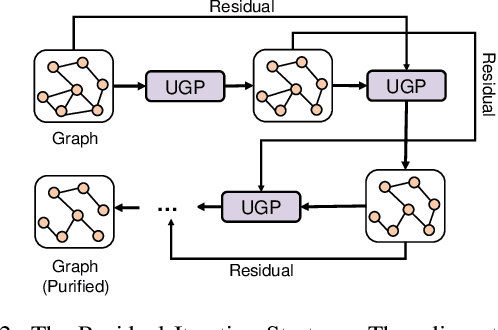

Graph Neural Networks (GNNs) as deep learning models working on graph-structure data have achieved advanced performance in many works. However, it has been proved repeatedly that, not all edges in a graph are necessary for the training of machine learning models. In other words, some of the connections between nodes may bring redundant or even misleading information to downstream tasks. In this paper, we try to provide a method to drop edges in order to purify the graph data from a new perspective. Specifically, it is a framework to purify graphs with the least loss of information, under which the core problems are how to better evaluate the edges and how to delete the relatively redundant edges with the least loss of information. To address the above two problems, we propose several measurements for the evaluation and different judges and filters for the edge deletion. We also introduce a residual-iteration strategy and a surrogate model for measurements requiring unknown information. The experimental results show that our proposed measurements for KL divergence with constraints to maintain the connectivity of the graph and delete edges in an iterative way can find out the most edges while keeping the performance of GNNs. What's more, further experiments show that this method also achieves the best defense performance against adversarial attacks.
Scaling Up Dynamic Graph Representation Learning via Spiking Neural Networks
Aug 15, 2022
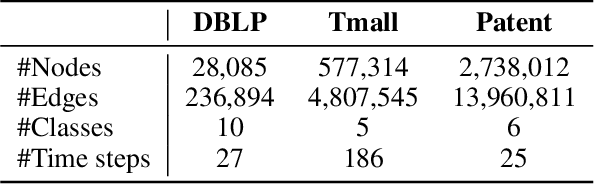
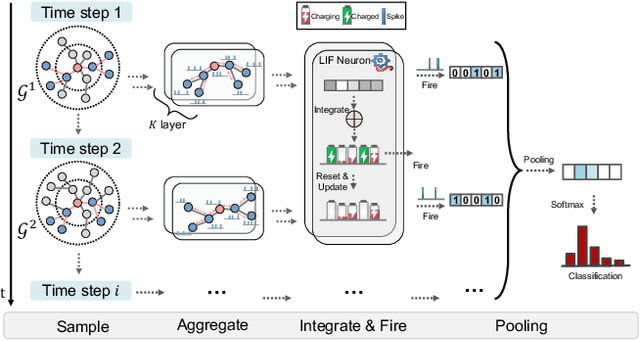
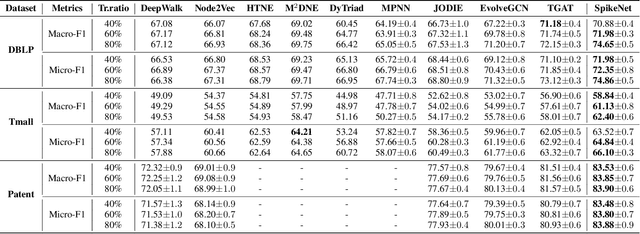
Recent years have seen a surge in research on dynamic graph representation learning, which aims to model temporal graphs that are dynamic and evolving constantly over time. However, current work typically models graph dynamics with recurrent neural networks (RNNs), making them suffer seriously from computation and memory overheads on large temporal graphs. So far, scalability of dynamic graph representation learning on large temporal graphs remains one of the major challenges. In this paper, we present a scalable framework, namely SpikeNet, to efficiently capture the temporal and structural patterns of temporal graphs. We explore a new direction in that we can capture the evolving dynamics of temporal graphs with spiking neural networks (SNNs) instead of RNNs. As a low-power alternative to RNNs, SNNs explicitly model graph dynamics as spike trains of neuron populations and enable spike-based propagation in an efficient way. Experiments on three large real-world temporal graph datasets demonstrate that SpikeNet outperforms strong baselines on the temporal node classification task with lower computational costs. Particularly, SpikeNet generalizes to a large temporal graph (2M nodes and 13M edges) with significantly fewer parameters and computation overheads. Our code is publicly available at https://github.com/EdisonLeeeee/SpikeNet
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022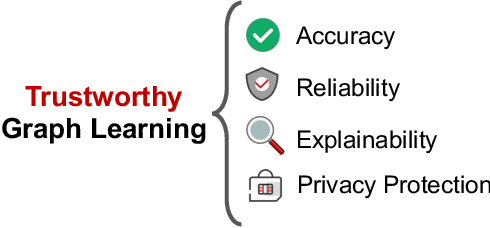


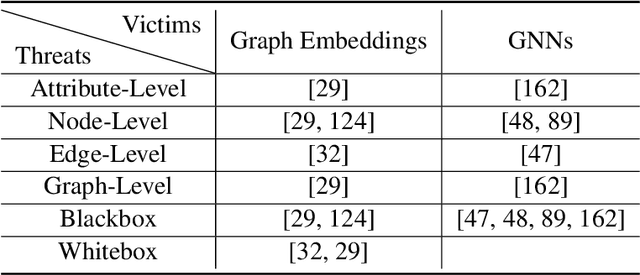
Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.
MaskGAE: Masked Graph Modeling Meets Graph Autoencoders
May 20, 2022
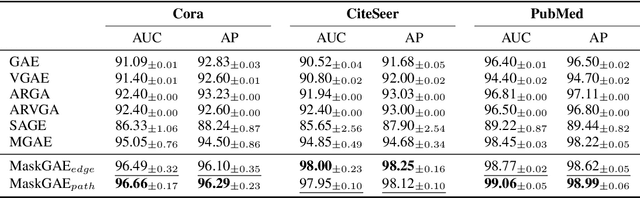
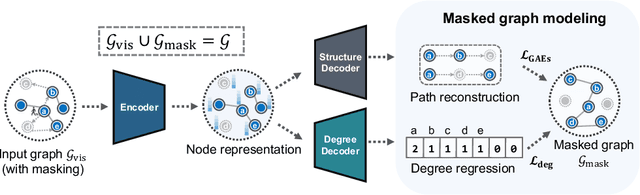
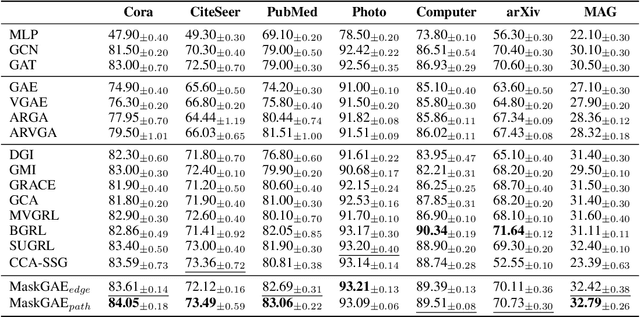
We present masked graph autoencoder (MaskGAE), a self-supervised learning framework for graph-structured data. Different from previous graph autoencoders (GAEs), MaskGAE adopts masked graph modeling (MGM) as a principled pretext task: masking a portion of edges and attempting to reconstruct the missing part with partially visible, unmasked graph structure. To understand whether MGM can help GAEs learn better representations, we provide both theoretical and empirical evidence to justify the benefits of this pretext task. Theoretically, we establish the connections between GAEs and contrastive learning, showing that MGM significantly improves the self-supervised learning scheme of GAEs. Empirically, we conduct extensive experiments on a number of benchmark datasets, demonstrating the superiority of MaskGAE over several state-of-the-arts on both link prediction and node classification tasks. Our code is publicly available at \url{https://github.com/EdisonLeeeee/MaskGAE}.
Spiking Graph Convolutional Networks
May 05, 2022
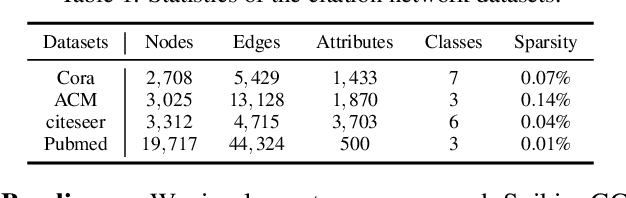
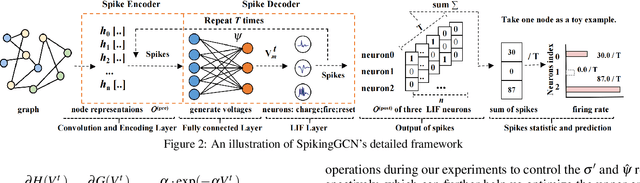
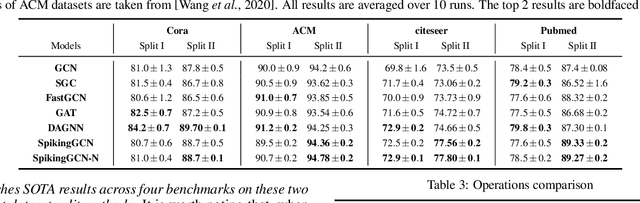
Graph Convolutional Networks (GCNs) achieve an impressive performance due to the remarkable representation ability in learning the graph information. However, GCNs, when implemented on a deep network, require expensive computation power, making them difficult to be deployed on battery-powered devices. In contrast, Spiking Neural Networks (SNNs), which perform a bio-fidelity inference process, offer an energy-efficient neural architecture. In this work, we propose SpikingGCN, an end-to-end framework that aims to integrate the embedding of GCNs with the biofidelity characteristics of SNNs. The original graph data are encoded into spike trains based on the incorporation of graph convolution. We further model biological information processing by utilizing a fully connected layer combined with neuron nodes. In a wide range of scenarios (e.g. citation networks, image graph classification, and recommender systems), our experimental results show that the proposed method could gain competitive performance against state-of-the-art approaches. Furthermore, we show that SpikingGCN on a neuromorphic chip can bring a clear advantage of energy efficiency into graph data analysis, which demonstrates its great potential to construct environment-friendly machine learning models.
GUARD: Graph Universal Adversarial Defense
Apr 20, 2022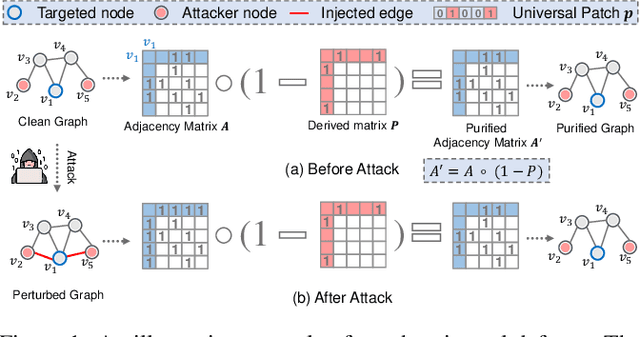
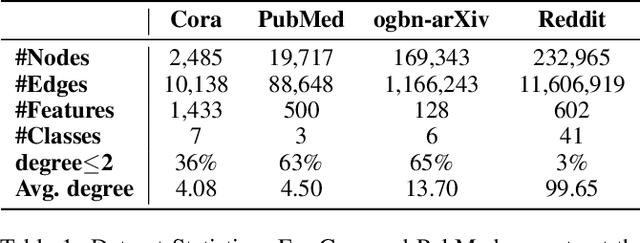
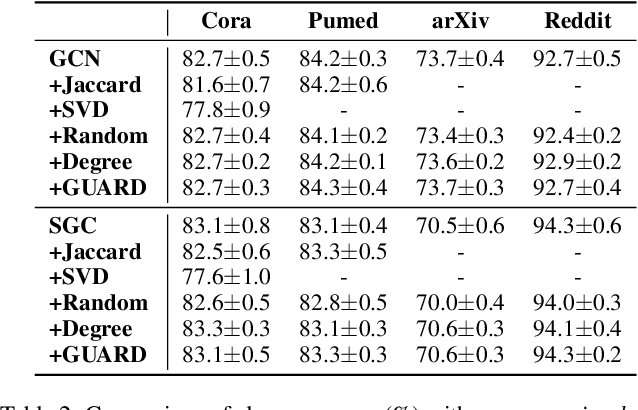
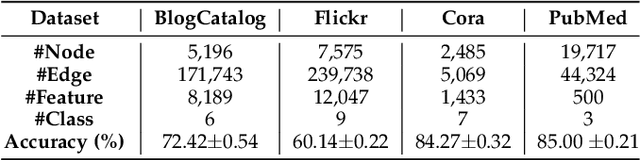
Recently, graph convolutional networks (GCNs) have shown to be vulnerable to small adversarial perturbations, which becomes a severe threat and largely limits their applications in security-critical scenarios. To mitigate such a threat, considerable research efforts have been devoted to increasing the robustness of GCNs against adversarial attacks. However, current approaches for defense are typically designed for the whole graph and consider the global performance, posing challenges in protecting important local nodes from stronger adversarial targeted attacks. In this work, we present a simple yet effective method, named \textbf{\underline{G}}raph \textbf{\underline{U}}niversal \textbf{\underline{A}}dve\textbf{\underline{R}}sarial \textbf{\underline{D}}efense (GUARD). Unlike previous works, GUARD protects each individual node from attacks with a universal defensive patch, which is generated once and can be applied to any node (node-agnostic) in a graph. Extensive experiments on four benchmark datasets demonstrate that our method significantly improves robustness for several established GCNs against multiple adversarial attacks and outperforms existing adversarial defense methods by large margins. Our code is publicly available at https://github.com/EdisonLeeeee/GUARD.
Recent Advances in Reliable Deep Graph Learning: Adversarial Attack, Inherent Noise, and Distribution Shift
Feb 15, 2022
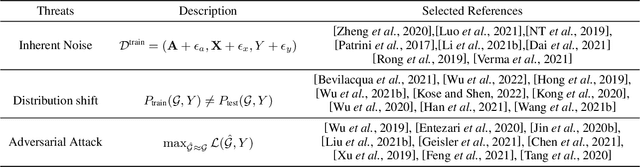
Deep graph learning (DGL) has achieved remarkable progress in both business and scientific areas ranging from finance and e-commerce to drug and advanced material discovery. Despite the progress, applying DGL to real-world applications faces a series of reliability threats including adversarial attacks, inherent noise, and distribution shift. This survey aims to provide a comprehensive review of recent advances for improving the reliability of DGL algorithms against the above threats. In contrast to prior related surveys which mainly focus on adversarial attacks and defense, our survey covers more reliability-related aspects of DGL, i.e., inherent noise and distribution shift. Additionally, we discuss the relationships among above aspects and highlight some important issues to be explored in future research.
Neighboring Backdoor Attacks on Graph Convolutional Network
Jan 17, 2022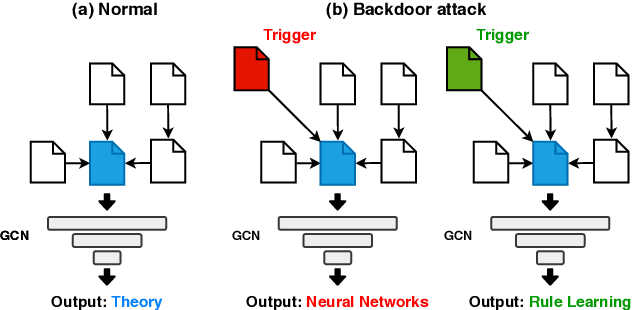
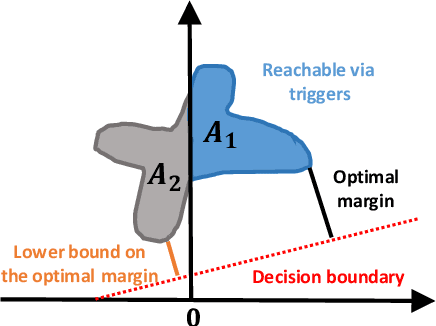
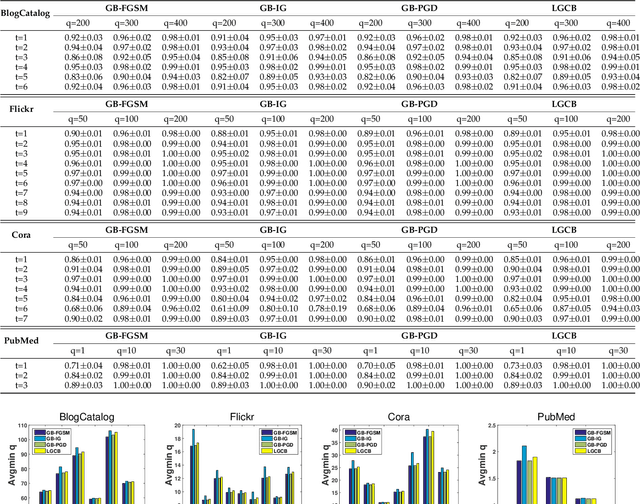
Backdoor attacks have been widely studied to hide the misclassification rules in the normal models, which are only activated when the model is aware of the specific inputs (i.e., the trigger). However, despite their success in the conventional Euclidean space, there are few studies of backdoor attacks on graph structured data. In this paper, we propose a new type of backdoor which is specific to graph data, called neighboring backdoor. Considering the discreteness of graph data, how to effectively design the triggers while retaining the model accuracy on the original task is the major challenge. To address such a challenge, we set the trigger as a single node, and the backdoor is activated when the trigger node is connected to the target node. To preserve the model accuracy, the model parameters are not allowed to be modified. Thus, when the trigger node is not connected, the model performs normally. Under these settings, in this work, we focus on generating the features of the trigger node. Two types of backdoors are proposed: (1) Linear Graph Convolution Backdoor which finds an approximation solution for the feature generation (can be viewed as an integer programming problem) by looking at the linear part of GCNs. (2) Variants of existing graph attacks. We extend current gradient-based attack methods to our backdoor attack scenario. Extensive experiments on two social networks and two citation networks datasets demonstrate that all proposed backdoors can achieve an almost 100\% attack success rate while having no impact on predictive accuracy.
Understanding Structural Vulnerability in Graph Convolutional Networks
Aug 13, 2021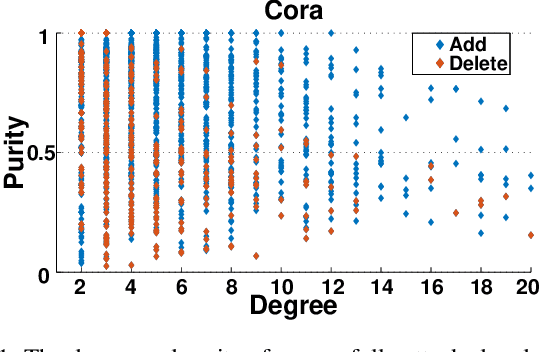
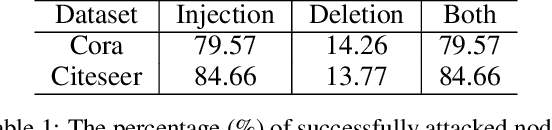
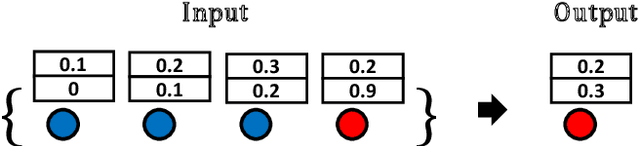
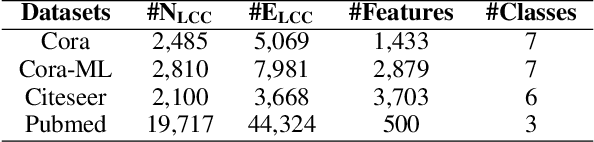
Recent studies have shown that Graph Convolutional Networks (GCNs) are vulnerable to adversarial attacks on the graph structure. Although multiple works have been proposed to improve their robustness against such structural adversarial attacks, the reasons for the success of the attacks remain unclear. In this work, we theoretically and empirically demonstrate that structural adversarial examples can be attributed to the non-robust aggregation scheme (i.e., the weighted mean) of GCNs. Specifically, our analysis takes advantage of the breakdown point which can quantitatively measure the robustness of aggregation schemes. The key insight is that weighted mean, as the basic design of GCNs, has a low breakdown point and its output can be dramatically changed by injecting a single edge. We show that adopting the aggregation scheme with a high breakdown point (e.g., median or trimmed mean) could significantly enhance the robustness of GCNs against structural attacks. Extensive experiments on four real-world datasets demonstrate that such a simple but effective method achieves the best robustness performance compared to state-of-the-art models.