 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingwen Wang
Siamese Encoder-based Spatial-Temporal Mixer for Growth Trend Prediction of Lung Nodules on CT Scans
Jun 07, 2022
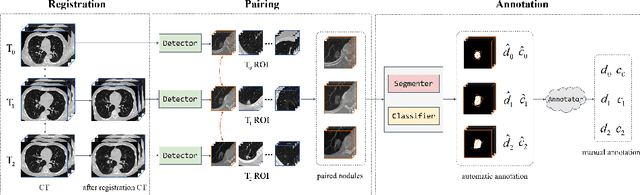
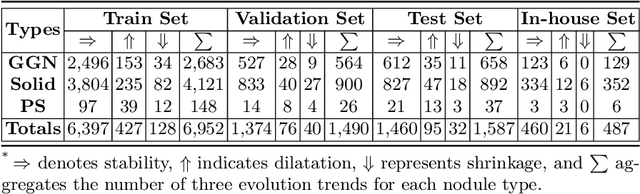
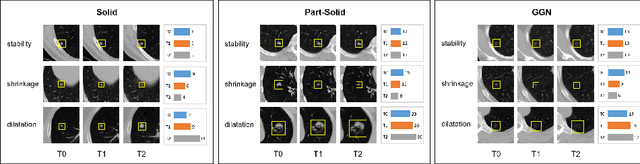
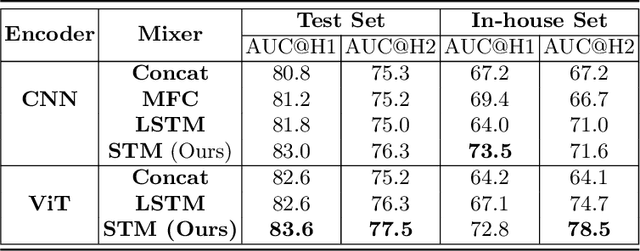
In the management of lung nodules, we are desirable to predict nodule evolution in terms of its diameter variation on Computed Tomography (CT) scans and then provide a follow-up recommendation according to the predicted result of the growing trend of the nodule. In order to improve the performance of growth trend prediction for lung nodules, it is vital to compare the changes of the same nodule in consecutive CT scans. Motivated by this, we screened out 4,666 subjects with more than two consecutive CT scans from the National Lung Screening Trial (NLST) dataset to organize a temporal dataset called NLSTt. In specific, we first detect and pair regions of interest (ROIs) covering the same nodule based on registered CT scans. After that, we predict the texture category and diameter size of the nodules through models. Last, we annotate the evolution class of each nodule according to its changes in diameter. Based on the built NLSTt dataset, we propose a siamese encoder to simultaneously exploit the discriminative features of 3D ROIs detected from consecutive CT scans. Then we novelly design a spatial-temporal mixer (STM) to leverage the interval changes of the same nodule in sequential 3D ROIs and capture spatial dependencies of nodule regions and the current 3D ROI. According to the clinical diagnosis routine, we employ hierarchical loss to pay more attention to growing nodules. The extensive experiments on our organized dataset demonstrate the advantage of our proposed method. We also conduct experiments on an in-house dataset to evaluate the clinical utility of our method by comparing it against skilled clinicians.
Controllable Video Captioning with an Exemplar Sentence
Dec 02, 2021
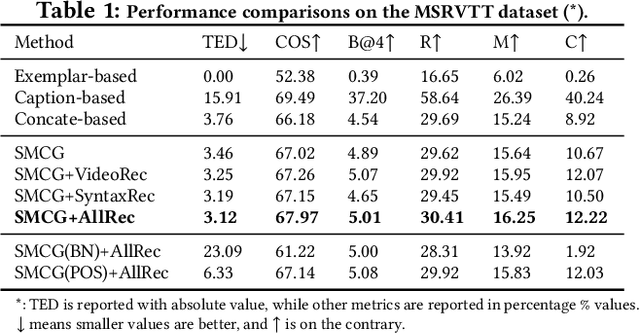
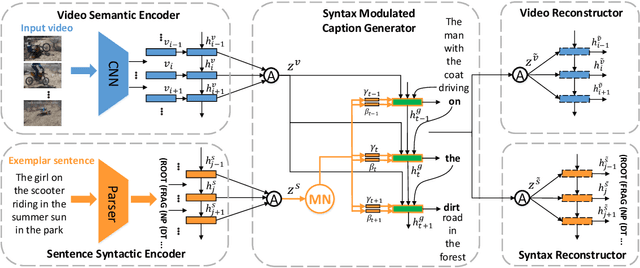
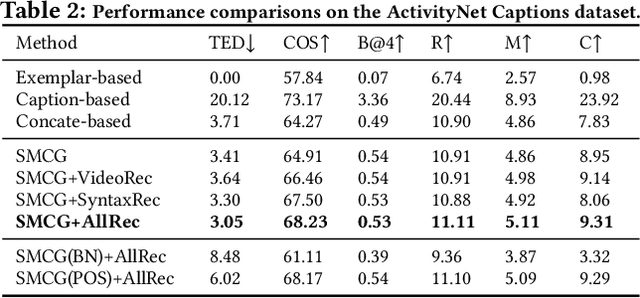
In this paper, we investigate a novel and challenging task, namely controllable video captioning with an exemplar sentence. Formally, given a video and a syntactically valid exemplar sentence, the task aims to generate one caption which not only describes the semantic contents of the video, but also follows the syntactic form of the given exemplar sentence. In order to tackle such an exemplar-based video captioning task, we propose a novel Syntax Modulated Caption Generator (SMCG) incorporated in an encoder-decoder-reconstructor architecture. The proposed SMCG takes video semantic representation as an input, and conditionally modulates the gates and cells of long short-term memory network with respect to the encoded syntactic information of the given exemplar sentence. Therefore, SMCG is able to control the states for word prediction and achieve the syntax customized caption generation. We conduct experiments by collecting auxiliary exemplar sentences for two public video captioning datasets. Extensive experimental results demonstrate the effectiveness of our approach on generating syntax controllable and semantic preserved video captions. By providing different exemplar sentences, our approach is capable of producing different captions with various syntactic structures, thus indicating a promising way to strengthen the diversity of video captioning.
DSP-SLAM: Object Oriented SLAM with Deep Shape Priors
Aug 21, 2021
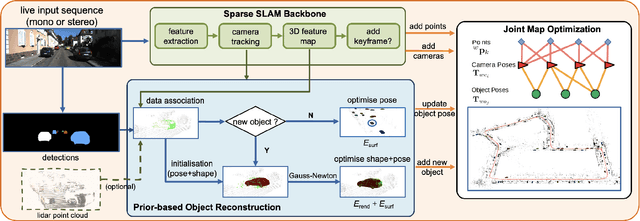
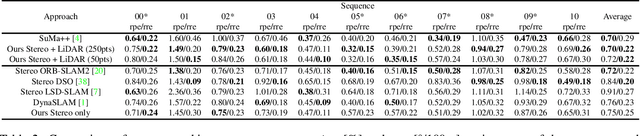

We propose DSP-SLAM, an object-oriented SLAM system that builds a rich and accurate joint map of dense 3D models for foreground objects, and sparse landmark points to represent the background. DSP-SLAM takes as input the 3D point cloud reconstructed by a feature-based SLAM system and equips it with the ability to enhance its sparse map with dense reconstructions of detected objects. Objects are detected via semantic instance segmentation, and their shape and pose is estimated using category-specific deep shape embeddings as priors, via a novel second order optimization. Our object-aware bundle adjustment builds a pose-graph to jointly optimize camera poses, object locations and feature points. DSP-SLAM can operate at 10 frames per second on 3 different input modalities: monocular, stereo, or stereo+LiDAR. We demonstrate DSP-SLAM operating at almost frame rate on monocular-RGB sequences from the Friburg and Redwood-OS datasets, and on stereo+LiDAR sequences on the KITTI odometry dataset showing that it achieves high-quality full object reconstructions, even from partial observations, while maintaining a consistent global map. Our evaluation shows improvements in object pose and shape reconstruction with respect to recent deep prior-based reconstruction methods and reductions in camera tracking drift on the KITTI dataset.
Integrating Semantics and Neighborhood Information with Graph-Driven Generative Models for Document Retrieval
May 27, 2021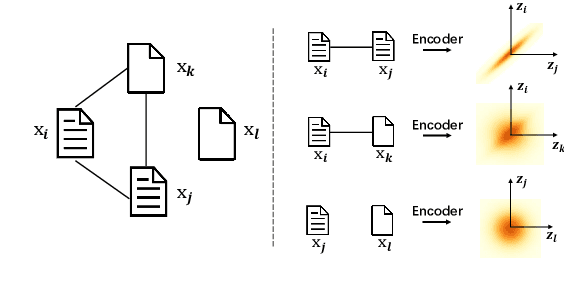
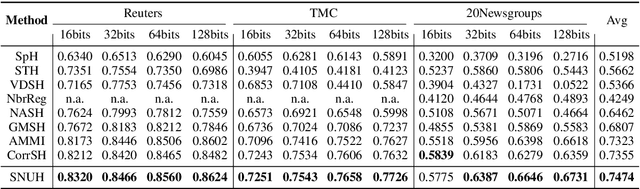
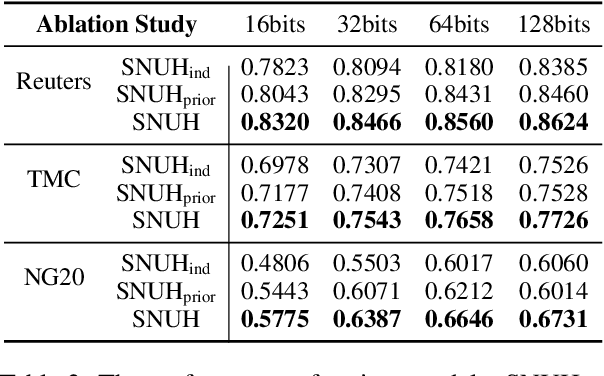
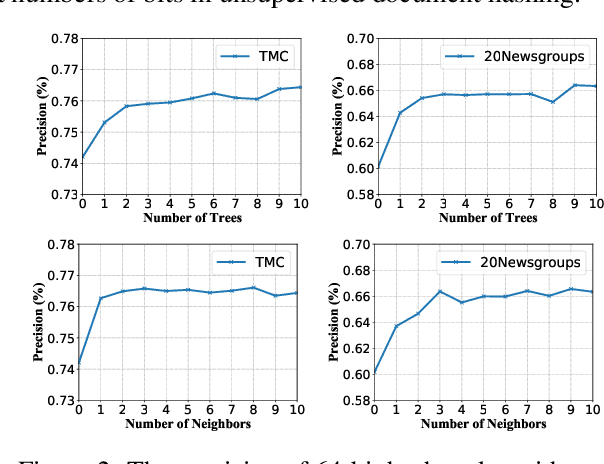
With the need of fast retrieval speed and small memory footprint, document hashing has been playing a crucial role in large-scale information retrieval. To generate high-quality hashing code, both semantics and neighborhood information are crucial. However, most existing methods leverage only one of them or simply combine them via some intuitive criteria, lacking a theoretical principle to guide the integration process. In this paper, we encode the neighborhood information with a graph-induced Gaussian distribution, and propose to integrate the two types of information with a graph-driven generative model. To deal with the complicated correlations among documents, we further propose a tree-structured approximation method for learning. Under the approximation, we prove that the training objective can be decomposed into terms involving only singleton or pairwise documents, enabling the model to be trained as efficiently as uncorrelated ones. Extensive experimental results on three benchmark datasets show that our method achieves superior performance over state-of-the-art methods, demonstrating the effectiveness of the proposed model for simultaneously preserving semantic and neighborhood information.\
Actor-Action Video Classification CSC 249/449 Spring 2020 Challenge Report
Aug 18, 2020
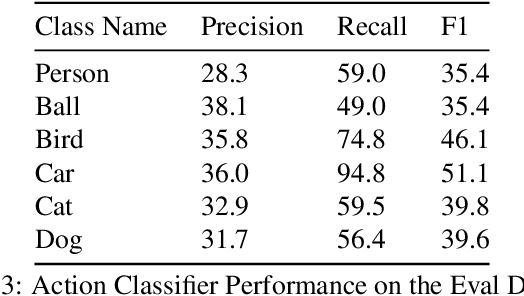
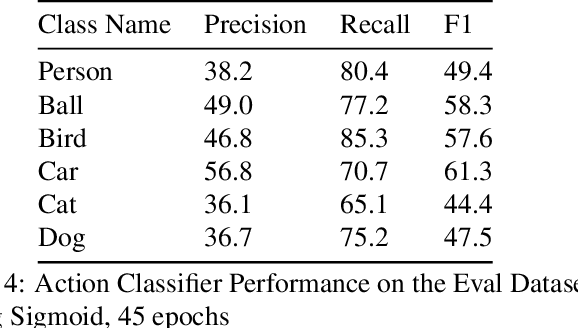
This technical report summarizes submissions and compiles from Actor-Action video classification challenge held as a final project in CSC 249/449 Machine Vision course (Spring 2020) at University of Rochester
Recurrent Exposure Generation for Low-Light Face Detection
Jul 21, 2020
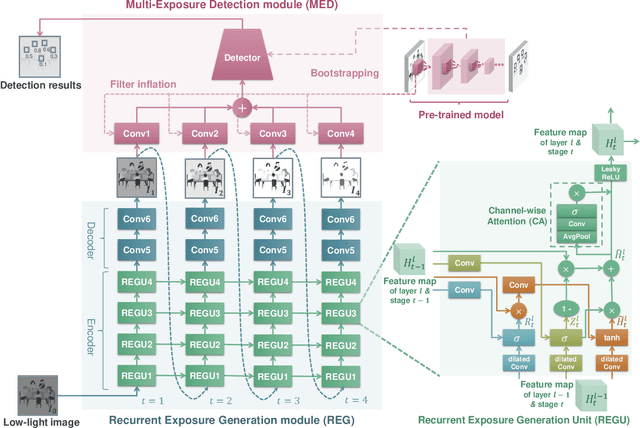
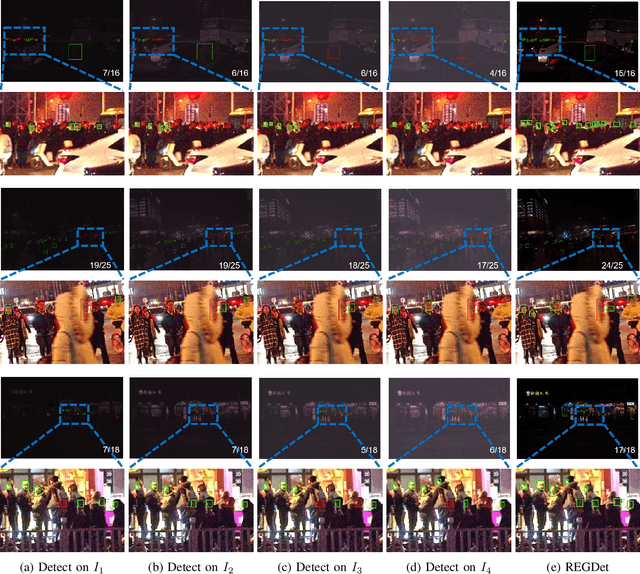
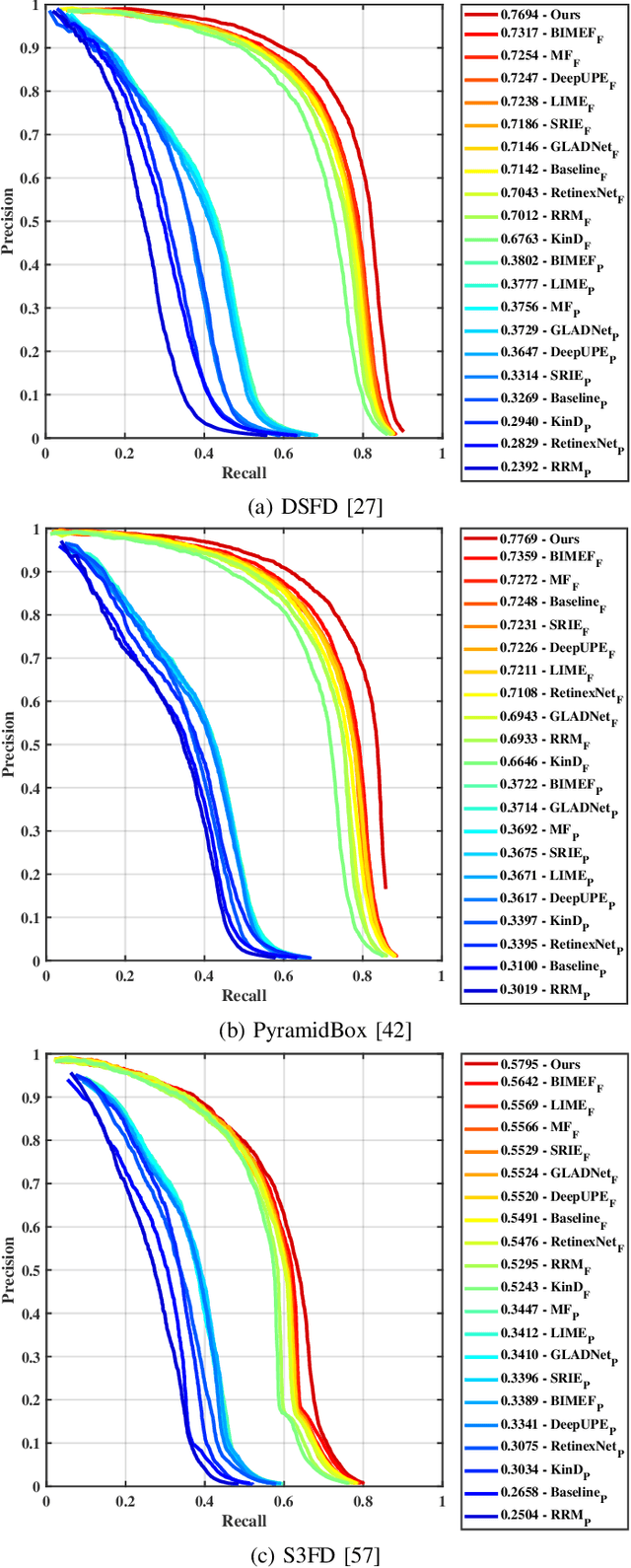
Face detection from low-light images is challenging due to limited photos and inevitable noise, which, to make the task even harder, are often spatially unevenly distributed. A natural solution is to borrow the idea from multi-exposure, which captures multiple shots to obtain well-exposed images under challenging conditions. High-quality implementation/approximation of multi-exposure from a single image is however nontrivial. Fortunately, as shown in this paper, neither is such high-quality necessary since our task is face detection rather than image enhancement. Specifically, we propose a novel Recurrent Exposure Generation (REG) module and couple it seamlessly with a Multi-Exposure Detection (MED) module, and thus significantly improve face detection performance by effectively inhibiting non-uniform illumination and noise issues. REG produces progressively and efficiently intermediate images corresponding to various exposure settings, and such pseudo-exposures are then fused by MED to detect faces across different lighting conditions. The proposed method, named REGDet, is the first `detection-with-enhancement' framework for low-light face detection. It not only encourages rich interaction and feature fusion across different illumination levels, but also enables effective end-to-end learning of the REG component to be better tailored for face detection. Moreover, as clearly shown in our experiments, REG can be flexibly coupled with different face detectors without extra low/normal-light image pairs for training. We tested REGDet on the DARK FACE low-light face benchmark with thorough ablation study, where REGDet outperforms previous state-of-the-arts by a significant margin, with only negligible extra parameters.
Deep Bilateral Retinex for Low-Light Image Enhancement
Jul 04, 2020

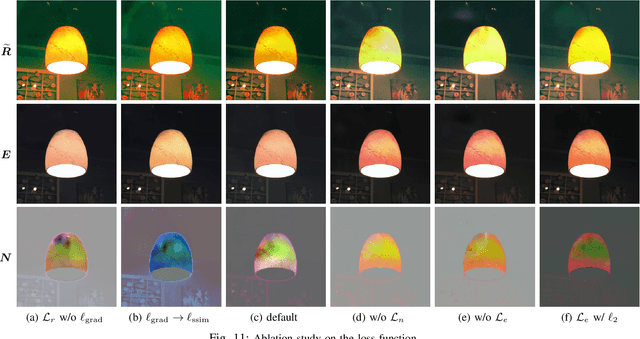
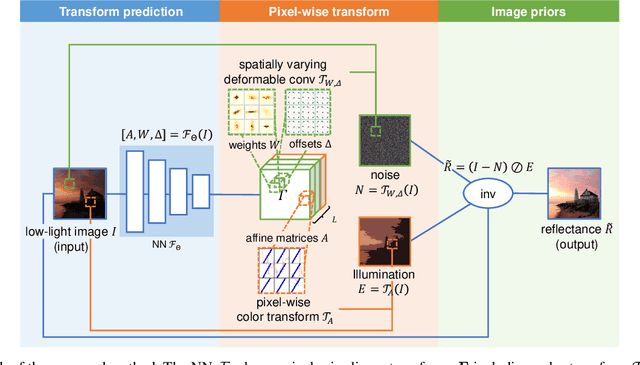
Low-light images, i.e. the images captured in low-light conditions, suffer from very poor visibility caused by low contrast, color distortion and significant measurement noise. Low-light image enhancement is about improving the visibility of low-light images. As the measurement noise in low-light images is usually significant yet complex with spatially-varying characteristic, how to handle the noise effectively is an important yet challenging problem in low-light image enhancement. Based on the Retinex decomposition of natural images, this paper proposes a deep learning method for low-light image enhancement with a particular focus on handling the measurement noise. The basic idea is to train a neural network to generate a set of pixel-wise operators for simultaneously predicting the noise and the illumination layer, where the operators are defined in the bilateral space. Such an integrated approach allows us to have an accurate prediction of the reflectance layer in the presence of significant spatially-varying measurement noise. Extensive experiments on several benchmark datasets have shown that the proposed method is very competitive to the state-of-the-art methods, and has significant advantage over others when processing images captured in extremely low lighting conditions.
STH: Spatio-Temporal Hybrid Convolution for Efficient Action Recognition
Mar 18, 2020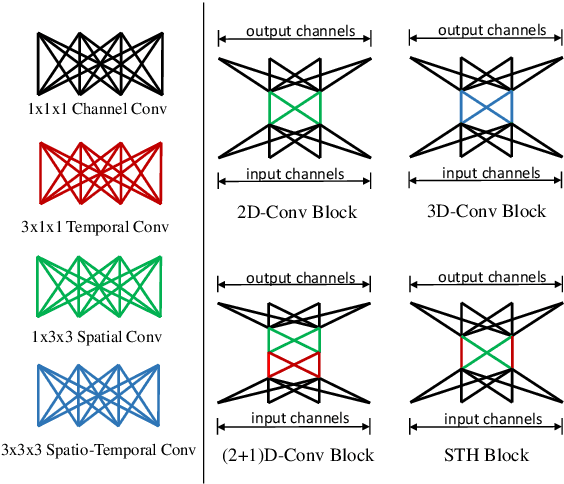
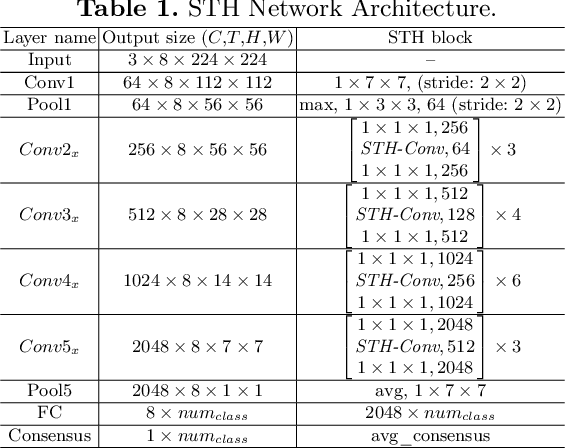
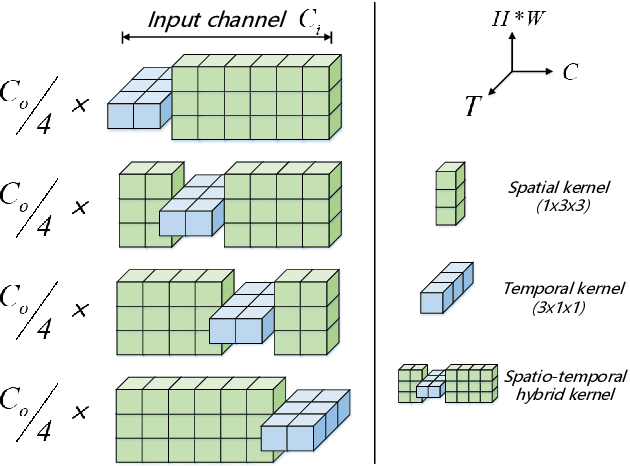
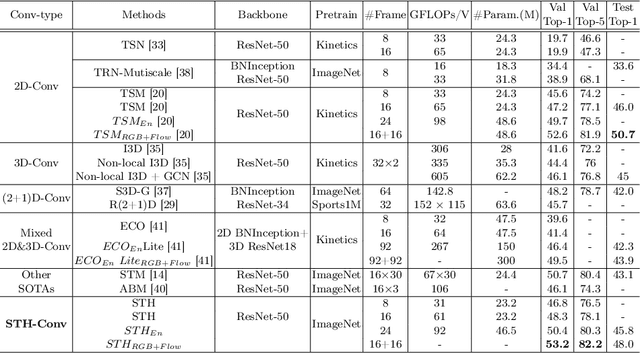
Effective and Efficient spatio-temporal modeling is essential for action recognition. Existing methods suffer from the trade-off between model performance and model complexity. In this paper, we present a novel Spatio-Temporal Hybrid Convolution Network (denoted as "STH") which simultaneously encodes spatial and temporal video information with a small parameter cost. Different from existing works that sequentially or parallelly extract spatial and temporal information with different convolutional layers, we divide the input channels into multiple groups and interleave the spatial and temporal operations in one convolutional layer, which deeply incorporates spatial and temporal clues. Such a design enables efficient spatio-temporal modeling and maintains a small model scale. STH-Conv is a general building block, which can be plugged into existing 2D CNN architectures such as ResNet and MobileNet by replacing the conventional 2D-Conv blocks (2D convolutions). STH network achieves competitive or even better performance than its competitors on benchmark datasets such as Something-Something (V1 & V2), Jester, and HMDB-51. Moreover, STH enjoys performance superiority over 3D CNNs while maintaining an even smaller parameter cost than 2D CNNs.
Weakly-Supervised Multi-Level Attentional Reconstruction Network for Grounding Textual Queries in Videos
Mar 16, 2020
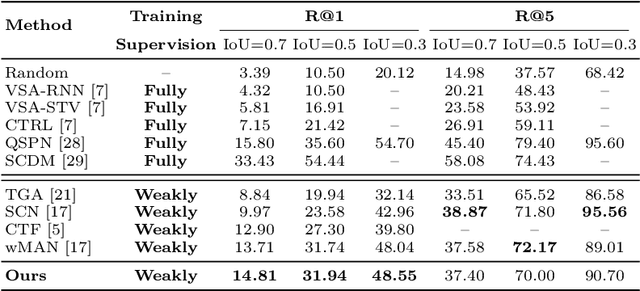
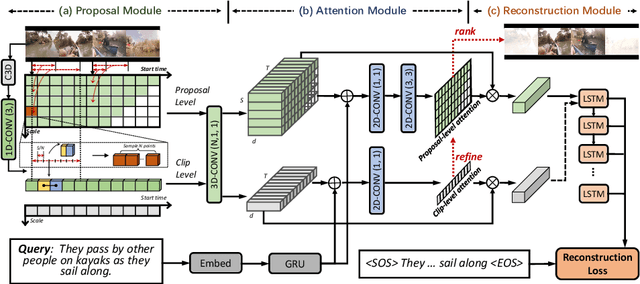
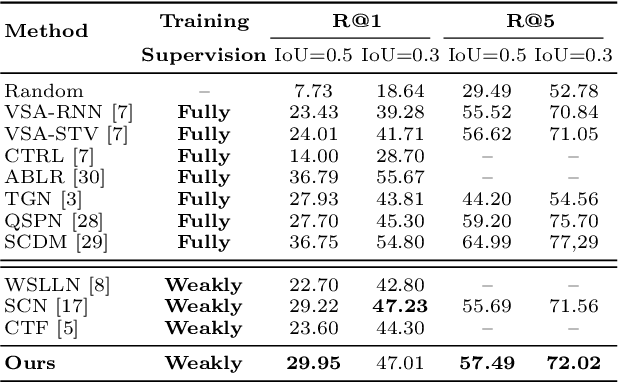
The task of temporally grounding textual queries in videos is to localize one video segment that semantically corresponds to the given query. Most of the existing approaches rely on segment-sentence pairs (temporal annotations) for training, which are usually unavailable in real-world scenarios. In this work we present an effective weakly-supervised model, named as Multi-Level Attentional Reconstruction Network (MARN), which only relies on video-sentence pairs during the training stage. The proposed method leverages the idea of attentional reconstruction and directly scores the candidate segments with the learnt proposal-level attentions. Moreover, another branch learning clip-level attention is exploited to refine the proposals at both the training and testing stage. We develop a novel proposal sampling mechanism to leverage intra-proposal information for learning better proposal representation and adopt 2D convolution to exploit inter-proposal clues for learning reliable attention map. Experiments on Charades-STA and ActivityNet-Captions datasets demonstrate the superiority of our MARN over the existing weakly-supervised methods.