 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingen Liu
Theme-Matters: Fashion Compatibility Learning via Theme Attention
Dec 12, 2019
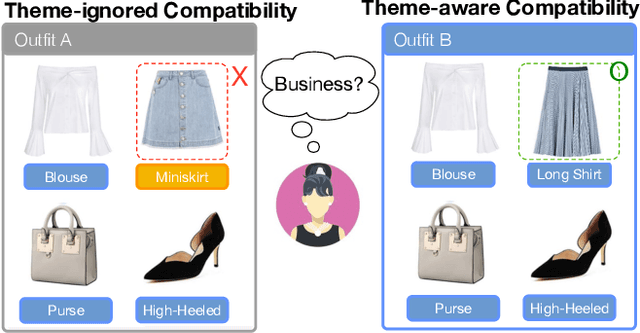
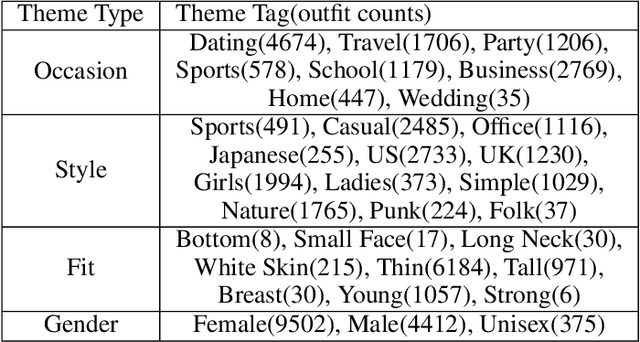
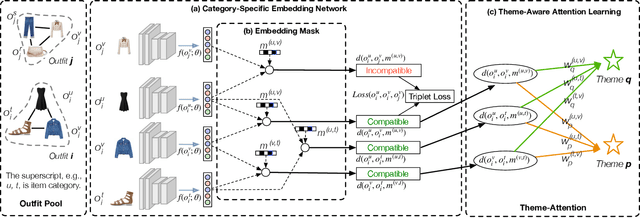
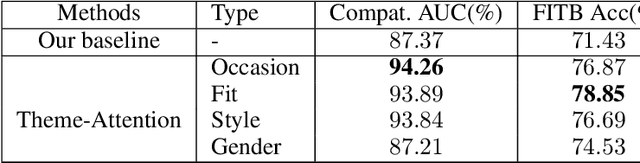
Fashion compatibility learning is important to many fashion markets such as outfit composition and online fashion recommendation. Unlike previous work, we argue that fashion compatibility is not only a visual appearance compatible problem but also a theme-matters problem. An outfit, which consists of a set of fashion items (e.g., shirt, suit, shoes, etc.), is considered to be compatible for a "dating" event, yet maybe not for a "business" occasion. In this paper, we aim at solving the fashion compatibility problem given specific themes. To this end, we built the first real-world theme-aware fashion dataset comprising 14K around outfits labeled with 32 themes. In this dataset, there are more than 40K fashion items labeled with 152 fine-grained categories. We also propose an attention model learning fashion compatibility given a specific theme. It starts with a category-specific subspace learning, which projects compatible outfit items in certain categories to be close in the subspace. Thanks to strong connections between fashion themes and categories, we then build a theme-attention model over the category-specific embedding space. This model associates themes with the pairwise compatibility with attention, and thus compute the outfit-wise compatibility. To the best of our knowledge, this is the first attempt to estimate outfit compatibility conditional on a theme. We conduct extensive qualitative and quantitative experiments on our new dataset. Our method outperforms the state-of-the-art approaches.
Customizable Architecture Search for Semantic Segmentation
Aug 26, 2019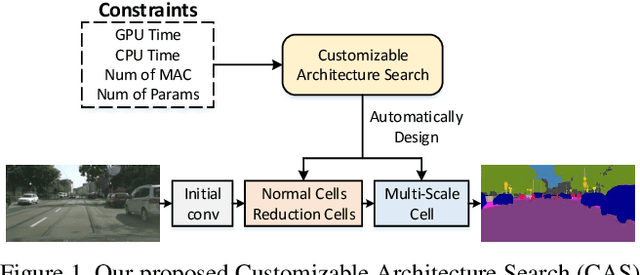
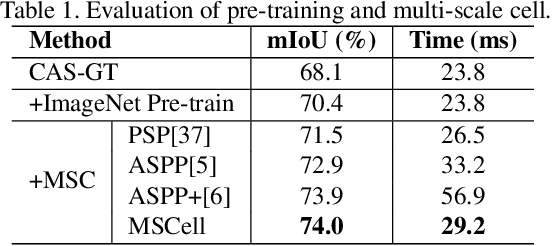
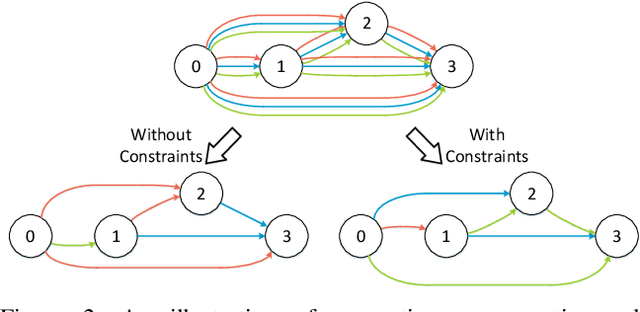
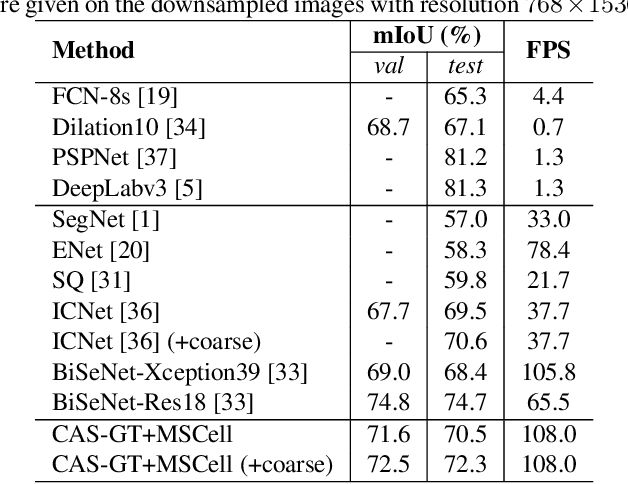
In this paper, we propose a Customizable Architecture Search (CAS) approach to automatically generate a network architecture for semantic image segmentation. The generated network consists of a sequence of stacked computation cells. A computation cell is represented as a directed acyclic graph, in which each node is a hidden representation (i.e., feature map) and each edge is associated with an operation (e.g., convolution and pooling), which transforms data to a new layer. During the training, the CAS algorithm explores the search space for an optimized computation cell to build a network. The cells of the same type share one architecture but with different weights. In real applications, however, an optimization may need to be conducted under some constraints such as GPU time and model size. To this end, a cost corresponding to the constraint will be assigned to each operation. When an operation is selected during the search, its associated cost will be added to the objective. As a result, our CAS is able to search an optimized architecture with customized constraints. The approach has been thoroughly evaluated on Cityscapes and CamVid datasets, and demonstrates superior performance over several state-of-the-art techniques. More remarkably, our CAS achieves 72.3% mIoU on the Cityscapes dataset with speed of 108 FPS on an Nvidia TitanXp GPU.
Zero-Shot Event Detection by Multimodal Distributional Semantic Embedding of Videos
Dec 16, 2015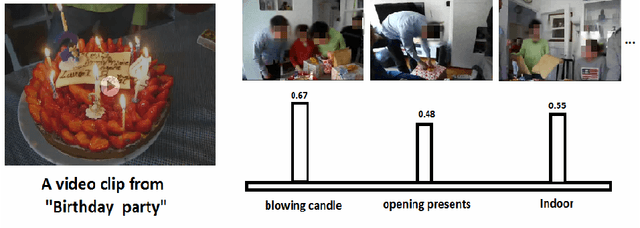

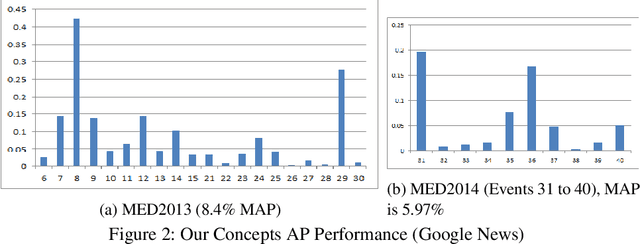

We propose a new zero-shot Event Detection method by Multi-modal Distributional Semantic embedding of videos. Our model embeds object and action concepts as well as other available modalities from videos into a distributional semantic space. To our knowledge, this is the first Zero-Shot event detection model that is built on top of distributional semantics and extends it in the following directions: (a) semantic embedding of multimodal information in videos (with focus on the visual modalities), (b) automatically determining relevance of concepts/attributes to a free text query, which could be useful for other applications, and (c) retrieving videos by free text event query (e.g., "changing a vehicle tire") based on their content. We embed videos into a distributional semantic space and then measure the similarity between videos and the event query in a free text form. We validated our method on the large TRECVID MED (Multimedia Event Detection) challenge. Using only the event title as a query, our method outperformed the state-of-the-art that uses big descriptions from 12.6% to 13.5% with MAP metric and 0.73 to 0.83 with ROC-AUC metric. It is also an order of magnitude faster.