 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Xiao
Variational Information Bottleneck for Effective Low-resource Audio Classification
Jul 10, 2021
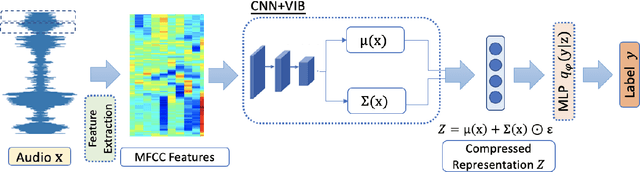
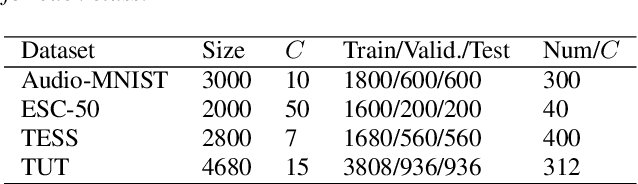

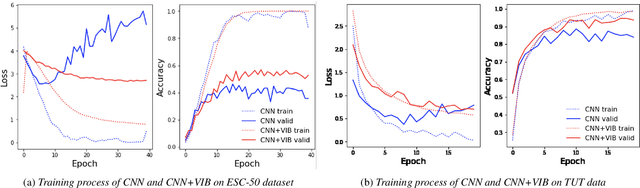
Large-scale deep neural networks (DNNs) such as convolutional neural networks (CNNs) have achieved impressive performance in audio classification for their powerful capacity and strong generalization ability. However, when training a DNN model on low-resource tasks, it is usually prone to overfitting the small data and learning too much redundant information. To address this issue, we propose to use variational information bottleneck (VIB) to mitigate overfitting and suppress irrelevant information. In this work, we conduct experiments ona 4-layer CNN. However, the VIB framework is ready-to-use and could be easily utilized with many other state-of-the-art network architectures. Evaluation on a few audio datasets shows that our approach significantly outperforms baseline methods, yielding more than 5.0% improvement in terms of classification accuracy in some low-source settings.
Loss Prediction: End-to-End Active Learning Approach For Speech Recognition
Jul 09, 2021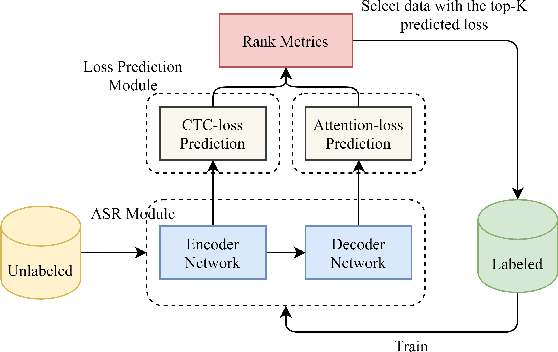
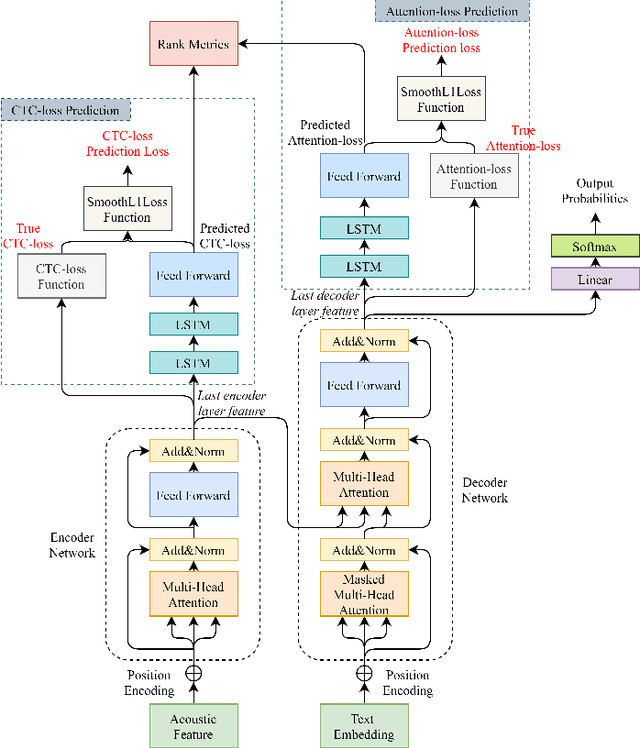
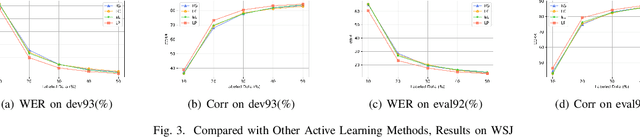

End-to-end speech recognition systems usually require huge amounts of labeling resource, while annotating the speech data is complicated and expensive. Active learning is the solution by selecting the most valuable samples for annotation. In this paper, we proposed to use a predicted loss that estimates the uncertainty of the sample. The CTC (Connectionist Temporal Classification) and attention loss are informative for speech recognition since they are computed based on all decoding paths and alignments. We defined an end-to-end active learning pipeline, training an ASR/LP (Automatic Speech Recognition/Loss Prediction) joint model. The proposed approach was validated on an English and a Chinese speech recognition task. The experiments show that our approach achieves competitive results, outperforming random selection, least confidence, and estimated loss method.
Dropout Regularization for Self-Supervised Learning of Transformer Encoder Speech Representation
Jul 09, 2021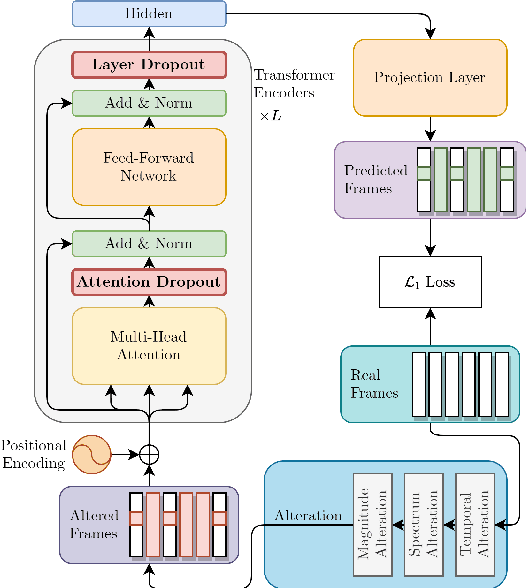
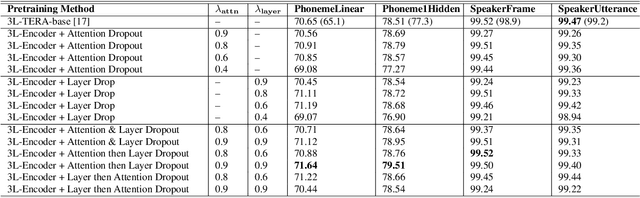

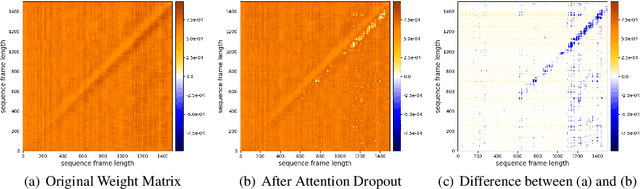
Predicting the altered acoustic frames is an effective way of self-supervised learning for speech representation. However, it is challenging to prevent the pretrained model from overfitting. In this paper, we proposed to introduce two dropout regularization methods into the pretraining of transformer encoder: (1) attention dropout, (2) layer dropout. Both of the two dropout methods encourage the model to utilize global speech information, and avoid just copying local spectrum features when reconstructing the masked frames. We evaluated the proposed methods on phoneme classification and speaker recognition tasks. The experiments demonstrate that our dropout approaches achieve competitive results, and improve the performance of classification accuracy on downstream tasks.
Federated Learning with Dynamic Transformer for Text to Speech
Jul 09, 2021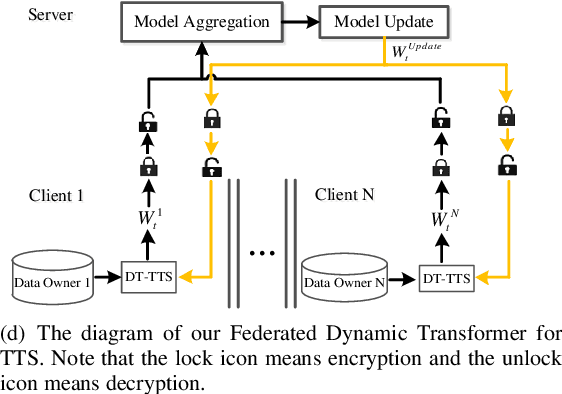

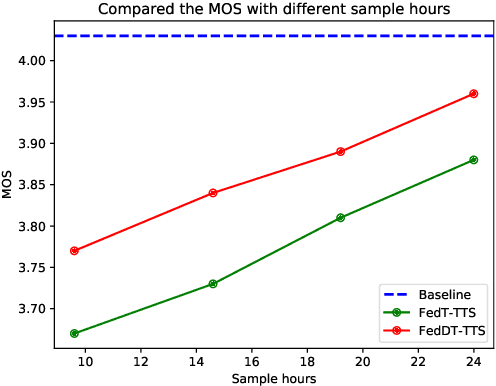
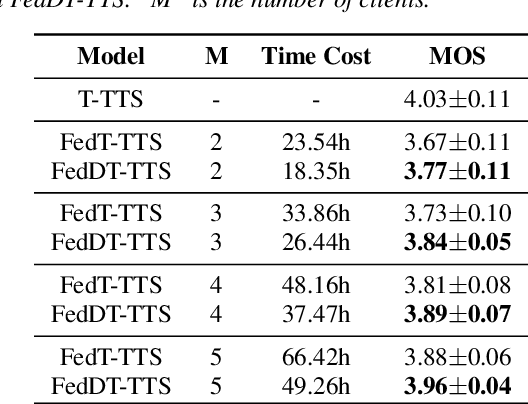
Text to speech (TTS) is a crucial task for user interaction, but TTS model training relies on a sizable set of high-quality original datasets. Due to privacy and security issues, the original datasets are usually unavailable directly. Recently, federated learning proposes a popular distributed machine learning paradigm with an enhanced privacy protection mechanism. It offers a practical and secure framework for data owners to collaborate with others, thus obtaining a better global model trained on the larger dataset. However, due to the high complexity of transformer models, the convergence process becomes slow and unstable in the federated learning setting. Besides, the transformer model trained in federated learning is costly communication and limited computational speed on clients, impeding its popularity. To deal with these challenges, we propose the federated dynamic transformer. On the one hand, the performance is greatly improved comparing with the federated transformer, approaching centralize-trained Transformer-TTS when increasing clients number. On the other hand, it achieves faster and more stable convergence in the training phase and significantly reduces communication time. Experiments on the LJSpeech dataset also strongly prove our method's advantage.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jun 18, 2021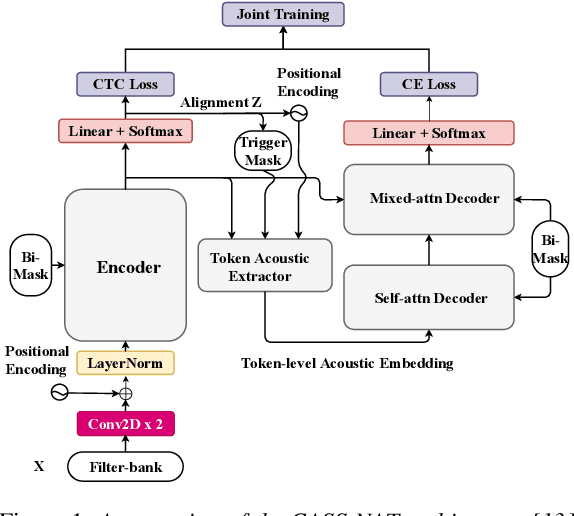
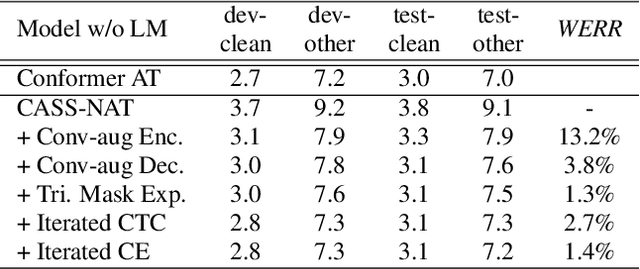
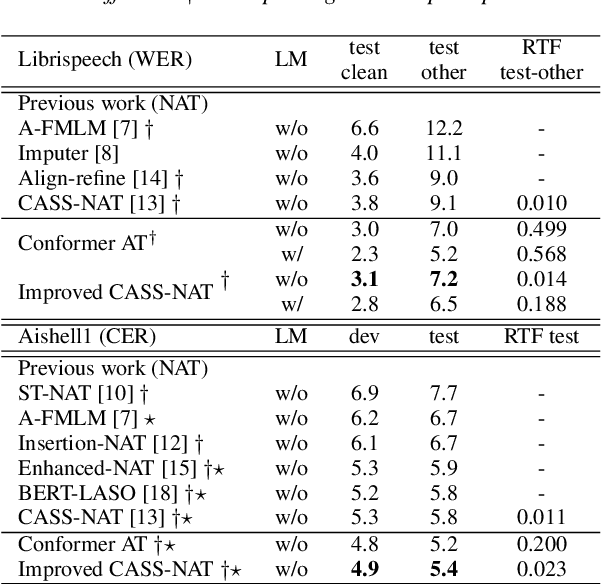
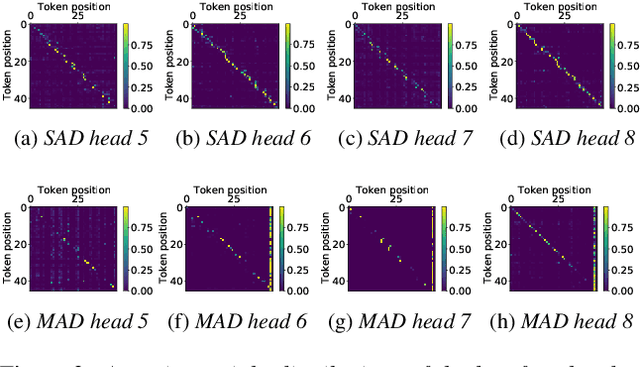
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
Lesion Segmentation and RECIST Diameter Prediction via Click-driven Attention and Dual-path Connection
May 05, 2021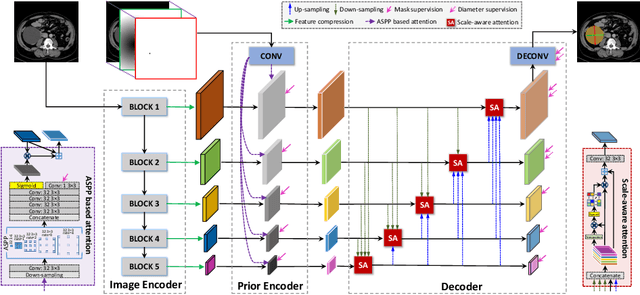
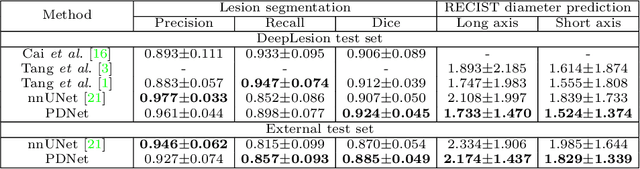
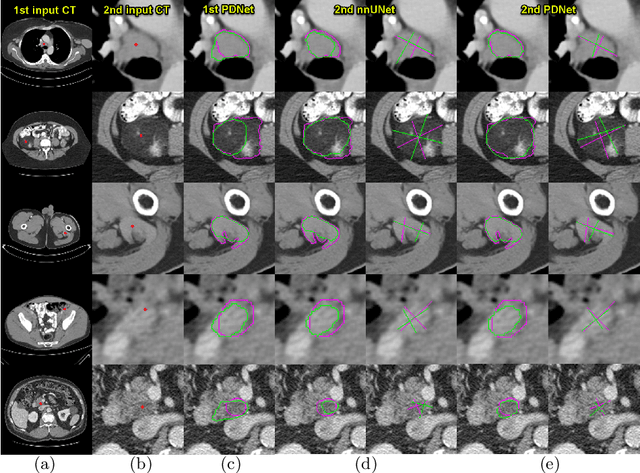
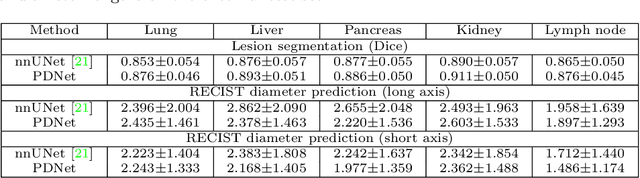
Measuring lesion size is an important step to assess tumor growth and monitor disease progression and therapy response in oncology image analysis. Although it is tedious and highly time-consuming, radiologists have to work on this task by using RECIST criteria (Response Evaluation Criteria In Solid Tumors) routinely and manually. Even though lesion segmentation may be the more accurate and clinically more valuable means, physicians can not manually segment lesions as now since much more heavy laboring will be required. In this paper, we present a prior-guided dual-path network (PDNet) to segment common types of lesions throughout the whole body and predict their RECIST diameters accurately and automatically. Similar to [1], a click guidance from radiologists is the only requirement. There are two key characteristics in PDNet: 1) Learning lesion-specific attention matrices in parallel from the click prior information by the proposed prior encoder, named click-driven attention; 2) Aggregating the extracted multi-scale features comprehensively by introducing top-down and bottom-up connections in the proposed decoder, named dual-path connection. Experiments show the superiority of our proposed PDNet in lesion segmentation and RECIST diameter prediction using the DeepLesion dataset and an external test set. PDNet learns comprehensive and representative deep image features for our tasks and produces more accurate results on both lesion segmentation and RECIST diameter prediction.
Weakly-Supervised Universal Lesion Segmentation with Regional Level Set Loss
May 03, 2021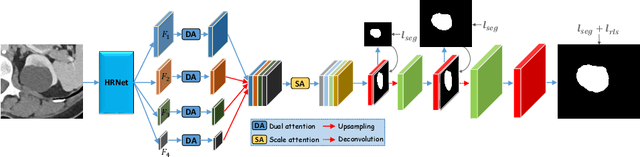
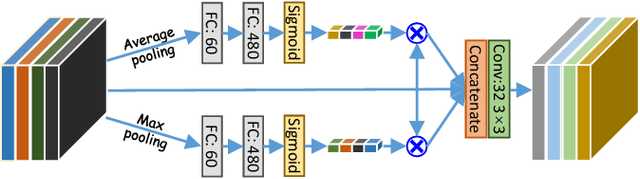
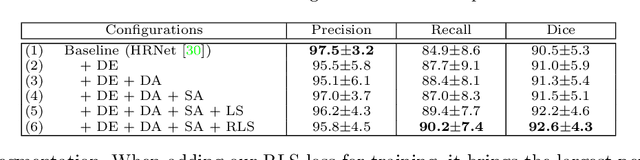
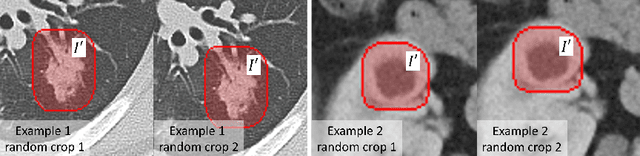
Accurately segmenting a variety of clinically significant lesions from whole body computed tomography (CT) scans is a critical task on precision oncology imaging, denoted as universal lesion segmentation (ULS). Manual annotation is the current clinical practice, being highly time-consuming and inconsistent on tumor's longitudinal assessment. Effectively training an automatic segmentation model is desirable but relies heavily on a large number of pixel-wise labelled data. Existing weakly-supervised segmentation approaches often struggle with regions nearby the lesion boundaries. In this paper, we present a novel weakly-supervised universal lesion segmentation method by building an attention enhanced model based on the High-Resolution Network (HRNet), named AHRNet, and propose a regional level set (RLS) loss for optimizing lesion boundary delineation. AHRNet provides advanced high-resolution deep image features by involving a decoder, dual-attention and scale attention mechanisms, which are crucial to performing accurate lesion segmentation. RLS can optimize the model reliably and effectively in a weakly-supervised fashion, forcing the segmentation close to lesion boundary. Extensive experimental results demonstrate that our method achieves the best performance on the publicly large-scale DeepLesion dataset and a hold-out test set.
Scalable Semi-supervised Landmark Localization for X-ray Images using Few-shot Deep Adaptive Graph
Apr 29, 2021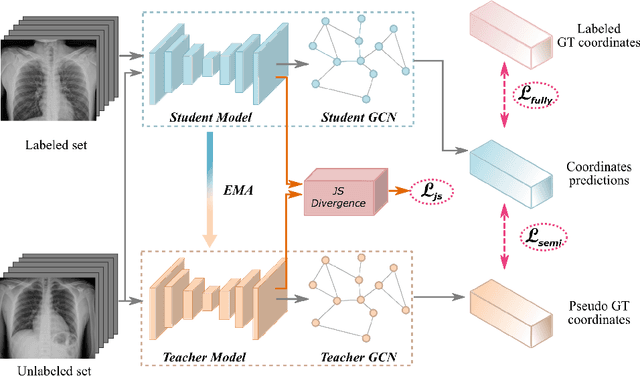
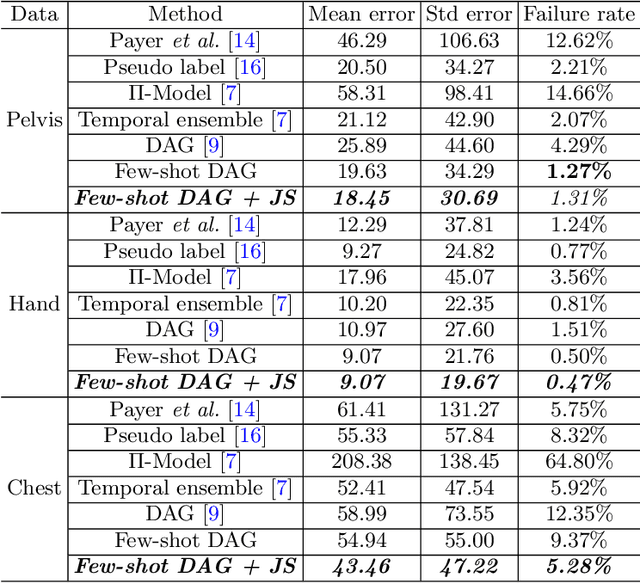
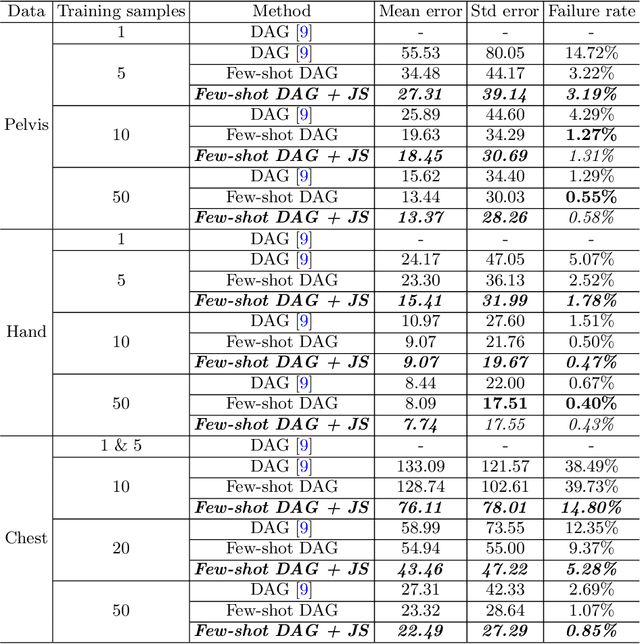
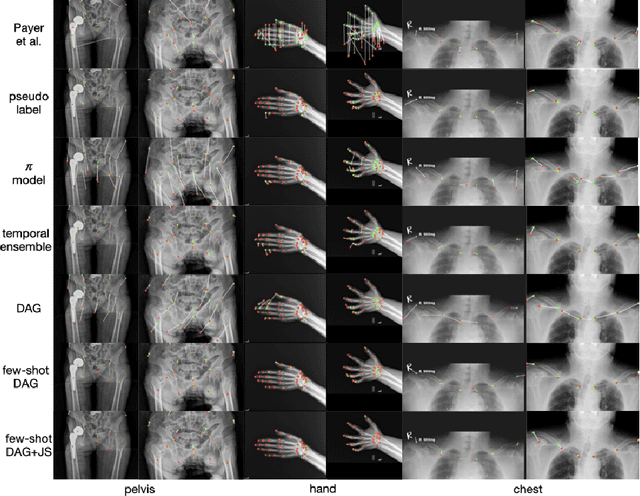
Landmark localization plays an important role in medical image analysis. Learning based methods, including CNN and GCN, have demonstrated the state-of-the-art performance. However, most of these methods are fully-supervised and heavily rely on manual labeling of a large training dataset. In this paper, based on a fully-supervised graph-based method, DAG, we proposed a semi-supervised extension of it, termed few-shot DAG, \ie five-shot DAG. It first trains a DAG model on the labeled data and then fine-tunes the pre-trained model on the unlabeled data with a teacher-student SSL mechanism. In addition to the semi-supervised loss, we propose another loss using JS divergence to regulate the consistency of the intermediate feature maps. We extensively evaluated our method on pelvis, hand and chest landmark detection tasks. Our experiment results demonstrate consistent and significant improvements over previous methods.
Learning from Subjective Ratings Using Auto-Decoded Deep Latent Embeddings
Apr 16, 2021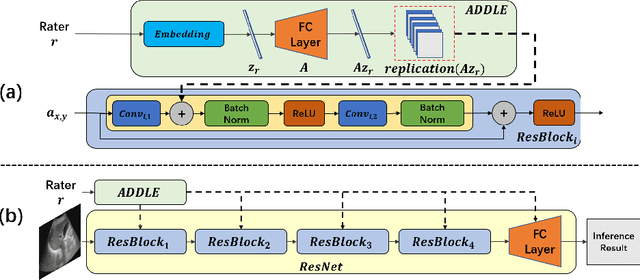
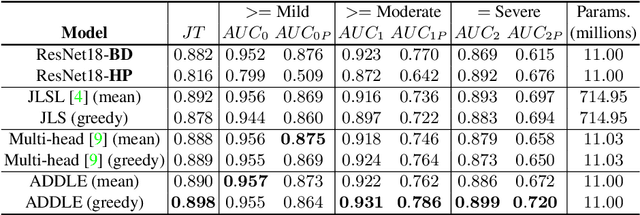
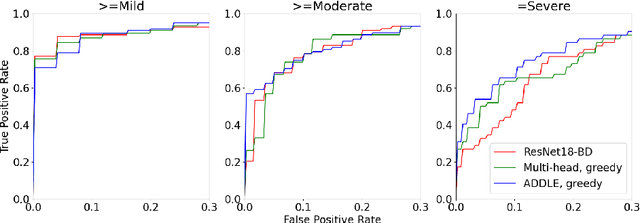
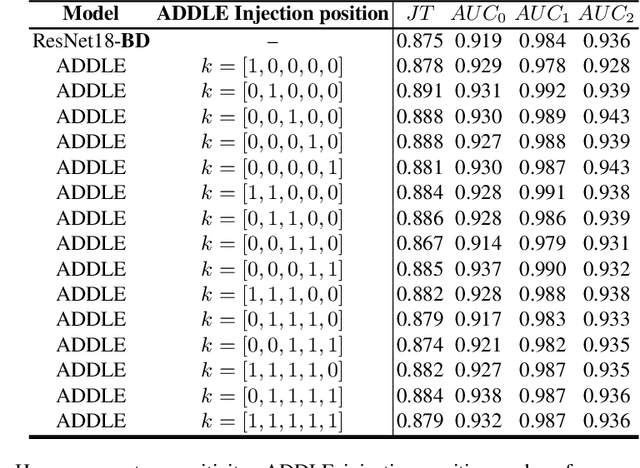
Depending on the application, radiological diagnoses can be associated with high inter- and intra-rater variabilities. Most computer-aided diagnosis (CAD) solutions treat such data as incontrovertible, exposing learning algorithms to considerable and possibly contradictory label noise and biases. Thus, managing subjectivity in labels is a fundamental problem in medical imaging analysis. To address this challenge, we introduce auto-decoded deep latent embeddings (ADDLE), which explicitly models the tendencies of each rater using an auto-decoder framework. After a simple linear transformation, the latent variables can be injected into any backbone at any and multiple points, allowing the model to account for rater-specific effects on the diagnosis. Importantly, ADDLE does not expect multiple raters per image in training, meaning it can readily learn from data mined from hospital archives. Moreover, the complexity of training ADDLE does not increase as more raters are added. During inference each rater can be simulated and a 'mean' or 'greedy' virtual rating can be produced. We test ADDLE on the problem of liver steatosis diagnosis from 2D ultrasound (US) by collecting 46 084 studies along with clinical US diagnoses originating from 65 different raters. We evaluated diagnostic performance using a separate dataset with gold-standard biopsy diagnoses. ADDLE can improve the partial areas under the curve (AUCs) for diagnosing severe steatosis by 10.5% over standard classifiers while outperforming other annotator-noise approaches, including those requiring 65 times the parameters.
An Alignment-Agnostic Model for Chinese Text Error Correction
Apr 15, 2021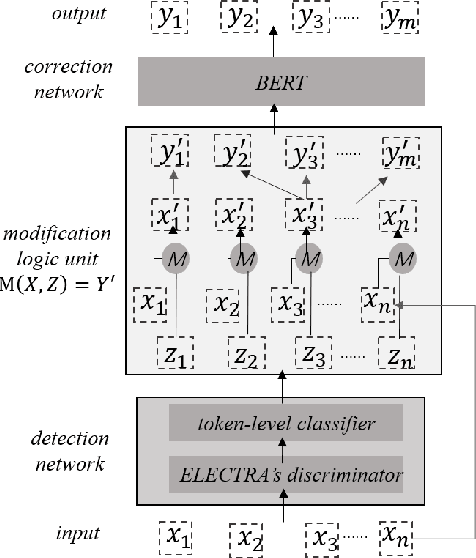
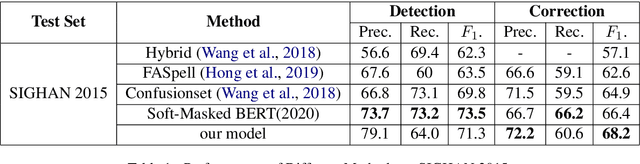
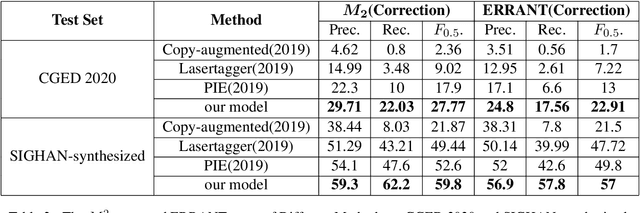
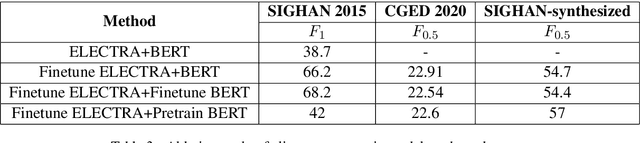
This paper investigates how to correct Chinese text errors with types of mistaken, missing and redundant characters, which is common for Chinese native speakers. Most existing models based on detect-correct framework can correct mistaken characters errors, but they cannot deal with missing or redundant characters. The reason is that lengths of sentences before and after correction are not the same, leading to the inconsistence between model inputs and outputs. Although the Seq2Seq-based or sequence tagging methods provide solutions to the problem and achieved relatively good results on English context, but they do not perform well in Chinese context according to our experimental results. In our work, we propose a novel detect-correct framework which is alignment-agnostic, meaning that it can handle both text aligned and non-aligned occasions, and it can also serve as a cold start model when there are no annotated data provided. Experimental results on three datasets demonstrate that our method is effective and achieves the best performance among existing published models.