 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Jiang
Improving Compositional Generalization in Math Word Problem Solving
Sep 03, 2022




Compositional generalization refers to a model's capability to generalize to newly composed input data based on the data components observed during training. It has triggered a series of compositional generalization analysis on different tasks as generalization is an important aspect of language and problem solving skills. However, the similar discussion on math word problems (MWPs) is limited. In this manuscript, we study compositional generalization in MWP solving. Specifically, we first introduce a data splitting method to create compositional splits from existing MWP datasets. Meanwhile, we synthesize data to isolate the effect of compositions. To improve the compositional generalization in MWP solving, we propose an iterative data augmentation method that includes diverse compositional variation into training data and could collaborate with MWP methods. During the evaluation, we examine a set of methods and find all of them encounter severe performance loss on the evaluated datasets. We also find our data augmentation method could significantly improve the compositional generalization of general MWP methods. Code is available at https://github.com/demoleiwang/CGMWP.
Disentangling Identity and Pose for Facial Expression Recognition
Aug 17, 2022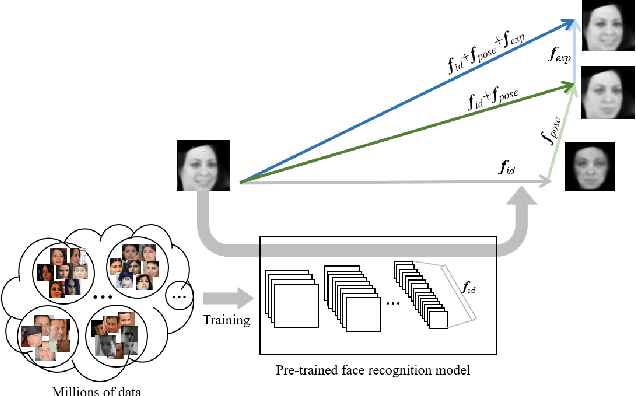

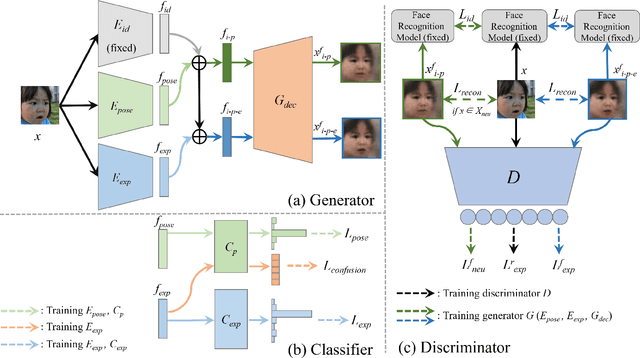
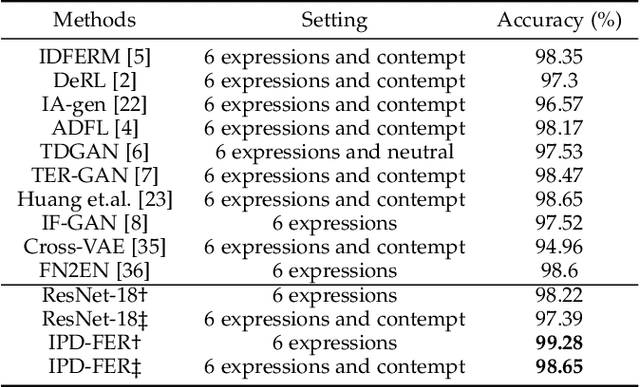
Facial expression recognition (FER) is a challenging problem because the expression component is always entangled with other irrelevant factors, such as identity and head pose. In this work, we propose an identity and pose disentangled facial expression recognition (IPD-FER) model to learn more discriminative feature representation. We regard the holistic facial representation as the combination of identity, pose and expression. These three components are encoded with different encoders. For identity encoder, a well pre-trained face recognition model is utilized and fixed during training, which alleviates the restriction on specific expression training data in previous works and makes the disentanglement practicable on in-the-wild datasets. At the same time, the pose and expression encoder are optimized with corresponding labels. Combining identity and pose feature, a neutral face of input individual should be generated by the decoder. When expression feature is added, the input image should be reconstructed. By comparing the difference between synthesized neutral and expressional images of the same individual, the expression component is further disentangled from identity and pose. Experimental results verify the effectiveness of our method on both lab-controlled and in-the-wild databases and we achieve state-of-the-art recognition performance.
Unsupervised Video Domain Adaptation: A Disentanglement Perspective
Aug 15, 2022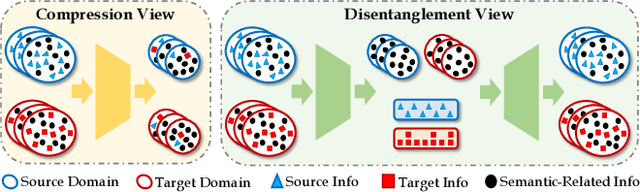
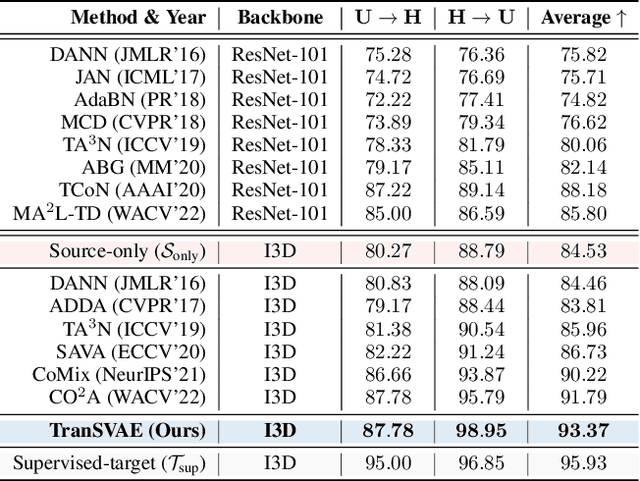
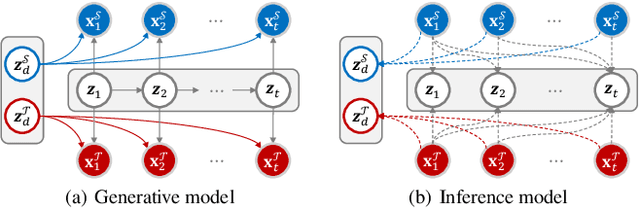
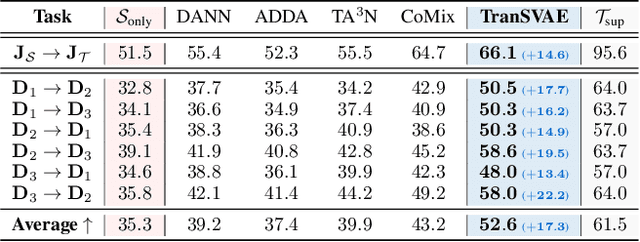
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view. Our key idea is to disentangle the domain-related information from the data during the adaptation process. Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information. A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods. Code is publicly available at https://github.com/ldkong1205/TranSVAE.
Boosting Facial Expression Recognition by A Semi-Supervised Progressive Teacher
May 28, 2022
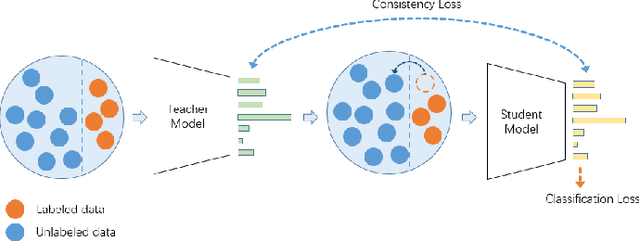

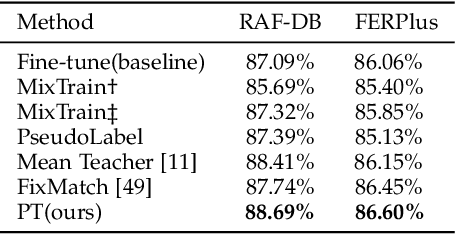
In this paper, we aim to improve the performance of in-the-wild Facial Expression Recognition (FER) by exploiting semi-supervised learning. Large-scale labeled data and deep learning methods have greatly improved the performance of image recognition. However, the performance of FER is still not ideal due to the lack of training data and incorrect annotations (e.g., label noises). Among existing in-the-wild FER datasets, reliable ones contain insufficient data to train robust deep models while large-scale ones are annotated in lower quality. To address this problem, we propose a semi-supervised learning algorithm named Progressive Teacher (PT) to utilize reliable FER datasets as well as large-scale unlabeled expression images for effective training. On the one hand, PT introduces semi-supervised learning method to relieve the shortage of data in FER. On the other hand, it selects useful labeled training samples automatically and progressively to alleviate label noise. PT uses selected clean labeled data for computing the supervised classification loss and unlabeled data for unsupervised consistency loss. Experiments on widely-used databases RAF-DB and FERPlus validate the effectiveness of our method, which achieves state-of-the-art performance with accuracy of 89.57% on RAF-DB. Additionally, when the synthetic noise rate reaches even 30%, the performance of our PT algorithm only degrades by 4.37%.
FedNoiL: A Simple Two-Level Sampling Method for Federated Learning with Noisy Labels
May 20, 2022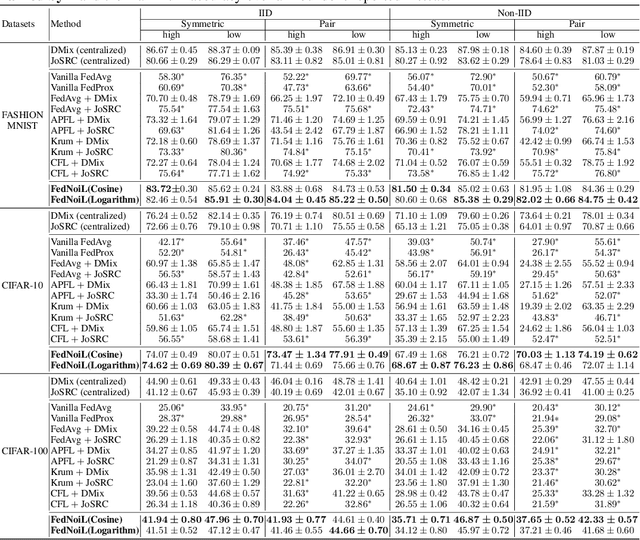
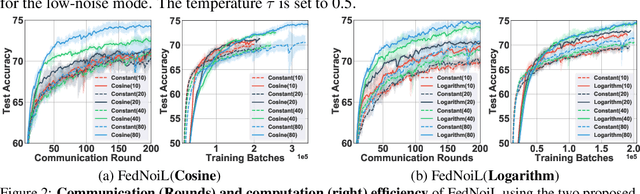
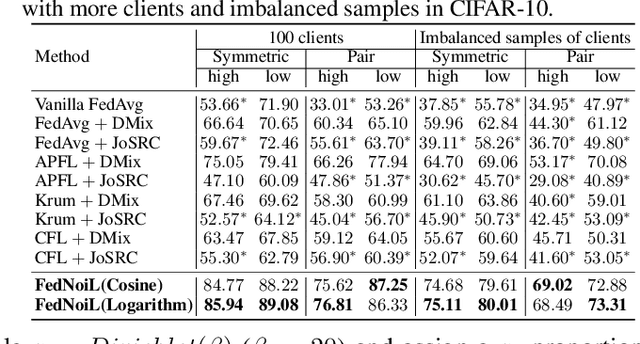
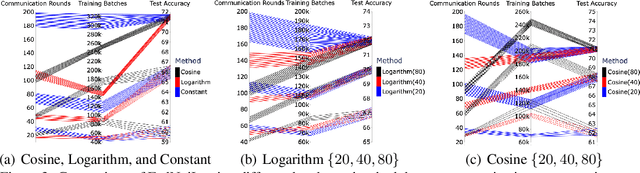
Federated learning (FL) aims at training a global model on the server side while the training data are collected and located at the local devices. Hence, the labels in practice are usually annotated by clients of varying expertise or criteria and thus contain different amounts of noises. Local training on noisy labels can easily result in overfitting to noisy labels, which is devastating to the global model through aggregation. Although recent robust FL methods take malicious clients into account, they have not addressed local noisy labels on each device and the impact to the global model. In this paper, we develop a simple two-level sampling method "FedNoiL" that (1) selects clients for more robust global aggregation on the server; and (2) selects clean labels and correct pseudo-labels at the client end for more robust local training. The sampling probabilities are built upon clean label detection by the global model. Moreover, we investigate different schedules changing the local epochs between aggregations over the course of FL, which notably improves the communication and computation efficiency in noisy label setting. In experiments with homogeneous/heterogeneous data distributions and noise ratios, we observed that direct combinations of SOTA FL methods with SOTA noisy-label learning methods can easily fail but our method consistently achieves better and robust performance.
Joint Trajectory Design and User Scheduling of Aerial Cognitive Radio Networks
Apr 21, 2022



Unmanned aerial vehicles (UAVs) have been widely employed to enhance the end-to-end performance of wireless communications since the links between UAVs and terrestrial nodes are line-of-sight (LoS) with high probability. However, the broadcast characteristics of signal propagation in LoS links make it vulnerable to being wiretapped by malicious eavesdroppers, which poses a considerable challenge to the security of wireless communications. This paper investigates the security of aerial cognitive radio networks (CRNs). An airborne base station transmits confidential messages to secondary users utilizing the same spectrum as the primary network. An aerial base station transmits jamming signals to suppress the eavesdropper to enhance secrecy performance. The uncertainty of eavesdropping node locations is considered, and the average secrecy rate of the cognitive user is maximized by optimizing multiple users' scheduling, the UAVs' trajectory, and transmit power. To solve the non-convex optimization problem with mixed multiple integers variable problem, we propose an iterative algorithm based on block coordinate descent and successive convex approximation. Numerical results verify the effectiveness of our proposed algorithm and demonstrate that our scheme is beneficial to improving the secrecy performance of aerial CRNs.
An Empirical Study of Memorization in NLP
Mar 23, 2022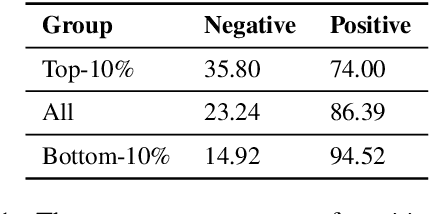
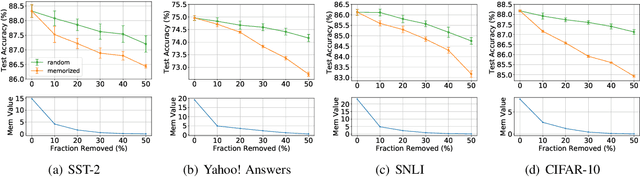
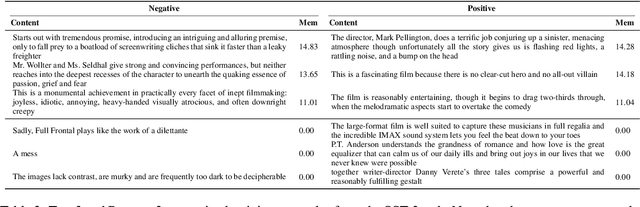
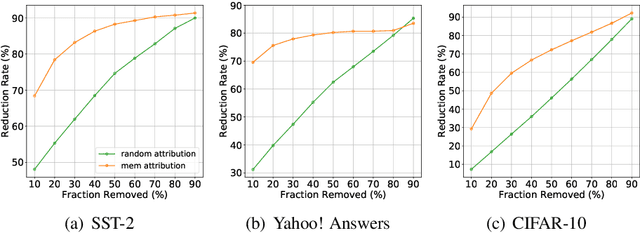
A recent study by Feldman (2020) proposed a long-tail theory to explain the memorization behavior of deep learning models. However, memorization has not been empirically verified in the context of NLP, a gap addressed by this work. In this paper, we use three different NLP tasks to check if the long-tail theory holds. Our experiments demonstrate that top-ranked memorized training instances are likely atypical, and removing the top-memorized training instances leads to a more serious drop in test accuracy compared with removing training instances randomly. Furthermore, we develop an attribution method to better understand why a training instance is memorized. We empirically show that our memorization attribution method is faithful, and share our interesting finding that the top-memorized parts of a training instance tend to be features negatively correlated with the class label.
Personalized Federated Learning With Structure
Mar 08, 2022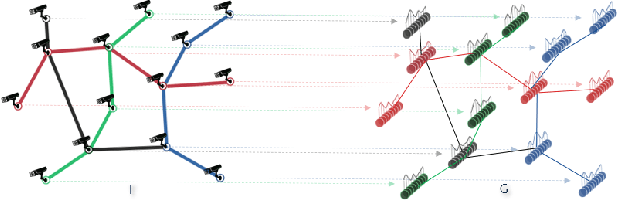

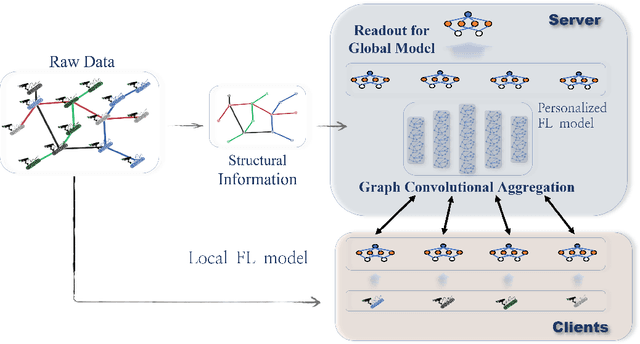
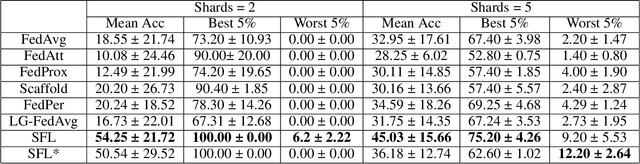
Knowledge sharing and model personalization are two key components to impact the performance of personalized federated learning (PFL). Existing PFL methods simply treat knowledge sharing as an aggregation of all clients regardless of the hidden relations among them. This paper is to enhance the knowledge-sharing process in PFL by leveraging the structural information among clients. We propose a novel structured federated learning(SFL) framework to simultaneously learn the global model and personalized model using each client's local relations with others and its private dataset. This proposed framework has been formulated to a new optimization problem to model the complex relationship among personalized models and structural topology information into a unified framework. Moreover, in contrast to a pre-defined structure, our framework could be further enhanced by adding a structure learning component to automatically learn the structure using the similarities between clients' models' parameters. By conducting extensive experiments, we first demonstrate how federated learning can be benefited by introducing structural information into the server aggregation process with a real-world dataset, and then the effectiveness of the proposed method has been demonstrated in varying degrees of data non-iid settings.
Exploring and Adapting Chinese GPT to Pinyin Input Method
Mar 02, 2022
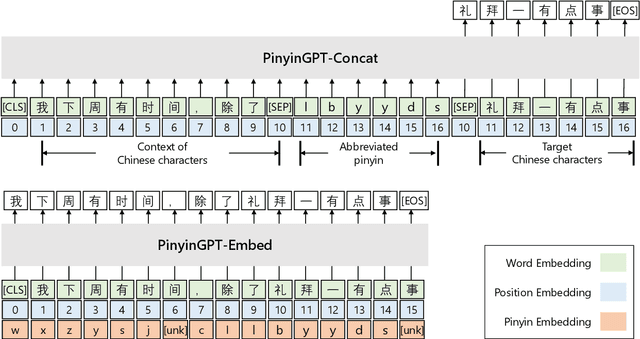

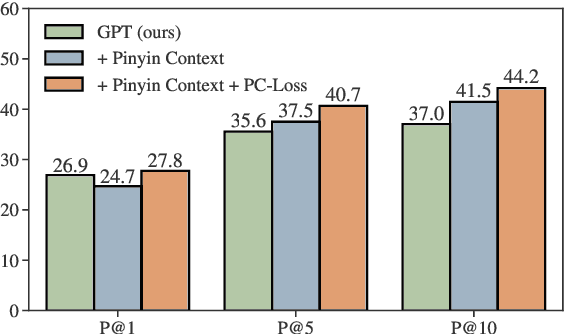
While GPT has become the de-facto method for text generation tasks, its application to pinyin input method remains unexplored. In this work, we make the first exploration to leverage Chinese GPT for pinyin input method. We find that a frozen GPT achieves state-of-the-art performance on perfect pinyin. However, the performance drops dramatically when the input includes abbreviated pinyin. A reason is that an abbreviated pinyin can be mapped to many perfect pinyin, which links to even larger number of Chinese characters. We mitigate this issue with two strategies, including enriching the context with pinyin and optimizing the training process to help distinguish homophones. To further facilitate the evaluation of pinyin input method, we create a dataset consisting of 270K instances from 15 domains. Results show that our approach improves performance on abbreviated pinyin across all domains. Model analysis demonstrates that both strategies contribute to the performance boost.
Applications of blockchain and artificial intelligence technologies for enabling prosumers in smart grids: A review
Feb 21, 2022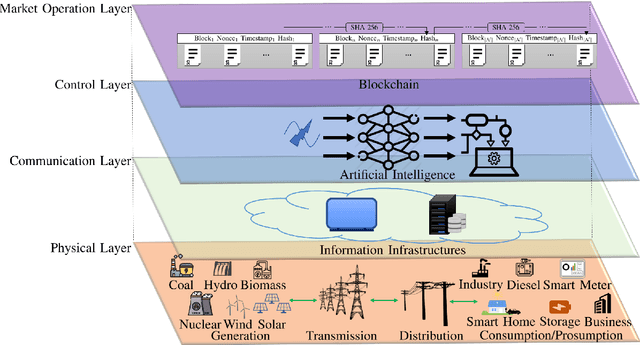

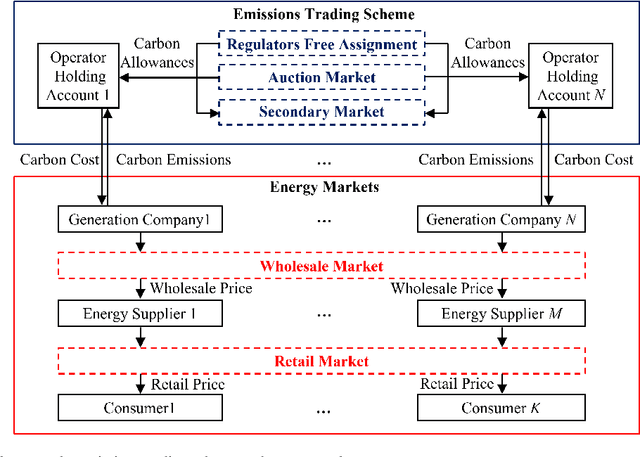
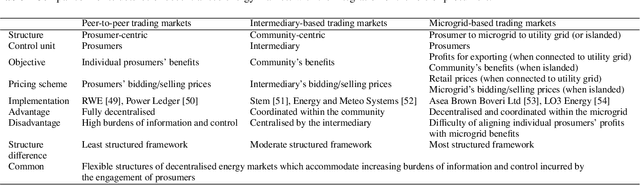
Governments' net zero emission target aims at increasing the share of renewable energy sources as well as influencing the behaviours of consumers to support the cost-effective balancing of energy supply and demand. These will be achieved by the advanced information and control infrastructures of smart grids which allow the interoperability among various stakeholders. Under this circumstance, increasing number of consumers produce, store, and consume energy, giving them a new role of prosumers. The integration of prosumers and accommodation of incurred bidirectional flows of energy and information rely on two key factors: flexible structures of energy markets and intelligent operations of power systems. The blockchain and artificial intelligence (AI) are innovative technologies to fulfil these two factors, by which the blockchain provides decentralised trading platforms for energy markets and the AI supports the optimal operational control of power systems. This paper attempts to address how to incorporate the blockchain and AI in the smart grids for facilitating prosumers to participate in energy markets. To achieve this objective, first, this paper reviews how policy designs price carbon emissions caused by the fossil-fuel based generation so as to facilitate the integration of prosumers with renewable energy sources. Second, the potential structures of energy markets with the support of the blockchain technologies are discussed. Last, how to apply the AI for enhancing the state monitoring and decision making during the operations of power systems is introduced.
* Accepted by Renewable & Sustainable Energy Reviews on 21 Feb 2022