 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Chen
DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
Mar 17, 2023
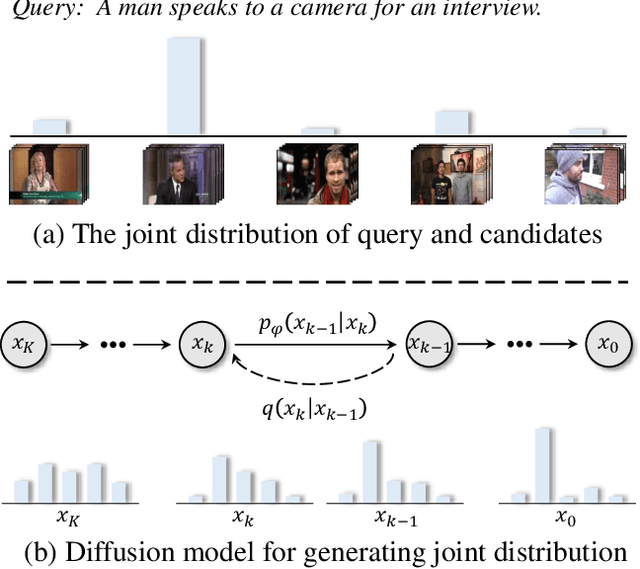
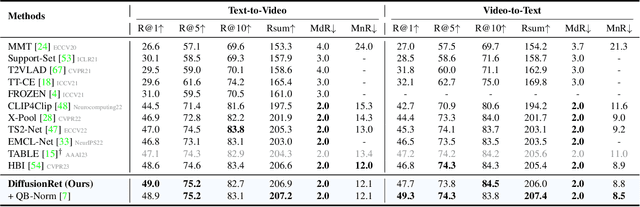
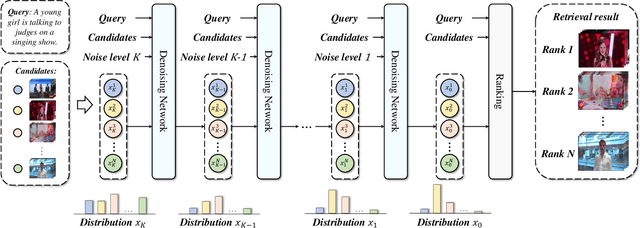
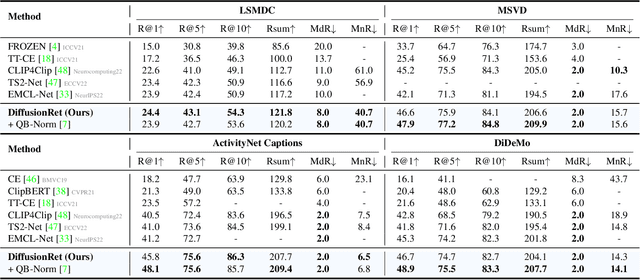
Existing text-video retrieval solutions are, in essence, discriminant models focused on maximizing the conditional likelihood, i.e., p(candidates|query). While straightforward, this de facto paradigm overlooks the underlying data distribution p(query), which makes it challenging to identify out-of-distribution data. To address this limitation, we creatively tackle this task from a generative viewpoint and model the correlation between the text and the video as their joint probability p(candidates,query). This is accomplished through a diffusion-based text-video retrieval framework (DiffusionRet), which models the retrieval task as a process of gradually generating joint distribution from noise. During training, DiffusionRet is optimized from both the generation and discrimination perspectives, with the generator being optimized by generation loss and the feature extractor trained with contrastive loss. In this way, DiffusionRet cleverly leverages the strengths of both generative and discriminative methods. Extensive experiments on five commonly used text-video retrieval benchmarks, including MSRVTT, LSMDC, MSVD, ActivityNet Captions, and DiDeMo, with superior performances, justify the efficacy of our method. More encouragingly, without any modification, DiffusionRet even performs well in out-domain retrieval settings. We believe this work brings fundamental insights into the related fields. Code will be available at https://github.com/jpthu17/DiffusionRet.
GLASU: A Communication-Efficient Algorithm for Federated Learning with Vertically Distributed Graph Data
Mar 16, 2023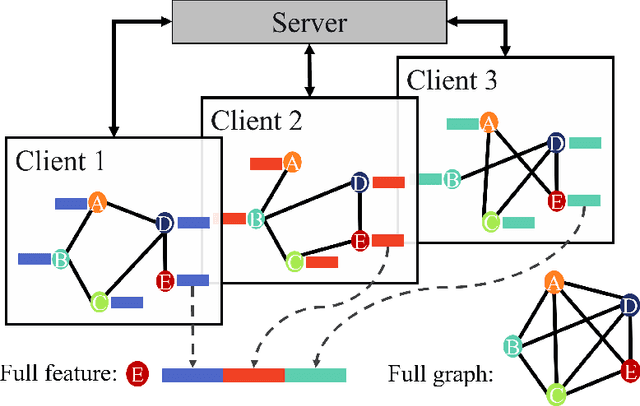
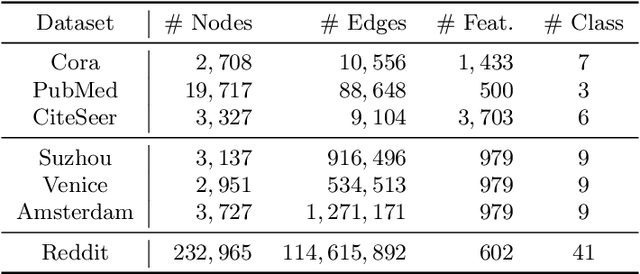
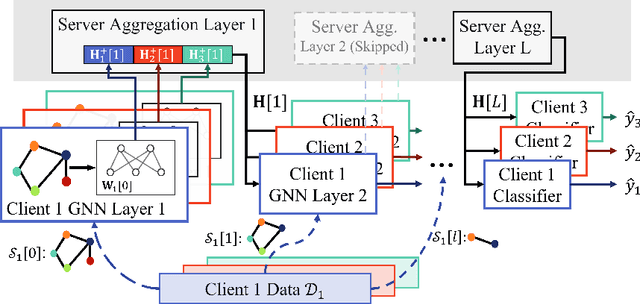
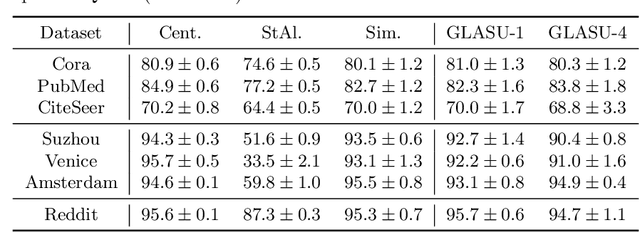
Vertical federated learning (VFL) is a distributed learning paradigm, where computing clients collectively train a model based on the partial features of the same set of samples they possess. Current research on VFL focuses on the case when samples are independent, but it rarely addresses an emerging scenario when samples are interrelated through a graph. For graph-structured data, graph neural networks (GNNs) are competitive machine learning models, but a naive implementation in the VFL setting causes a significant communication overhead. Moreover, the analysis of the training is faced with a challenge caused by the biased stochastic gradients. In this paper, we propose a model splitting method that splits a backbone GNN across the clients and the server and a communication-efficient algorithm, GLASU, to train such a model. GLASU adopts lazy aggregation and stale updates to skip aggregation when evaluating the model and skip feature exchanges during training, greatly reducing communication. We offer a theoretical analysis and conduct extensive numerical experiments on real-world datasets, showing that the proposed algorithm effectively trains a GNN model, whose performance matches that of the backbone GNN when trained in a centralized manner.
Nonlinear Hyperspectral Unmixing based on Multilinear Mixing Model using Convolutional Autoencoders
Mar 14, 2023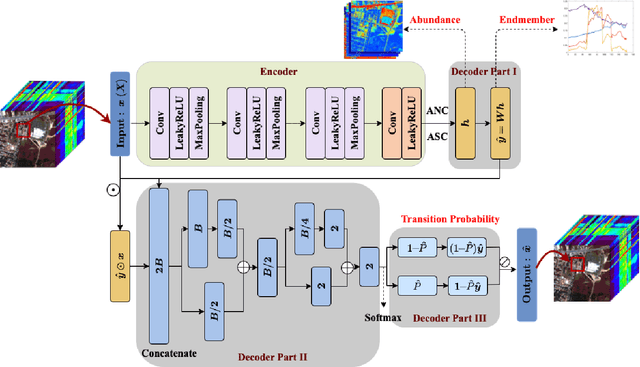
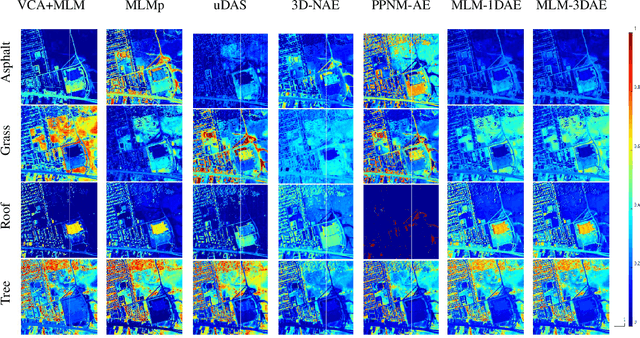
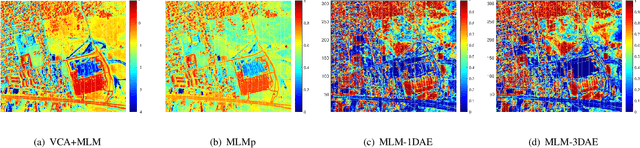
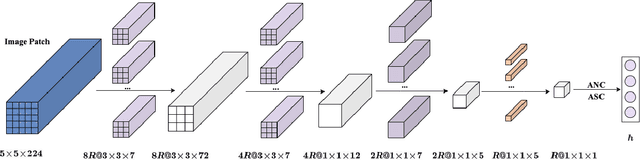
Unsupervised spectral unmixing consists of representing each observed pixel as a combination of several pure materials called endmembers with their corresponding abundance fractions. Beyond the linear assumption, various nonlinear unmixing models have been proposed, with the associated optimization problems solved either by traditional optimization algorithms or deep learning techniques. Current deep learning-based nonlinear unmixing focuses on the models in additive, bilinear-based formulations. By interpreting the reflection process using the discrete Markov chain, the multilinear mixing model (MLM) successfully accounts for the up to infinite-order interactions between endmembers. However, to simulate the physics process of MLM by neural networks explicitly is a challenging problem that has not been approached by far. In this article, we propose a novel autoencoder-based network for unsupervised unmixing based on MLM. Benefitting from an elaborate network design, the relationships among all the model parameters {\em i.e.}, endmembers, abundances, and transition probability parameters are explicitly modeled. There are two modes: MLM-1DAE considers only pixel-wise spectral information, and MLM-3DAE exploits the spectral-spatial correlations within input patches. Experiments on both the synthetic and real datasets demonstrate the effectiveness of the proposed method as it achieves competitive performance to the classic solutions of MLM.
Parallel Vertex Diffusion for Unified Visual Grounding
Mar 14, 2023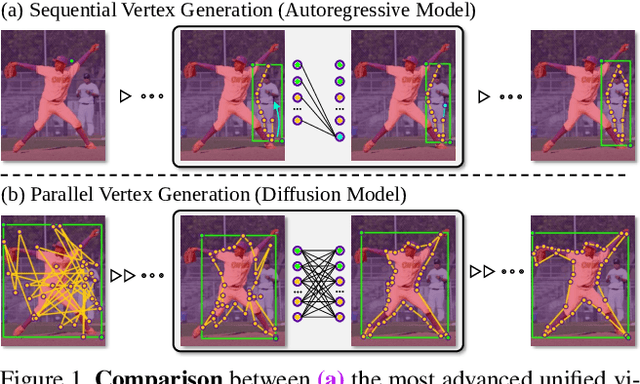
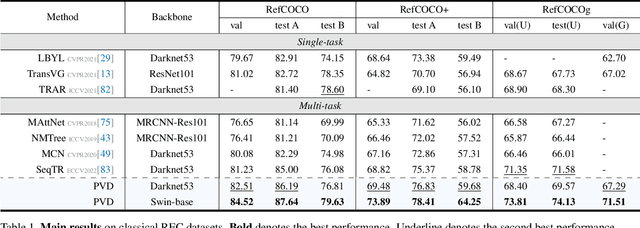

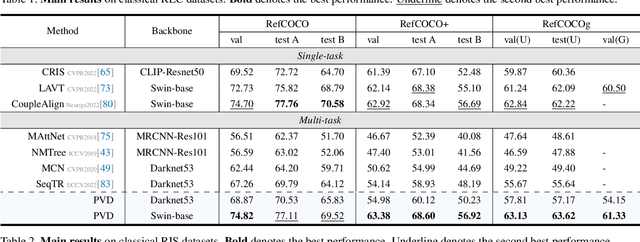
Unified visual grounding pursues a simple and generic technical route to leverage multi-task data with less task-specific design. The most advanced methods typically present boxes and masks as vertex sequences to model referring detection and segmentation as an autoregressive sequential vertex generation paradigm. However, generating high-dimensional vertex sequences sequentially is error-prone because the upstream of the sequence remains static and cannot be refined based on downstream vertex information, even if there is a significant location gap. Besides, with limited vertexes, the inferior fitting of objects with complex contours restricts the performance upper bound. To deal with this dilemma, we propose a parallel vertex generation paradigm for superior high-dimension scalability with a diffusion model by simply modifying the noise dimension. An intuitive materialization of our paradigm is Parallel Vertex Diffusion (PVD) to directly set vertex coordinates as the generation target and use a diffusion model to train and infer. We claim that it has two flaws: (1) unnormalized coordinate caused a high variance of loss value; (2) the original training objective of PVD only considers point consistency but ignores geometry consistency. To solve the first flaw, Center Anchor Mechanism (CAM) is designed to convert coordinates as normalized offset values to stabilize the training loss value. For the second flaw, Angle summation loss (ASL) is designed to constrain the geometry difference of prediction and ground truth vertexes for geometry-level consistency. Empirical results show that our PVD achieves state-of-the-art in both referring detection and segmentation, and our paradigm is more scalable and efficient than sequential vertex generation with high-dimension data.
Mastering Strategy Card Game (Hearthstone) with Improved Techniques
Mar 09, 2023
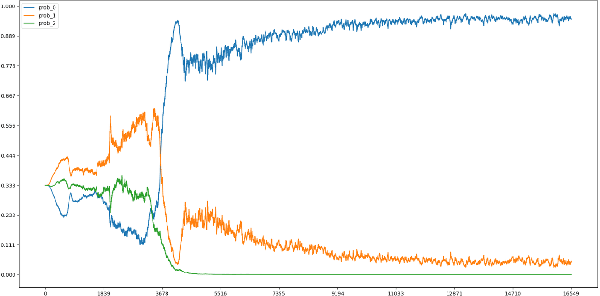
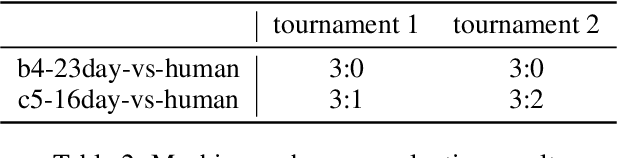
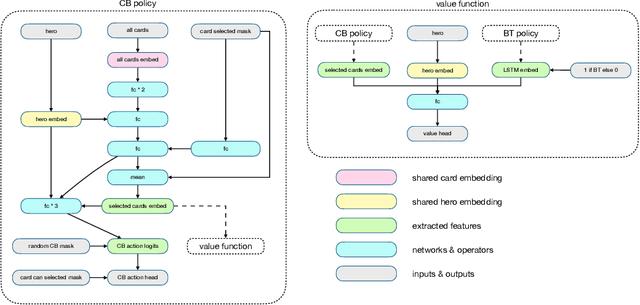
Strategy card game is a well-known genre that is demanding on the intelligent game-play and can be an ideal test-bench for AI. Previous work combines an end-to-end policy function and an optimistic smooth fictitious play, which shows promising performances on the strategy card game Legend of Code and Magic. In this work, we apply such algorithms to Hearthstone, a famous commercial game that is more complicated in game rules and mechanisms. We further propose several improved techniques and consequently achieve significant progress. For a machine-vs-human test we invite a Hearthstone streamer whose best rank was top 10 of the official league in China region that is estimated to be of millions of players. Our models defeat the human player in all Best-of-5 tournaments of full games (including both deck building and battle), showing a strong capability of decision making.
Mastering Strategy Card Game (Legends of Code and Magic) via End-to-End Policy and Optimistic Smooth Fictitious Play
Mar 07, 2023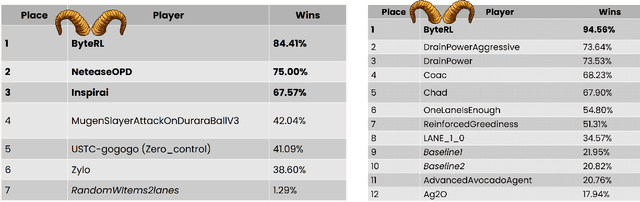
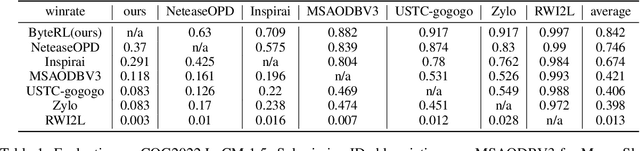

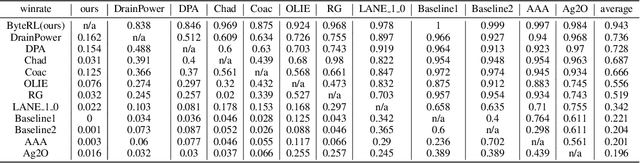
Deep Reinforcement Learning combined with Fictitious Play shows impressive results on many benchmark games, most of which are, however, single-stage. In contrast, real-world decision making problems may consist of multiple stages, where the observation spaces and the action spaces can be completely different across stages. We study a two-stage strategy card game Legends of Code and Magic and propose an end-to-end policy to address the difficulties that arise in multi-stage game. We also propose an optimistic smooth fictitious play algorithm to find the Nash Equilibrium for the two-player game. Our approach wins double championships of COG2022 competition. Extensive studies verify and show the advancement of our approach.
A Coarse to Fine Framework for Object Detection in High Resolution Image
Mar 02, 2023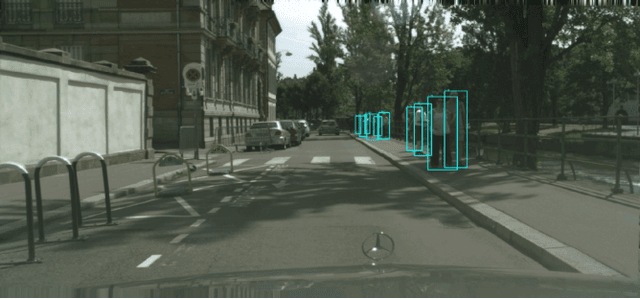
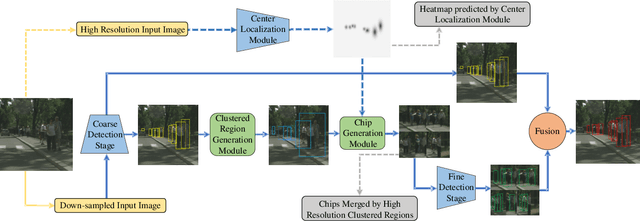
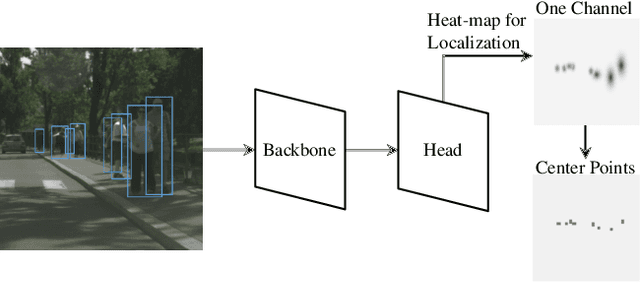
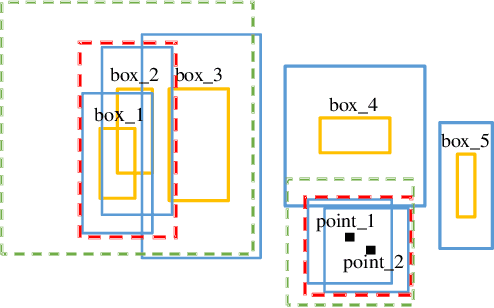
Object detection is a fundamental problem in computer vision, aiming at locating and classifying objects in image. Although current devices can easily take very high-resolution images, current approaches of object detection seldom consider detecting tiny object or the large scale variance problem in high resolution images. In this paper, we introduce a simple yet efficient approach that improves accuracy of object detection especially for small objects and large scale variance scene while reducing the computational cost in high resolution image. Inspired by observing that overall detection accuracy is reduced if the image is properly down-sampled but the recall rate is not significantly reduced. Besides, small objects can be better detected by inputting high-resolution images even if using lightweight detector. We propose a cluster-based coarse-to-fine object detection framework to enhance the performance for detecting small objects while ensure the accuracy of large objects in high-resolution images. For the first stage, we perform coarse detection on the down-sampled image and center localization of small objects by lightweight detector on high-resolution image, and then obtains image chips based on cluster region generation method by coarse detection and center localization results, and further sends chips to the second stage detector for fine detection. Finally, we merge the coarse detection and fine detection results. Our approach can make good use of the sparsity of the objects and the information in high-resolution image, thereby making the detection more efficient. Experiment results show that our proposed approach achieves promising performance compared with other state-of-the-art detectors.
Impact of Channel Aging on Dual-Function Radar-Communication Systems: Performance Analysis and Resource Allocation
Mar 01, 2023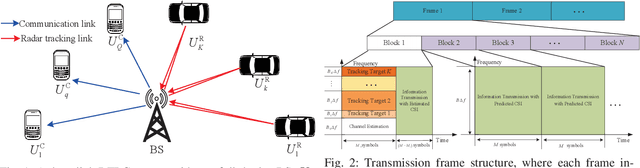
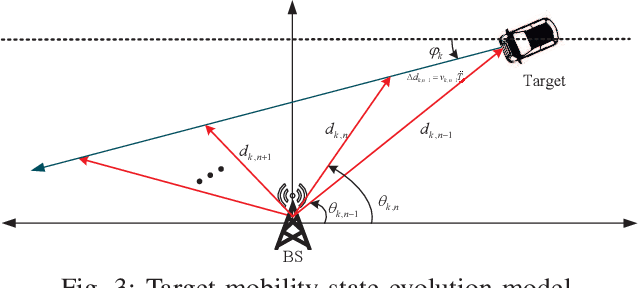
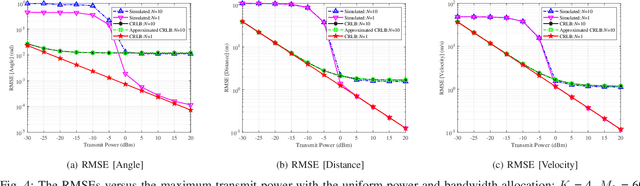
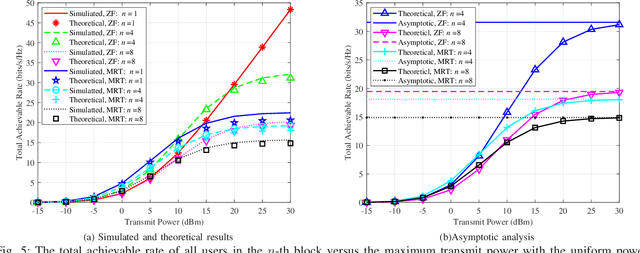
In conventional dual-function radar-communication (DFRC) systems, the radar and communication channels are routinely estimated at fixed time intervals based on their worst-case operation scenarios. Such situation-agnostic repeated estimations cause significant training overhead and dramatically degrade the system performance, especially for applications with dynamic sensing/communication demands and limited radio resources. In this paper, we leverage the channel aging characteristics to reduce training overhead and to design a situation-dependent channel re-estimation interval optimization-based resource allocation for performance improvement in a multi-target tracking DFRC system. Specifically, we exploit the channel temporal correlation to predict radar and communication channels for reducing the need of training preamble retransmission. Then, we characterize the channel aging effects on the Cramer-Rao lower bounds (CRLBs) for radar tracking performance analysis and achievable rates with maximum ratio transmission (MRT) and zero-forcing (ZF) transmit beamforming for communication performance analysis. In particular, the aged CRLBs and achievable rates are derived as closed-form expressions with respect to the channel aging time, bandwidth, and power. Based on the analyzed results, we optimize these factors to maximize the average total aged achievable rate subject to individual target tracking precision demand, communication rate requirement, and other practical constraints. Since the formulated problem belongs to a non-convex problem, we develop an efficient one-dimensional search based optimization algorithm to obtain its suboptimal solutions. Finally, simulation results are presented to validate the correctness of the derived theoretical results and the effectiveness of the proposed allocation scheme.
Graph Neural Network-Inspired Kernels for Gaussian Processes in Semi-Supervised Learning
Feb 12, 2023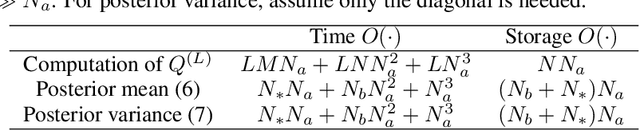
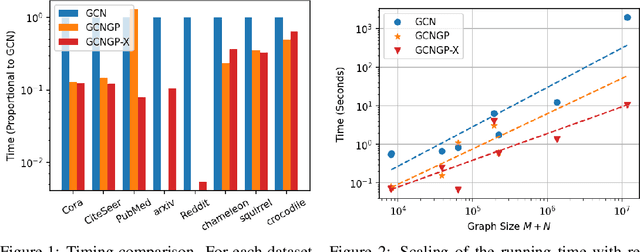

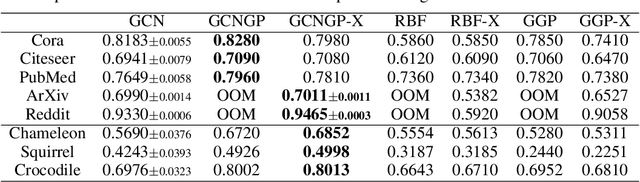
Gaussian processes (GPs) are an attractive class of machine learning models because of their simplicity and flexibility as building blocks of more complex Bayesian models. Meanwhile, graph neural networks (GNNs) emerged recently as a promising class of models for graph-structured data in semi-supervised learning and beyond. Their competitive performance is often attributed to a proper capturing of the graph inductive bias. In this work, we introduce this inductive bias into GPs to improve their predictive performance for graph-structured data. We show that a prominent example of GNNs, the graph convolutional network, is equivalent to some GP when its layers are infinitely wide; and we analyze the kernel universality and the limiting behavior in depth. We further present a programmable procedure to compose covariance kernels inspired by this equivalence and derive example kernels corresponding to several interesting members of the GNN family. We also propose a computationally efficient approximation of the covariance matrix for scalable posterior inference with large-scale data. We demonstrate that these graph-based kernels lead to competitive classification and regression performance, as well as advantages in computation time, compared with the respective GNNs.
TJ-FlyingFish: Design and Implementation of an Aerial-Aquatic Quadrotor with Tiltable Propulsion Units
Feb 07, 2023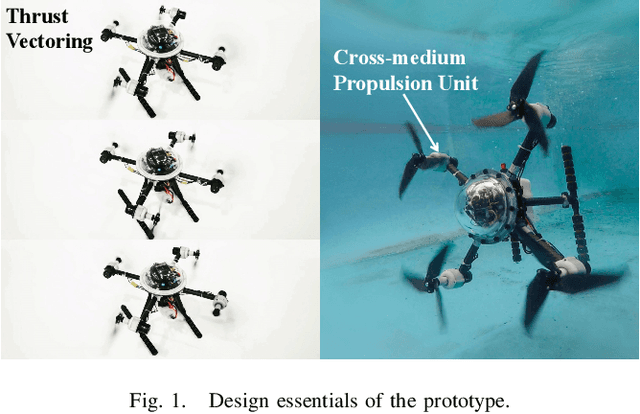
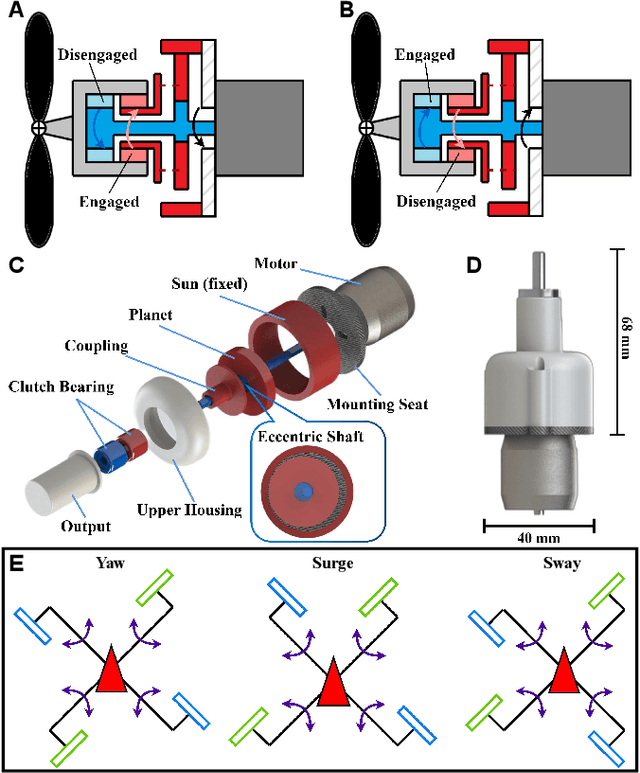
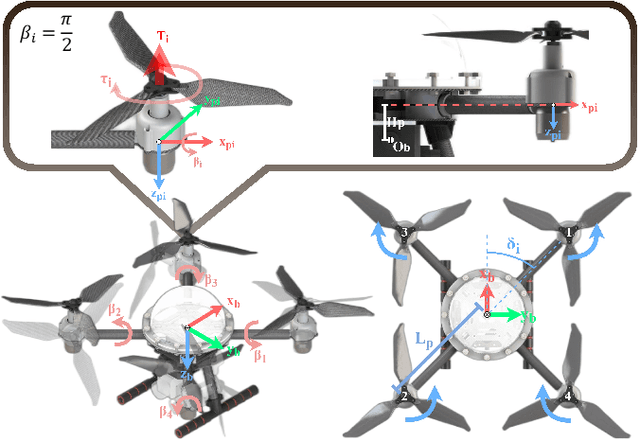
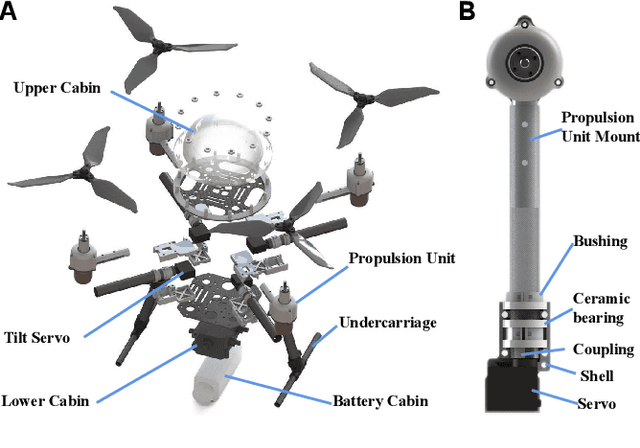
Aerial-aquatic vehicles are capable to move in the two most dominant fluids, making them more promising for a wide range of applications. We propose a prototype with special designs for propulsion and thruster configuration to cope with the vast differences in the fluid properties of water and air. For propulsion, the operating range is switched for the different mediums by the dual-speed propulsion unit, providing sufficient thrust and also ensuring output efficiency. For thruster configuration, thrust vectoring is realized by the rotation of the propulsion unit around the mount arm, thus enhancing the underwater maneuverability. This paper presents a quadrotor prototype of this concept and the design details and realization in practice.