 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianmin Zheng
Recovering Facial Reflectance and Geometry from Multi-view Images
Nov 27, 2019
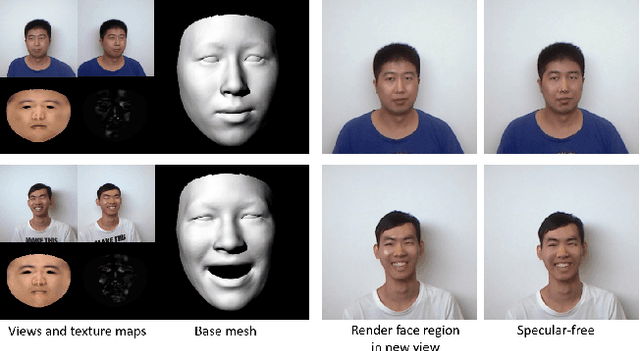

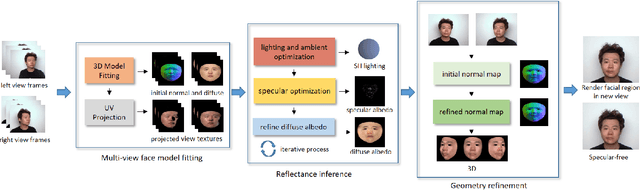
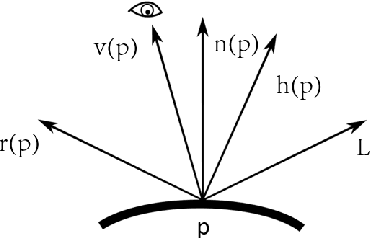
While the problem of estimating shapes and diffuse reflectances of human faces from images has been extensively studied, there is relatively less work done on recovering the specular albedo. This paper presents a lightweight solution for inferring photorealistic facial reflectance and geometry. Our system processes video streams from two views of a subject, and outputs two reflectance maps for diffuse and specular albedos, as well as a vector map of surface normals. A model-based optimization approach is used, consisting of the three stages of multi-view face model fitting, facial reflectance inference and facial geometry refinement. Our approach is based on a novel formulation built upon the 3D morphable model (3DMM) for representing 3D textured faces in conjunction with the Blinn-Phong reflection model. It has the advantage of requiring only a simple setup with two video streams, and is able to exploit the interaction between the diffuse and specular reflections across multiple views as well as time frames. As a result, the method is able to reliably recover high-fidelity facial reflectance and geometry, which facilitates various applications such as generating photorealistic facial images under new viewpoints or illumination conditions.
Learning 3D Human Body Embedding
May 14, 2019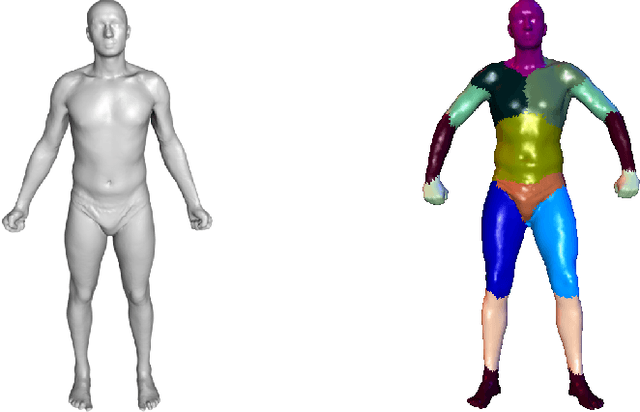
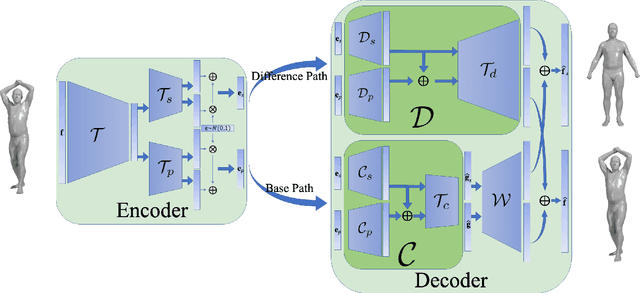
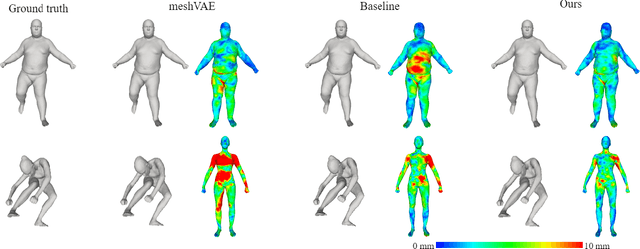

Although human body shapes vary for different identities with different poses, they can be embedded into a low-dimensional space due to their similarity in structure. Inspired by the recent work on latent representation learning with a deformation-based mesh representation, we propose an autoencoder like network architecture to learn disentangled shape and pose embedding specifically for 3D human body. We also integrate a coarse-to-fine reconstruction pipeline into the disentangling process to improve the reconstruction accuracy. Moreover, we construct a large dataset of human body models with consistent topology for the learning of neural network. Our learned embedding can achieve not only superior reconstruction accuracy but also provide great flexibilities in 3D human body creations via interpolation, bilateral interpolation and latent space sampling, which is confirmed by extensive experiments. The constructed dataset and trained model will be made publicly available.
Region Deformer Networks for Unsupervised Depth Estimation from Unconstrained Monocular Videos
Feb 26, 2019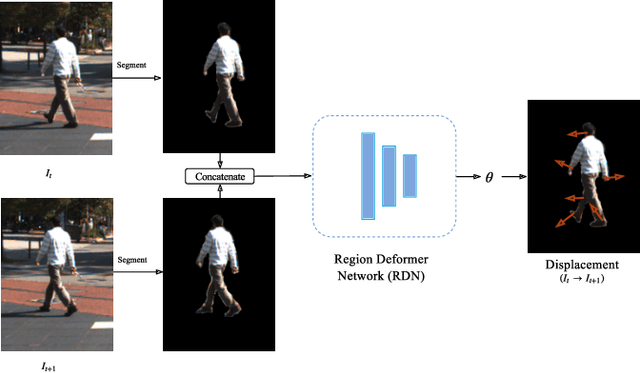
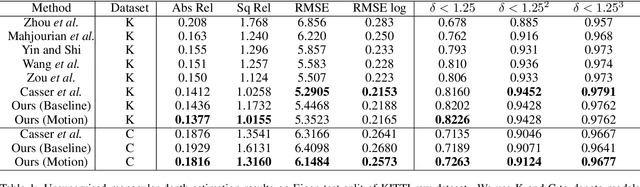
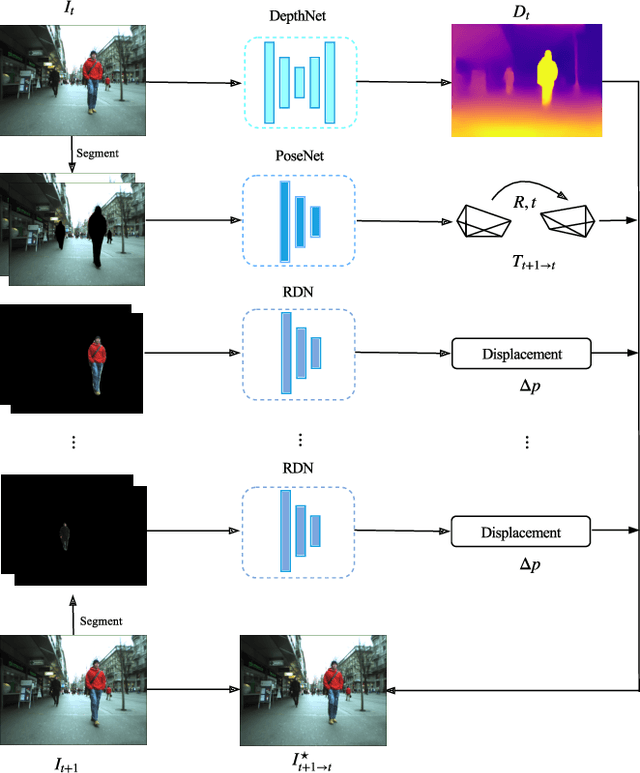

While learning based depth estimation from images/videos has achieved substantial progress, there still exist intrinsic limitations. Supervised methods are limited by small amount of ground truth or labeled data and unsupervised methods for monocular videos are mostly based on the static scene assumption, not performing well on real world scenarios with the presence of dynamic objects. In this paper, we propose a new learning based method consisting of DepthNet, PoseNet and Region Deformer Networks (RDN) to estimate depth from unconstrained monocular videos without ground truth supervision. The core contribution lies in RDN for proper handling of rigid and non-rigid motions of various objects such as rigidly moving cars and deformable humans. In particular, a deformation based motion representation is proposed to model individual object motion on 2D images. This representation enables our method to be applicable to diverse unconstrained monocular videos. Our method can not only achieve the state-of-the-art results on standard benchmarks KITTI and Cityscapes, but also show promising results on a crowded pedestrian tracking dataset, which demonstrates the effectiveness of the deformation based motion representation.
Real-time 3D Face-Eye Performance Capture of a Person Wearing VR Headset
Jan 21, 2019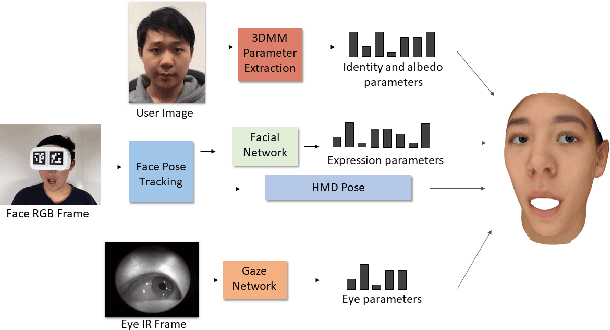
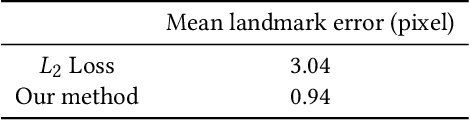

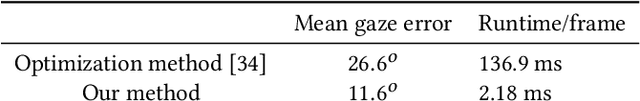
Teleconference or telepresence based on virtual reality (VR) headmount display (HMD) device is a very interesting and promising application since HMD can provide immersive feelings for users. However, in order to facilitate face-to-face communications for HMD users, real-time 3D facial performance capture of a person wearing HMD is needed, which is a very challenging task due to the large occlusion caused by HMD. The existing limited solutions are very complex either in setting or in approach as well as lacking the performance capture of 3D eye gaze movement. In this paper, we propose a convolutional neural network (CNN) based solution for real-time 3D face-eye performance capture of HMD users without complex modification to devices. To address the issue of lacking training data, we generate massive pairs of HMD face-label dataset by data synthesis as well as collecting VR-IR eye dataset from multiple subjects. Then, we train a dense-fitting network for facial region and an eye gaze network to regress 3D eye model parameters. Extensive experimental results demonstrate that our system can efficiently and effectively produce in real time a vivid personalized 3D avatar with the correct identity, pose, expression and eye motion corresponding to the HMD user.
Self-supervised CNN for Unconstrained 3D Facial Performance Capture from an RGB-D Camera
Aug 17, 2018
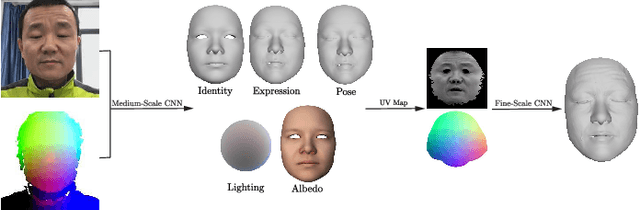


We present a novel method for real-time 3D facial performance capture with consumer-level RGB-D sensors. Our capturing system is targeted at robust and stable 3D face capturing in the wild, in which the RGB-D facial data contain noise, imperfection and occlusion, and often exhibit high variability in motion, pose, expression and lighting conditions, thus posing great challenges. The technical contribution is a self-supervised deep learning framework, which is trained directly from raw RGB-D data. The key novelties include: (1) learning both the core tensor and the parameters for refining our parametric face model; (2) using vertex displacement and UV map for learning surface detail; (3) designing the loss function by incorporating temporal coherence and same identity constraints based on pairs of RGB-D images and utilizing sparse norms, in addition to the conventional terms for photo-consistency, feature similarity, regularization as well as geometry consistency; and (4) augmenting the training data set in new ways. The method is demonstrated in a live setup that runs in real-time on a smartphone and an RGB-D sensor. Extensive experiments show that our method is robust to severe occlusion, fast motion, large rotation, exaggerated facial expressions and diverse lighting.
CNN-based Real-time Dense Face Reconstruction with Inverse-rendered Photo-realistic Face Images
May 15, 2018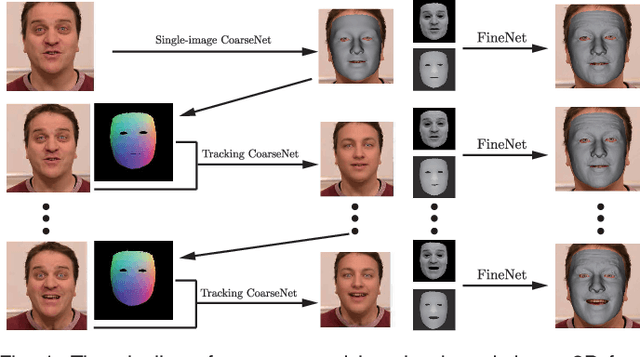
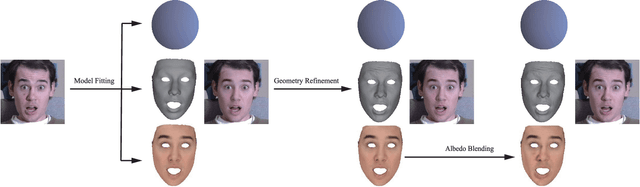

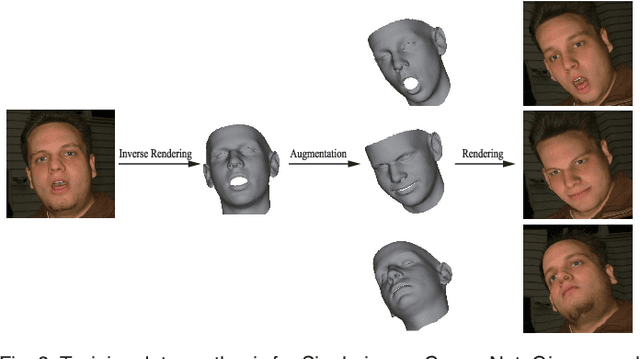
With the powerfulness of convolution neural networks (CNN), CNN based face reconstruction has recently shown promising performance in reconstructing detailed face shape from 2D face images. The success of CNN-based methods relies on a large number of labeled data. The state-of-the-art synthesizes such data using a coarse morphable face model, which however has difficulty to generate detailed photo-realistic images of faces (with wrinkles). This paper presents a novel face data generation method. Specifically, we render a large number of photo-realistic face images with different attributes based on inverse rendering. Furthermore, we construct a fine-detailed face image dataset by transferring different scales of details from one image to another. We also construct a large number of video-type adjacent frame pairs by simulating the distribution of real video data. With these nicely constructed datasets, we propose a coarse-to-fine learning framework consisting of three convolutional networks. The networks are trained for real-time detailed 3D face reconstruction from monocular video as well as from a single image. Extensive experimental results demonstrate that our framework can produce high-quality reconstruction but with much less computation time compared to the state-of-the-art. Moreover, our method is robust to pose, expression and lighting due to the diversity of data.
Alive Caricature from 2D to 3D
Mar 27, 2018
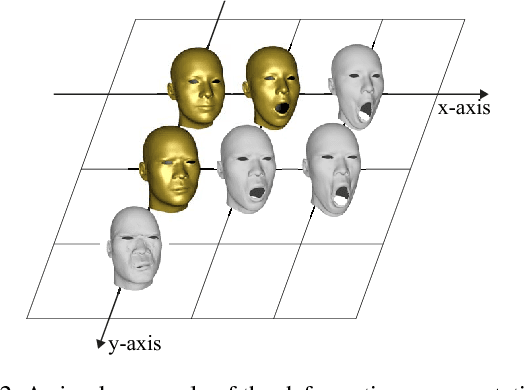
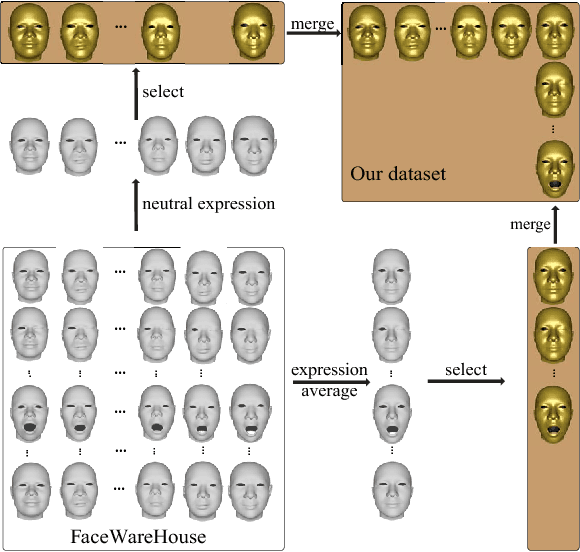

Caricature is an art form that expresses subjects in abstract, simple and exaggerated view. While many caricatures are 2D images, this paper presents an algorithm for creating expressive 3D caricatures from 2D caricature images with a minimum of user interaction. The key idea of our approach is to introduce an intrinsic deformation representation that has a capacity of extrapolation enabling us to create a deformation space from standard face dataset, which maintains face constraints and meanwhile is sufficiently large for producing exaggerated face models. Built upon the proposed deformation representation, an optimization model is formulated to find the 3D caricature that captures the style of the 2D caricature image automatically. The experiments show that our approach has better capability in expressing caricatures than those fitting approaches directly using classical parametric face models such as 3DMM and FaceWareHouse. Moreover, our approach is based on standard face datasets and avoids constructing complicated 3D caricature training set, which provides great flexibility in real applications.