 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianke Zhu
Point2Mask: Point-supervised Panoptic Segmentation via Optimal Transport
Aug 03, 2023
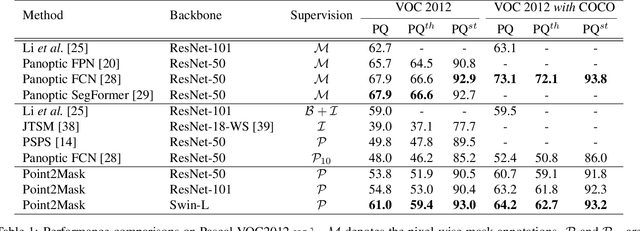
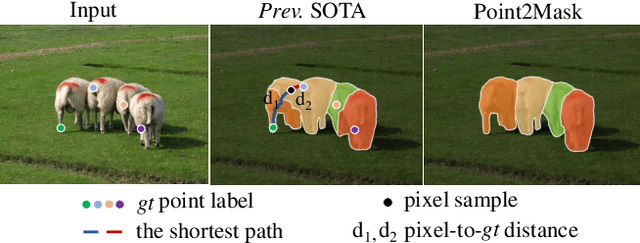
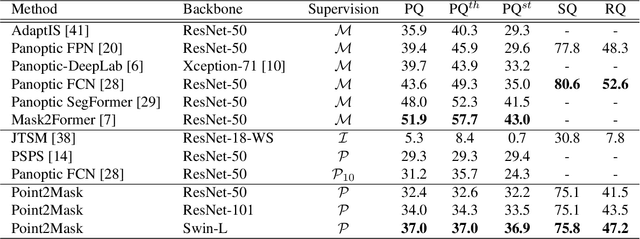
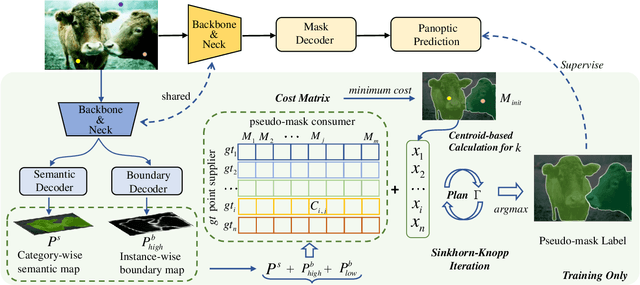
Weakly-supervised image segmentation has recently attracted increasing research attentions, aiming to avoid the expensive pixel-wise labeling. In this paper, we present an effective method, namely Point2Mask, to achieve high-quality panoptic prediction using only a single random point annotation per target for training. Specifically, we formulate the panoptic pseudo-mask generation as an Optimal Transport (OT) problem, where each ground-truth (gt) point label and pixel sample are defined as the label supplier and consumer, respectively. The transportation cost is calculated by the introduced task-oriented maps, which focus on the category-wise and instance-wise differences among the various thing and stuff targets. Furthermore, a centroid-based scheme is proposed to set the accurate unit number for each gt point supplier. Hence, the pseudo-mask generation is converted into finding the optimal transport plan at a globally minimal transportation cost, which can be solved via the Sinkhorn-Knopp Iteration. Experimental results on Pascal VOC and COCO demonstrate the promising performance of our proposed Point2Mask approach to point-supervised panoptic segmentation. Source code is available at: https://github.com/LiWentomng/Point2Mask.
Pyramid Deep Fusion Network for Two-Hand Reconstruction from RGB-D Images
Jul 12, 2023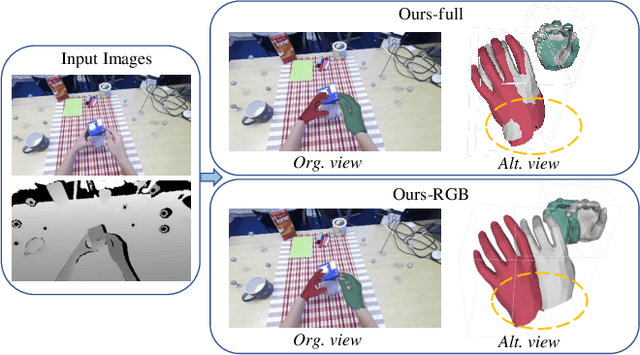
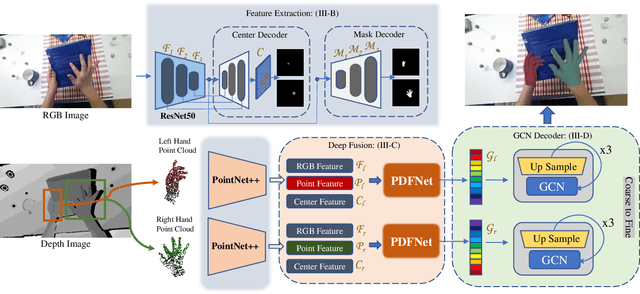
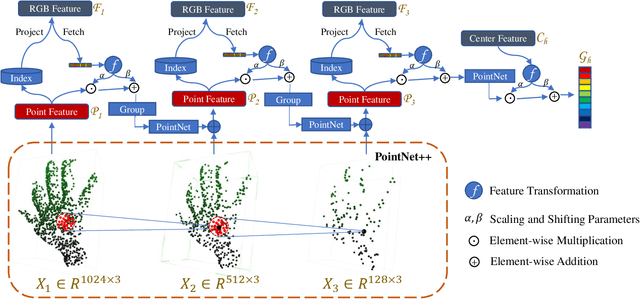

Accurately recovering the dense 3D mesh of both hands from monocular images poses considerable challenges due to occlusions and projection ambiguity. Most of the existing methods extract features from color images to estimate the root-aligned hand meshes, which neglect the crucial depth and scale information in the real world. Given the noisy sensor measurements with limited resolution, depth-based methods predict 3D keypoints rather than a dense mesh. These limitations motivate us to take advantage of these two complementary inputs to acquire dense hand meshes on a real-world scale. In this work, we propose an end-to-end framework for recovering dense meshes for both hands, which employ single-view RGB-D image pairs as input. The primary challenge lies in effectively utilizing two different input modalities to mitigate the blurring effects in RGB images and noises in depth images. Instead of directly treating depth maps as additional channels for RGB images, we encode the depth information into the unordered point cloud to preserve more geometric details. Specifically, our framework employs ResNet50 and PointNet++ to derive features from RGB and point cloud, respectively. Additionally, we introduce a novel pyramid deep fusion network (PDFNet) to aggregate features at different scales, which demonstrates superior efficacy compared to previous fusion strategies. Furthermore, we employ a GCN-based decoder to process the fused features and recover the corresponding 3D pose and dense mesh. Through comprehensive ablation experiments, we have not only demonstrated the effectiveness of our proposed fusion algorithm but also outperformed the state-of-the-art approaches on publicly available datasets. To reproduce the results, we will make our source code and models publicly available at {\url{https://github.com/zijinxuxu/PDFNet}}.
FastMESH: Fast Surface Reconstruction by Hexagonal Mesh-based Neural Rendering
May 29, 2023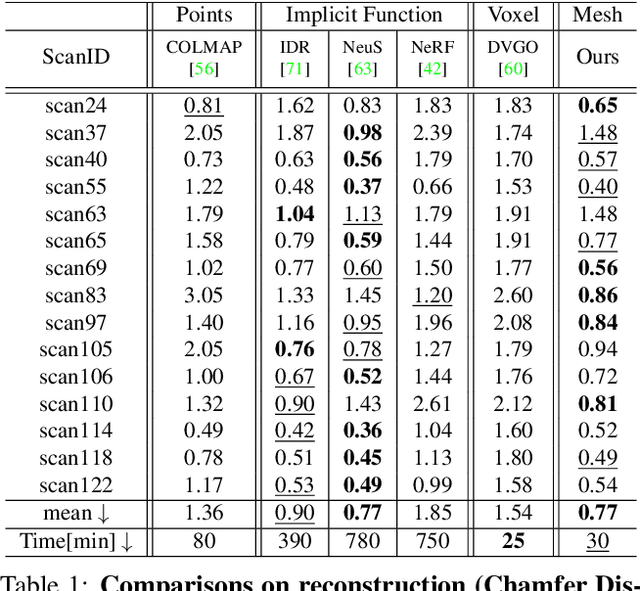
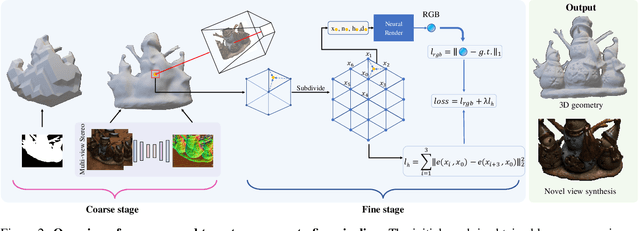
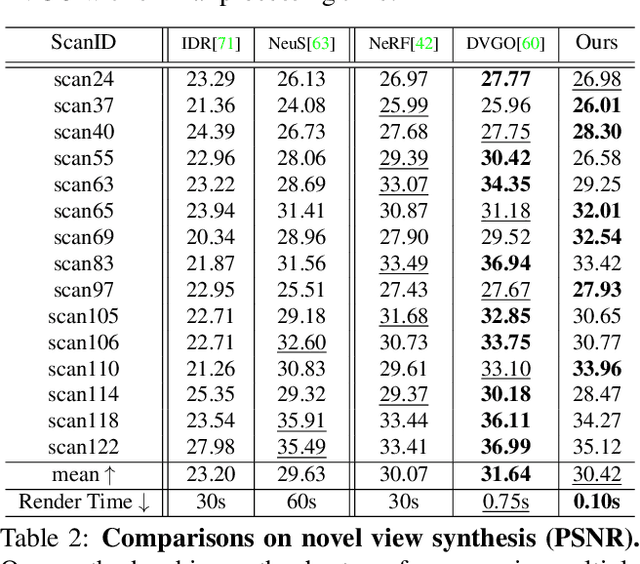
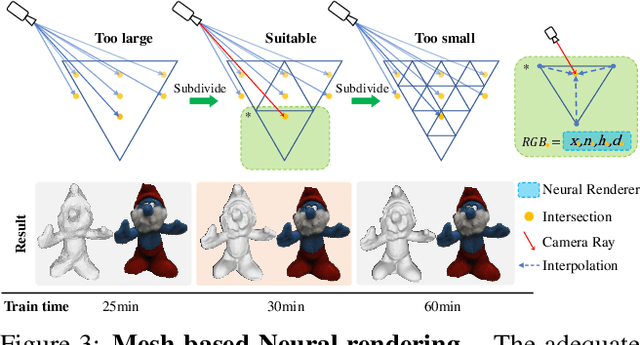
Despite the promising results of multi-view reconstruction, the recent neural rendering-based methods, such as implicit surface rendering (IDR) and volume rendering (NeuS), not only incur a heavy computational burden on training but also have the difficulties in disentangling the geometric and appearance. Although having achieved faster training speed than implicit representation and hash coding, the explicit voxel-based method obtains the inferior results on recovering surface. To address these challenges, we propose an effective mesh-based neural rendering approach, named FastMESH, which only samples at the intersection of ray and mesh. A coarse-to-fine scheme is introduced to efficiently extract the initial mesh by space carving. More importantly, we suggest a hexagonal mesh model to preserve surface regularity by constraining the second-order derivatives of vertices, where only low level of positional encoding is engaged for neural rendering. The experiments demonstrate that our approach achieves the state-of-the-art results on both reconstruction and novel view synthesis. Besides, we obtain 10-fold acceleration on training comparing to the implicit representation-based methods.
BundleRecon: Ray Bundle-Based 3D Neural Reconstruction
May 12, 2023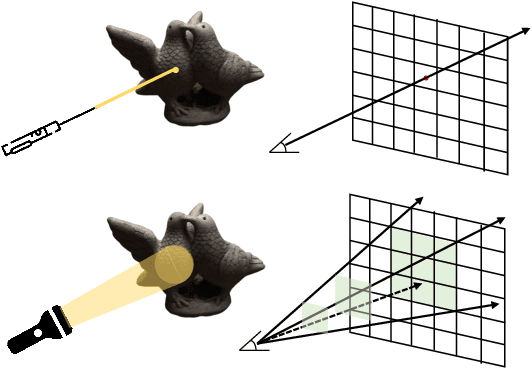
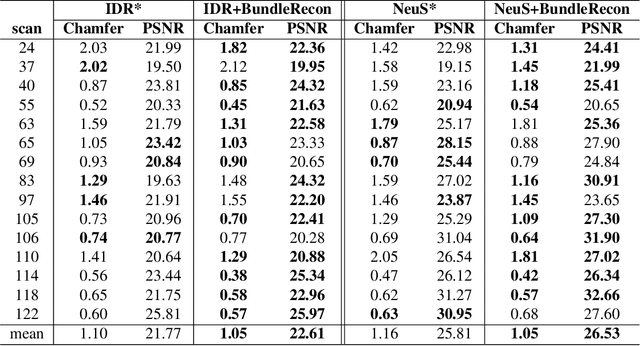
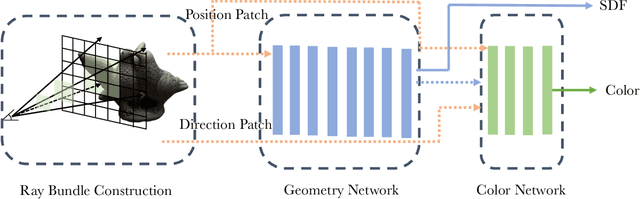
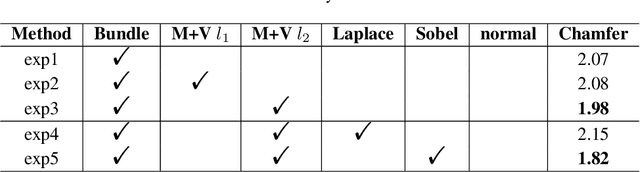
With the growing popularity of neural rendering, there has been an increasing number of neural implicit multi-view reconstruction methods. While many models have been enhanced in terms of positional encoding, sampling, rendering, and other aspects to improve the reconstruction quality, current methods do not fully leverage the information among neighboring pixels during the reconstruction process. To address this issue, we propose an enhanced model called BundleRecon. In the existing approaches, sampling is performed by a single ray that corresponds to a single pixel. In contrast, our model samples a patch of pixels using a bundle of rays, which incorporates information from neighboring pixels. Furthermore, we design bundle-based constraints to further improve the reconstruction quality. Experimental results demonstrate that BundleRecon is compatible with the existing neural implicit multi-view reconstruction methods and can improve their reconstruction quality.
Multi-View Stereo Representation Revisit: Region-Aware MVSNet
Apr 27, 2023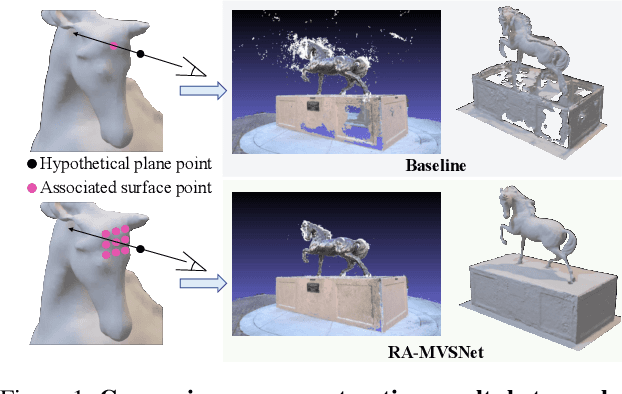
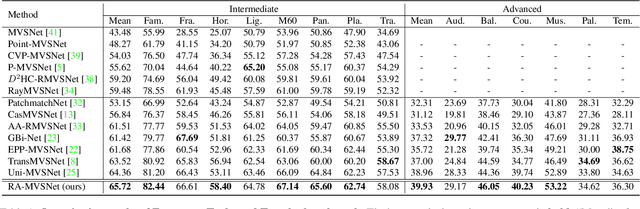
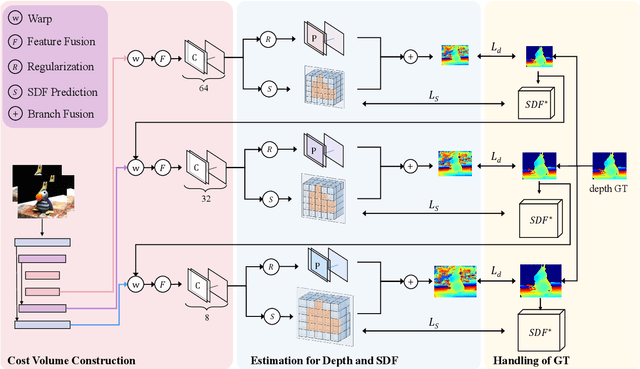
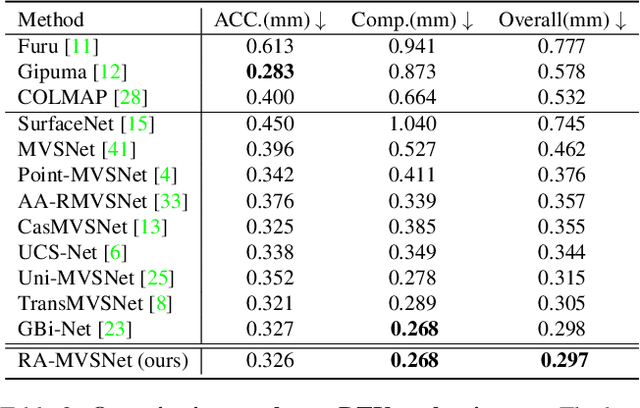
Deep learning-based multi-view stereo has emerged as a powerful paradigm for reconstructing the complete geometrically-detailed objects from multi-views. Most of the existing approaches only estimate the pixel-wise depth value by minimizing the gap between the predicted point and the intersection of ray and surface, which usually ignore the surface topology. It is essential to the textureless regions and surface boundary that cannot be properly reconstructed. To address this issue, we suggest to take advantage of point-to-surface distance so that the model is able to perceive a wider range of surfaces. To this end, we predict the distance volume from cost volume to estimate the signed distance of points around the surface. Our proposed RA-MVSNet is patch-awared, since the perception range is enhanced by associating hypothetical planes with a patch of surface. Therefore, it could increase the completion of textureless regions and reduce the outliers at the boundary. Moreover, the mesh topologies with fine details can be generated by the introduced distance volume. Comparing to the conventional deep learning-based multi-view stereo methods, our proposed RA-MVSNet approach obtains more complete reconstruction results by taking advantage of signed distance supervision. The experiments on both the DTU and Tanks \& Temples datasets demonstrate that our proposed approach achieves the state-of-the-art results.
LiDAR2Map: In Defense of LiDAR-Based Semantic Map Construction Using Online Camera Distillation
Apr 22, 2023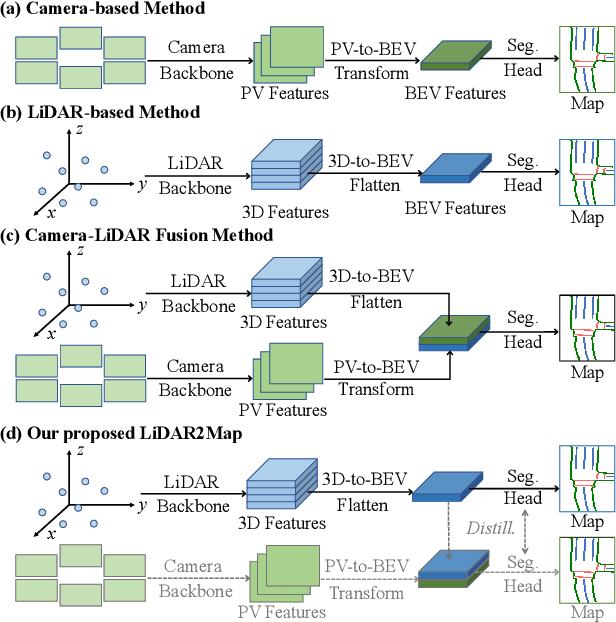
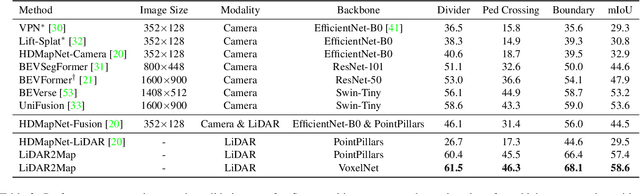
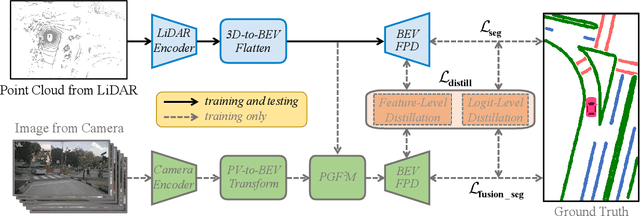
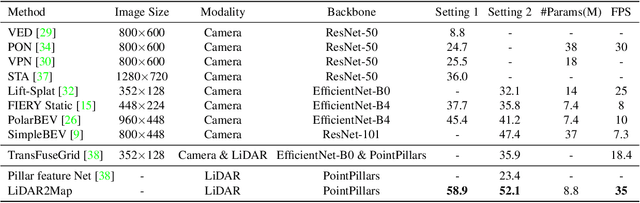
Semantic map construction under bird's-eye view (BEV) plays an essential role in autonomous driving. In contrast to camera image, LiDAR provides the accurate 3D observations to project the captured 3D features onto BEV space inherently. However, the vanilla LiDAR-based BEV feature often contains many indefinite noises, where the spatial features have little texture and semantic cues. In this paper, we propose an effective LiDAR-based method to build semantic map. Specifically, we introduce a BEV pyramid feature decoder that learns the robust multi-scale BEV features for semantic map construction, which greatly boosts the accuracy of the LiDAR-based method. To mitigate the defects caused by lacking semantic cues in LiDAR data, we present an online Camera-to-LiDAR distillation scheme to facilitate the semantic learning from image to point cloud. Our distillation scheme consists of feature-level and logit-level distillation to absorb the semantic information from camera in BEV. The experimental results on challenging nuScenes dataset demonstrate the efficacy of our proposed LiDAR2Map on semantic map construction, which significantly outperforms the previous LiDAR-based methods over 27.9% mIoU and even performs better than the state-of-the-art camera-based approaches. Source code is available at: https://github.com/songw-zju/LiDAR2Map.
Bridging the Emotional Semantic Gap via Multimodal Relevance Estimation
Feb 03, 2023

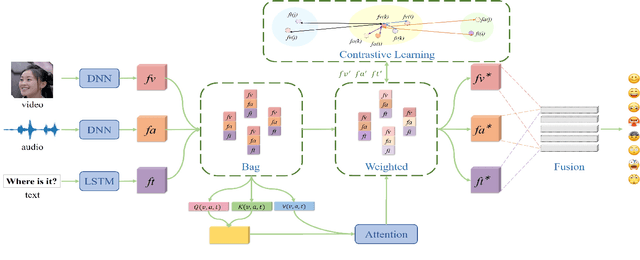
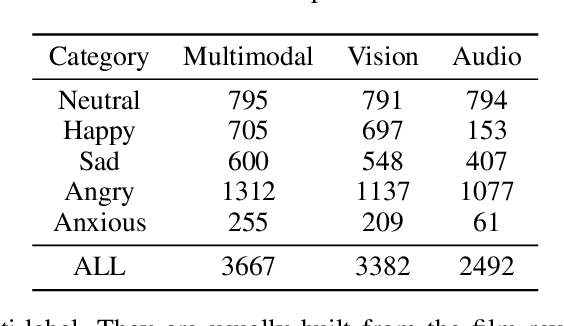
Human beings have rich ways of emotional expressions, including facial action, voice, and natural languages. Due to the diversity and complexity of different individuals, the emotions expressed by various modalities may be semantically irrelevant. Directly fusing information from different modalities may inevitably make the model subject to the noise from semantically irrelevant modalities. To tackle this problem, we propose a multimodal relevance estimation network to capture the relevant semantics among modalities in multimodal emotions. Specifically, we take advantage of an attention mechanism to reflect the semantic relevance weights of each modality. Moreover, we propose a relevant semantic estimation loss to weakly supervise the semantics of each modality. Furthermore, we make use of contrastive learning to optimize the similarity of category-level modality-relevant semantics across different modalities in feature space, thereby bridging the semantic gap between heterogeneous modalities. In order to better reflect the emotional state in the real interactive scenarios and perform the semantic relevance analysis, we collect a single-label discrete multimodal emotion dataset named SDME, which enables researchers to conduct multimodal semantic relevance research with large category bias. Experiments on continuous and discrete emotion datasets show that our model can effectively capture the relevant semantics, especially for the large deviations in modal semantics. The code and SDME dataset will be publicly available.
Box2Mask: Box-supervised Instance Segmentation via Level-set Evolution
Dec 03, 2022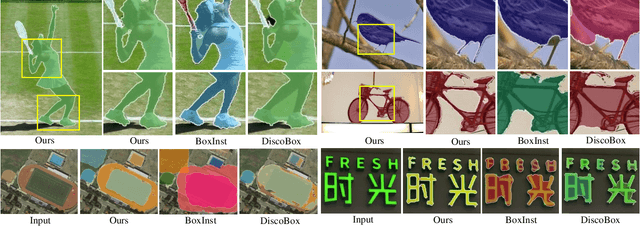
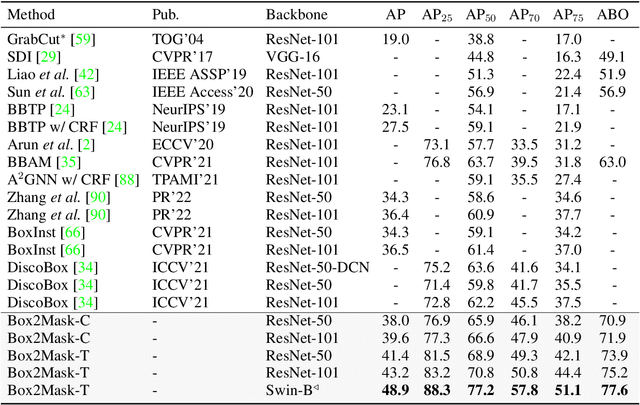
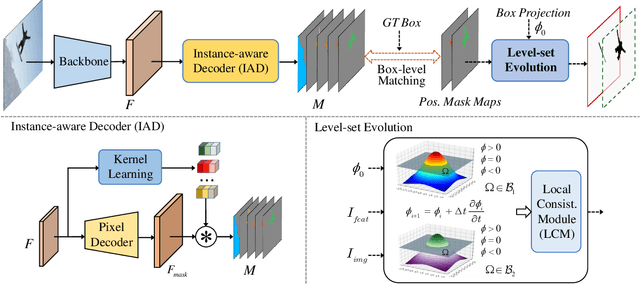
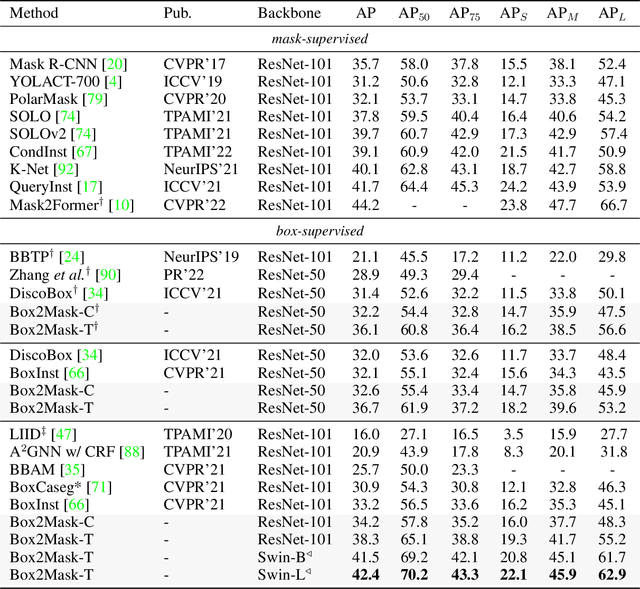
In contrast to fully supervised methods using pixel-wise mask labels, box-supervised instance segmentation takes advantage of simple box annotations, which has recently attracted increasing research attention. This paper presents a novel single-shot instance segmentation approach, namely Box2Mask, which integrates the classical level-set evolution model into deep neural network learning to achieve accurate mask prediction with only bounding box supervision. Specifically, both the input image and its deep features are employed to evolve the level-set curves implicitly, and a local consistency module based on a pixel affinity kernel is used to mine the local context and spatial relations. Two types of single-stage frameworks, i.e., CNN-based and transformer-based frameworks, are developed to empower the level-set evolution for box-supervised instance segmentation, and each framework consists of three essential components: instance-aware decoder, box-level matching assignment and level-set evolution. By minimizing the level-set energy function, the mask map of each instance can be iteratively optimized within its bounding box annotation. The experimental results on five challenging testbeds, covering general scenes, remote sensing, medical and scene text images, demonstrate the outstanding performance of our proposed Box2Mask approach for box-supervised instance segmentation. In particular, with the Swin-Transformer large backbone, our Box2Mask obtains 42.4% mask AP on COCO, which is on par with the recently developed fully mask-supervised methods. The code is available at: https://github.com/LiWentomng/boxlevelset.
PatchShading: High-Quality Human Reconstruction by Patch Warping and Shading Refinement
Nov 26, 2022
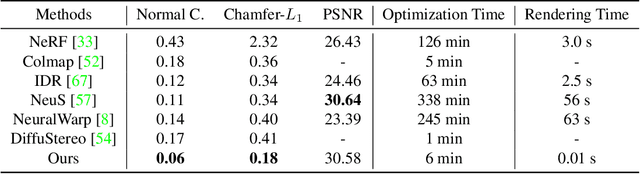
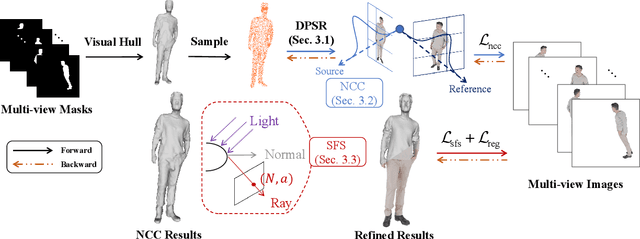
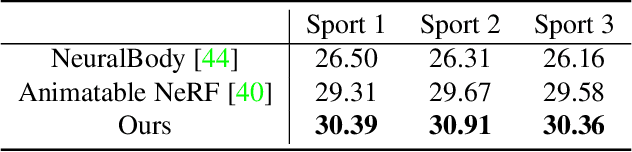
Human reconstruction from multi-view images plays an important role in many applications. Although neural rendering methods have achieved promising results on synthesising realistic images, it is still difficult to handle the ambiguity between the geometry and appearance using only rendering loss. Moreover, it is very computationally intensive to render a whole image as each pixel requires a forward network inference. To tackle these challenges, we propose a novel approach called \emph{PatchShading} to reconstruct high-quality mesh of human body from multi-view posed images. We first present a patch warping strategy to constrain multi-view photometric consistency explicitly. Second, we adopt sphere harmonics (SH) illumination and shape from shading image formation to further refine the geometric details. By taking advantage of the oriented point clouds shape representation and SH shading, our proposed method significantly reduce the optimization and rendering time compared to those implicit methods. The encouraging results on both synthetic and real-world datasets demonstrate the efficacy of our proposed approach.
Box-supervised Instance Segmentation with Level Set Evolution
Jul 19, 2022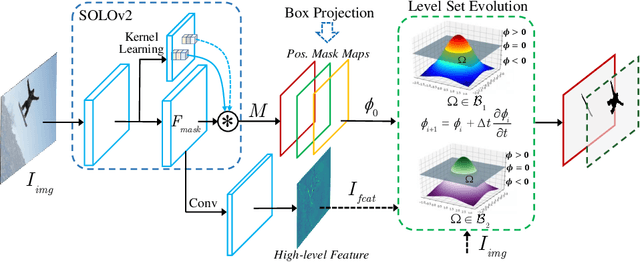
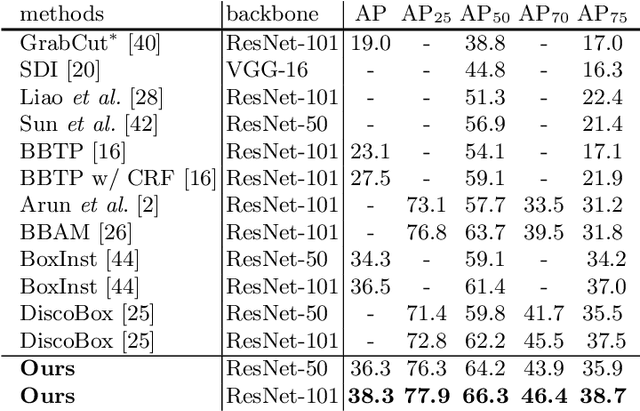
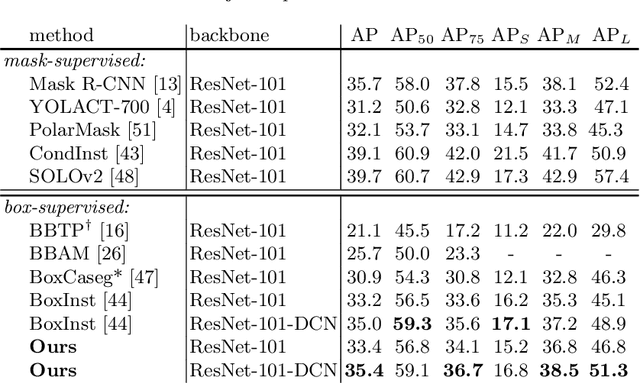

In contrast to the fully supervised methods using pixel-wise mask labels, box-supervised instance segmentation takes advantage of the simple box annotations, which has recently attracted a lot of research attentions. In this paper, we propose a novel single-shot box-supervised instance segmentation approach, which integrates the classical level set model with deep neural network delicately. Specifically, our proposed method iteratively learns a series of level sets through a continuous Chan-Vese energy-based function in an end-to-end fashion. A simple mask supervised SOLOv2 model is adapted to predict the instance-aware mask map as the level set for each instance. Both the input image and its deep features are employed as the input data to evolve the level set curves, where a box projection function is employed to obtain the initial boundary. By minimizing the fully differentiable energy function, the level set for each instance is iteratively optimized within its corresponding bounding box annotation. The experimental results on four challenging benchmarks demonstrate the leading performance of our proposed approach to robust instance segmentation in various scenarios. The code is available at: https://github.com/LiWentomng/boxlevelset.