 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Level Network for High-Speed Multi-Person Pose Estimation
Nov 26, 2019
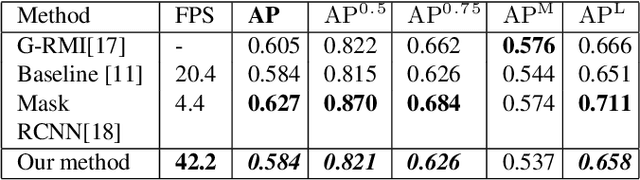
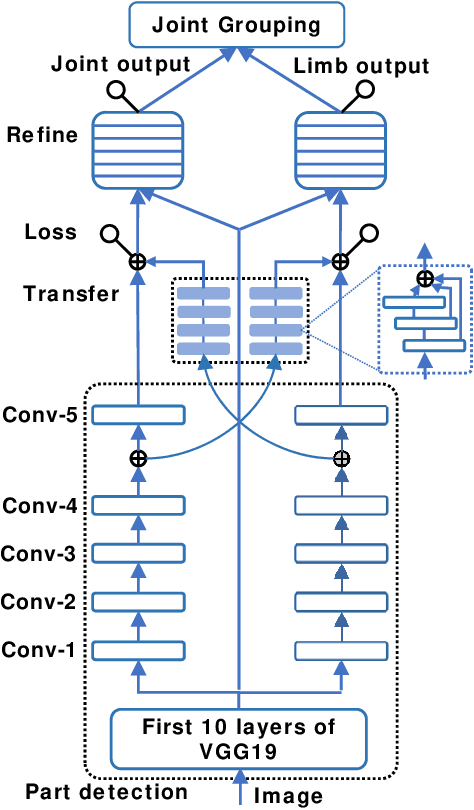

In multi-person pose estimation, the left/right joint type discrimination is always a hard problem because of the similar appearance. Traditionally, we solve this problem by stacking multiple refinement modules to increase network's receptive fields and capture more global context, which can also increase a great amount of computation. In this paper, we propose a Multi-level Network (MLN) that learns to aggregate features from lower-level (left/right information), upper-level (localization information), joint-limb level (complementary information) and global-level (context) information for discrimination of joint type. Through feature reuse and its intra-relation, MLN can attain comparable performance to other conventional methods while runtime speed retains at 42.2 FPS.
FollowMeUp Sports: New Benchmark for 2D Human Keypoint Recognition
Nov 19, 2019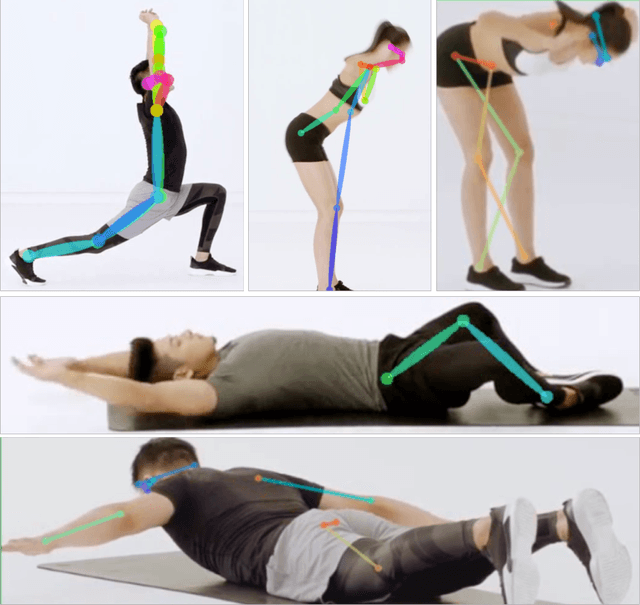

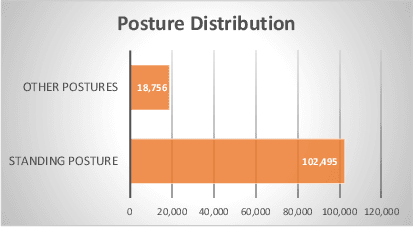
Human pose estimation has made significant advancement in recent years. However, the existing datasets are limited in their coverage of pose variety. In this paper, we introduce a novel benchmark FollowMeUp Sports that makes an important advance in terms of specific postures, self-occlusion and class balance, a contribution that we feel is required for future development in human body models. This comprehensive dataset was collected using an established taxonomy of over 200 standard workout activities with three different shot angles. The collected videos cover a wider variety of specific workout activities than previous datasets including push-up, squat and body moving near the ground with severe self-occlusion or occluded by some sport equipment and outfits. Given these rich images, we perform a detailed analysis of the leading human pose estimation approaches gaining insights for the success and failures of these methods.