 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiangchao Yao
Edge-Cloud Polarization and Collaboration: A Comprehensive Survey
Nov 11, 2021
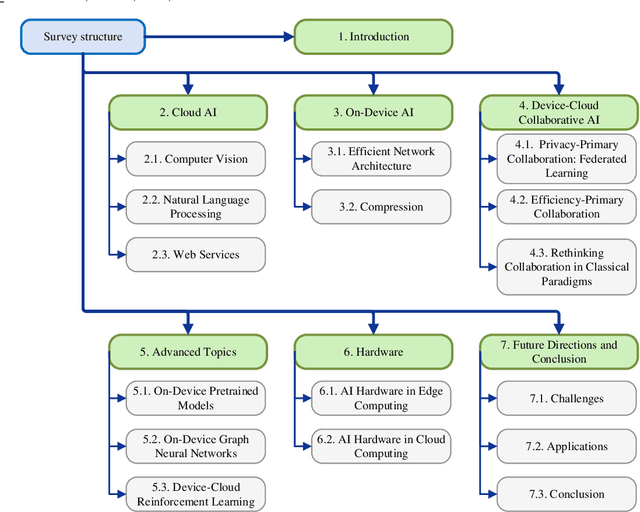
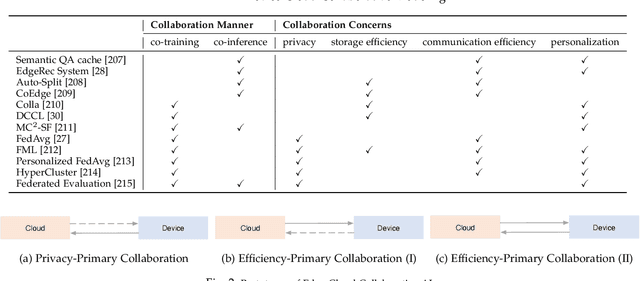
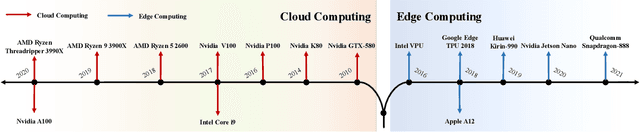
Influenced by the great success of deep learning via cloud computing and the rapid development of edge chips, research in artificial intelligence (AI) has shifted to both of the computing paradigms, i.e., cloud computing and edge computing. In recent years, we have witnessed significant progress in developing more advanced AI models on cloud servers that surpass traditional deep learning models owing to model innovations (e.g., Transformers, Pretrained families), explosion of training data and soaring computing capabilities. However, edge computing, especially edge and cloud collaborative computing, are still in its infancy to announce their success due to the resource-constrained IoT scenarios with very limited algorithms deployed. In this survey, we conduct a systematic review for both cloud and edge AI. Specifically, we are the first to set up the collaborative learning mechanism for cloud and edge modeling with a thorough review of the architectures that enable such mechanism. We also discuss potentials and practical experiences of some on-going advanced edge AI topics including pretraining models, graph neural networks and reinforcement learning. Finally, we discuss the promising directions and challenges in this field.
Click-through Rate Prediction with Auto-Quantized Contrastive Learning
Sep 27, 2021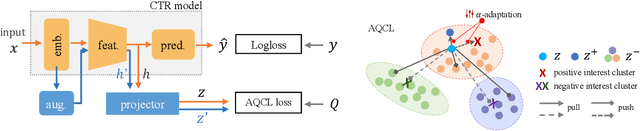
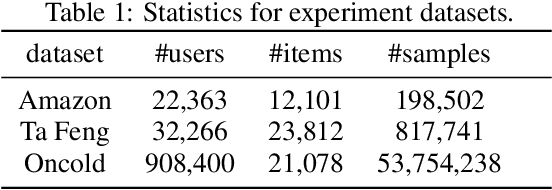
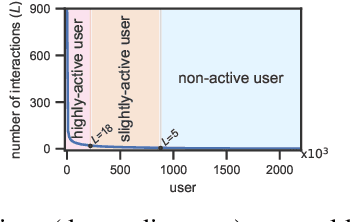
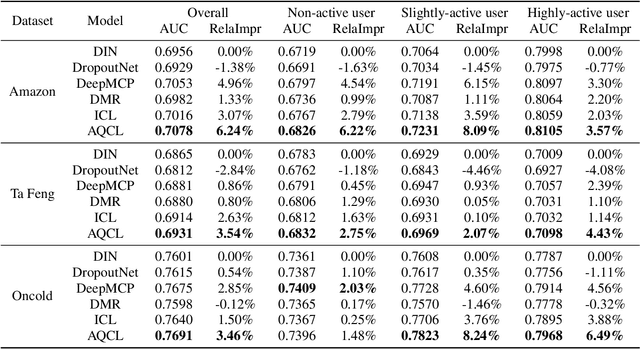
Click-through rate (CTR) prediction becomes indispensable in ubiquitous web recommendation applications. Nevertheless, the current methods are struggling under the cold-start scenarios where the user interactions are extremely sparse. We consider this problem as an automatic identification about whether the user behaviors are rich enough to capture the interests for prediction, and propose an Auto-Quantized Contrastive Learning (AQCL) loss to regularize the model. Different from previous methods, AQCL explores both the instance-instance and the instance-cluster similarity to robustify the latent representation, and automatically reduces the information loss to the active users due to the quantization. The proposed framework is agnostic to different model architectures and can be trained in an end-to-end fashion. Extensive results show that it consistently improves the current state-of-the-art CTR models.
MC$^2$-SF: Slow-Fast Learning for Mobile-Cloud Collaborative Recommendation
Sep 25, 2021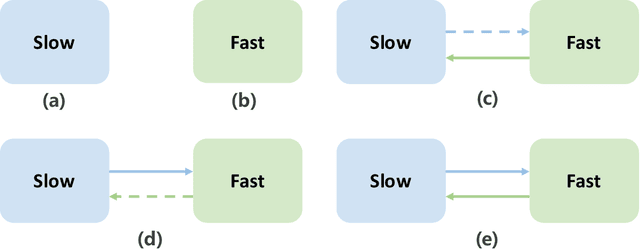
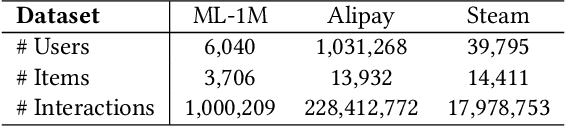
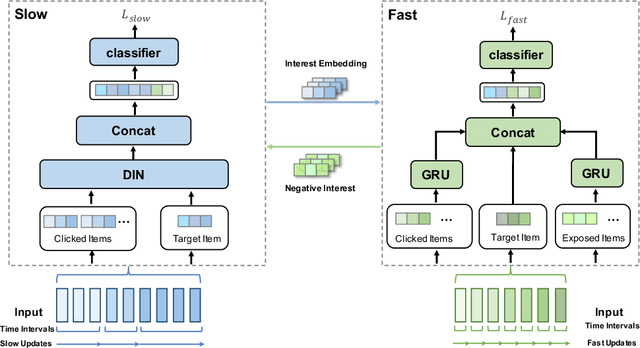
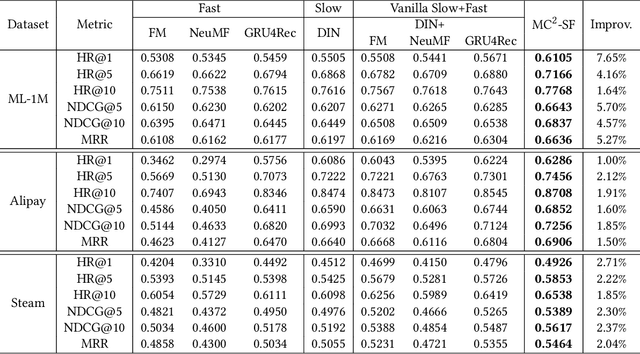
With the hardware development of mobile devices, it is possible to build the recommendation models on the mobile side to utilize the fine-grained features and the real-time feedbacks. Compared to the straightforward mobile-based modeling appended to the cloud-based modeling, we propose a Slow-Fast learning mechanism to make the Mobile-Cloud Collaborative recommendation (MC$^2$-SF) mutual benefit. Specially, in our MC$^2$-SF, the cloud-based model and the mobile-based model are respectively treated as the slow component and the fast component, according to their interaction frequency in real-world scenarios. During training and serving, they will communicate the prior/privileged knowledge to each other to help better capture the user interests about the candidates, resembling the role of System I and System II in the human cognition. We conduct the extensive experiments on three benchmark datasets and demonstrate the proposed MC$^2$-SF outperforms several state-of-the-art methods.
Cooperative Learning for Noisy Supervision
Aug 11, 2021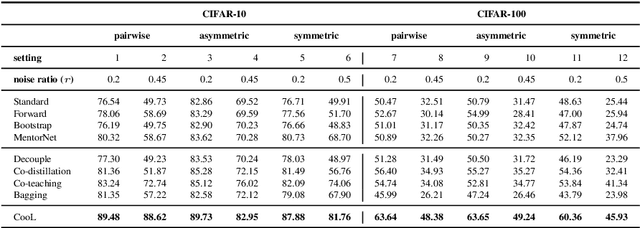
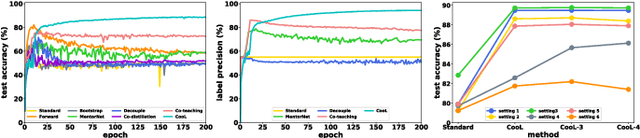
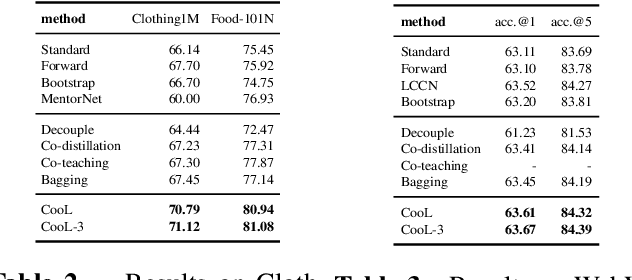
Learning with noisy labels has gained the enormous interest in the robust deep learning area. Recent studies have empirically disclosed that utilizing dual networks can enhance the performance of single network but without theoretic proof. In this paper, we propose Cooperative Learning (CooL) framework for noisy supervision that analytically explains the effects of leveraging dual or multiple networks. Specifically, the simple but efficient combination in CooL yields a more reliable risk minimization for unseen clean data. A range of experiments have been conducted on several benchmarks with both synthetic and real-world settings. Extensive results indicate that CooL outperforms several state-of-the-art methods.
Reliable Adversarial Distillation with Unreliable Teachers
Jun 09, 2021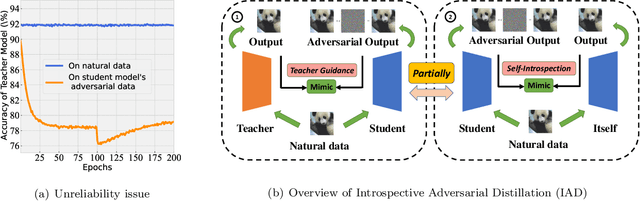
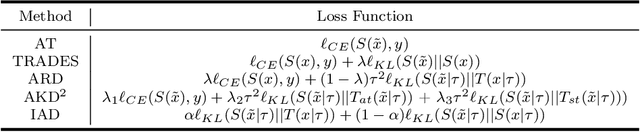
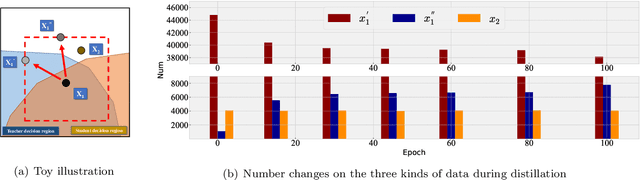
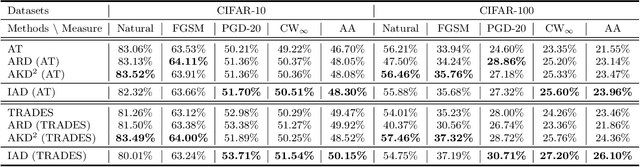
In ordinary distillation, student networks are trained with soft labels (SLs) given by pretrained teacher networks, and students are expected to improve upon teachers since SLs are stronger supervision than the original hard labels. However, when considering adversarial robustness, teachers may become unreliable and adversarial distillation may not work: teachers are pretrained on their own adversarial data, and it is too demanding to require that teachers are also good at every adversarial data queried by students. Therefore, in this paper, we propose reliable introspective adversarial distillation (IAD) where students partially instead of fully trust their teachers. Specifically, IAD distinguishes between three cases given a query of a natural data (ND) and the corresponding adversarial data (AD): (a) if a teacher is good at AD, its SL is fully trusted; (b) if a teacher is good at ND but not AD, its SL is partially trusted and the student also takes its own SL into account; (c) otherwise, the student only relies on its own SL. Experiments demonstrate the effectiveness of IAD for improving upon teachers in terms of adversarial robustness.
Contrastive Conditional Transport for Representation Learning
May 08, 2021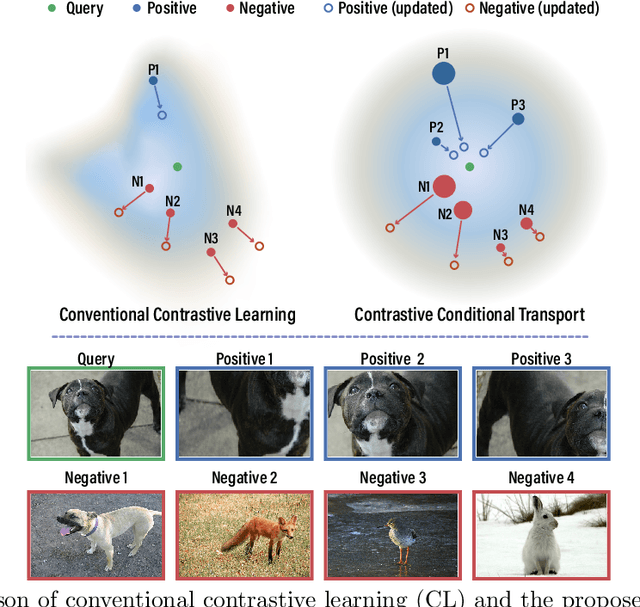
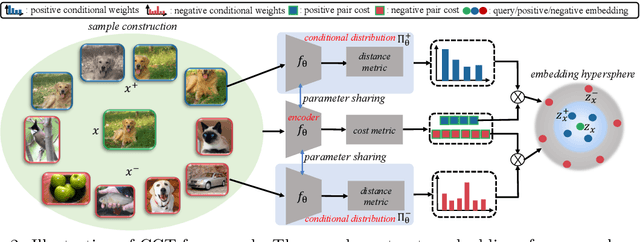
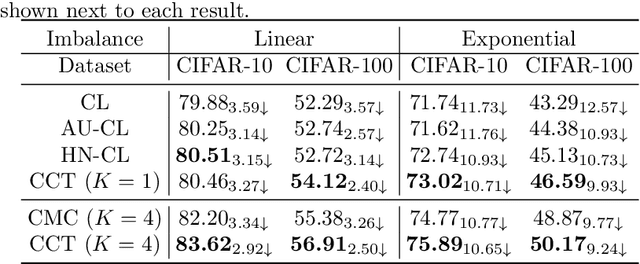
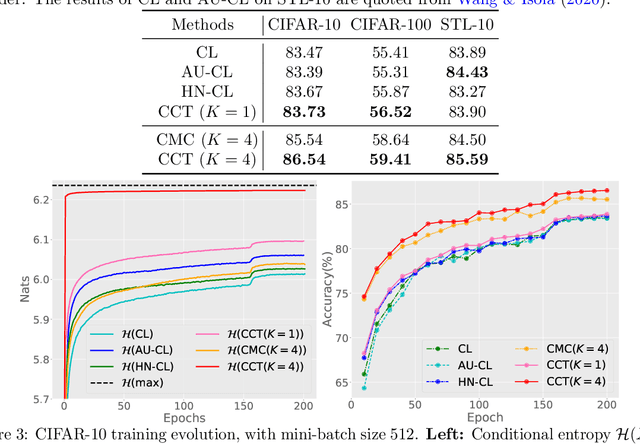
Contrastive learning (CL) has achieved remarkable success in learning data representations without label supervision. However, the conventional CL loss is sensitive to how many negative samples are included and how they are selected. This paper proposes contrastive conditional transport (CCT) that defines its CL loss over dependent sample-query pairs, which in practice is realized by drawing a random query, randomly selecting positive and negative samples, and contrastively reweighting these samples according to their distances to the query, exerting a greater force to both pull more distant positive samples towards the query and push closer negative samples away from the query. Theoretical analysis shows that this unique contrastive reweighting scheme helps in the representation space to both align the positive samples with the query and reduce the mutual information between the negative sample and query. Extensive large-scale experiments on standard vision tasks show that CCT not only consistently outperforms existing methods on benchmark datasets in contrastive representation learning but also provides interpretable contrastive weights and latent representations. PyTorch code will be provided.
Collaborative Label Correction via Entropy Thresholding
Apr 27, 2021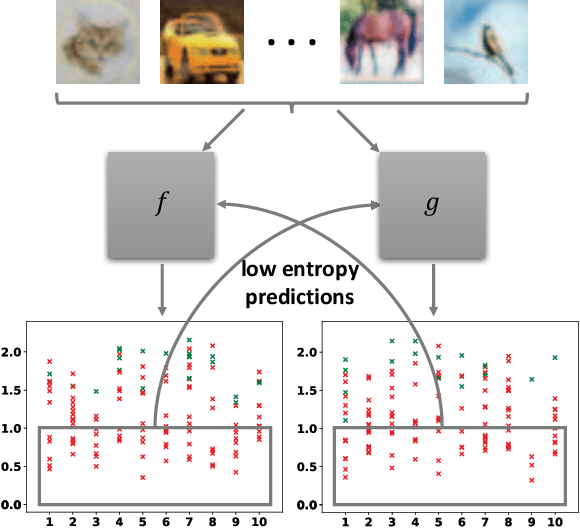
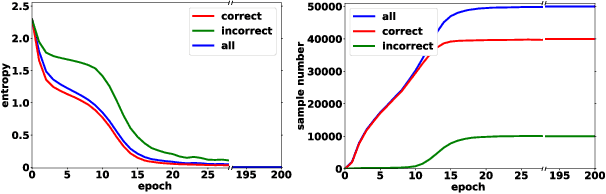

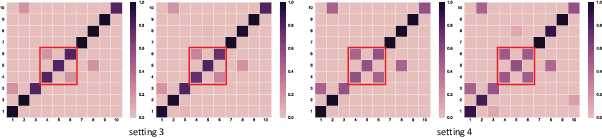
Deep neural networks (DNNs) have the capacity to fit extremely noisy labels nonetheless they tend to learn data with clean labels first and then memorize those with noisy labels. We examine this behavior in light of the Shannon entropy of the predictions and demonstrate the low entropy predictions determined by a given threshold are much more reliable as the supervision than the original noisy labels. It also shows the advantage in maintaining more training samples than previous methods. Then, we power this entropy criterion with the Collaborative Label Correction (CLC) framework to further avoid undesired local minimums of the single network. A range of experiments have been conducted on multiple benchmarks with both synthetic and real-world settings. Extensive results indicate that our CLC outperforms several state-of-the-art methods.
Device-Cloud Collaborative Learning for Recommendation
Apr 14, 2021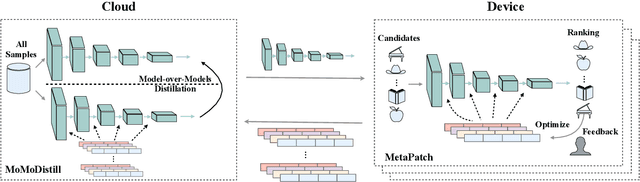
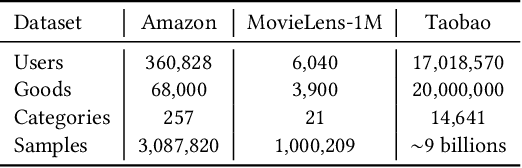
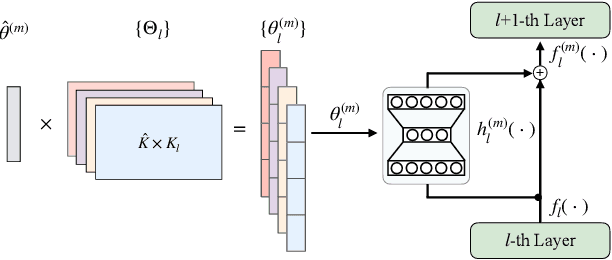
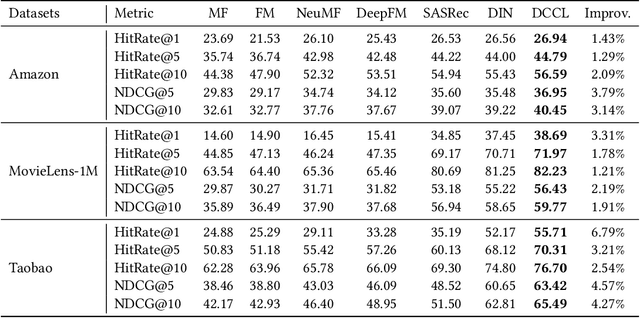
With the rapid development of storage and computing power on mobile devices, it becomes critical and popular to deploy models on devices to save onerous communication latencies and to capture real-time features. While quite a lot of works have explored to facilitate on-device learning and inference, most of them focus on dealing with response delay or privacy protection. Little has been done to model the collaboration between the device and the cloud modeling and benefit both sides jointly. To bridge this gap, we are among the first attempts to study the Device-Cloud Collaborative Learning (DCCL) framework. Specifically, we propose a novel MetaPatch learning approach on the device side to efficiently achieve "thousands of people with thousands of models" given a centralized cloud model. Then, with billions of updated personalized device models, we propose a "model-over-models" distillation algorithm, namely MoMoDistill, to update the centralized cloud model. Our extensive experiments over a range of datasets with different settings demonstrate the effectiveness of such collaboration on both cloud and device sides, especially its superiority in modeling long-tailed users.
Learning with Group Noise
Mar 17, 2021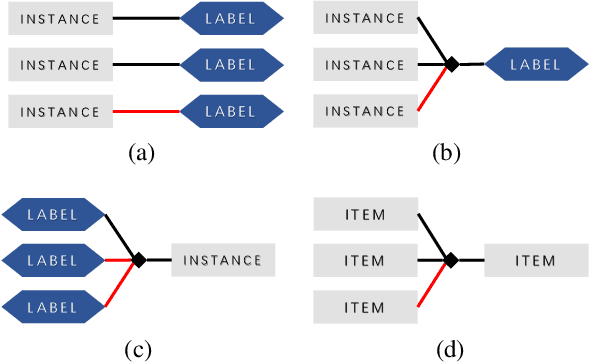
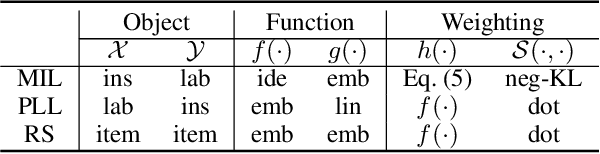
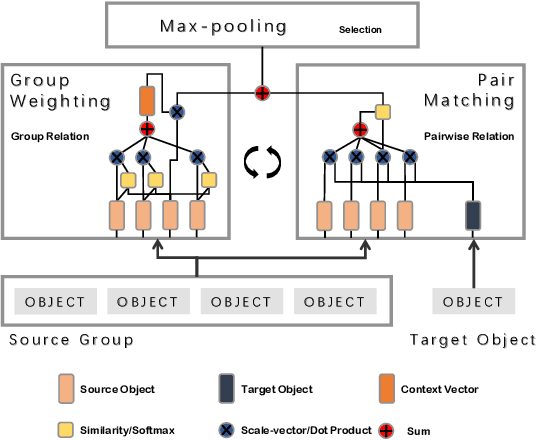
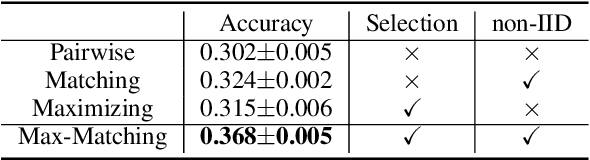
Machine learning in the context of noise is a challenging but practical setting to plenty of real-world applications. Most of the previous approaches in this area focus on the pairwise relation (casual or correlational relationship) with noise, such as learning with noisy labels. However, the group noise, which is parasitic on the coarse-grained accurate relation with the fine-grained uncertainty, is also universal and has not been well investigated. The challenge under this setting is how to discover true pairwise connections concealed by the group relation with its fine-grained noise. To overcome this issue, we propose a novel Max-Matching method for learning with group noise. Specifically, it utilizes a matching mechanism to evaluate the relation confidence of each object w.r.t. the target, meanwhile considering the Non-IID characteristics among objects in the group. Only the most confident object is considered to learn the model, so that the fine-grained noise is mostly dropped. The performance on arange of real-world datasets in the area of several learning paradigms demonstrates the effectiveness of Max-Matching
Sparse-Interest Network for Sequential Recommendation
Feb 18, 2021
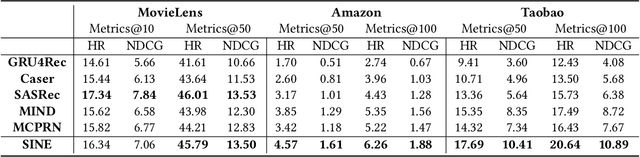
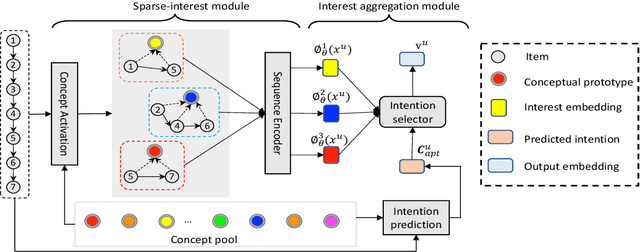
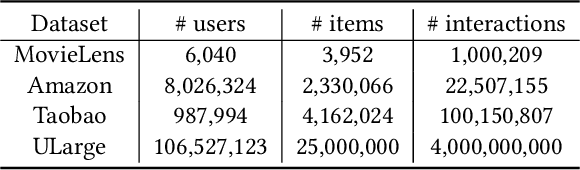
Recent methods in sequential recommendation focus on learning an overall embedding vector from a user's behavior sequence for the next-item recommendation. However, from empirical analysis, we discovered that a user's behavior sequence often contains multiple conceptually distinct items, while a unified embedding vector is primarily affected by one's most recent frequent actions. Thus, it may fail to infer the next preferred item if conceptually similar items are not dominant in recent interactions. To this end, an alternative solution is to represent each user with multiple embedding vectors encoding different aspects of the user's intentions. Nevertheless, recent work on multi-interest embedding usually considers a small number of concepts discovered via clustering, which may not be comparable to the large pool of item categories in real systems. It is a non-trivial task to effectively model a large number of diverse conceptual prototypes, as items are often not conceptually well clustered in fine granularity. Besides, an individual usually interacts with only a sparse set of concepts. In light of this, we propose a novel \textbf{S}parse \textbf{I}nterest \textbf{NE}twork (SINE) for sequential recommendation. Our sparse-interest module can adaptively infer a sparse set of concepts for each user from the large concept pool and output multiple embeddings accordingly. Given multiple interest embeddings, we develop an interest aggregation module to actively predict the user's current intention and then use it to explicitly model multiple interests for next-item prediction. Empirical results on several public benchmark datasets and one large-scale industrial dataset demonstrate that SINE can achieve substantial improvement over state-of-the-art methods.