 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiangchao Yao
Towards Efficient Task-Driven Model Reprogramming with Foundation Models
Apr 05, 2023
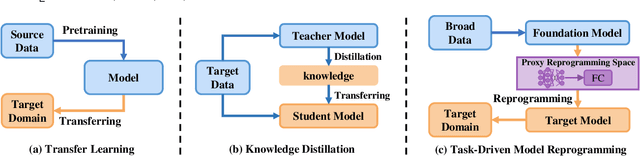
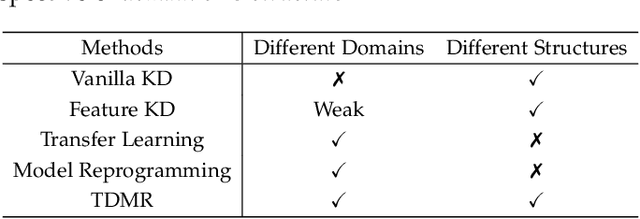
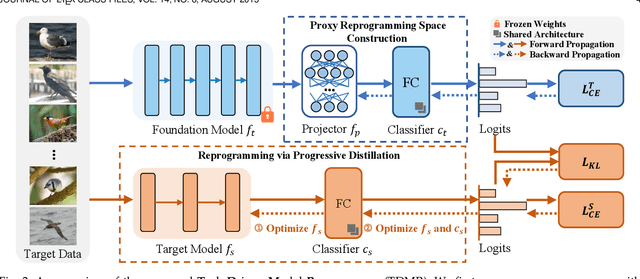
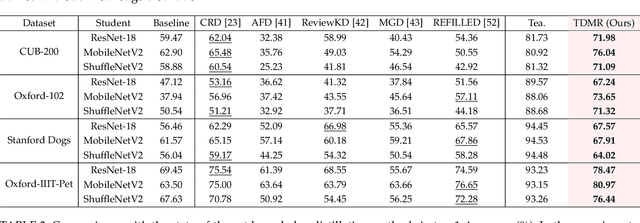
Vision foundation models exhibit impressive power, benefiting from the extremely large model capacity and broad training data. However, in practice, downstream scenarios may only support a small model due to the limited computational resources or efficiency considerations. Moreover, the data used for pretraining foundation models are usually invisible and very different from the target data of downstream tasks. This brings a critical challenge for the real-world application of foundation models: one has to transfer the knowledge of a foundation model to the downstream task that has a quite different architecture with only downstream target data. Existing transfer learning or knowledge distillation methods depend on either the same model structure or finetuning of the foundation model. Thus, naively introducing these methods can be either infeasible or very inefficient. To address this, we propose a Task-Driven Model Reprogramming (TDMR) framework. Specifically, we reprogram the foundation model to project the knowledge into a proxy space, which alleviates the adverse effect of task mismatch and domain inconsistency. Then, we reprogram the target model via progressive distillation from the proxy space to efficiently learn the knowledge from the reprogrammed foundation model. TDMR is compatible with different pre-trained model types (CNN, transformer or their mix) and limited target data, and promotes the wide applications of vision foundation models to downstream tasks in a cost-effective manner. Extensive experiments on different downstream classification tasks and target model structures demonstrate the effectiveness of our methods with both CNNs and transformer foundation models.
Combating Exacerbated Heterogeneity for Robust Models in Federated Learning
Mar 01, 2023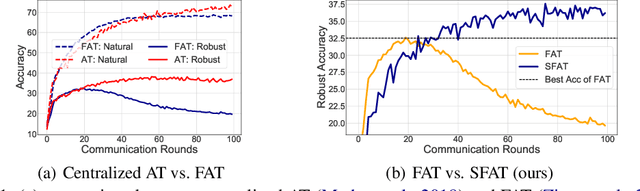
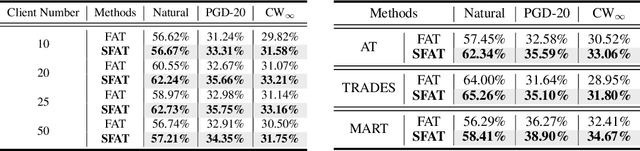

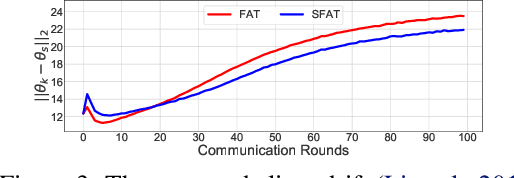
Privacy and security concerns in real-world applications have led to the development of adversarially robust federated models. However, the straightforward combination between adversarial training and federated learning in one framework can lead to the undesired robustness deterioration. We discover that the attribution behind this phenomenon is that the generated adversarial data could exacerbate the data heterogeneity among local clients, making the wrapped federated learning perform poorly. To deal with this problem, we propose a novel framework called Slack Federated Adversarial Training (SFAT), assigning the client-wise slack during aggregation to combat the intensified heterogeneity. Theoretically, we analyze the convergence of the proposed method to properly relax the objective when combining federated learning and adversarial training. Experimentally, we verify the rationality and effectiveness of SFAT on various benchmarked and real-world datasets with different adversarial training and federated optimization methods. The code is publicly available at https://github.com/ZFancy/SFAT.
Latent Class-Conditional Noise Model
Feb 19, 2023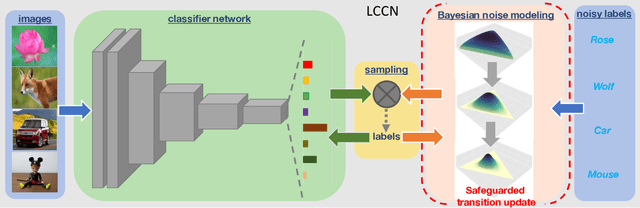
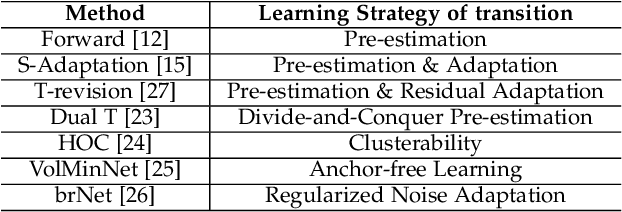

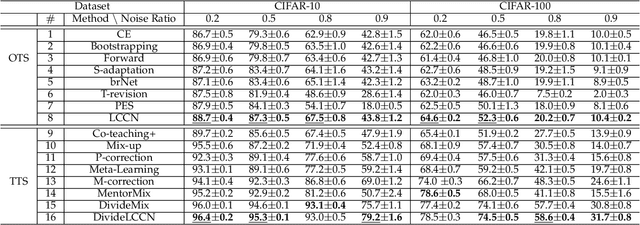
Learning with noisy labels has become imperative in the Big Data era, which saves expensive human labors on accurate annotations. Previous noise-transition-based methods have achieved theoretically-grounded performance under the Class-Conditional Noise model (CCN). However, these approaches builds upon an ideal but impractical anchor set available to pre-estimate the noise transition. Even though subsequent works adapt the estimation as a neural layer, the ill-posed stochastic learning of its parameters in back-propagation easily falls into undesired local minimums. We solve this problem by introducing a Latent Class-Conditional Noise model (LCCN) to parameterize the noise transition under a Bayesian framework. By projecting the noise transition into the Dirichlet space, the learning is constrained on a simplex characterized by the complete dataset, instead of some ad-hoc parametric space wrapped by the neural layer. We then deduce a dynamic label regression method for LCCN, whose Gibbs sampler allows us efficiently infer the latent true labels to train the classifier and to model the noise. Our approach safeguards the stable update of the noise transition, which avoids previous arbitrarily tuning from a mini-batch of samples. We further generalize LCCN to different counterparts compatible with open-set noisy labels, semi-supervised learning as well as cross-model training. A range of experiments demonstrate the advantages of LCCN and its variants over the current state-of-the-art methods.
Long-Tailed Partial Label Learning via Dynamic Rebalancing
Feb 10, 2023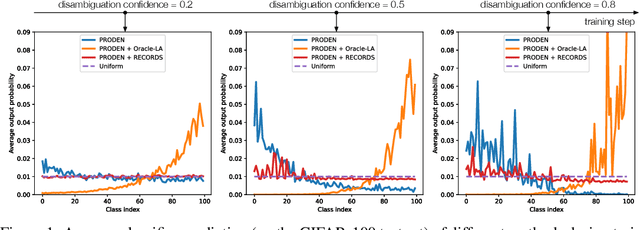
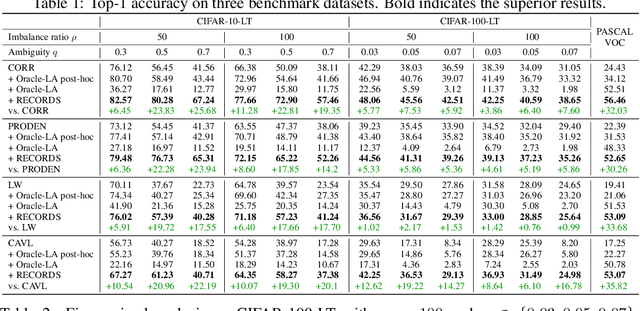
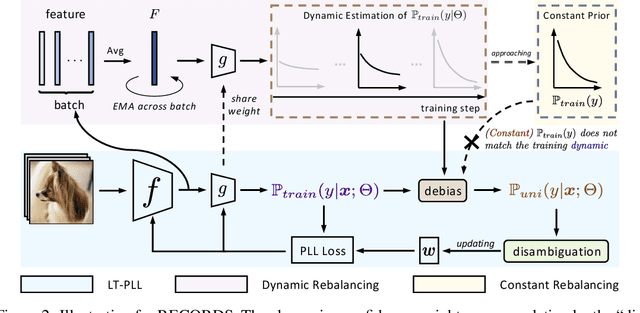
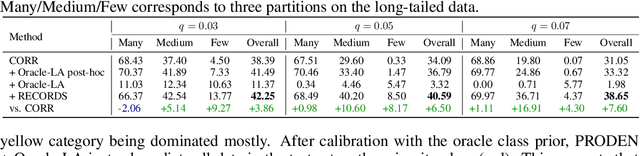
Real-world data usually couples the label ambiguity and heavy imbalance, challenging the algorithmic robustness of partial label learning (PLL) and long-tailed learning (LT). The straightforward combination of LT and PLL, i.e., LT-PLL, suffers from a fundamental dilemma: LT methods build upon a given class distribution that is unavailable in PLL, and the performance of PLL is severely influenced in long-tailed context. We show that even with the auxiliary of an oracle class prior, the state-of-the-art methods underperform due to an adverse fact that the constant rebalancing in LT is harsh to the label disambiguation in PLL. To overcome this challenge, we thus propose a dynamic rebalancing method, termed as RECORDS, without assuming any prior knowledge about the class distribution. Based on a parametric decomposition of the biased output, our method constructs a dynamic adjustment that is benign to the label disambiguation process and theoretically converges to the oracle class prior. Extensive experiments on three benchmark datasets demonstrate the significant gain of RECORDS compared with a range of baselines. The code is publicly available.
FedSkip: Combatting Statistical Heterogeneity with Federated Skip Aggregation
Dec 14, 2022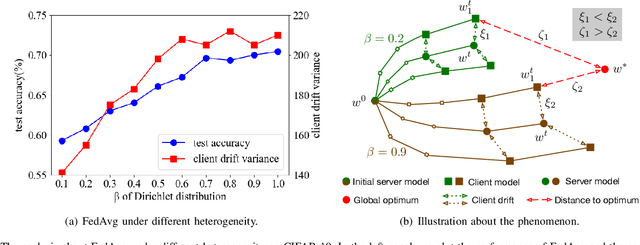
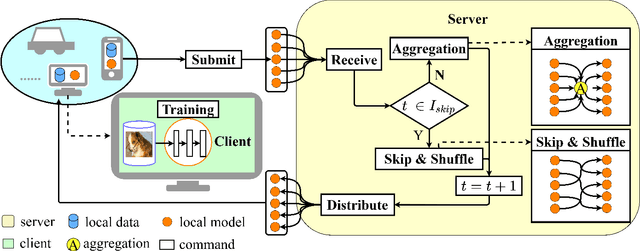
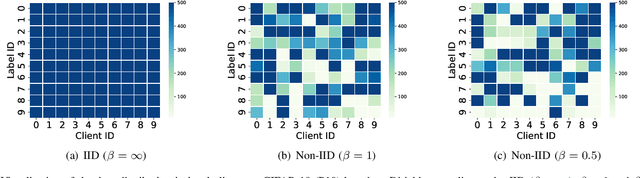
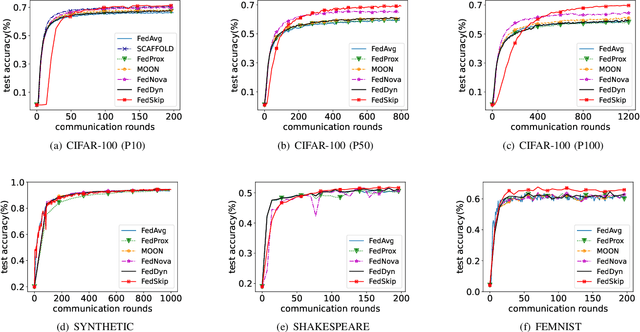
The statistical heterogeneity of the non-independent and identically distributed (non-IID) data in local clients significantly limits the performance of federated learning. Previous attempts like FedProx, SCAFFOLD, MOON, FedNova and FedDyn resort to an optimization perspective, which requires an auxiliary term or re-weights local updates to calibrate the learning bias or the objective inconsistency. However, in addition to previous explorations for improvement in federated averaging, our analysis shows that another critical bottleneck is the poorer optima of client models in more heterogeneous conditions. We thus introduce a data-driven approach called FedSkip to improve the client optima by periodically skipping federated averaging and scattering local models to the cross devices. We provide theoretical analysis of the possible benefit from FedSkip and conduct extensive experiments on a range of datasets to demonstrate that FedSkip achieves much higher accuracy, better aggregation efficiency and competing communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedSkip.
NAS-LID: Efficient Neural Architecture Search with Local Intrinsic Dimension
Nov 24, 2022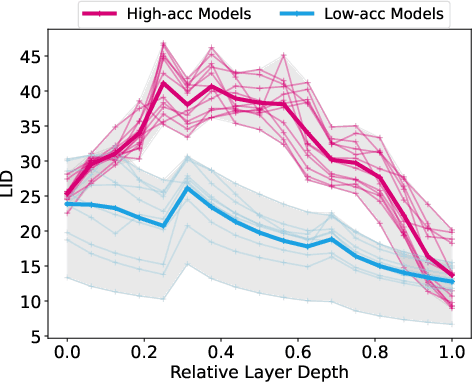
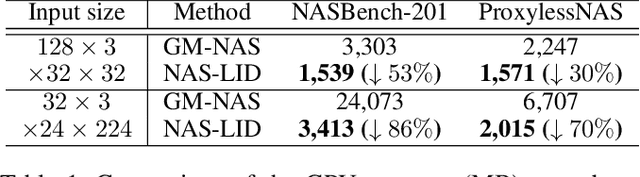
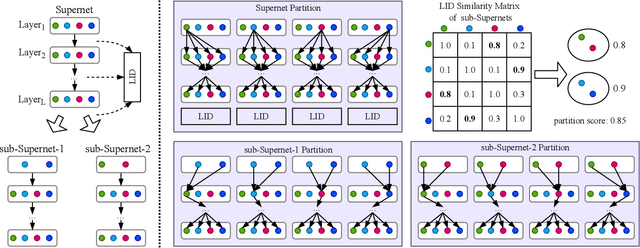

One-shot neural architecture search (NAS) substantially improves the search efficiency by training one supernet to estimate the performance of every possible child architecture (i.e., subnet). However, the inconsistency of characteristics among subnets incurs serious interference in the optimization, resulting in poor performance ranking correlation of subnets. Subsequent explorations decompose supernet weights via a particular criterion, e.g., gradient matching, to reduce the interference; yet they suffer from huge computational cost and low space separability. In this work, we propose a lightweight and effective local intrinsic dimension (LID)-based method NAS-LID. NAS-LID evaluates the geometrical properties of architectures by calculating the low-cost LID features layer-by-layer, and the similarity characterized by LID enjoys better separability compared with gradients, which thus effectively reduces the interference among subnets. Extensive experiments on NASBench-201 indicate that NAS-LID achieves superior performance with better efficiency. Specifically, compared to the gradient-driven method, NAS-LID can save up to 86% of GPU memory overhead when searching on NASBench-201. We also demonstrate the effectiveness of NAS-LID on ProxylessNAS and OFA spaces. Source code: https://github.com/marsggbo/NAS-LID.
Device-Cloud Collaborative Recommendation via Meta Controller
Jul 07, 2022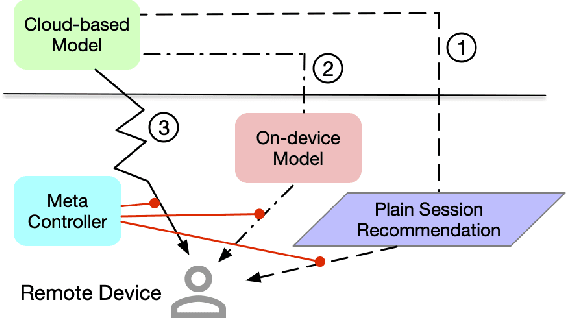
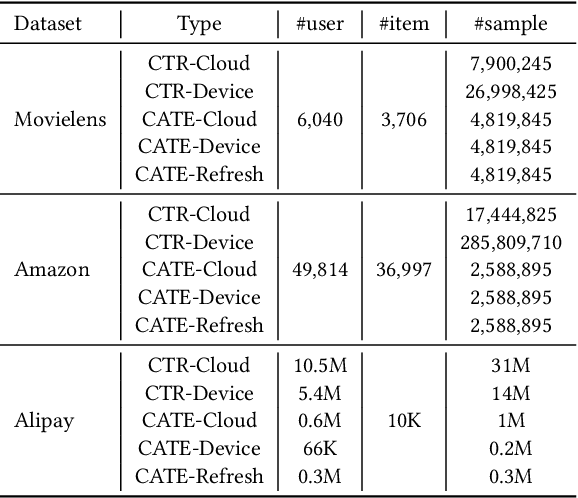
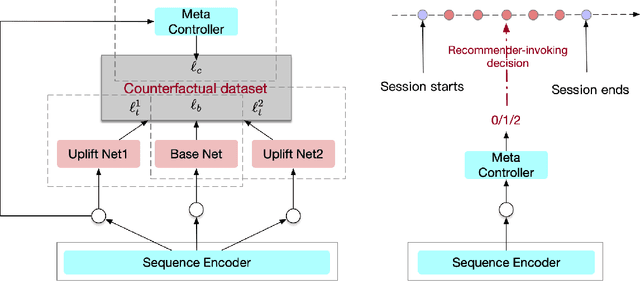
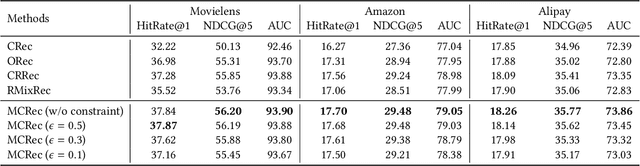
On-device machine learning enables the lightweight deployment of recommendation models in local clients, which reduces the burden of the cloud-based recommenders and simultaneously incorporates more real-time user features. Nevertheless, the cloud-based recommendation in the industry is still very important considering its powerful model capacity and the efficient candidate generation from the billion-scale item pool. Previous attempts to integrate the merits of both paradigms mainly resort to a sequential mechanism, which builds the on-device recommender on top of the cloud-based recommendation. However, such a design is inflexible when user interests dramatically change: the on-device model is stuck by the limited item cache while the cloud-based recommendation based on the large item pool do not respond without the new re-fresh feedback. To overcome this issue, we propose a meta controller to dynamically manage the collaboration between the on-device recommender and the cloud-based recommender, and introduce a novel efficient sample construction from the causal perspective to solve the dataset absence issue of meta controller. On the basis of the counterfactual samples and the extended training, extensive experiments in the industrial recommendation scenarios show the promise of meta controller in the device-cloud collaboration.
Contrastive Learning with Boosted Memorization
Jun 03, 2022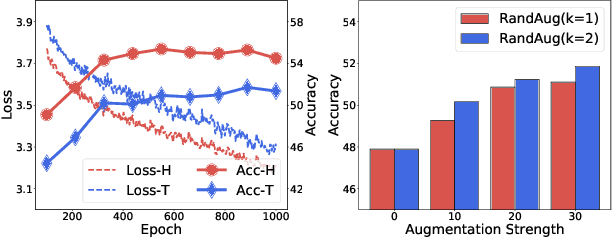
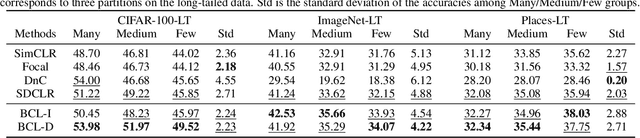
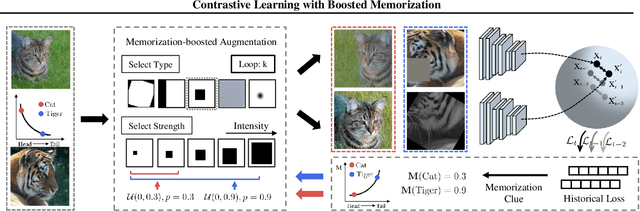
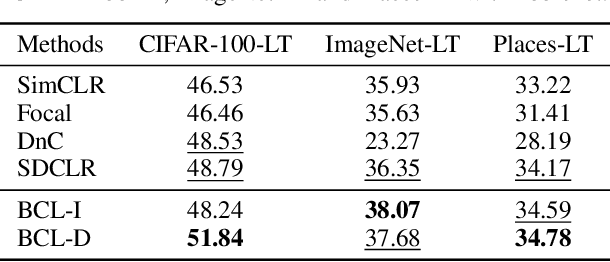
Self-supervised learning has achieved a great success in the representation learning of visual and textual data. However, the current methods are mainly validated on the well-curated datasets, which do not exhibit the real-world long-tailed distribution. Recent attempts to consider self-supervised long-tailed learning are made by rebalancing in the loss perspective or the model perspective, resembling the paradigms in the supervised long-tailed learning. Nevertheless, without the aid of labels, these explorations have not shown the expected significant promise due to the limitation in tail sample discovery or the heuristic structure design. Different from previous works, we explore this direction from an alternative perspective, i.e., the data perspective, and propose a novel Boosted Contrastive Learning (BCL) method. Specifically, BCL leverages the memorization effect of deep neural networks to automatically drive the information discrepancy of the sample views in contrastive learning, which is more efficient to enhance the long-tailed learning in the label-unaware context. Extensive experiments on a range of benchmark datasets demonstrate the effectiveness of BCL over several state-of-the-art methods. Our code is available at https://github.com/MediaBrain-SJTU/BCL.
Edge-Cloud Polarization and Collaboration: A Comprehensive Survey
Nov 12, 2021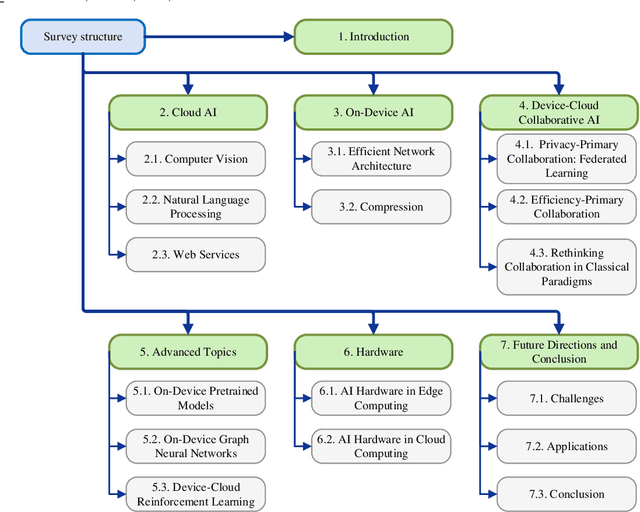
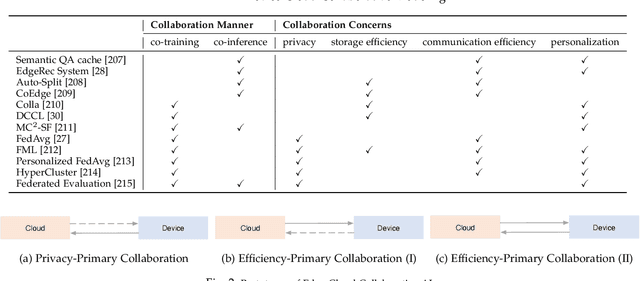
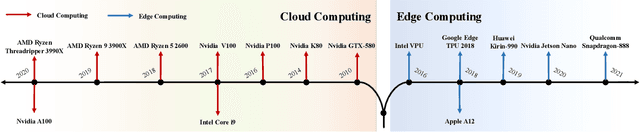
Influenced by the great success of deep learning via cloud computing and the rapid development of edge chips, research in artificial intelligence (AI) has shifted to both of the computing paradigms, i.e., cloud computing and edge computing. In recent years, we have witnessed significant progress in developing more advanced AI models on cloud servers that surpass traditional deep learning models owing to model innovations (e.g., Transformers, Pretrained families), explosion of training data and soaring computing capabilities. However, edge computing, especially edge and cloud collaborative computing, are still in its infancy to announce their success due to the resource-constrained IoT scenarios with very limited algorithms deployed. In this survey, we conduct a systematic review for both cloud and edge AI. Specifically, we are the first to set up the collaborative learning mechanism for cloud and edge modeling with a thorough review of the architectures that enable such mechanism. We also discuss potentials and practical experiences of some on-going advanced edge AI topics including pretraining models, graph neural networks and reinforcement learning. Finally, we discuss the promising directions and challenges in this field.