 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianfeng Gao
Towards Generating Long and Coherent Text with Multi-Level Latent Variable Models
Feb 01, 2019

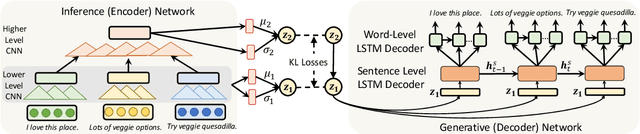
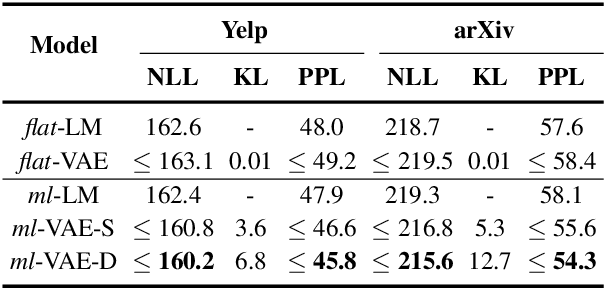
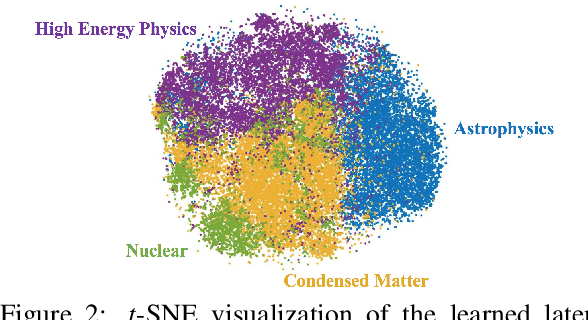
Variational autoencoders (VAEs) have received much attention recently as an end-to-end architecture for text generation with latent variables. In this paper, we investigate several multi-level structures to learn a VAE model to generate long, and coherent text. In particular, we use a hierarchy of stochastic layers between the encoder and decoder networks to generate more informative latent codes. We also investigate a multi-level decoder structure to learn a coherent long-term structure by generating intermediate sentence representations as high-level plan vectors. Empirical results demonstrate that a multi-level VAE model produces more coherent and less repetitive long text compared to the standard VAE models and can further mitigate the posterior-collapse issue.
Multi-Task Deep Neural Networks for Natural Language Understanding
Jan 31, 2019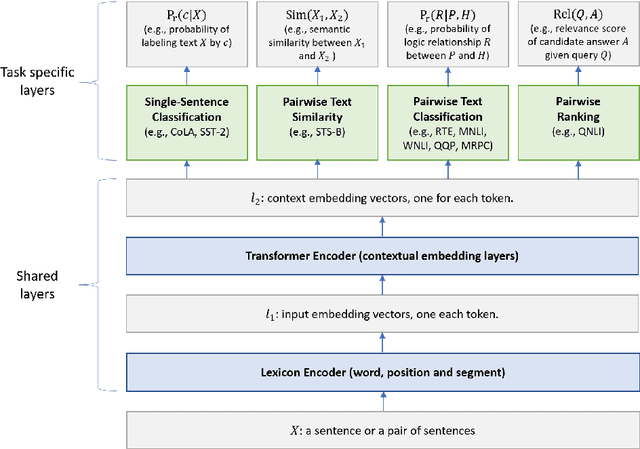
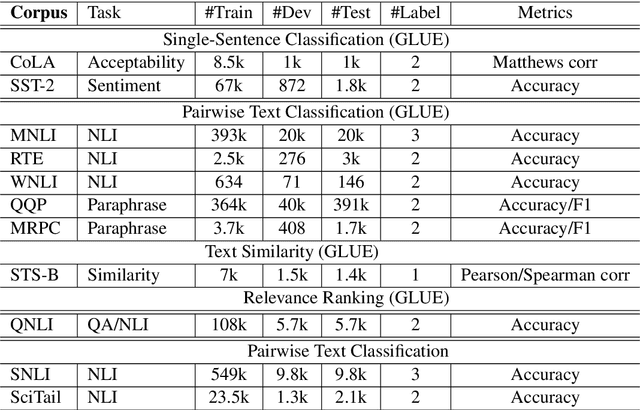
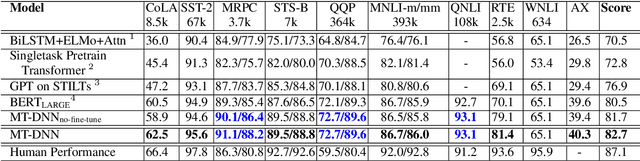
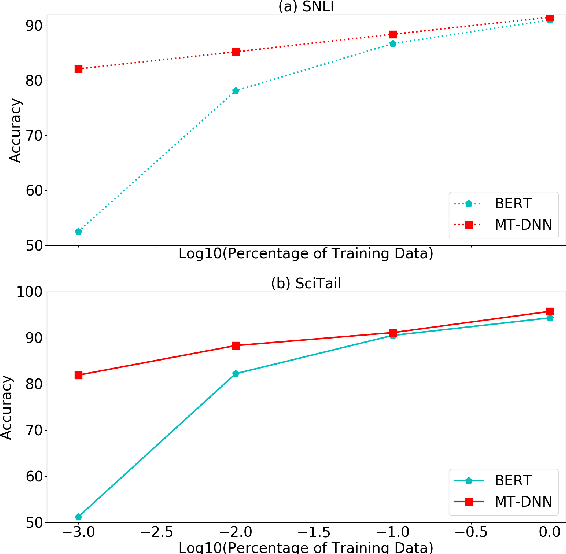
In this paper, we present a Multi-Task Deep Neural Network (MT-DNN) for learning representations across multiple natural language understanding (NLU) tasks. MT-DNN not only leverages large amounts of cross-task data, but also benefits from a regularization effect that leads to more general representations in order to adapt to new tasks and domains. MT-DNN extends the model proposed in Liu et al. (2015) by incorporating a pre-trained bidirectional transformer language model, known as BERT (Devlin et al., 2018). MT-DNN obtains new state-of-the-art results on ten NLU tasks, including SNLI, SciTail, and eight out of nine GLUE tasks, pushing the GLUE benchmark to 82.2% (1.8% absolute improvement). We also demonstrate using the SNLI and SciTail datasets that the representations learned by MT-DNN allow domain adaptation with substantially fewer in-domain labels than the pre-trained BERT representations. Our code and pre-trained models will be made publicly available.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
The Design and Implementation of XiaoIce, an Empathetic Social Chatbot
Dec 21, 2018



This paper describes the development of the Microsoft XiaoIce system, the most popular social chatbot in the world. XiaoIce is uniquely designed as an AI companion with an emotional connection to satisfy the human need for communication, affection, and social belonging. We take into account both intelligent quotient (IQ) and emotional quotient (EQ) in system design, cast human-machine social chat as decision-making over Markov Decision Processes (MDPs), and optimize XiaoIce for long-term user engagement, measured in expected Conversation-turns Per Session (CPS). We detail the system architecture and key components including dialogue manager, core chat, skills, and an empathetic computing module. We show how XiaoIce dynamically recognizes human feelings and states, understands user intents, and responds to user needs throughout long conversations. Since the release in 2014, XiaoIce has communicated with over 660 million users and succeeded in establishing long-term relationships with many of them. Analysis of large-scale online logs shows that XiaoIce has achieved an average CPS of 23, which is significantly higher than that of other chatbots and even human conversations.
Sequential Attention GAN for Interactive Image Editing via Dialogue
Dec 20, 2018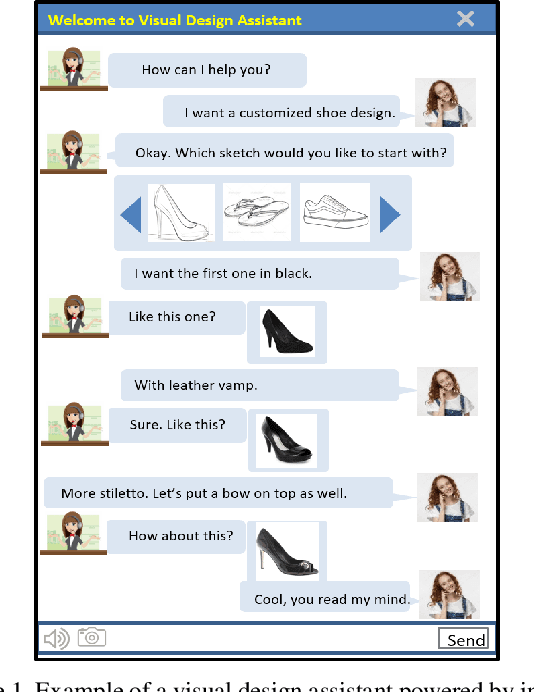
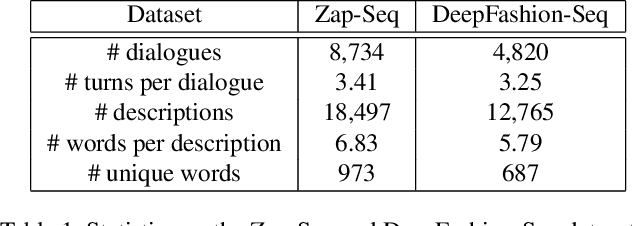

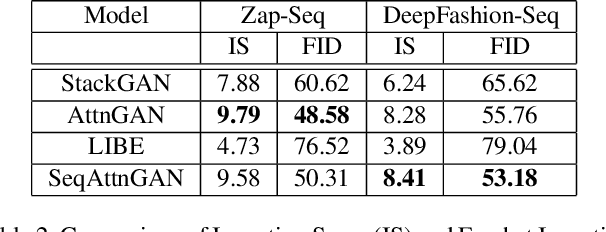
In this paper, we introduce a new task - interactive image editing via conversational language, where users can guide an agent to edit images via multi-turn dialogue in natural language. In each dialogue turn, the agent takes a source image and a natural language description from the user as the input, and generates a target image following the textual description. Two new datasets are created for this task,Zap-Seq and DeepFashion-Seq, collected via crowdsourcing. For this task, we propose a new Sequential Attention Genrative Adversarial Network (SeqAttnGAN) framework, which applies a neural state tracker to encode both source image and textual descriptions, and generates high quality images in each dialogue turn. To achieve better region specific text-to-image generation, we also introducean attention mechanism into the model. Experiments on the two datasets, including quantitative evaluation and user study, show that our model outperforms state-of-the-art ap-proaches in both image quality and text-to-image consistency.
StoryGAN: A Sequential Conditional GAN for Story Visualization
Dec 06, 2018

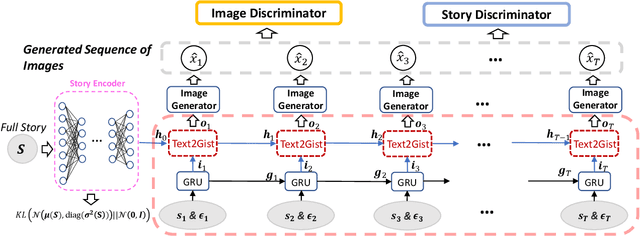
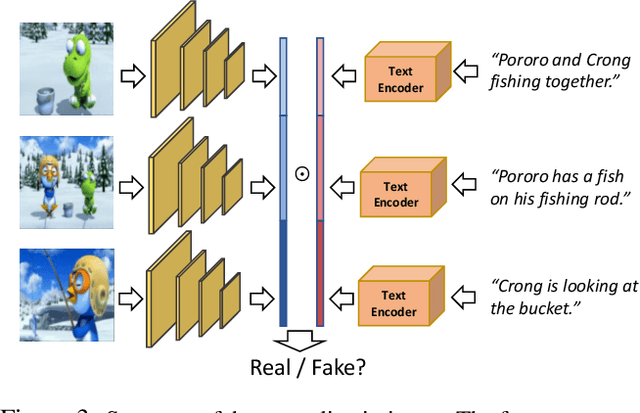
In this work we propose a new task called Story Visualization. Given a multi-sentence paragraph, the story is visualized by generating a sequence of images, one for each sentence. In contrast to video generation, story visualization focuses less on the continuity in generated images (frames), but more on the global consistency across dynamic scenes and characters -- a challenge that has not been addressed by any single-image or video generation methods. Therefore, we propose a new story-to-image-sequence generation model, StoryGAN, based on the sequential conditional GAN framework. Our model is unique in that it consists of a deep Context Encoder that dynamically tracks the story flow, and two discriminators at the story and image levels, respectively, to enhance the image quality and the consistency of the generated sequences. To evaluate the model, we modified existing datasets to create the CLEVR-SV and Pororo-SV datasets. Empirically, StoryGAN outperformed state-of-the-art models in image quality, contextual consistency metrics, and human evaluation.
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
Nov 25, 2018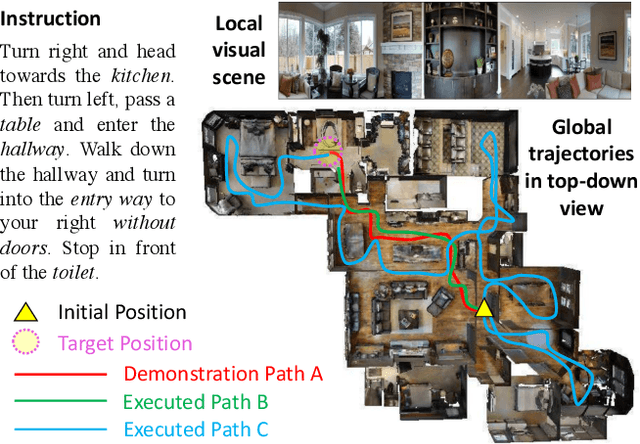
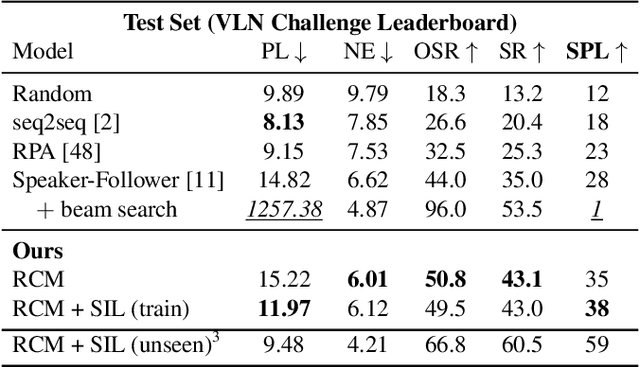
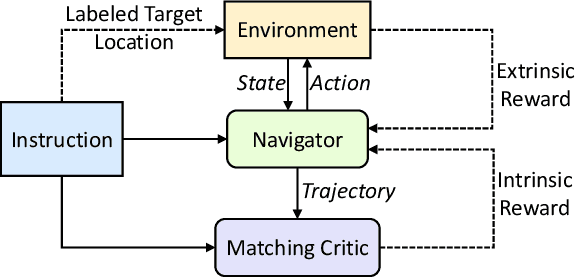
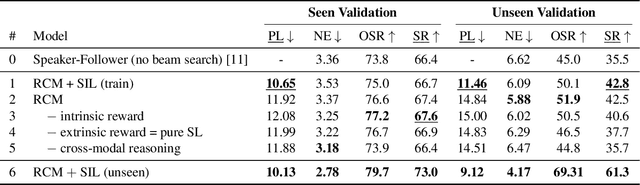
Vision-language navigation (VLN) is the task of navigating an embodied agent to carry out natural language instructions inside real 3D environments. In this paper, we study how to address three critical challenges for this task: the cross-modal grounding, the ill-posed feedback, and the generalization problems. First, we propose a novel Reinforced Cross-Modal Matching (RCM) approach that enforces cross-modal grounding both locally and globally via reinforcement learning (RL). Particularly, a matching critic is used to provide an intrinsic reward to encourage global matching between instructions and trajectories, and a reasoning navigator is employed to perform cross-modal grounding in the local visual scene. Evaluation on a VLN benchmark dataset shows that our RCM model significantly outperforms existing methods by 10% on SPL and achieves the new state-of-the-art performance. To improve the generalizability of the learned policy, we further introduce a Self-Supervised Imitation Learning (SIL) method to explore unseen environments by imitating its own past, good decisions. We demonstrate that SIL can approximate a better and more efficient policy, which tremendously minimizes the success rate performance gap between seen and unseen environments (from 30.7% to 11.7%).
Switch-based Active Deep Dyna-Q: Efficient Adaptive Planning for Task-Completion Dialogue Policy Learning
Nov 19, 2018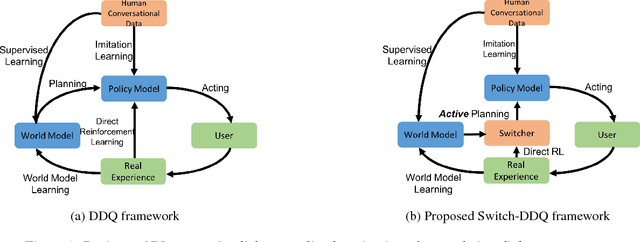

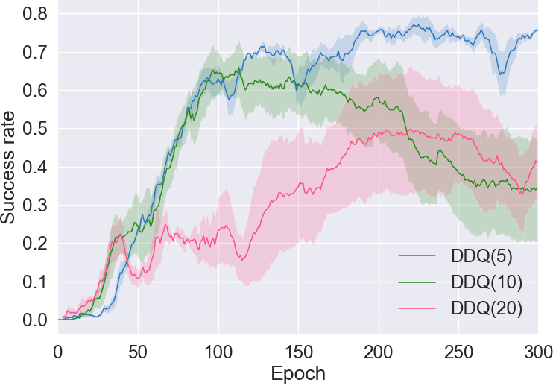
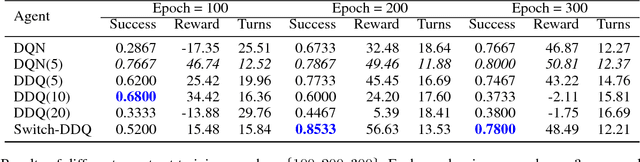
Training task-completion dialogue agents with reinforcement learning usually requires a large number of real user experiences. The Dyna-Q algorithm extends Q-learning by integrating a world model, and thus can effectively boost training efficiency using simulated experiences generated by the world model. The effectiveness of Dyna-Q, however, depends on the quality of the world model - or implicitly, the pre-specified ratio of real vs. simulated experiences used for Q-learning. To this end, we extend the recently proposed Deep Dyna-Q (DDQ) framework by integrating a switcher that automatically determines whether to use a real or simulated experience for Q-learning. Furthermore, we explore the use of active learning for improving sample efficiency, by encouraging the world model to generate simulated experiences in the state-action space where the agent has not (fully) explored. Our results show that by combining switcher and active learning, the new framework named as Switch-based Active Deep Dyna-Q (Switch-DDQ), leads to significant improvement over DDQ and Q-learning baselines in both simulation and human evaluations.
Generating Informative and Diverse Conversational Responses via Adversarial Information Maximization
Nov 03, 2018
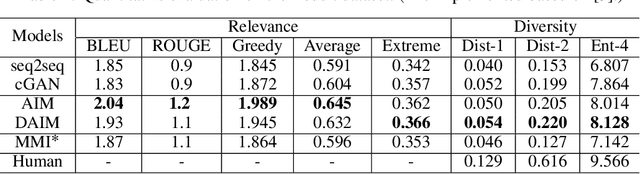

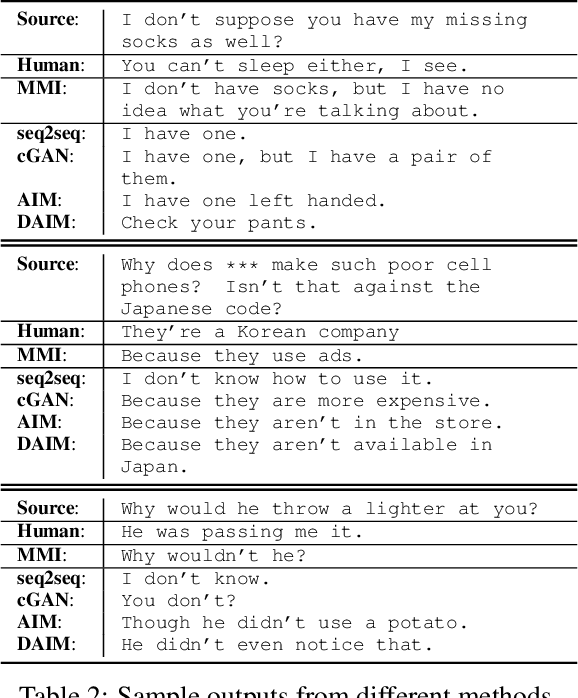
Responses generated by neural conversational models tend to lack informativeness and diversity. We present Adversarial Information Maximization (AIM), an adversarial learning strategy that addresses these two related but distinct problems. To foster response diversity, we leverage adversarial training that allows distributional matching of synthetic and real responses. To improve informativeness, our framework explicitly optimizes a variational lower bound on pairwise mutual information between query and response. Empirical results from automatic and human evaluations demonstrate that our methods significantly boost informativeness and diversity.
A bird's-eye view on coherence, and a worm's-eye view on cohesion
Nov 01, 2018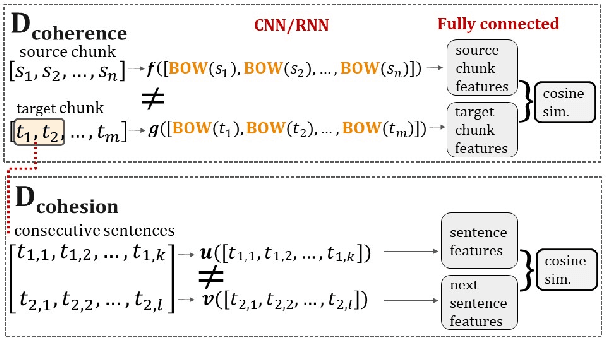
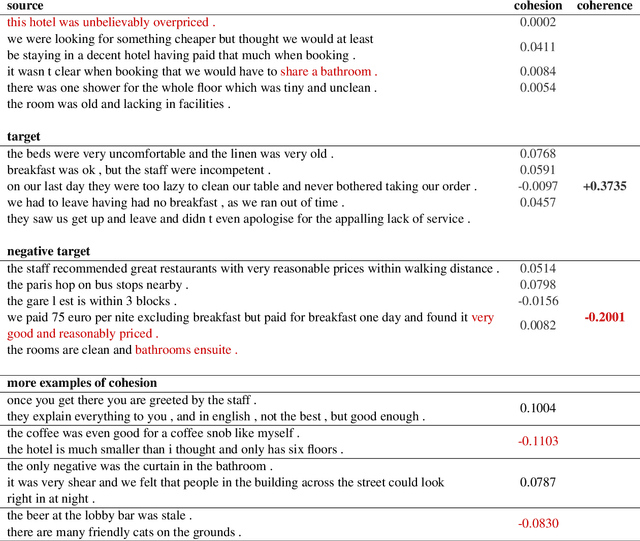


Generating coherent and cohesive long-form texts is a challenging problem in natural language generation. Previous works relied on a large amount of human-generated texts to train language models, however, few attempted to explicitly model the desired linguistic properties of natural language text, such as coherence and cohesion. In this work, we train two expert discriminators for coherence and cohesion, respectively, to provide hierarchical feedback for text generation. We also propose a simple variant of policy gradient, called 'negative-critical sequence training', using margin rewards, in which the 'baseline' is constructed from randomly generated negative samples. We demonstrate the effectiveness of our approach through empirical studies, showing significant improvements over the strong baseline -- attention-based bidirectional MLE-trained neural language model -- in a number of automated metrics. The proposed discriminators can serve as baseline architectures to promote further research to better extract, encode essential linguistic qualities, such as coherence and cohesion.