 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianfeng Gao
Adversarial Training as Stackelberg Game: An Unrolled Optimization Approach
Apr 11, 2021
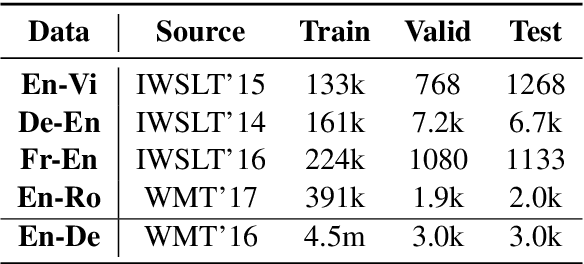
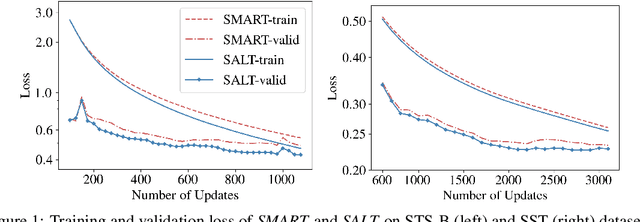
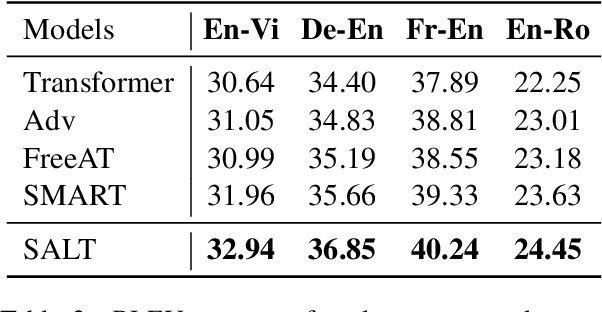
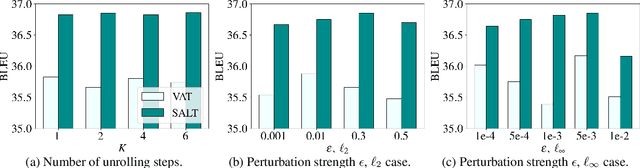
Adversarial training has been shown to improve the generalization performance of deep learning models in various natural language processing tasks. Existing works usually formulate adversarial training as a zero-sum game, which is solved by alternating gradient descent/ascent algorithms. Such a formulation treats the adversarial and the defending players equally, which is undesirable because only the defending player contributes to the generalization performance. To address this issue, we propose Stackelberg Adversarial Training (SALT), which formulates adversarial training as a Stackelberg game. This formulation induces a competition between a leader and a follower, where the follower generates perturbations, and the leader trains the model subject to the perturbations. Different from conventional adversarial training, in SALT, the leader is in an advantageous position. When the leader moves, it recognizes the strategy of the follower and takes the anticipated follower's outcomes into consideration. Such a leader's advantage enables us to improve the model fitting to the unperturbed data. The leader's strategic information is captured by the Stackelberg gradient, which is obtained using an unrolling algorithm. Our experimental results on a set of machine translation and natural language understanding tasks show that SALT outperforms existing adversarial training baselines across all tasks.
Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
Mar 29, 2021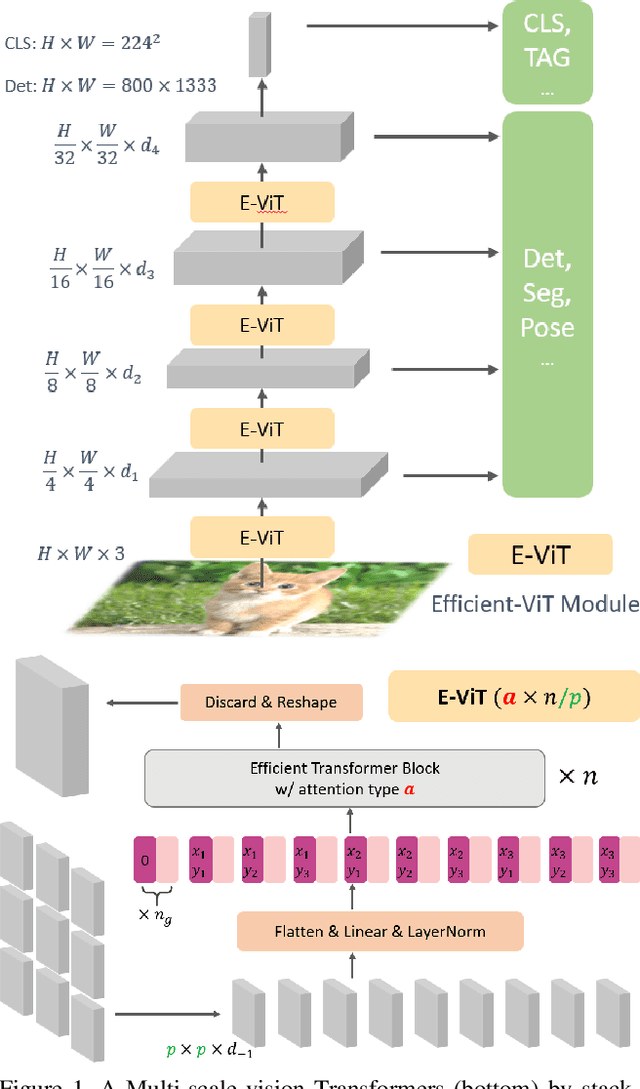
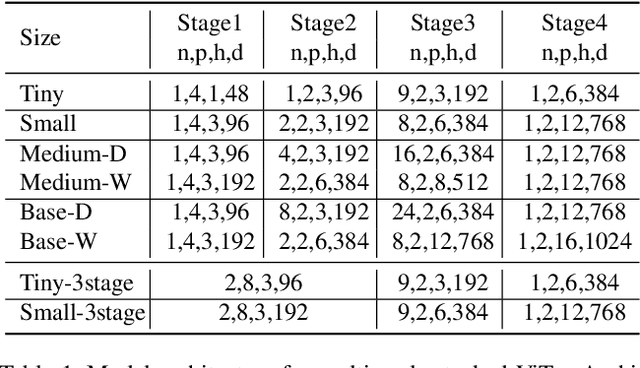
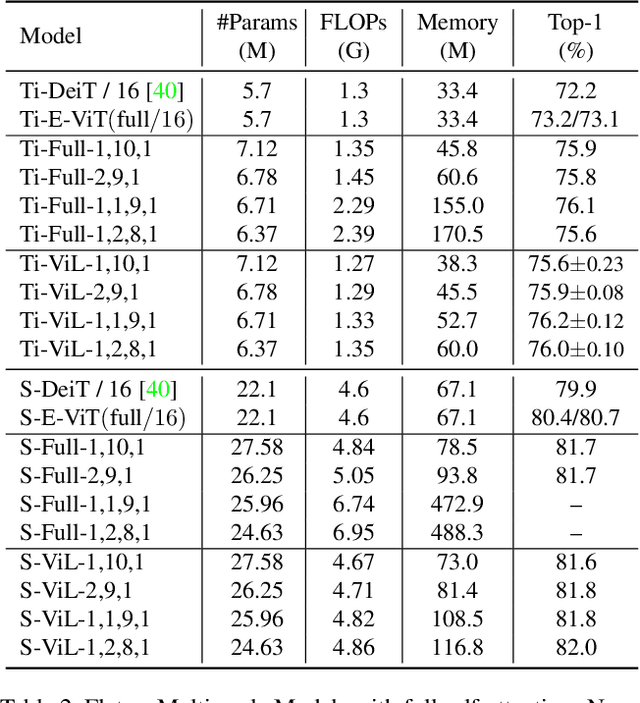
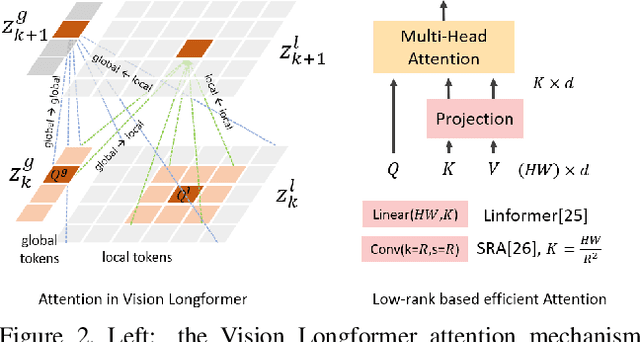
This paper presents a new Vision Transformer (ViT) architecture Multi-Scale Vision Longformer, which significantly enhances the ViT of \cite{dosovitskiy2020image} for encoding high-resolution images using two techniques. The first is the multi-scale model structure, which provides image encodings at multiple scales with manageable computational cost. The second is the attention mechanism of vision Longformer, which is a variant of Longformer \cite{beltagy2020longformer}, originally developed for natural language processing, and achieves a linear complexity w.r.t. the number of input tokens. A comprehensive empirical study shows that the new ViT significantly outperforms several strong baselines, including the existing ViT models and their ResNet counterparts, and the Pyramid Vision Transformer from a concurrent work \cite{wang2021pyramid}, on a range of vision tasks, including image classification, object detection, and segmentation. The models and source code used in this study will be released to public soon.
Token-wise Curriculum Learning for Neural Machine Translation
Mar 20, 2021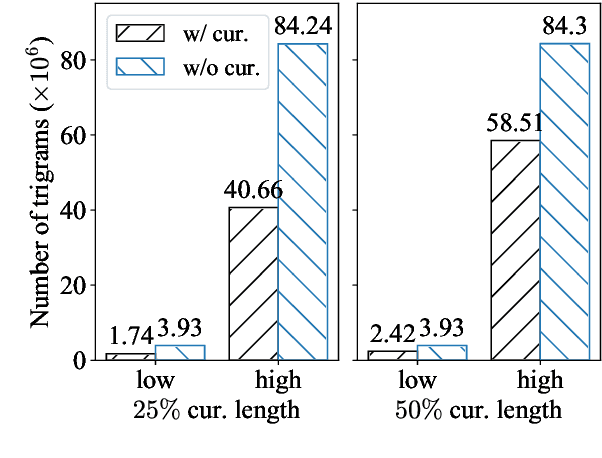
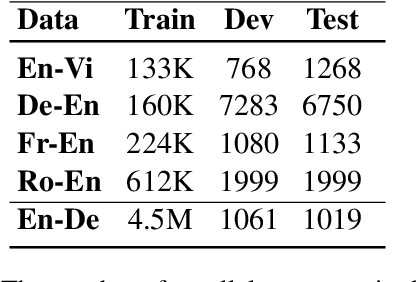
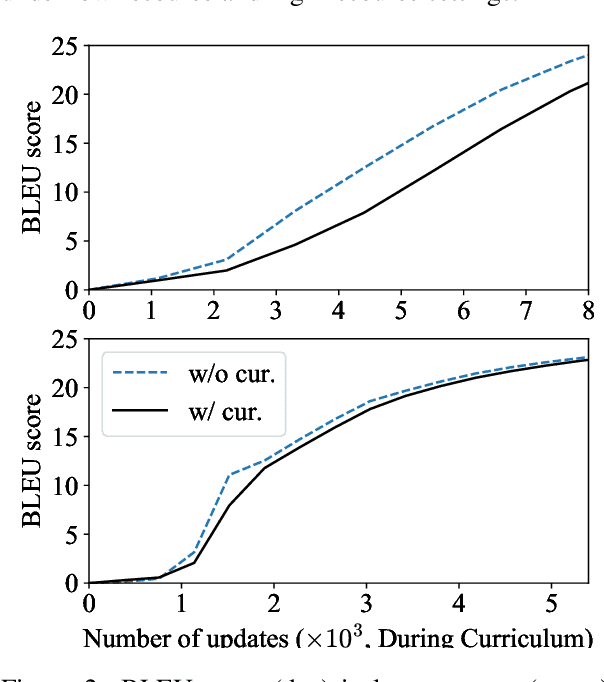
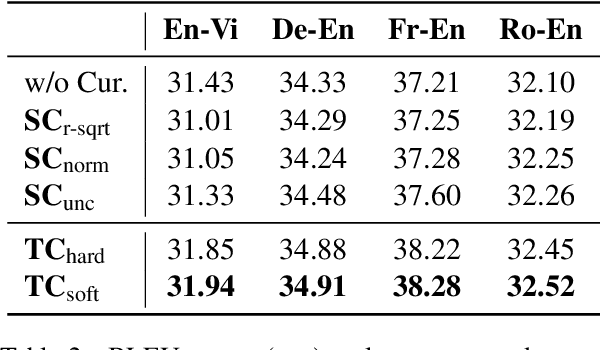
Existing curriculum learning approaches to Neural Machine Translation (NMT) require sampling sufficient amounts of "easy" samples from training data at the early training stage. This is not always achievable for low-resource languages where the amount of training data is limited. To address such limitation, we propose a novel token-wise curriculum learning approach that creates sufficient amounts of easy samples. Specifically, the model learns to predict a short sub-sequence from the beginning part of each target sentence at the early stage of training, and then the sub-sequence is gradually expanded as the training progresses. Such a new curriculum design is inspired by the cumulative effect of translation errors, which makes the latter tokens more difficult to predict than the beginning ones. Extensive experiments show that our approach can consistently outperform baselines on 5 language pairs, especially for low-resource languages. Combining our approach with sentence-level methods further improves the performance on high-resource languages.
Data Augmentation for Abstractive Query-Focused Multi-Document Summarization
Mar 02, 2021
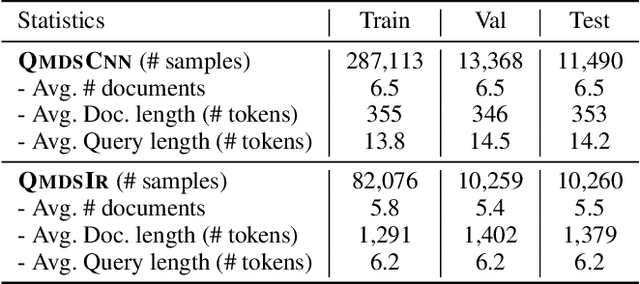
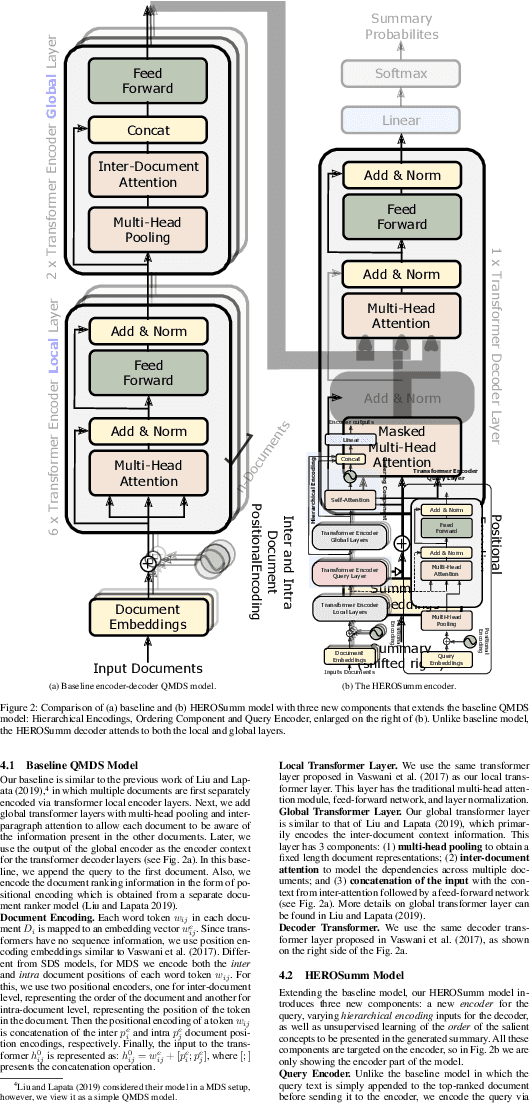
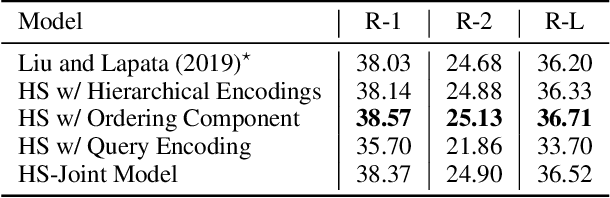
The progress in Query-focused Multi-Document Summarization (QMDS) has been limited by the lack of sufficient largescale high-quality training datasets. We present two QMDS training datasets, which we construct using two data augmentation methods: (1) transferring the commonly used single-document CNN/Daily Mail summarization dataset to create the QMDSCNN dataset, and (2) mining search-query logs to create the QMDSIR dataset. These two datasets have complementary properties, i.e., QMDSCNN has real summaries but queries are simulated, while QMDSIR has real queries but simulated summaries. To cover both these real summary and query aspects, we build abstractive end-to-end neural network models on the combined datasets that yield new state-of-the-art transfer results on DUC datasets. We also introduce new hierarchical encoders that enable a more efficient encoding of the query together with multiple documents. Empirical results demonstrate that our data augmentation and encoding methods outperform baseline models on automatic metrics, as well as on human evaluations along multiple attributes.
Learning to Shift Attention for Motion Generation
Feb 24, 2021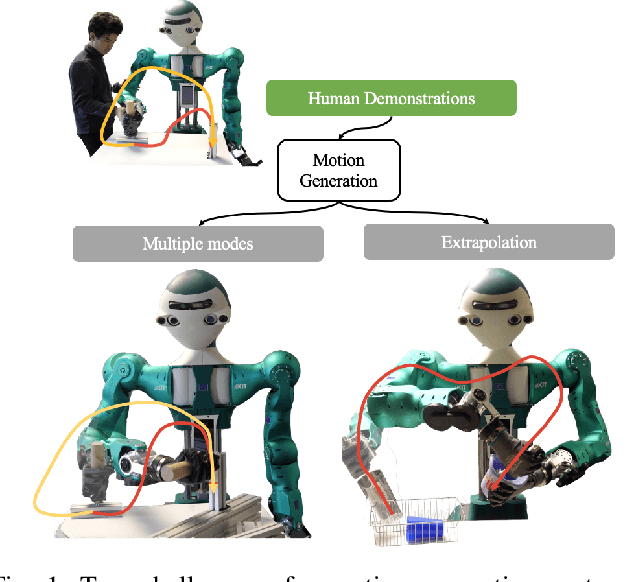
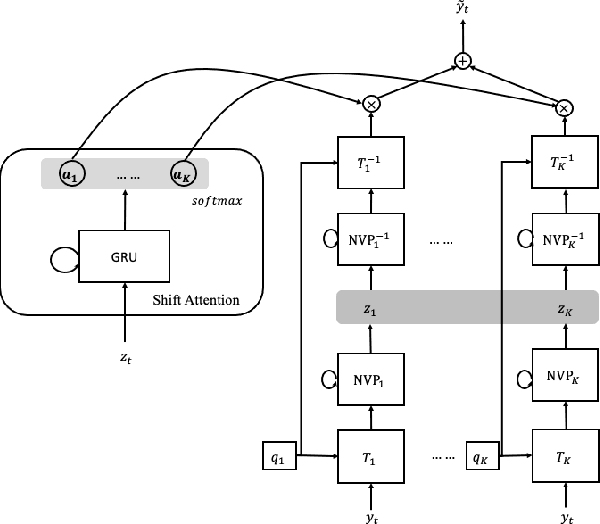
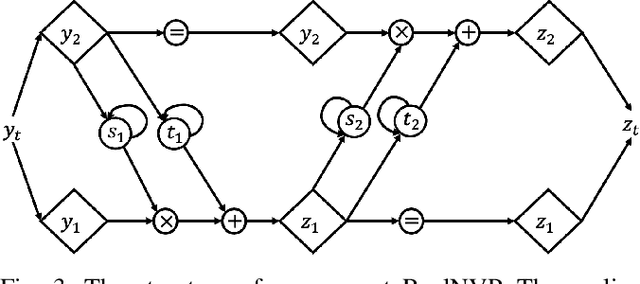
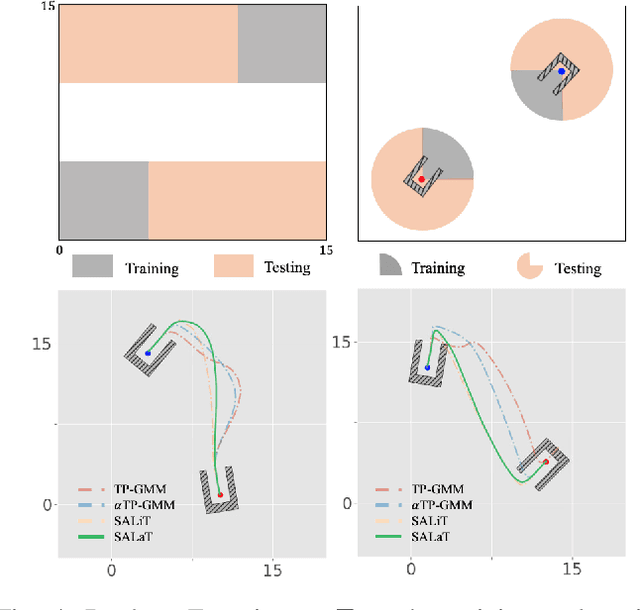
One challenge of motion generation using robot learning from demonstration techniques is that human demonstrations follow a distribution with multiple modes for one task query. Previous approaches fail to capture all modes or tend to average modes of the demonstrations and thus generate invalid trajectories. The other difficulty is the small number of demonstrations that cannot cover the entire working space. To overcome this problem, a motion generation model with extrapolation ability is needed. Previous works restrict task queries as local frames and learn representations in local frames. We propose a model to solve both problems. For multiple modes, we suggest to learn local latent representations of motion trajectories with a density estimation method based on real-valued non-volume preserving (RealNVP) transformations that provides a set of powerful, stably invertible, and learnable transformations. To improve the extrapolation ability, we propose to shift the attention of the robot from one local frame to another during the task execution. In experiments, we consider the docking problem used also in previous works where a trajectory has to be generated to connect two dockers without collision. We increase complexity of the task and show that the proposed method outperforms other approaches. In addition, we evaluate the approach in real robot experiments.
Self-supervised Pre-training with Hard Examples Improves Visual Representations
Jan 04, 2021
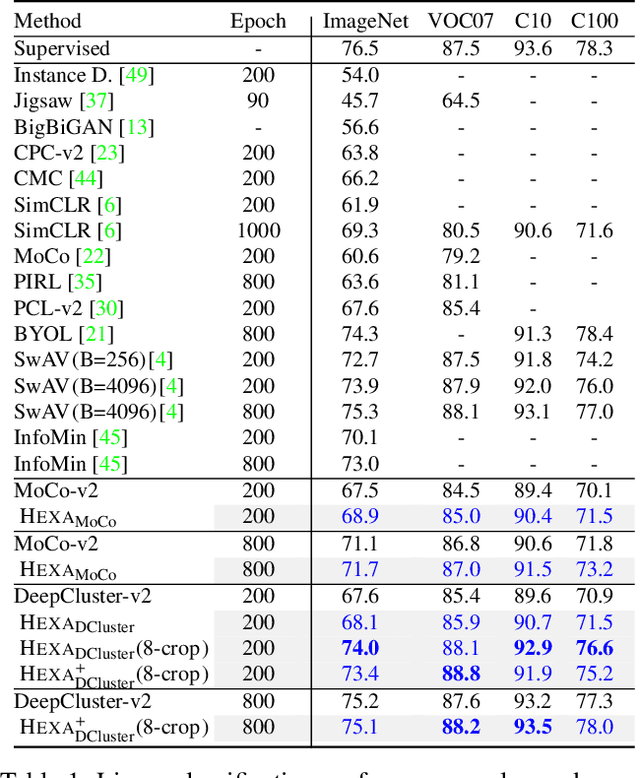
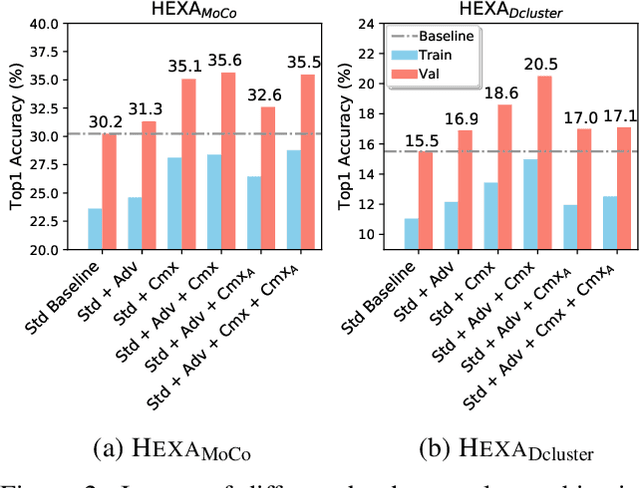
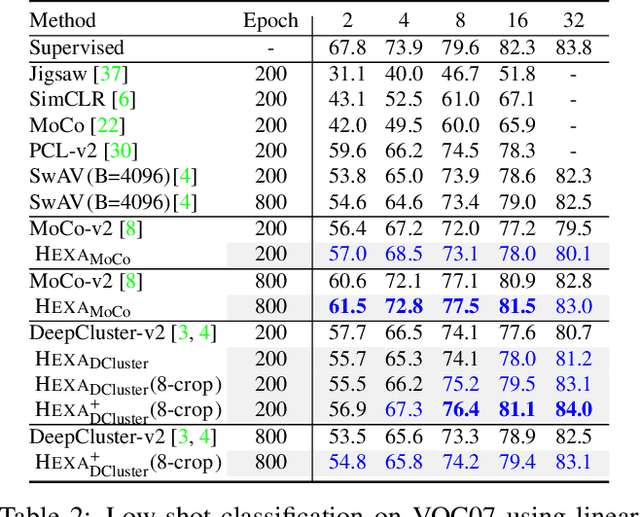
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA_{MoCo} and HEXA_{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.
VinVL: Making Visual Representations Matter in Vision-Language Models
Jan 02, 2021


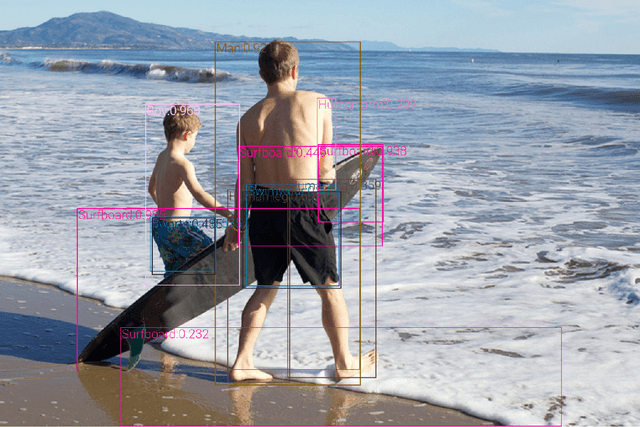
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \emph{bottom-up and top-down} model \cite{anderson2018bottom}, the new model is bigger, better-designed for VL tasks, and pre-trained on much larger training corpora that combine multiple public annotated object detection datasets. Therefore, it can generate representations of a richer collection of visual objects and concepts. While previous VL research focuses mainly on improving the vision-language fusion model and leaves the object detection model improvement untouched, we show that visual features matter significantly in VL models. In our experiments we feed the visual features generated by the new object detection model into a Transformer-based VL fusion model \oscar \cite{li2020oscar}, and utilize an improved approach \short\ to pre-train the VL model and fine-tune it on a wide range of downstream VL tasks. Our results show that the new visual features significantly improve the performance across all VL tasks, creating new state-of-the-art results on seven public benchmarks. We will release the new object detection model to public.
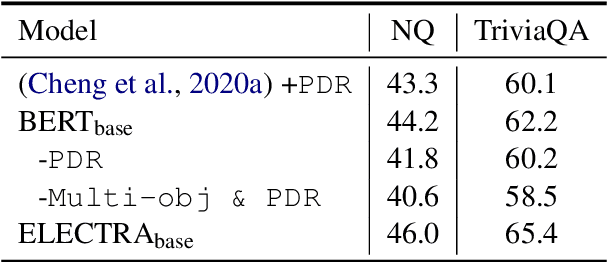
Reader-Guided Passage Reranking for Open-Domain Question Answering
Jan 01, 2021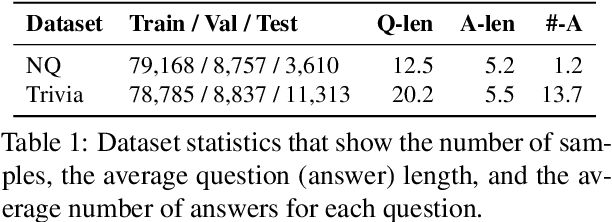
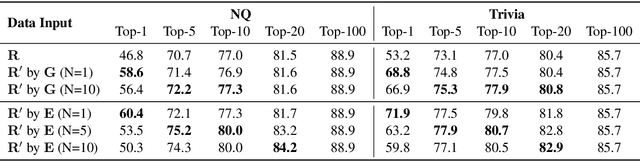
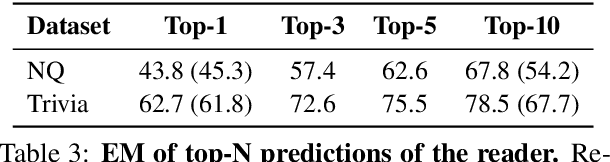
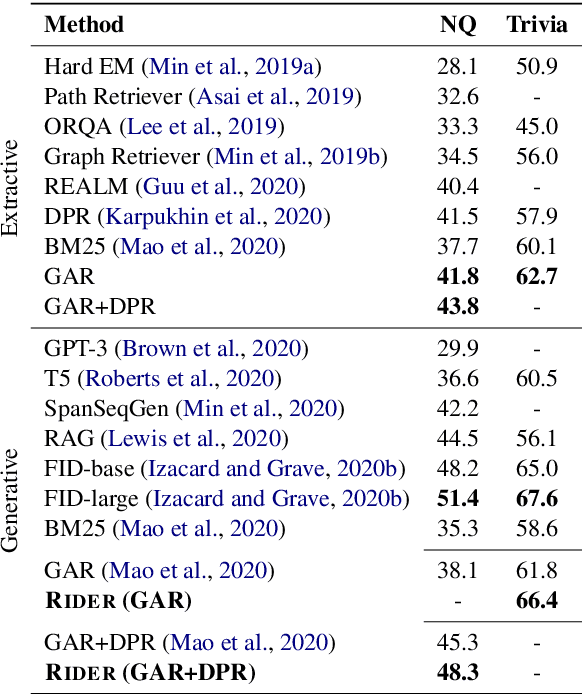
Current open-domain question answering (QA) systems often follow a Retriever-Reader (R2) architecture, where the retriever first retrieves relevant passages and the reader then reads the retrieved passages to form an answer. In this paper, we propose a simple and effective passage reranking method, Reader-guIDEd Reranker (Rider), which does not involve any training and reranks the retrieved passages solely based on the top predictions of the reader before reranking. We show that Rider, despite its simplicity, achieves 10 to 20 absolute gains in top-1 retrieval accuracy and 1 to 4 Exact Match (EM) score gains without refining the retriever or reader. In particular, Rider achieves 48.3 EM on the Natural Questions dataset and 66.4 on the TriviaQA dataset when only 1,024 tokens (7.8 passages on average) are used as the reader input.
UnitedQA: A Hybrid Approach for Open Domain Question Answering
Jan 01, 2021
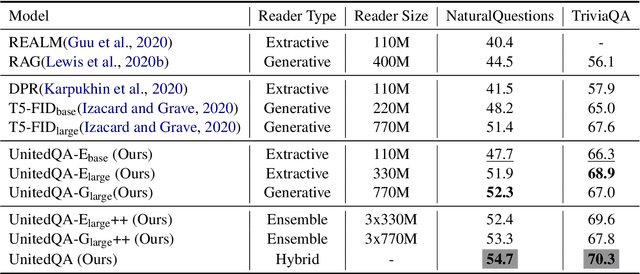
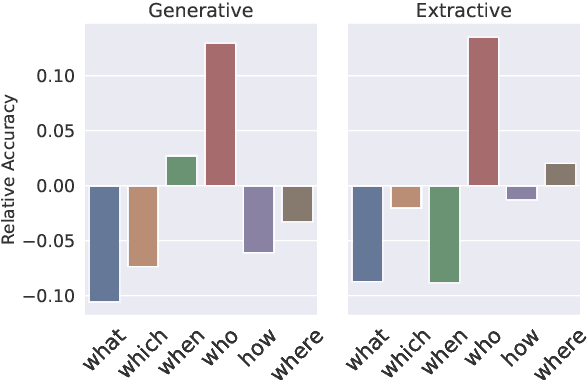
To date, most of recent work under the retrieval-reader framework for open-domain QA focuses on either extractive or generative reader exclusively. In this paper, we study a hybrid approach for leveraging the strengths of both models. We apply novel techniques to enhance both extractive and generative readers built upon recent pretrained neural language models, and find that proper training methods can provide large improvement over previous state-of-the-art models. We demonstrate that a simple hybrid approach by combining answers from both readers can efficiently take advantages of extractive and generative answer inference strategies and outperforms single models as well as homogeneous ensembles. Our approach outperforms previous state-of-the-art models by 3.3 and 2.7 points in exact match on NaturalQuestions and TriviaQA respectively.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021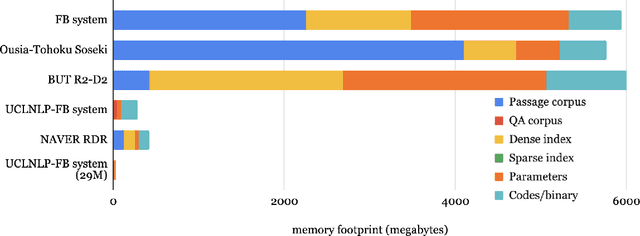
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.