 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Context-Sensitive Decomposition for Low-Light Image Enhancement
Dec 09, 2021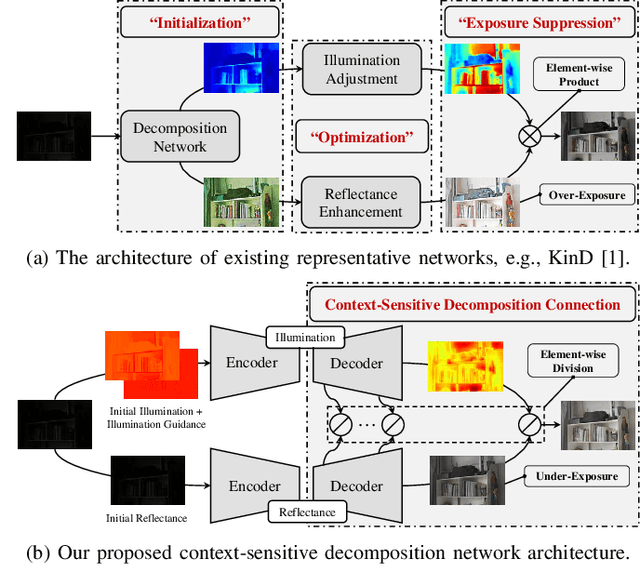
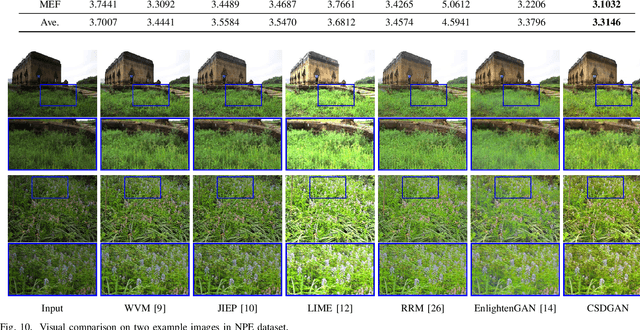

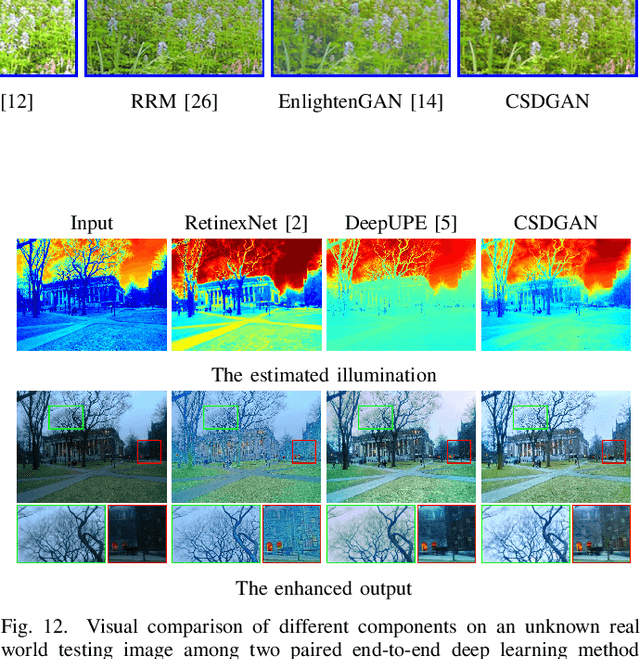
Enhancing the quality of low-light images plays a very important role in many image processing and multimedia applications. In recent years, a variety of deep learning techniques have been developed to address this challenging task. A typical framework is to simultaneously estimate the illumination and reflectance, but they disregard the scene-level contextual information encapsulated in feature spaces, causing many unfavorable outcomes, e.g., details loss, color unsaturation, artifacts, and so on. To address these issues, we develop a new context-sensitive decomposition network architecture to exploit the scene-level contextual dependencies on spatial scales. More concretely, we build a two-stream estimation mechanism including reflectance and illumination estimation network. We design a novel context-sensitive decomposition connection to bridge the two-stream mechanism by incorporating the physical principle. The spatially-varying illumination guidance is further constructed for achieving the edge-aware smoothness property of the illumination component. According to different training patterns, we construct CSDNet (paired supervision) and CSDGAN (unpaired supervision) to fully evaluate our designed architecture. We test our method on seven testing benchmarks to conduct plenty of analytical and evaluated experiments. Thanks to our designed context-sensitive decomposition connection, we successfully realized excellent enhanced results, which fully indicates our superiority against existing state-of-the-art approaches. Finally, considering the practical needs for high-efficiency, we develop a lightweight CSDNet (named LiteCSDNet) by reducing the number of channels. Further, by sharing an encoder for these two components, we obtain a more lightweight version (SLiteCSDNet for short). SLiteCSDNet just contains 0.0301M parameters but achieves the almost same performance as CSDNet.
Retinex-inspired Unrolling with Cooperative Prior Architecture Search for Low-light Image Enhancement
Dec 10, 2020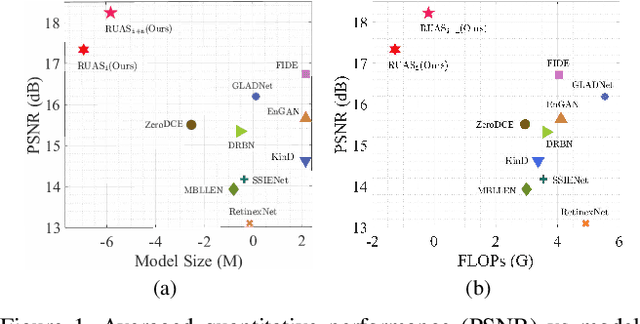

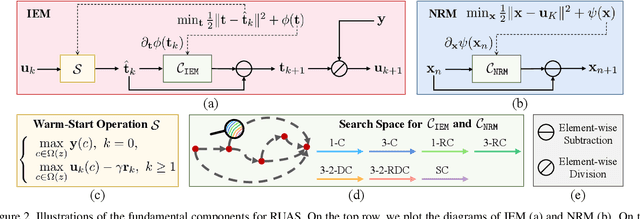

Low-light image enhancement plays very important roles in low-level vision field. Recent works have built a large variety of deep learning models to address this task. However, these approaches mostly rely on significant architecture engineering and suffer from high computational burden. In this paper, we propose a new method, named Retinex-inspired Unrolling with Architecture Search (RUAS), to construct lightweight yet effective enhancement network for low-light images in real-world scenario. Specifically, building upon Retinex rule, RUAS first establishes models to characterize the intrinsic underexposed structure of low-light images and unroll their optimization processes to construct our holistic propagation structure. Then by designing a cooperative reference-free learning strategy to discover low-light prior architectures from a compact search space, RUAS is able to obtain a top-performing image enhancement network, which is with fast speed and requires few computational resources. Extensive experiments verify the superiority of our RUAS framework against recently proposed state-of-the-art methods.