 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBespoke vs. Prêt-à-Porter Lottery Tickets: Exploiting Mask Similarity for Trainable Sub-Network Finding
Jul 06, 2020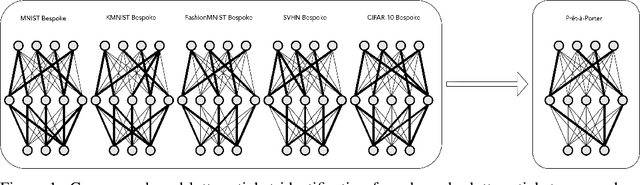
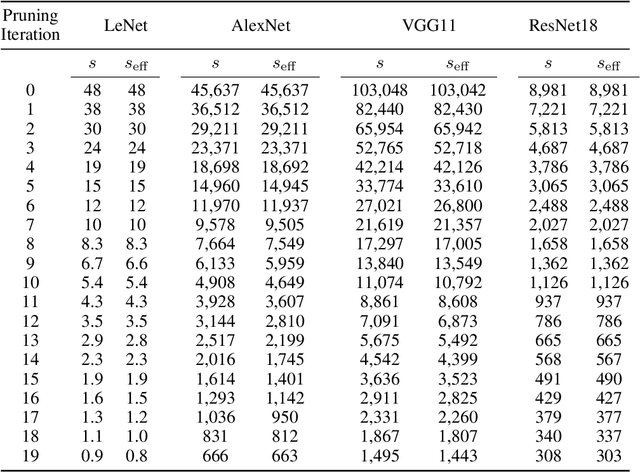
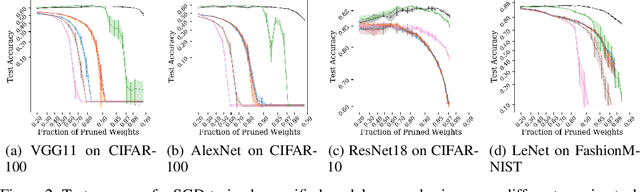
The observation of sparse trainable sub-networks within over-parametrized networks - also known as Lottery Tickets (LTs) - has prompted inquiries around their trainability, scaling, uniqueness, and generalization properties. Across 28 combinations of image classification tasks and architectures, we discover differences in the connectivity structure of LTs found through different iterative pruning techniques, thus disproving their uniqueness and connecting emergent mask structure to the choice of pruning. In addition, we propose a consensus-based method for generating refined lottery tickets. This lottery ticket denoising procedure, based on the principle that parameters that always go unpruned across different tasks more reliably identify important sub-networks, is capable of selecting a meaningful portion of the architecture in an embarrassingly parallel way, while quickly discarding extra parameters without the need for further pruning iterations. We successfully train these sub-networks to performance comparable to that of ordinary lottery tickets.
dagger: A Python Framework for Reproducible Machine Learning Experiment Orchestration
Jun 12, 2020
Many research directions in machine learning, particularly in deep learning, involve complex, multi-stage experiments, commonly involving state-mutating operations acting on models along multiple paths of execution. Although machine learning frameworks provide clean interfaces for defining model architectures and unbranched flows, burden is often placed on the researcher to track experimental provenance, that is, the state tree that leads to a final model configuration and result in a multi-stage experiment. Originally motivated by analysis reproducibility in the context of neural network pruning research, where multi-stage experiment pipelines are common, we present dagger, a framework to facilitate reproducible and reusable experiment orchestration. We describe the design principles of the framework and example usage.
Individual predictions matter: Assessing the effect of data ordering in training fine-tuned CNNs for medical imaging
Dec 08, 2019
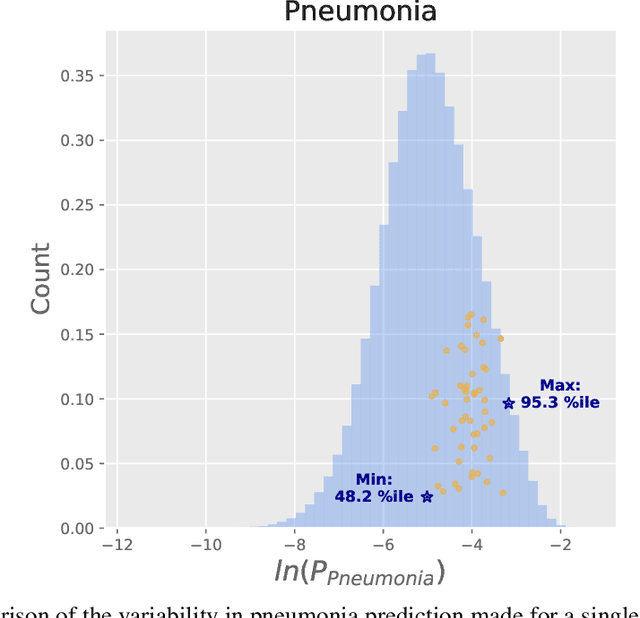
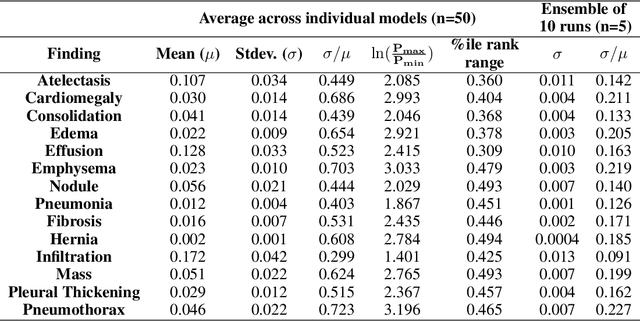
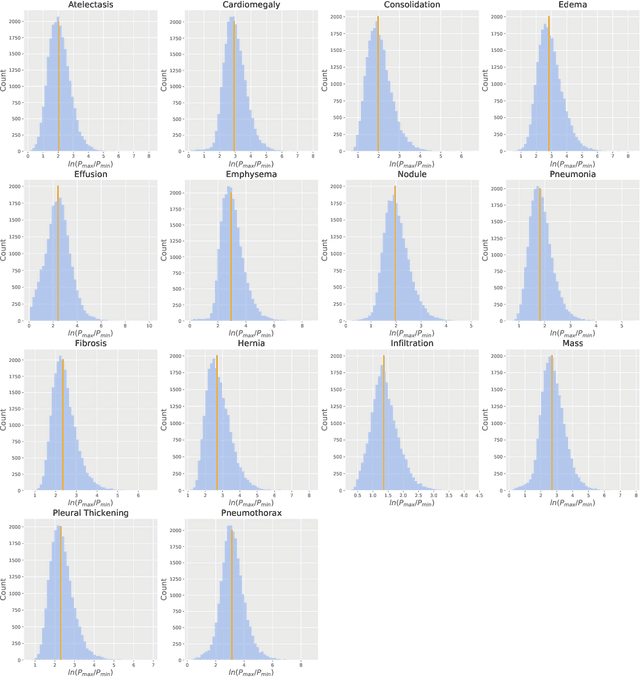
We reproduced the results of CheXNet with fixed hyperparameters and 50 different random seeds to identify 14 finding in chest radiographs (x-rays). Because CheXNet fine-tunes a pre-trained DenseNet, the random seed affects the ordering of the batches of training data but not the initialized model weights. We found substantial variability in predictions for the same radiograph across model runs (mean ln[(maximum probability)/(minimum probability)] 2.45, coefficient of variation 0.543). This individual radiograph-level variability was not fully reflected in the variability of AUC on a large test set. Averaging predictions from 10 models reduced variability by nearly 70% (mean coefficient of variation from 0.543 to 0.169, t-test 15.96, p-value < 0.0001). We encourage researchers to be aware of the potential variability of CNNs and ensemble predictions from multiple models to minimize the effect this variability may have on the care of individual patients when these models are deployed clinically.
The Scientific Method in the Science of Machine Learning
Apr 24, 2019In the quest to align deep learning with the sciences to address calls for rigor, safety, and interpretability in machine learning systems, this contribution identifies key missing pieces: the stages of hypothesis formulation and testing, as well as statistical and systematic uncertainty estimation -- core tenets of the scientific method. This position paper discusses the ways in which contemporary science is conducted in other domains and identifies potentially useful practices. We present a case study from physics and describe how this field has promoted rigor through specific methodological practices, and provide recommendations on how machine learning researchers can adopt these practices into the research ecosystem. We argue that both domain-driven experiments and application-agnostic questions of the inner workings of fundamental building blocks of machine learning models ought to be examined with the tools of the scientific method, to ensure we not only understand effect, but also begin to understand cause, which is the raison d'\^{e}tre of science.