 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Level Feature Abstraction from Convolutional Neural Networks for Multimodal Biometric Identification
Jul 03, 2018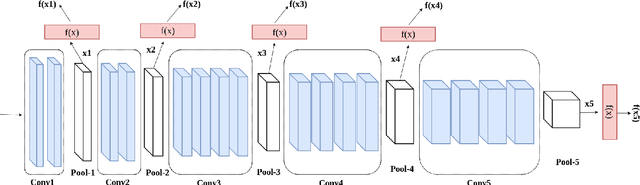
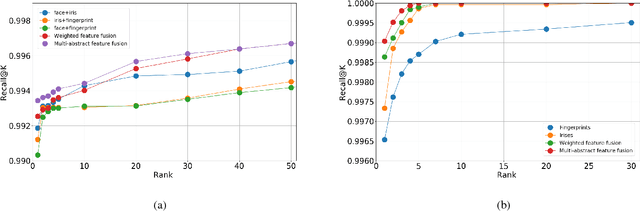
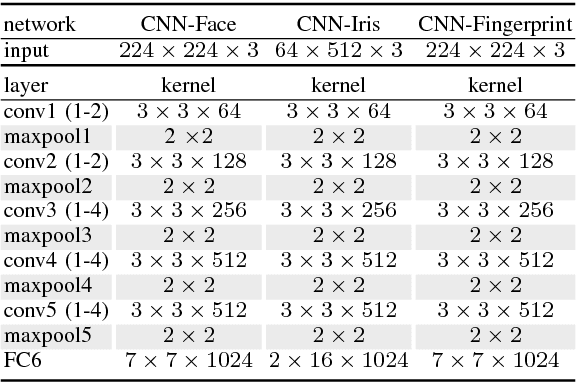
In this paper, we propose a deep multimodal fusion network to fuse multiple modalities (face, iris, and fingerprint) for person identification. The proposed deep multimodal fusion algorithm consists of multiple streams of modality-specific Convolutional Neural Networks (CNNs), which are jointly optimized at multiple feature abstraction levels. Multiple features are extracted at several different convolutional layers from each modality-specific CNN for joint feature fusion, optimization, and classification. Features extracted at different convolutional layers of a modality-specific CNN represent the input at several different levels of abstract representations. We demonstrate that an efficient multimodal classification can be accomplished with a significant reduction in the number of network parameters by exploiting these multi-level abstract representations extracted from all the modality-specific CNNs. We demonstrate an increase in multimodal person identification performance by utilizing the proposed multi-level feature abstract representations in our multimodal fusion, rather than using only the features from the last layer of each modality-specific CNNs. We show that our deep multi-modal CNNs with multimodal fusion at several different feature level abstraction can significantly outperform the unimodal representation accuracy. We also demonstrate that the joint optimization of all the modality-specific CNNs excels the score and decision level fusions of independently optimized CNNs.
Generalized Bilinear Deep Convolutional Neural Networks for Multimodal Biometric Identification
Jul 03, 2018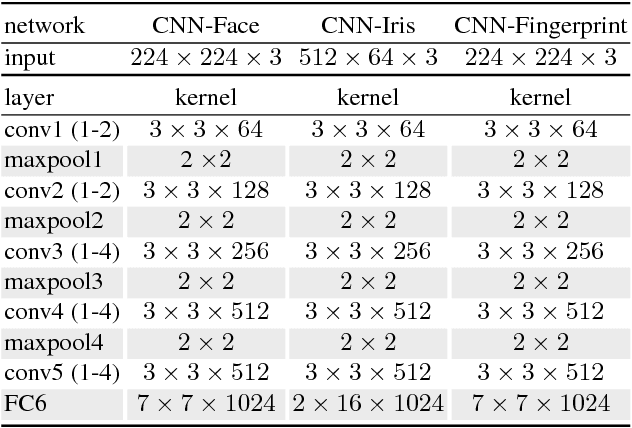
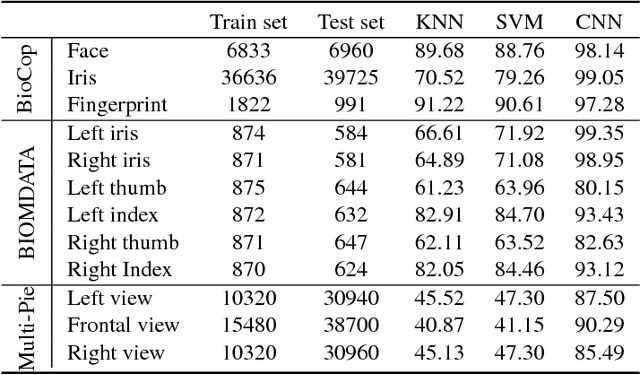
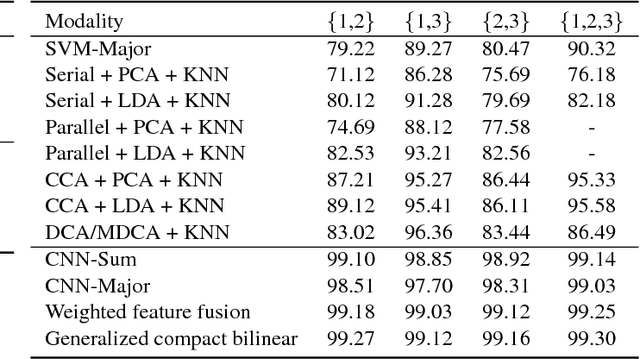
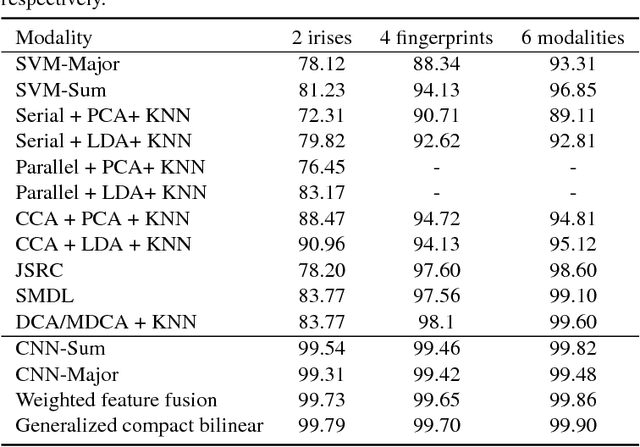
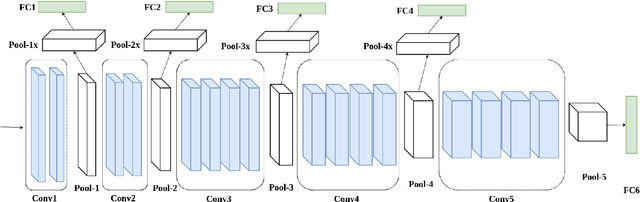
In this paper, we propose to employ a bank of modality-dedicated Convolutional Neural Networks (CNNs), fuse, train, and optimize them together for person classification tasks. A modality-dedicated CNN is used for each modality to extract modality-specific features. We demonstrate that, rather than spatial fusion at the convolutional layers, the fusion can be performed on the outputs of the fully-connected layers of the modality-specific CNNs without any loss of performance and with significant reduction in the number of parameters. We show that, using multiple CNNs with multimodal fusion at the feature-level, we significantly outperform systems that use unimodal representation. We study weighted feature, bilinear, and compact bilinear feature-level fusion algorithms for multimodal biometric person identification. Finally, We propose generalized compact bilinear fusion algorithm to deploy both the weighted feature fusion and compact bilinear schemes. We provide the results for the proposed algorithms on three challenging databases: CMU Multi-PIE, BioCop, and BIOMDATA.
Text-Independent Speaker Verification Using 3D Convolutional Neural Networks
Jun 06, 2018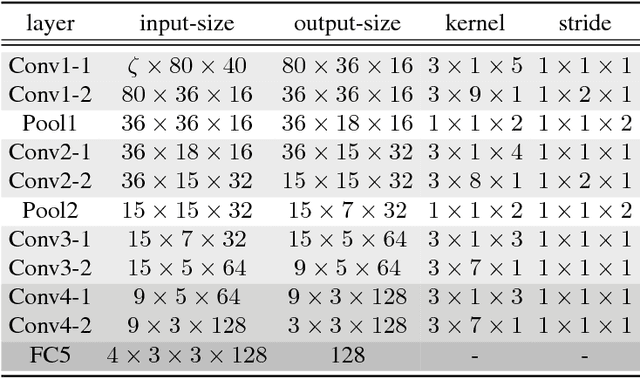
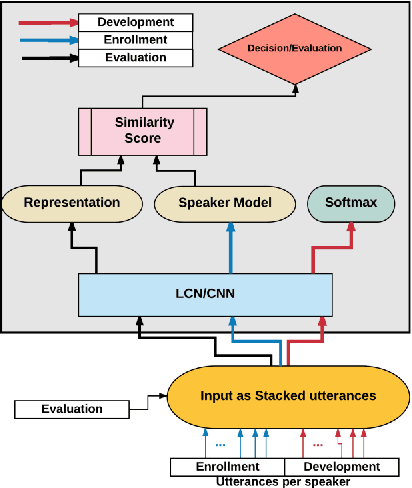
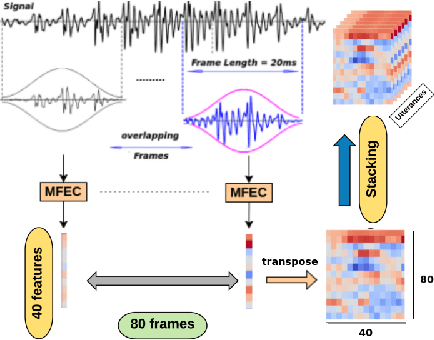
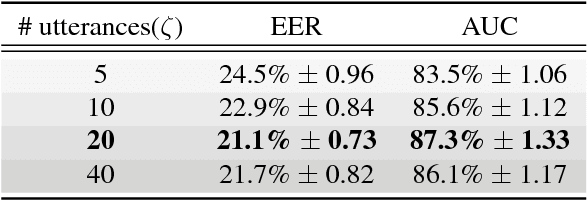
In this paper, a novel method using 3D Convolutional Neural Network (3D-CNN) architecture has been proposed for speaker verification in the text-independent setting. One of the main challenges is the creation of the speaker models. Most of the previously-reported approaches create speaker models based on averaging the extracted features from utterances of the speaker, which is known as the d-vector system. In our paper, we propose an adaptive feature learning by utilizing the 3D-CNNs for direct speaker model creation in which, for both development and enrollment phases, an identical number of spoken utterances per speaker is fed to the network for representing the speakers' utterances and creation of the speaker model. This leads to simultaneously capturing the speaker-related information and building a more robust system to cope with within-speaker variation. We demonstrate that the proposed method significantly outperforms the traditional d-vector verification system. Moreover, the proposed system can also be an alternative to the traditional d-vector system which is a one-shot speaker modeling system by utilizing 3D-CNNs.
A Deep Face Identification Network Enhanced by Facial Attributes Prediction
Apr 20, 2018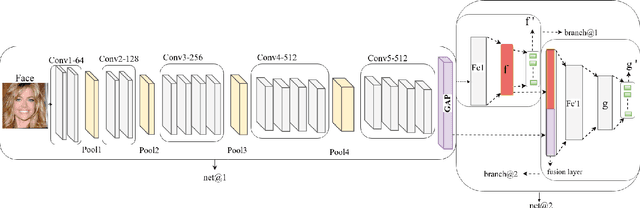
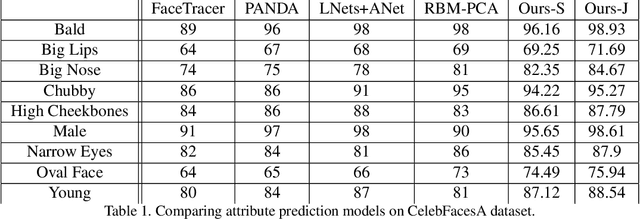

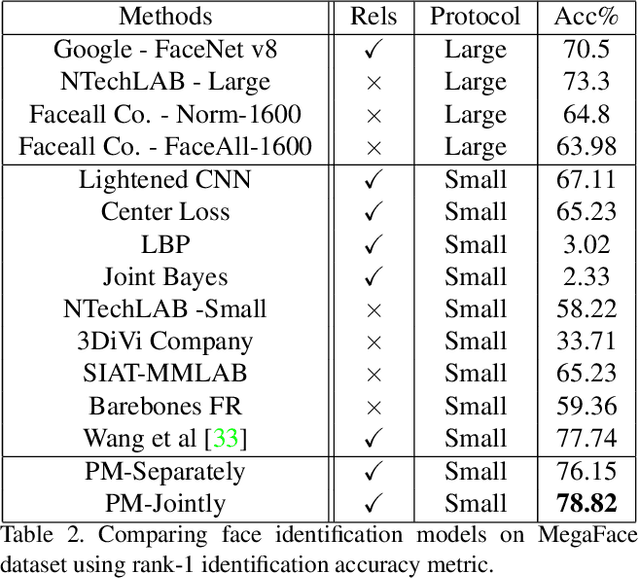
In this paper, we propose a new deep framework which predicts facial attributes and leverage it as a soft modality to improve face identification performance. Our model is an end to end framework which consists of a convolutional neural network (CNN) whose output is fanned out into two separate branches; the first branch predicts facial attributes while the second branch identifies face images. Contrary to the existing multi-task methods which only use a shared CNN feature space to train these two tasks jointly, we fuse the predicted attributes with the features from the face modality in order to improve the face identification performance. Experimental results show that our model brings benefits to both face identification as well as facial attribute prediction performance, especially in the case of identity facial attributes such as gender prediction. We tested our model on two standard datasets annotated by identities and face attributes. Experimental results indicate that the proposed model outperforms most of the current existing face identification and attribute prediction methods.
3D Convolutional Neural Networks for Cross Audio-Visual Matching Recognition
Aug 13, 2017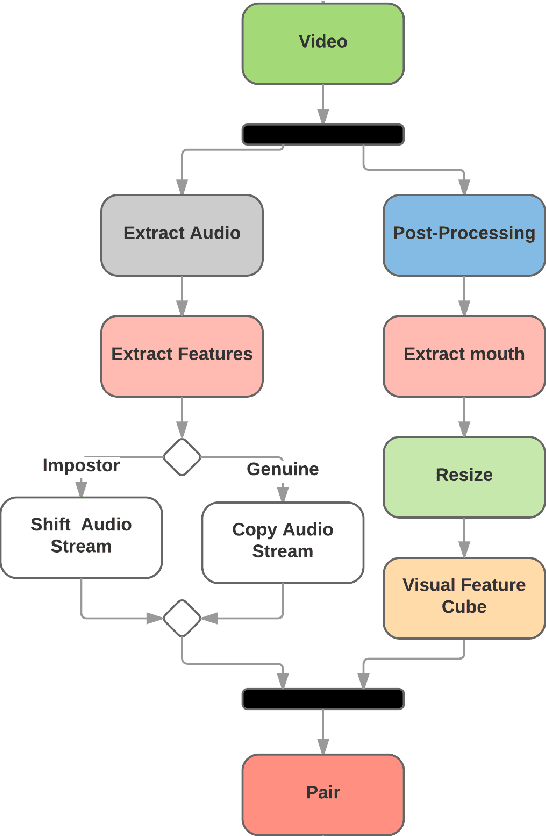
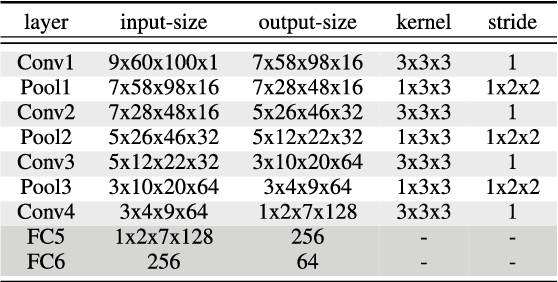
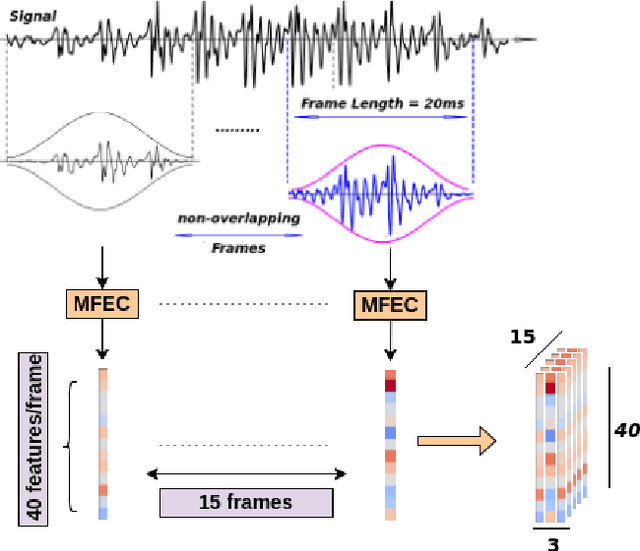
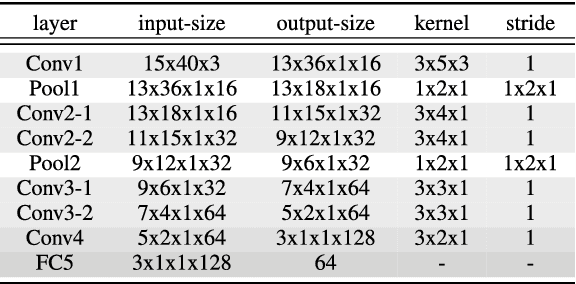
Audio-visual recognition (AVR) has been considered as a solution for speech recognition tasks when the audio is corrupted, as well as a visual recognition method used for speaker verification in multi-speaker scenarios. The approach of AVR systems is to leverage the extracted information from one modality to improve the recognition ability of the other modality by complementing the missing information. The essential problem is to find the correspondence between the audio and visual streams, which is the goal of this work. We propose the use of a coupled 3D Convolutional Neural Network (3D-CNN) architecture that can map both modalities into a representation space to evaluate the correspondence of audio-visual streams using the learned multimodal features. The proposed architecture will incorporate both spatial and temporal information jointly to effectively find the correlation between temporal information for different modalities. By using a relatively small network architecture and much smaller dataset for training, our proposed method surpasses the performance of the existing similar methods for audio-visual matching which use 3D CNNs for feature representation. We also demonstrate that an effective pair selection method can significantly increase the performance. The proposed method achieves relative improvements over 20% on the Equal Error Rate (EER) and over 7% on the Average Precision (AP) in comparison to the state-of-the-art method.