 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Spectral Iris Matching Using Conditional Coupled GAN
Oct 09, 2020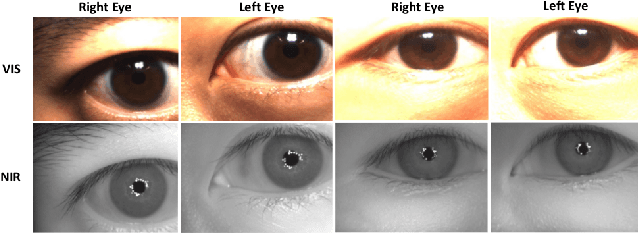
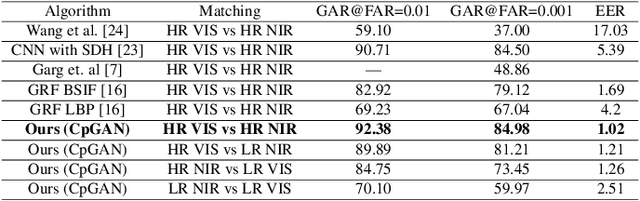
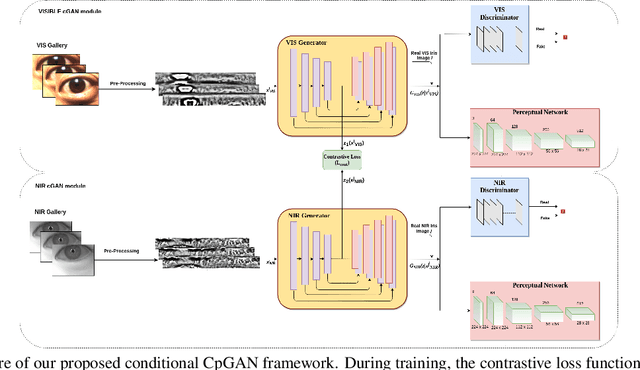

Cross-spectral iris recognition is emerging as a promising biometric approach to authenticating the identity of individuals. However, matching iris images acquired at different spectral bands shows significant performance degradation when compared to single-band near-infrared (NIR) matching due to the spectral gap between iris images obtained in the NIR and visual-light (VIS) spectra. Although researchers have recently focused on deep-learning-based approaches to recover invariant representative features for more accurate recognition performance, the existing methods cannot achieve the expected accuracy required for commercial applications. Hence, in this paper, we propose a conditional coupled generative adversarial network (CpGAN) architecture for cross-spectral iris recognition by projecting the VIS and NIR iris images into a low-dimensional embedding domain to explore the hidden relationship between them. The conditional CpGAN framework consists of a pair of GAN-based networks, one responsible for retrieving images in the visible domain and other responsible for retrieving images in the NIR domain. Both networks try to map the data into a common embedding subspace to ensure maximum pair-wise similarity between the feature vectors from the two iris modalities of the same subject. To prove the usefulness of our proposed approach, extensive experimental results obtained on the PolyU dataset are compared to existing state-of-the-art cross-spectral recognition methods.
PF-cpGAN: Profile to Frontal Coupled GAN for Face Recognition in the Wild
Apr 25, 2020
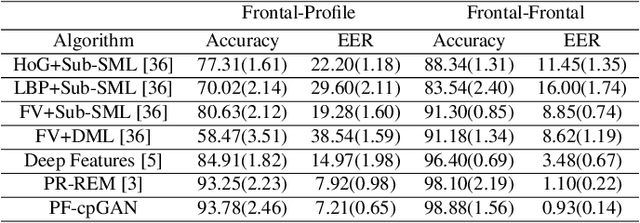
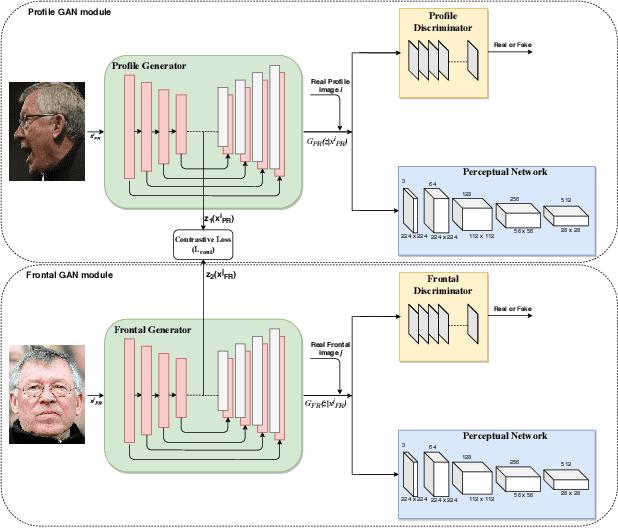
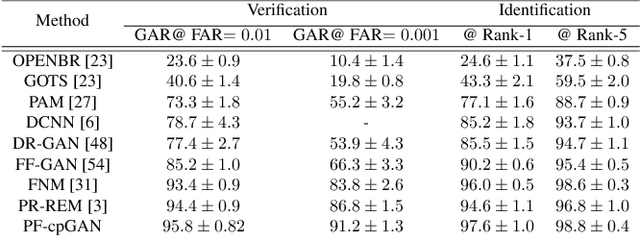
In recent years, due to the emergence of deep learning, face recognition has achieved exceptional success. However, many of these deep face recognition models perform relatively poorly in handling profile faces compared to frontal faces. The major reason for this poor performance is that it is inherently difficult to learn large pose invariant deep representations that are useful for profile face recognition. In this paper, we hypothesize that the profile face domain possesses a gradual connection with the frontal face domain in the deep feature space. We look to exploit this connection by projecting the profile faces and frontal faces into a common latent space and perform verification or retrieval in the latent domain. We leverage a coupled generative adversarial network (cpGAN) structure to find the hidden relationship between the profile and frontal images in a latent common embedding subspace. Specifically, the cpGAN framework consists of two GAN-based sub-networks, one dedicated to the frontal domain and the other dedicated to the profile domain. Each sub-network tends to find a projection that maximizes the pair-wise correlation between two feature domains in a common embedding feature subspace. The efficacy of our approach compared with the state-of-the-art is demonstrated using the CFP, CMU MultiPIE, IJB-A, and IJB-C datasets.
Boosting Deep Face Recognition via Disentangling Appearance and Geometry
Jan 13, 2020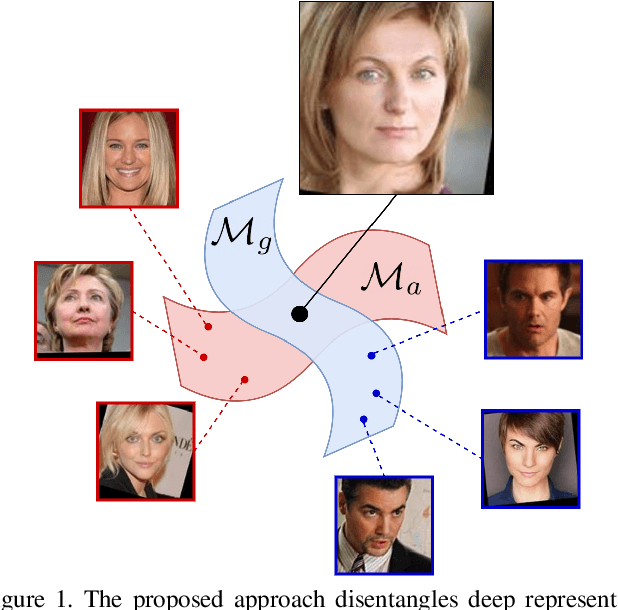
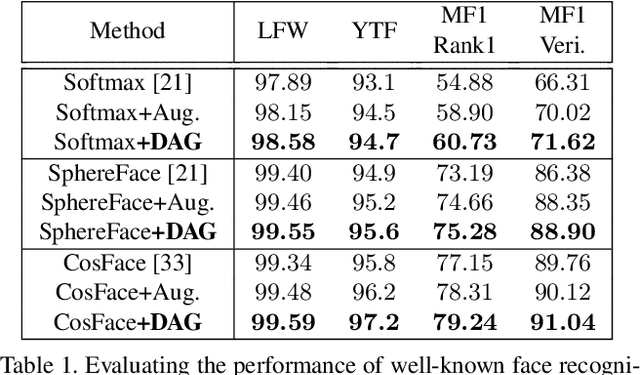

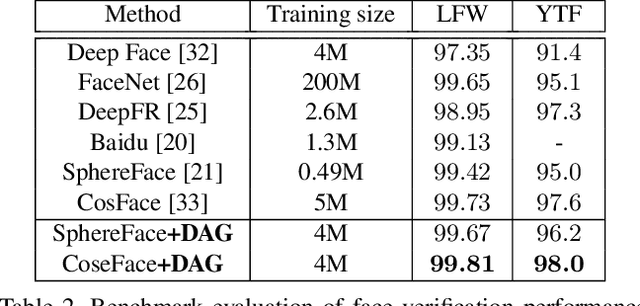
In this paper, we propose a framework for disentangling the appearance and geometry representations in the face recognition task. To provide supervision for this aim, we generate geometrically identical faces by incorporating spatial transformations. We demonstrate that the proposed approach enhances the performance of deep face recognition models by assisting the training process in two ways. First, it enforces the early and intermediate convolutional layers to learn more representative features that satisfy the properties of disentangled embeddings. Second, it augments the training set by altering faces geometrically. Through extensive experiments, we demonstrate that integrating the proposed approach into state-of-the-art face recognition methods effectively improves their performance on challenging datasets, such as LFW, YTF, and MegaFace. Both theoretical and practical aspects of the method are analyzed rigorously by concerning ablation studies and knowledge transfer tasks. Furthermore, we show that the knowledge leaned by the proposed method can favor other face-related tasks, such as attribute prediction.
SmoothFool: An Efficient Framework for Computing Smooth Adversarial Perturbations
Oct 08, 2019
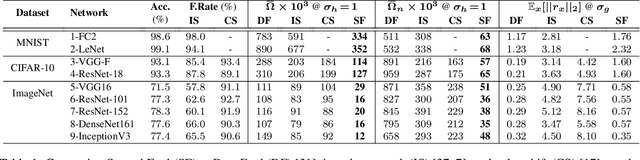
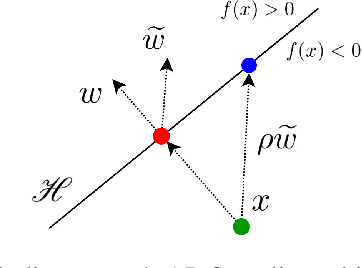
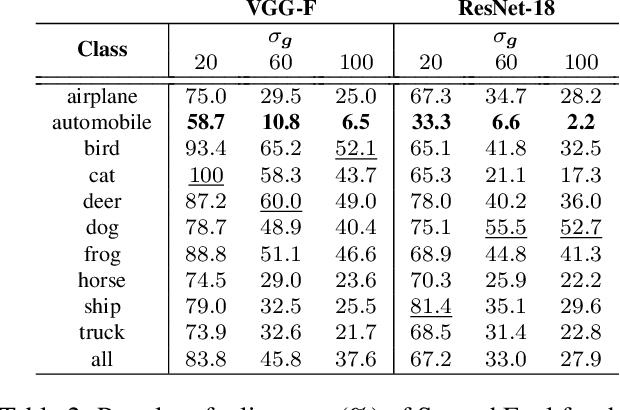
Deep neural networks are susceptible to adversarial manipulations in the input domain. The extent of vulnerability has been explored intensively in cases of $\ell_p$-bounded and $\ell_p$-minimal adversarial perturbations. However, the vulnerability of DNNs to adversarial perturbations with specific statistical properties or frequency-domain characteristics has not been sufficiently explored. In this paper, we study the smoothness of perturbations and propose SmoothFool, a general and computationally efficient framework for computing smooth adversarial perturbations. Through extensive experiments, we validate the efficacy of the proposed method for both the white-box and black-box attack scenarios. In particular, we demonstrate that: (i) there exist extremely smooth adversarial perturbations for well-established and widely used network architectures, (ii) smoothness significantly enhances the robustness of perturbations against state-of-the-art defense mechanisms, (iii) smoothness improves the transferability of adversarial perturbations across both data points and network architectures, and (iv) class categories exhibit a variable range of susceptibility to smooth perturbations. Our results suggest that smooth APs can play a significant role in exploring the vulnerability extent of DNNs to adversarial examples.
Deep Sparse Band Selection for Hyperspectral Face Recognition
Aug 15, 2019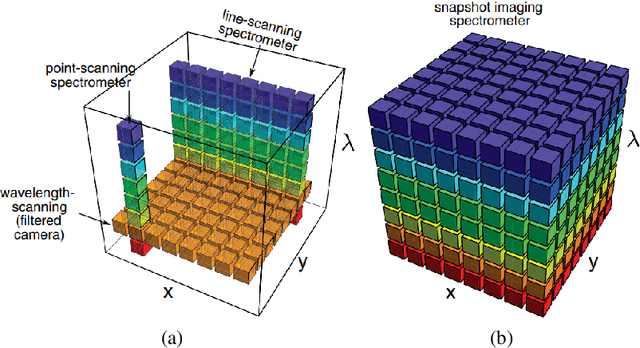

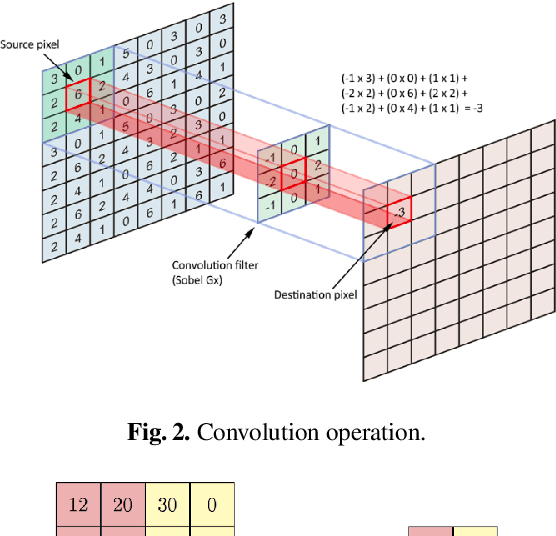

Hyperspectral imaging systems collect and process information from specific wavelengths across the electromagnetic spectrum. The fusion of multi-spectral bands in the visible spectrum has been exploited to improve face recognition performance over all the conventional broad band face images. In this book chapter, we propose a new Convolutional Neural Network (CNN) framework which adopts a structural sparsity learning technique to select the optimal spectral bands to obtain the best face recognition performance over all of the spectral bands. Specifically, in this method, images from all bands are fed to a CNN, and the convolutional filters in the first layer of the CNN are then regularized by employing a group Lasso algorithm to zero out the redundant bands during the training of the network. Contrary to other methods which usually select the useful bands manually or in a greedy fashion, our method selects the optimal spectral bands automatically to achieve the best face recognition performance over all spectral bands. Moreover, experimental results demonstrate that our method outperforms state of the art band selection methods for face recognition on several publicly-available hyperspectral face image datasets.
Defending Against Adversarial Iris Examples Using Wavelet Decomposition
Aug 08, 2019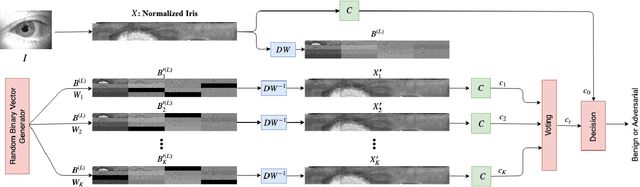
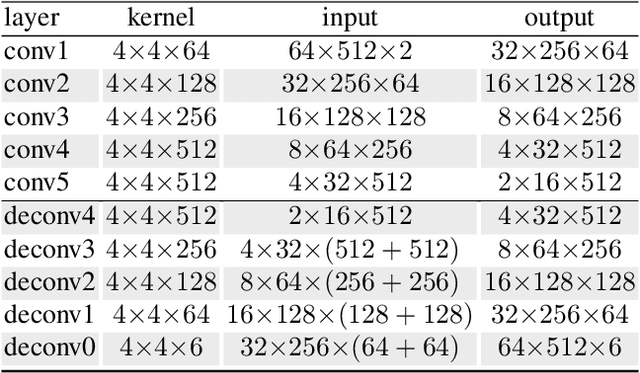
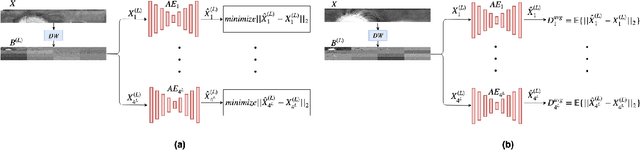

Deep neural networks have presented impressive performance in biometric applications. However, their performance is highly at risk when facing carefully crafted input samples known as adversarial examples. In this paper, we present three defense strategies to detect adversarial iris examples. These defense strategies are based on wavelet domain denoising of the input examples by investigating each wavelet sub-band and removing the sub-bands that are most affected by the adversary. The first proposed defense strategy reconstructs multiple denoised versions of the input example through manipulating the mid- and high-frequency components of the wavelet domain representation of the input example and makes a decision upon the classification result of the majority of the denoised examples. The second and third proposed defense strategies aim to denoise each wavelet domain sub-band and determine the sub-bands that are most likely affected by the adversary using the reconstruction error computed for each sub-band. We test the performance of the proposed defense strategies against several attack scenarios and compare the results with five state of the art defense strategies.
Adversarial Examples to Fool Iris Recognition Systems
Jul 18, 2019
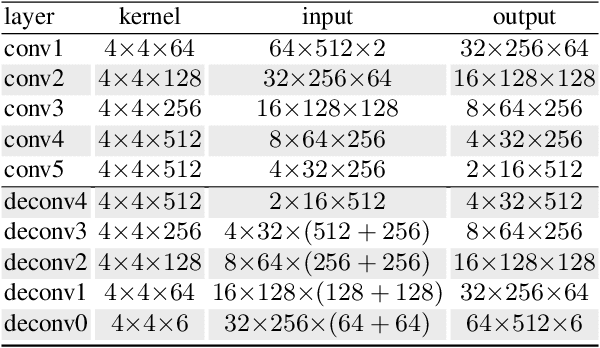
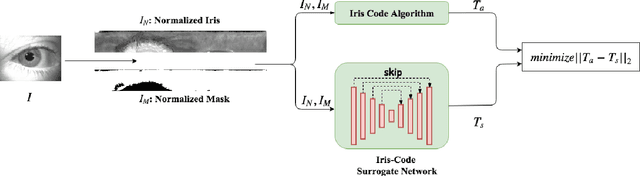
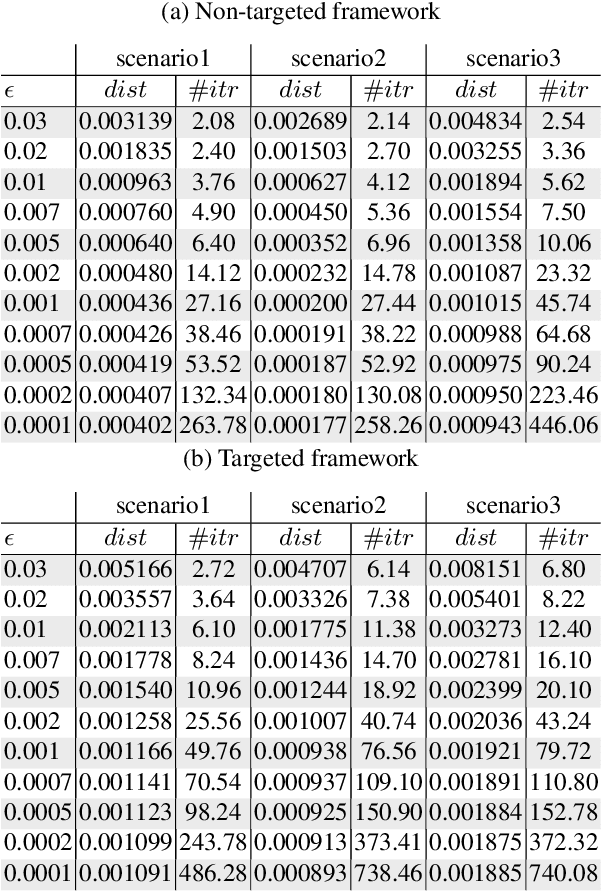
Adversarial examples have recently proven to be able to fool deep learning methods by adding carefully crafted small perturbation to the input space image. In this paper, we study the possibility of generating adversarial examples for code-based iris recognition systems. Since generating adversarial examples requires back-propagation of the adversarial loss, conventional filter bank-based iris-code generation frameworks cannot be employed in such a setup. Therefore, to compensate for this shortcoming, we propose to train a deep auto-encoder surrogate network to mimic the conventional iris code generation procedure. This trained surrogate network is then deployed to generate the adversarial examples using the iterative gradient sign method algorithm. We consider non-targeted and targeted attacks through three attack scenarios. Considering these attacks, we study the possibility of fooling an iris recognition system in white-box and black-box frameworks.
Fast Geometrically-Perturbed Adversarial Faces
Sep 28, 2018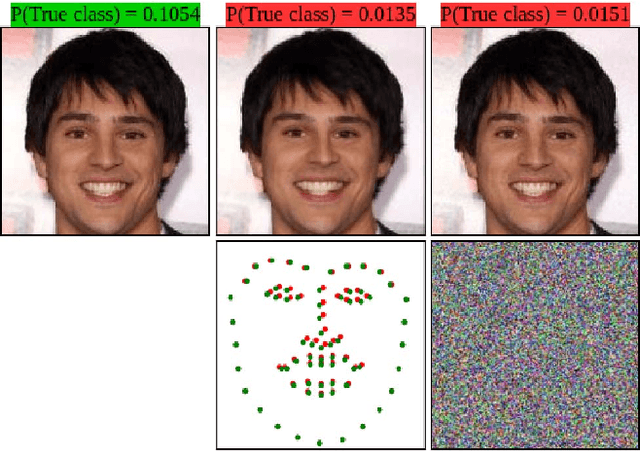
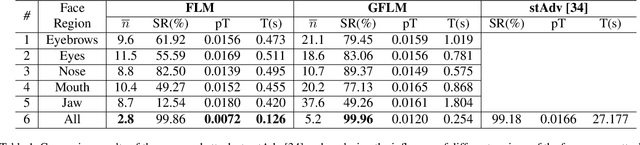
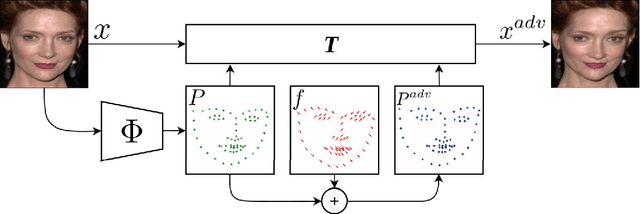
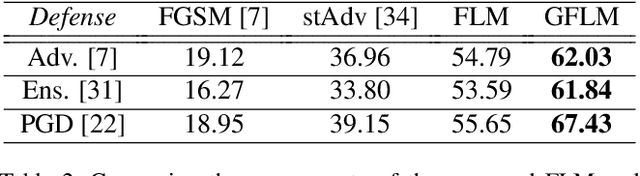
The state-of-the-art performance of deep learning algorithms has led to a considerable increase in the utilization of machine learning in security-sensitive and critical applications. However, it has recently been shown that a small and carefully crafted perturbation in the input space can completely fool a deep model. In this study, we explore the extent to which face recognition systems are vulnerable to geometrically-perturbed adversarial faces. We propose a fast landmark manipulation method for generating adversarial faces, which is approximately 200 times faster than the previous geometric attacks and obtains 99.86% success rate on the state-of-the-art face recognition models. To further force the generated samples to be natural, we introduce a second attack constrained on the semantic structure of the face which has the half speed of the first attack with the success rate of 99.96%. Both attacks are extremely robust against the state-of-the-art defense methods with the success rate of equal or greater than 53.59%. Code is available at https://github.com/alldbi/FLM
Prosodic-Enhanced Siamese Convolutional Neural Networks for Cross-Device Text-Independent Speaker Verification
Jul 31, 2018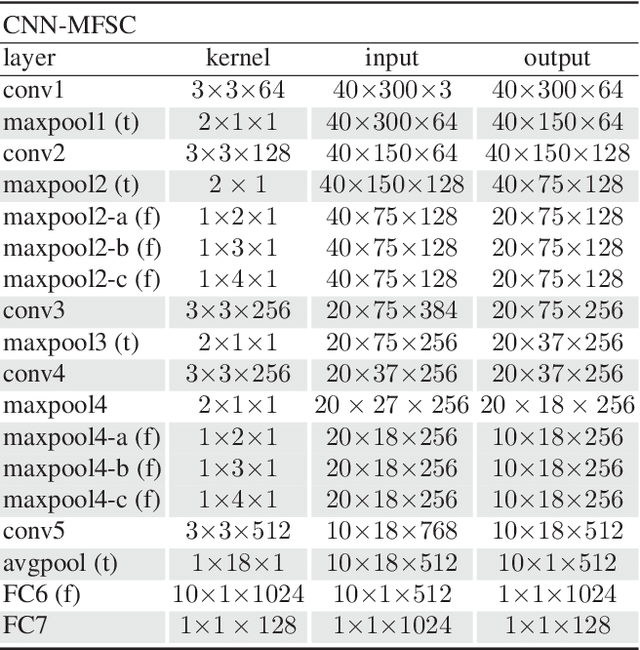
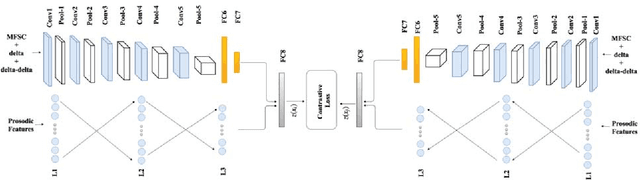
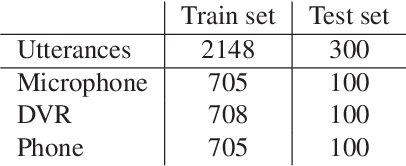
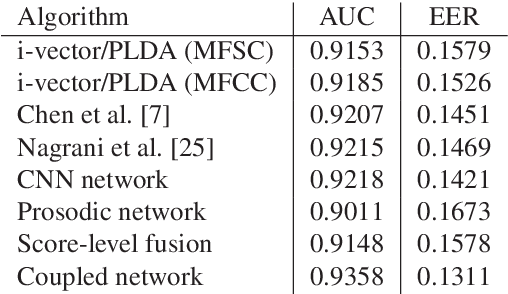
In this paper a novel cross-device text-independent speaker verification architecture is proposed. Majority of the state-of-the-art deep architectures that are used for speaker verification tasks consider Mel-frequency cepstral coefficients. In contrast, our proposed Siamese convolutional neural network architecture uses Mel-frequency spectrogram coefficients to benefit from the dependency of the adjacent spectro-temporal features. Moreover, although spectro-temporal features have proved to be highly reliable in speaker verification models, they only represent some aspects of short-term acoustic level traits of the speaker's voice. However, the human voice consists of several linguistic levels such as acoustic, lexicon, prosody, and phonetics, that can be utilized in speaker verification models. To compensate for these inherited shortcomings in spectro-temporal features, we propose to enhance the proposed Siamese convolutional neural network architecture by deploying a multilayer perceptron network to incorporate the prosodic, jitter, and shimmer features. The proposed end-to-end verification architecture performs feature extraction and verification simultaneously. This proposed architecture displays significant improvement over classical signal processing approaches and deep algorithms for forensic cross-device speaker verification.
ID Preserving Generative Adversarial Network for Partial Latent Fingerprint Reconstruction
Jul 31, 2018
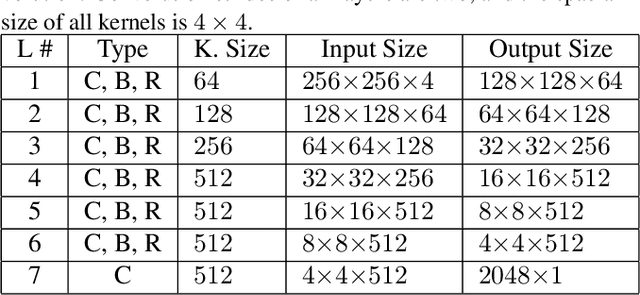
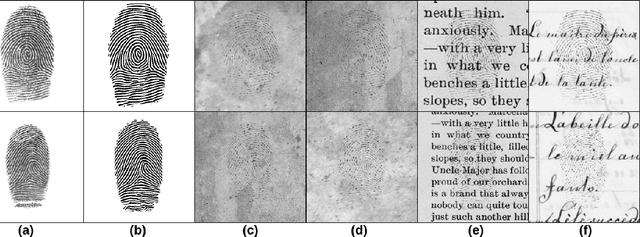

Performing recognition tasks using latent fingerprint samples is often challenging for automated identification systems due to poor quality, distortion, and partially missing information from the input samples. We propose a direct latent fingerprint reconstruction model based on conditional generative adversarial networks (cGANs). Two modifications are applied to the cGAN to adapt it for the task of latent fingerprint reconstruction. First, the model is forced to generate three additional maps to the ridge map to ensure that the orientation and frequency information is considered in the generation process, and prevent the model from filling large missing areas and generating erroneous minutiae. Second, a perceptual ID preservation approach is developed to force the generator to preserve the ID information during the reconstruction process. Using a synthetically generated database of latent fingerprints, the deep network learns to predict missing information from the input latent samples. We evaluate the proposed method in combination with two different fingerprint matching algorithms on several publicly available latent fingerprint datasets. We achieved the rank-10 accuracy of 88.02\% on the IIIT-Delhi latent fingerprint database for the task of latent-to-latent matching and rank-50 accuracy of 70.89\% on the IIIT-Delhi MOLF database for the task of latent-to-sensor matching. Experimental results of matching reconstructed samples in both latent-to-sensor and latent-to-latent frameworks indicate that the proposed method significantly increases the matching accuracy of the fingerprint recognition systems for the latent samples.