 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJatin Ganhotra
Knowledge-incorporating ESIM models for Response Selection in Retrieval-based Dialog Systems
Jul 11, 2019
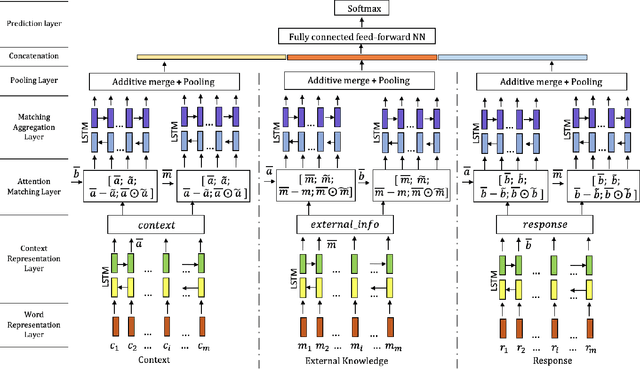
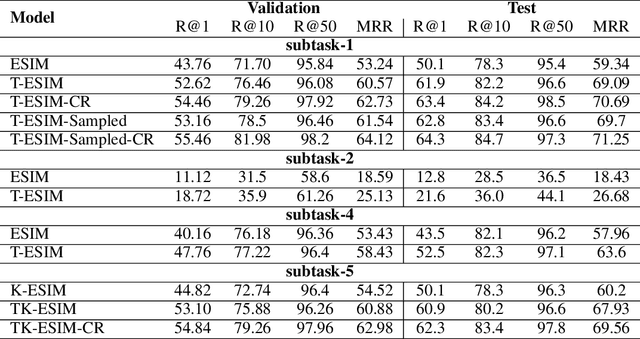

Goal-oriented dialog systems, which can be trained end-to-end without manually encoding domain-specific features, show tremendous promise in the customer support use-case e.g. flight booking, hotel reservation, technical support, student advising etc. These dialog systems must learn to interact with external domain knowledge to achieve the desired goal e.g. recommending courses to a student, booking a table at a restaurant etc. This paper presents extended Enhanced Sequential Inference Model (ESIM) models: a) K-ESIM (Knowledge-ESIM), which incorporates the external domain knowledge and b) T-ESIM (Targeted-ESIM), which leverages information from similar conversations to improve the prediction accuracy. Our proposed models and the baseline ESIM model are evaluated on the Ubuntu and Advising datasets in the Sentence Selection track of the latest Dialog System Technology Challenge (DSTC7), where the goal is to find the correct next utterance, given a partial conversation, from a set of candidates. Our preliminary results suggest that incorporating external knowledge sources and leveraging information from similar dialogs leads to performance improvements for predicting the next utterance.
Quantized-Dialog Language Model for Goal-Oriented Conversational Systems
Dec 26, 2018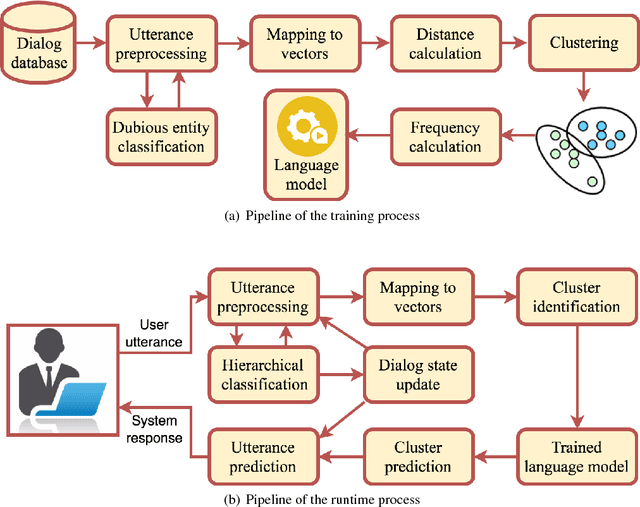
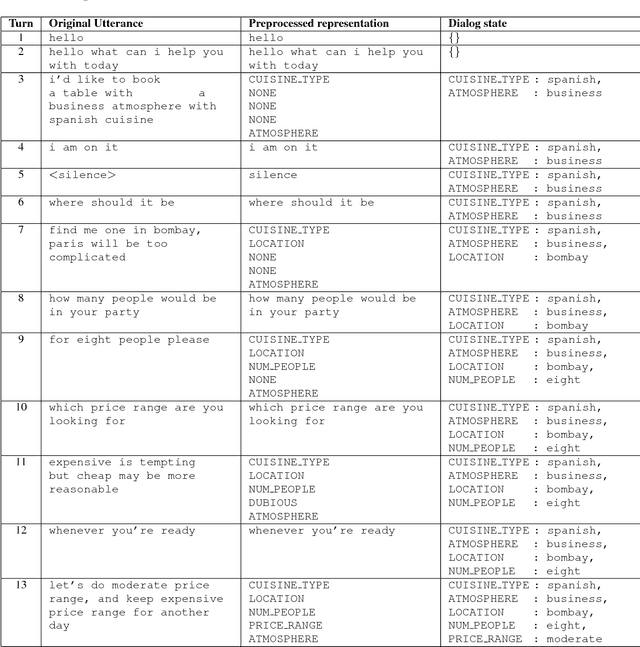
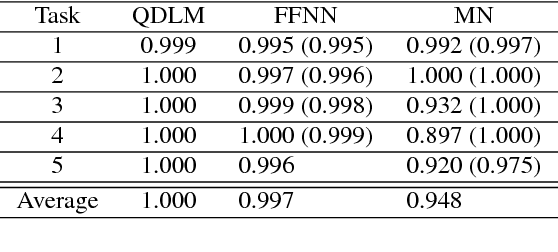
We propose a novel methodology to address dialog learning in the context of goal-oriented conversational systems. The key idea is to quantize the dialog space into clusters and create a language model across the clusters, thus allowing for an accurate choice of the next utterance in the conversation. The language model relies on n-grams associated with clusters of utterances. This quantized-dialog language model methodology has been applied to the end-to-end goal-oriented track of the latest Dialog System Technology Challenges (DSTC6). The objective is to find the correct system utterance from a pool of candidates in order to complete a dialog between a user and an automated restaurant-reservation system. Our results show that the technique proposed in this paper achieves high accuracy regarding selection of the correct candidate utterance, and outperforms other state-of-the-art approaches based on neural networks.
Analyzing Assumptions in Conversation Disentanglement Research Through the Lens of a New Dataset and Model
Oct 25, 2018
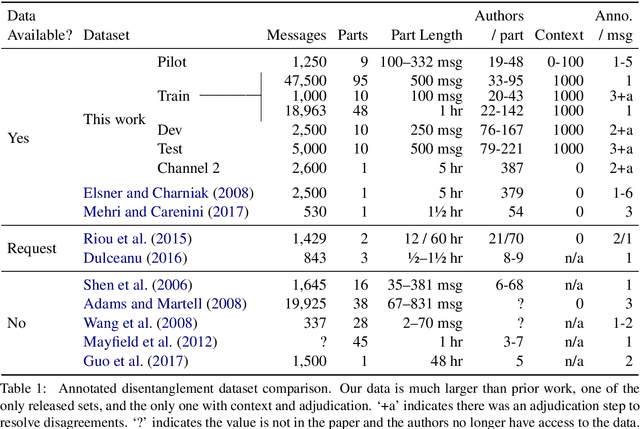

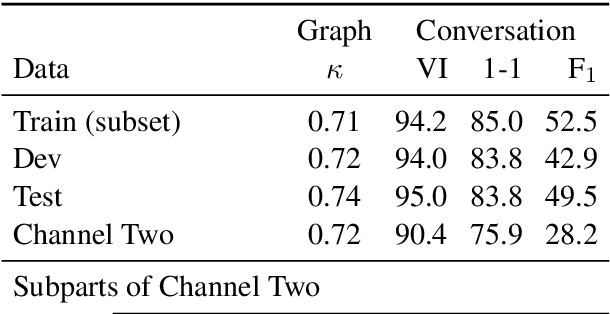
Disentangling conversations mixed together in a single stream of messages is a difficult task with no large annotated datasets. We created a new dataset that is 25 times the size of any previous publicly available resource, has samples of conversation from 152 points in time across a decade, and is annotated with both threads and a within-thread reply-structure graph. We also developed a new neural network model, which extracts conversation threads substantially more accurately than prior work. Using our annotated data and our model we tested assumptions in prior work, revealing major issues in heuristically constructed resources, and identifying how small datasets have biased our understanding of multi-party multi-conversation chat.
Learning End-to-End Goal-Oriented Dialog with Multiple Answers
Aug 24, 2018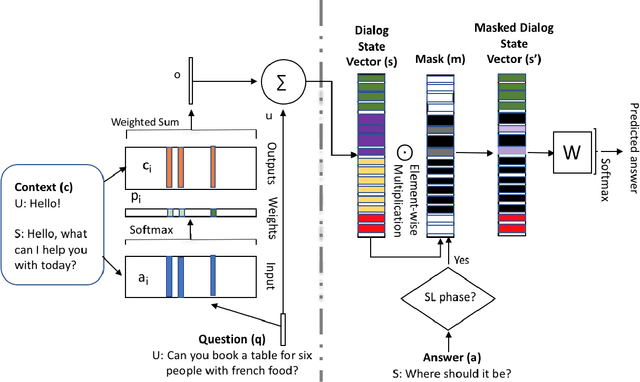
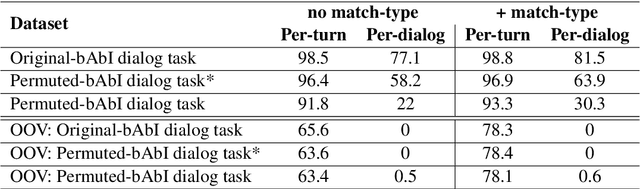
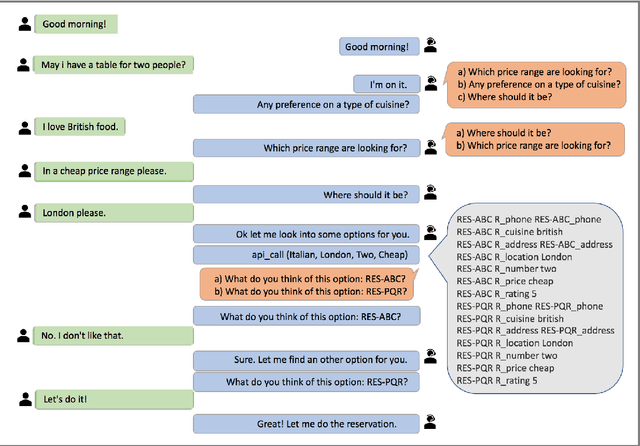
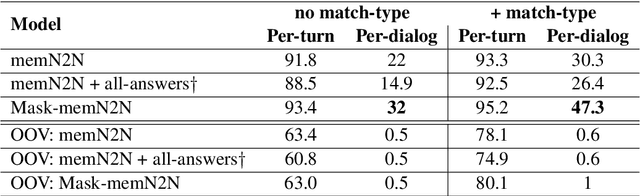
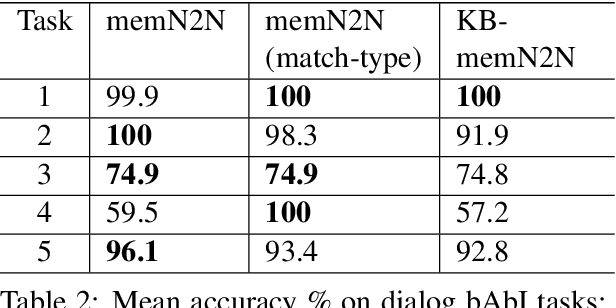
In a dialog, there can be multiple valid next utterances at any point. The present end-to-end neural methods for dialog do not take this into account. They learn with the assumption that at any time there is only one correct next utterance. In this work, we focus on this problem in the goal-oriented dialog setting where there are different paths to reach a goal. We propose a new method, that uses a combination of supervised learning and reinforcement learning approaches to address this issue. We also propose a new and more effective testbed, permuted-bAbI dialog tasks, by introducing multiple valid next utterances to the original-bAbI dialog tasks, which allows evaluation of goal-oriented dialog systems in a more realistic setting. We show that there is a significant drop in performance of existing end-to-end neural methods from 81.5% per-dialog accuracy on original-bAbI dialog tasks to 30.3% on permuted-bAbI dialog tasks. We also show that our proposed method improves the performance and achieves 47.3% per-dialog accuracy on permuted-bAbI dialog tasks.
Knowledge-based end-to-end memory networks
Apr 23, 2018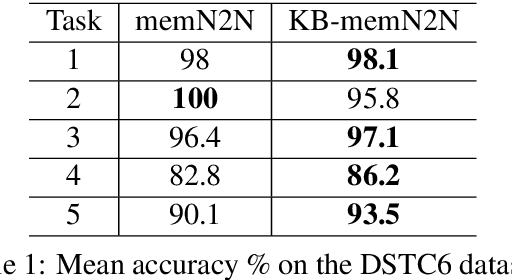
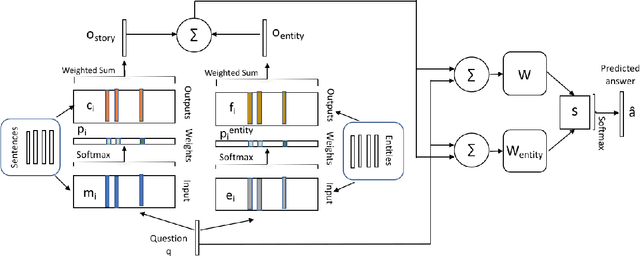
End-to-end dialog systems have become very popular because they hold the promise of learning directly from human to human dialog interaction. Retrieval and Generative methods have been explored in this area with mixed results. A key element that is missing so far, is the incorporation of a-priori knowledge about the task at hand. This knowledge may exist in the form of structured or unstructured information. As a first step towards this direction, we present a novel approach, Knowledge based end-to-end memory networks (KB-memN2N), which allows special handling of named entities for goal-oriented dialog tasks. We present results on two datasets, DSTC6 challenge dataset and dialog bAbI tasks.
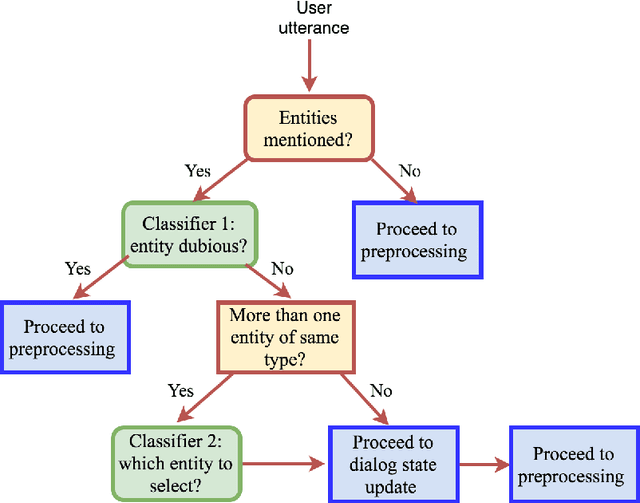
Named Entities troubling your Neural Methods? Build NE-Table: A neural approach for handling Named Entities
Apr 22, 2018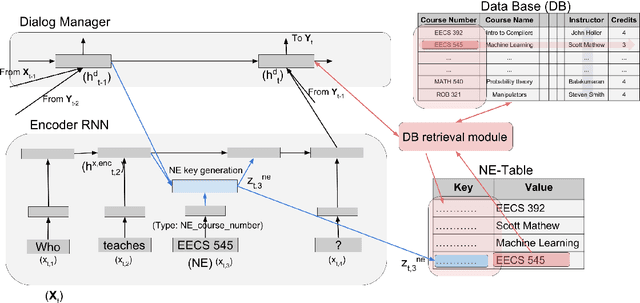
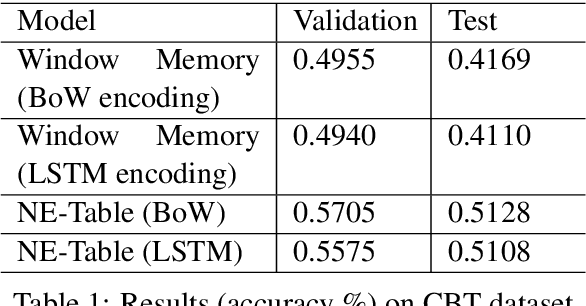
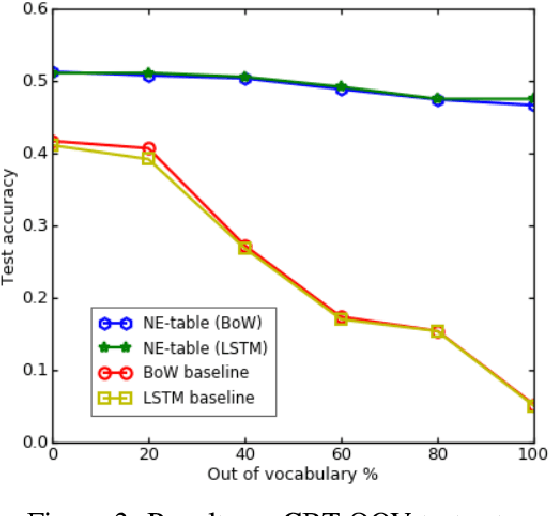
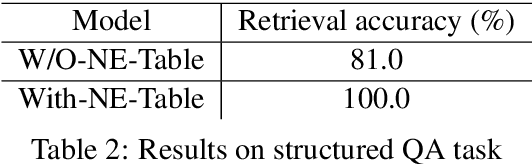
Many natural language processing tasks require dealing with Named Entities (NEs) in the texts themselves and sometimes also in external knowledge sources. While this is often easy for humans, recent neural methods that rely on learned word embeddings for NLP tasks have difficulty with it, especially with out of vocabulary or rare NEs. In this paper, we propose a new neural method for this problem, and present empirical evaluations on a structured Question-Answering task, three related Goal-Oriented dialog tasks and a reading-comprehension-based task. They show that our proposed method can be effective in dealing with both in-vocabulary and out of vocabulary (OOV) NEs. We create extended versions of dialog bAbI tasks 1,2 and 4 and Out-of-vocabulary (OOV) versions of the CBT test set which will be made publicly available online.