 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition-based Scaled Gradient for Model Quantization and Sparse Training
Jun 10, 2020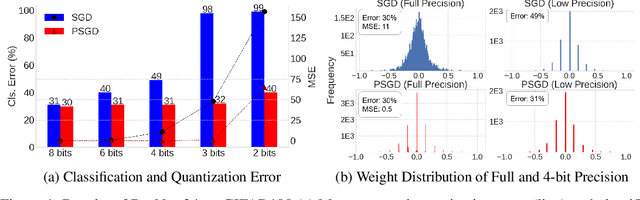
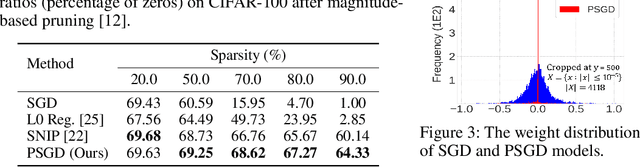
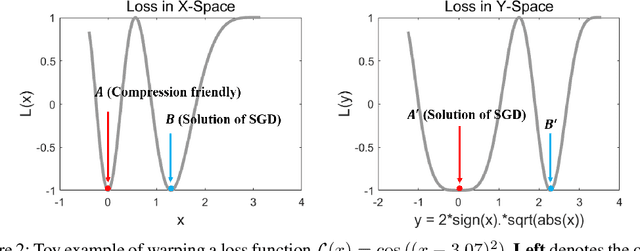
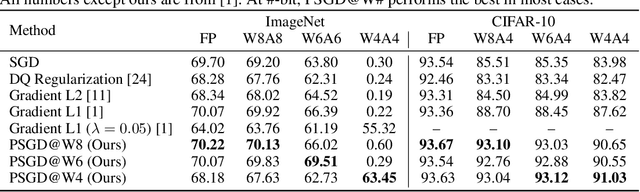
We propose the position-based scaled gradient (PSG) that scales the gradient depending on the position of a weight vector to make it more compression-friendly. First, we theoretically show that applying PSG to the standard gradient descent (GD), which is called PSGD, is equivalent to the GD in the warped weight space, a space made by warping the original weight space via an appropriately designed invertible function. Second, we empirically show that PSG acting as a regularizer to a weight vector is very useful in model compression domains such as quantization and sparse training. PSG reduces the gap between the weight distributions of a full-precision model and its compressed counterpart. This enables the versatile deployment of a model either as an uncompressed mode or as a compressed mode depending on the availability of resources. The experimental results on CIFAR-10/100 and Imagenet datasets show the effectiveness of the proposed PSG in both domains of sparse training and quantization even for extremely low bits.
Feature-map-level Online Adversarial Knowledge Distillation
Feb 05, 2020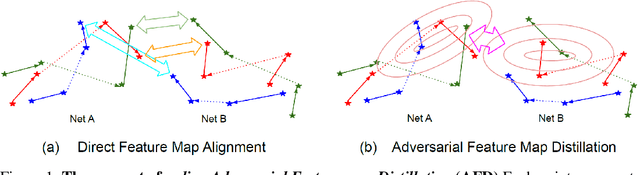
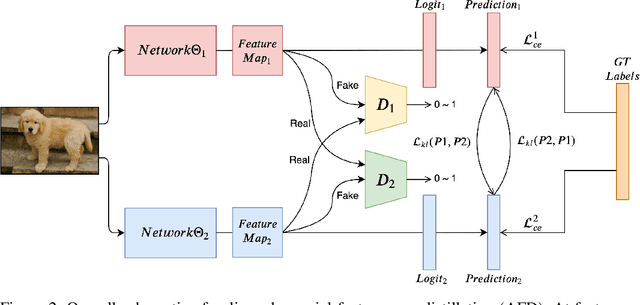
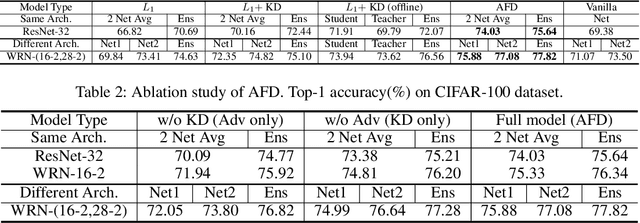
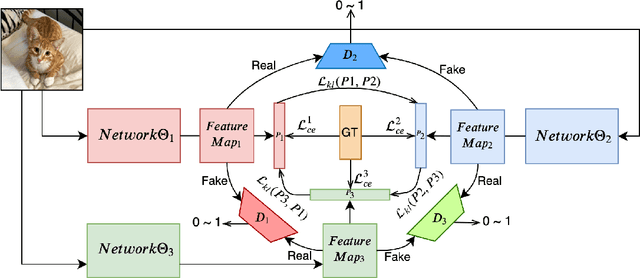
Feature maps contain rich information about image intensity and spatial correlation. However, previous online knowledge distillation methods only utilize the class probabilities. Thus in this paper, we propose an online knowledge distillation method that transfers not only the knowledge of the class probabilities but also that of the feature map using the adversarial training framework. We train multiple networks simultaneously by employing discriminators to distinguish the feature map distributions of different networks. Each network has its corresponding discriminator which discriminates the feature map from its own as fake while classifying that of the other network as real. By training a network to fool the corresponding discriminator, it can learn the other network's feature map distribution. We show that our method performs better than the conventional direct alignment method such as L1 and is more suitable for online distillation. Also, we propose a novel cyclic learning scheme for training more than two networks together. We have applied our method to various network architectures on the classification task and discovered a significant improvement of performance especially in the case of training a pair of a small network and a large one.
QKD: Quantization-aware Knowledge Distillation
Nov 28, 2019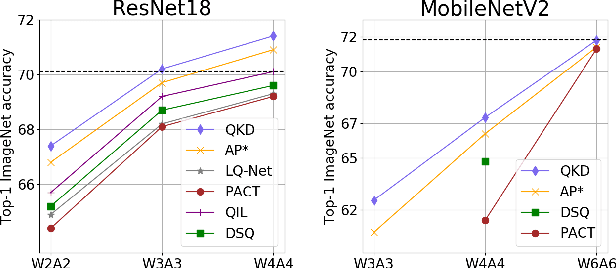
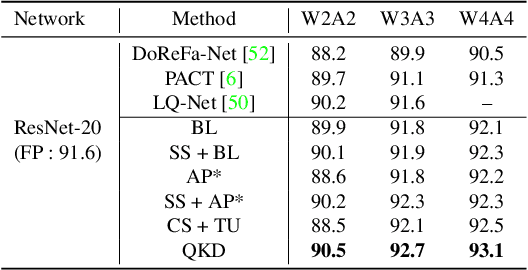
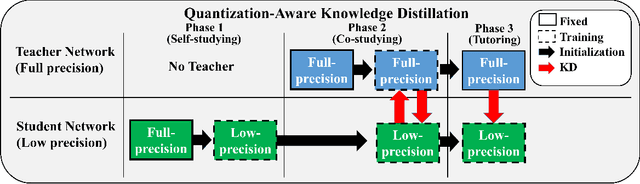
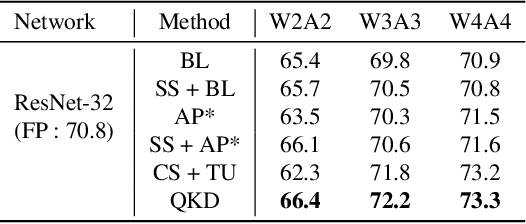
Quantization and Knowledge distillation (KD) methods are widely used to reduce memory and power consumption of deep neural networks (DNNs), especially for resource-constrained edge devices. Although their combination is quite promising to meet these requirements, it may not work as desired. It is mainly because the regularization effect of KD further diminishes the already reduced representation power of a quantized model. To address this short-coming, we propose Quantization-aware Knowledge Distillation (QKD) wherein quantization and KD are care-fully coordinated in three phases. First, Self-studying (SS) phase fine-tunes a quantized low-precision student network without KD to obtain a good initialization. Second, Co-studying (CS) phase tries to train a teacher to make it more quantizaion-friendly and powerful than a fixed teacher. Finally, Tutoring (TU) phase transfers knowledge from the trained teacher to the student. We extensively evaluate our method on ImageNet and CIFAR-10/100 datasets and show an ablation study on networks with both standard and depthwise-separable convolutions. The proposed QKD outperformed existing state-of-the-art methods (e.g., 1.3% improvement on ResNet-18 with W4A4, 2.6% on MobileNetV2 with W4A4). Additionally, QKD could recover the full-precision accuracy at as low as W3A3 quantization on ResNet and W6A6 quantization on MobilenetV2.
Feature Fusion for Online Mutual Knowledge Distillation
Apr 19, 2019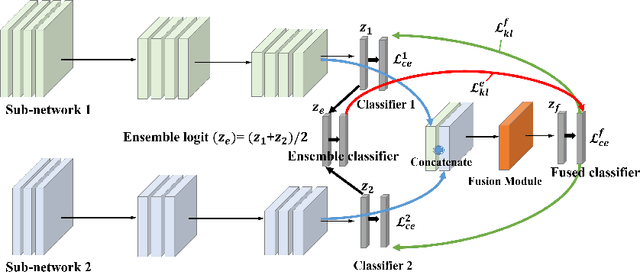
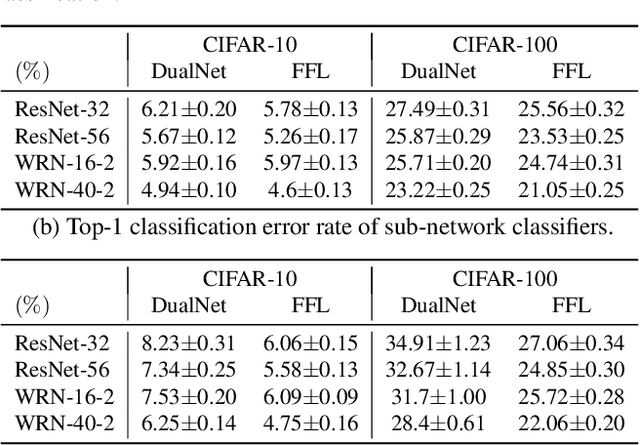

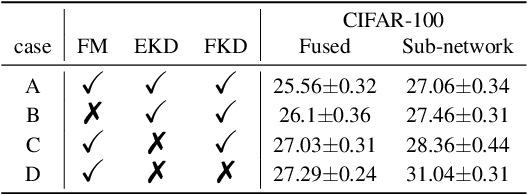
We propose a learning framework named Feature Fusion Learning (FFL) that efficiently trains a powerful classifier through a fusion module which combines the feature maps generated from parallel neural networks. Specifically, we train a number of parallel neural networks as sub-networks, then we combine the feature maps from each sub-network using a fusion module to create a more meaningful feature map. The fused feature map is passed into the fused classifier for overall classification. Unlike existing feature fusion methods, in our framework, an ensemble of sub-network classifiers transfers its knowledge to the fused classifier and then the fused classifier delivers its knowledge back to each sub-network, mutually teaching one another in an online-knowledge distillation manner. This mutually teaching system not only improves the performance of the fused classifier but also obtains performance gain in each sub-network. Moreover, our model is more beneficial because different types of network can be used for each sub-network. We have performed a variety of experiments on multiple datasets such as CIFAR-10, CIFAR-100 and ImageNet and proved that our method is more effective than other alternative methods in terms of performance of both sub-networks and the fused classifier.
Paraphrasing Complex Network: Network Compression via Factor Transfer
Sep 27, 2018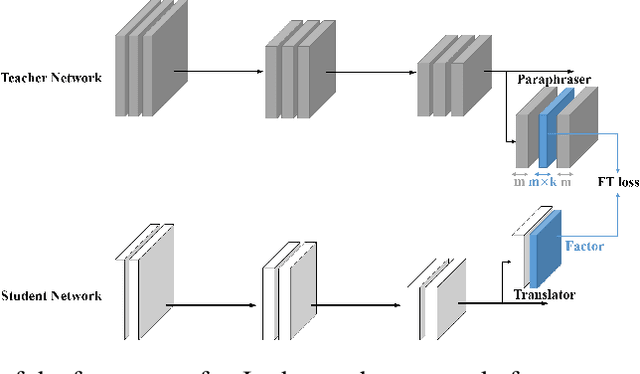
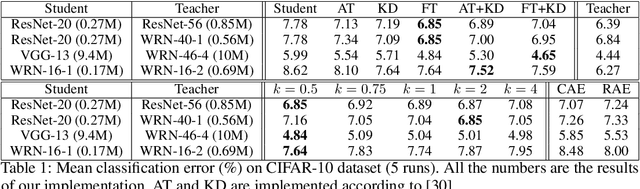
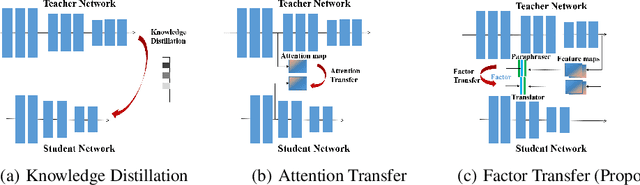

Deep neural networks (DNN) have recently shown promising performances in various areas. Although DNNs are very powerful, a large number of network parameters requires substantial storage and memory bandwidth which hinders them from being applied to actual embedded systems. Many researchers have sought ways of model compression to reduce the size of a network with minimal performance degradation. Among them, a method called knowledge transfer is to train the student network with a stronger teacher network. In this paper, we propose a method to overcome the limitations of conventional knowledge transfer methods and improve the performance of a student network. An auto-encoder is used in an unsupervised manner to extract compact factors which are defined as compressed feature maps of the teacher network. When using the factors to train the student network, we observed that the performance of the student network becomes better than the ones with other conventional knowledge transfer methods because factors contain paraphrased compact information of the teacher network that is easy for the student network to understand.
HC-Net: Memory-based Incremental Dual-Network System for Continual learning
Sep 07, 2018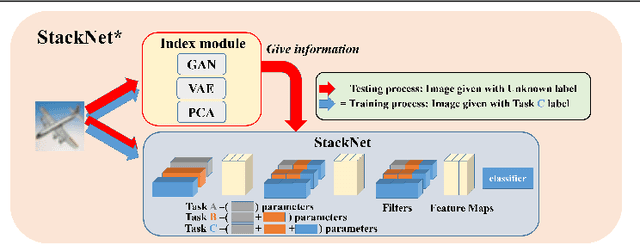
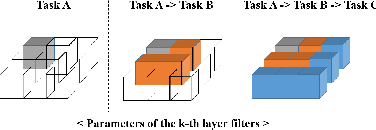
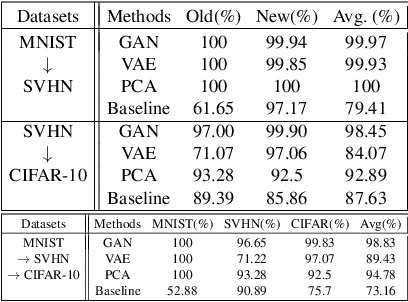
Training a neural network for a classification task typically assumes that the data to train are given from the beginning. However, in the real world, additional data accumulate gradually and the model requires additional training without accessing the old training data. This usually leads to the catastrophic forgetting problem which is inevitable for the traditional training methodology of neural networks. In this paper, we propose a memory-based continual learning method that is able to learn additional tasks while retaining the performance of previously learned tasks. Composed of two complementary networks, the Hippocampus-net (H-net) and the Cortex-net (C-net), our model estimates the index of the corresponding task for an input sample and utilizes a particular portion of itself with the estimated index. The C-net guarantees no degradation in the performance of the previously learned tasks and the H-net shows high confidence in finding the origin of the input sample
Generating objects going well with the surroundings
Jul 09, 2018
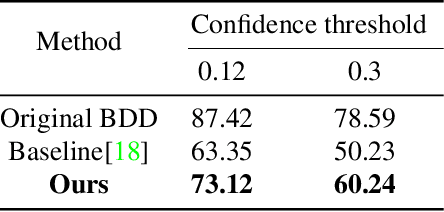
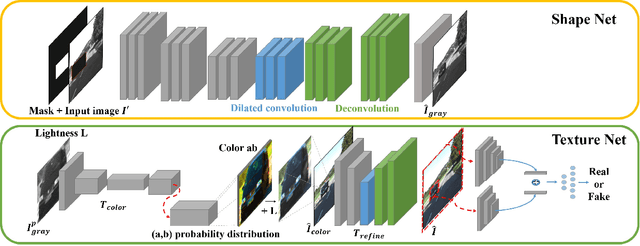

Since the generative adversarial network has made a breakthrough in the image generation problem, lots of researches on its applications have been studied such as image restoration, style transfer and image completion. However, there have been few researches generating objects in uncontrolled real-world environments. In this paper, we propose a novel approach for image generation in real-world scenes. The overall architecture consists of two different networks each of which completes the shape of the generating object and paints the context on it respectively. Using a subnetwork proposed in a precedent work of image completion, our model make the shape of an object. Unlike the approaches used in the image completion problem, details of trained objects are encoded into a latent variable by an additional subnetwork, resulting in a better quality of the generated objects. We evaluated our method using KITTI and City-scape datasets, which are widely used for object detection and image segmentation problems. The adequacy of the generated images by the proposed method has also been evaluated using a widely utilized object detection algorithm.