 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrack-MDP: Reinforcement Learning for Target Tracking with Controlled Sensing
Jul 19, 2024State of the art methods for target tracking with sensor management (or controlled sensing) are model-based and are obtained through solutions to Partially Observable Markov Decision Process (POMDP) formulations. In this paper a Reinforcement Learning (RL) approach to the problem is explored for the setting where the motion model for the object/target to be tracked is unknown to the observer. It is assumed that the target dynamics are stationary in time, the state space and the observation space are discrete, and there is complete observability of the location of the target under certain (a priori unknown) sensor control actions. Then, a novel Markov Decision Process (MDP) rather than POMDP formulation is proposed for the tracking problem with controlled sensing, which is termed as Track-MDP. In contrast to the POMDP formulation, the Track-MDP formulation is amenable to an RL based solution. It is shown that the optimal policy for the Track-MDP formulation, which is approximated through RL, is guaranteed to track all significant target paths with certainty. The Track-MDP method is then compared with the optimal POMDP policy, and it is shown that the infinite horizon tracking reward of the optimal Track-MDP policy is the same as that of the optimal POMDP policy. In simulations it is demonstrated that Track-MDP based RL leads to a policy that can track the target with high accuracy.
StarCraftImage: A Dataset For Prototyping Spatial Reasoning Methods For Multi-Agent Environments
Jan 09, 2024



Spatial reasoning tasks in multi-agent environments such as event prediction, agent type identification, or missing data imputation are important for multiple applications (e.g., autonomous surveillance over sensor networks and subtasks for reinforcement learning (RL)). StarCraft II game replays encode intelligent (and adversarial) multi-agent behavior and could provide a testbed for these tasks; however, extracting simple and standardized representations for prototyping these tasks is laborious and hinders reproducibility. In contrast, MNIST and CIFAR10, despite their extreme simplicity, have enabled rapid prototyping and reproducibility of ML methods. Following the simplicity of these datasets, we construct a benchmark spatial reasoning dataset based on StarCraft II replays that exhibit complex multi-agent behaviors, while still being as easy to use as MNIST and CIFAR10. Specifically, we carefully summarize a window of 255 consecutive game states to create 3.6 million summary images from 60,000 replays, including all relevant metadata such as game outcome and player races. We develop three formats of decreasing complexity: Hyperspectral images that include one channel for every unit type (similar to multispectral geospatial images), RGB images that mimic CIFAR10, and grayscale images that mimic MNIST. We show how this dataset can be used for prototyping spatial reasoning methods. All datasets, code for extraction, and code for dataset loading can be found at https://starcraftdata.davidinouye.com
* Published in CVPR 23'
A General Framework for Distributed Inference with Uncertain Models
Nov 20, 2020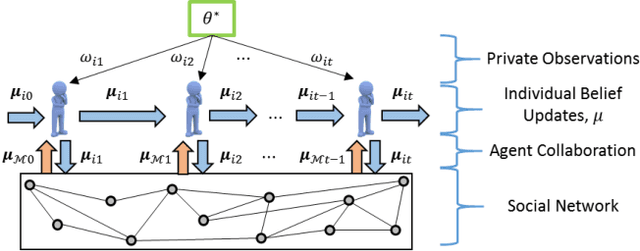
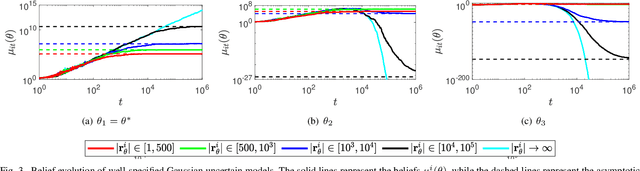
This paper studies the problem of distributed classification with a network of heterogeneous agents. The agents seek to jointly identify the underlying target class that best describes a sequence of observations. The problem is first abstracted to a hypothesis-testing framework, where we assume that the agents seek to agree on the hypothesis (target class) that best matches the distribution of observations. Non-Bayesian social learning theory provides a framework that solves this problem in an efficient manner by allowing the agents to sequentially communicate and update their beliefs for each hypothesis over the network. Most existing approaches assume that agents have access to exact statistical models for each hypothesis. However, in many practical applications, agents learn the likelihood models based on limited data, which induces uncertainty in the likelihood function parameters. In this work, we build upon the concept of uncertain models to incorporate the agents' uncertainty in the likelihoods by identifying a broad set of parametric distribution that allows the agents' beliefs to converge to the same result as a centralized approach. Furthermore, we empirically explore extensions to non-parametric models to provide a generalized framework of uncertain models in non-Bayesian social learning.
Non-Bayesian Social Learning with Uncertain Models
Sep 27, 2019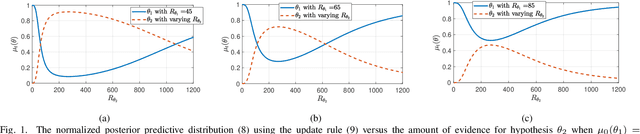
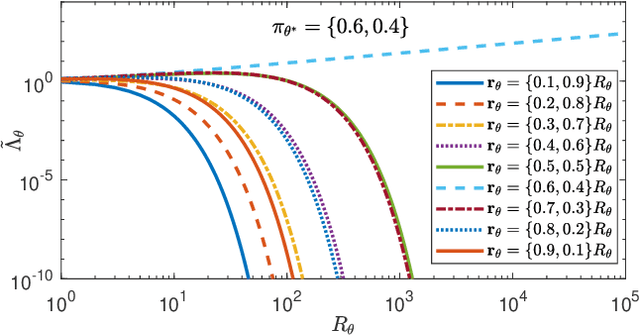
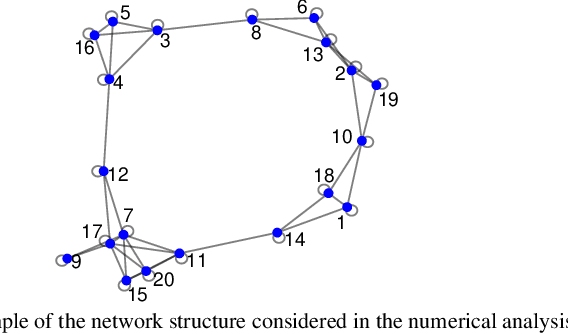
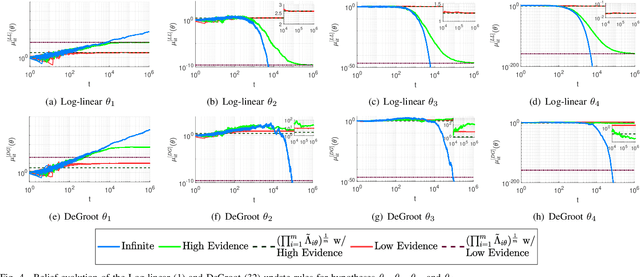
Non-Bayesian social learning theory provides a framework that models distributed inference for a group of agents interacting over a social network. In this framework, each agent iteratively forms and communicates beliefs about an unknown state of the world with their neighbors using a learning rule. Existing approaches assume agents have access to precise statistical models (in the form of likelihoods) for the state of the world. However in many situations, such models must be learned from finite data. We propose a social learning rule that takes into account uncertainty in the statistical models using second-order probabilities. Therefore, beliefs derived from uncertain models are sensitive to the amount of past evidence collected for each hypothesis. We characterize how well the hypotheses can be tested on a social network, as consistent or not with the state of the world. We explicitly show the dependency of the generated beliefs with respect to the amount of prior evidence. Moreover, as the amount of prior evidence goes to infinity, learning occurs and is consistent with traditional social learning theory.