 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-Correcting Neural Sequence Prediction
Jan 21, 2019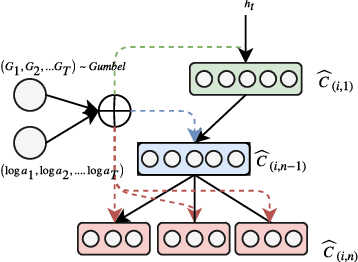
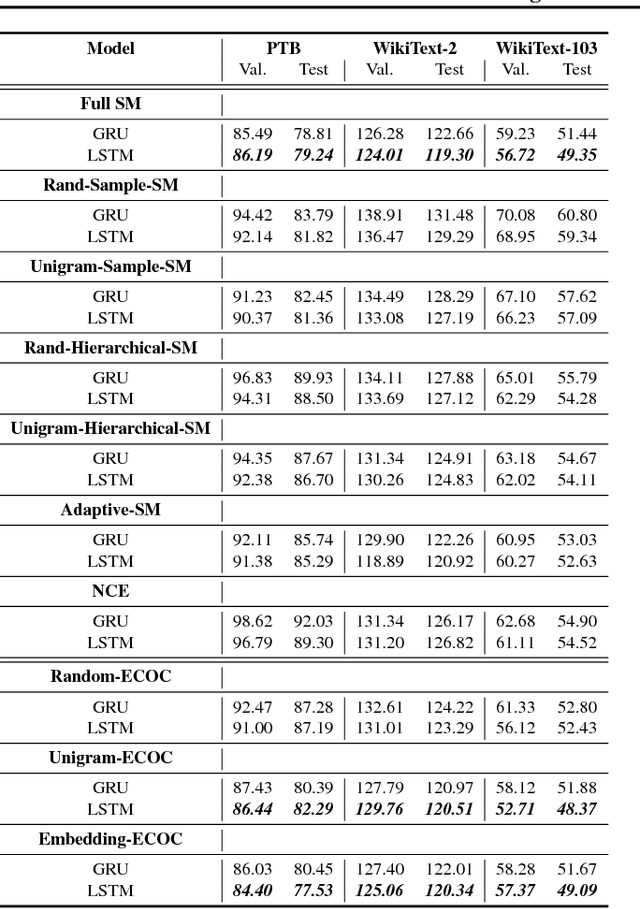
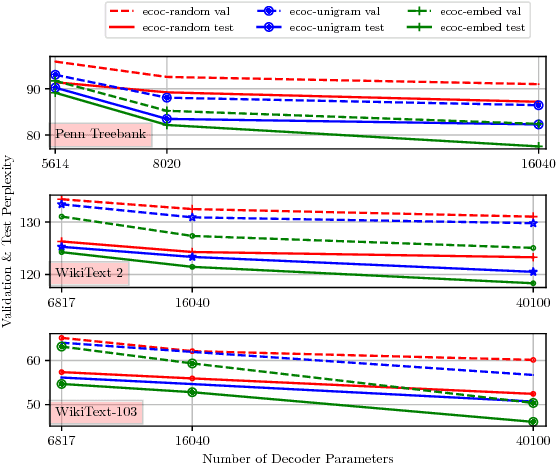
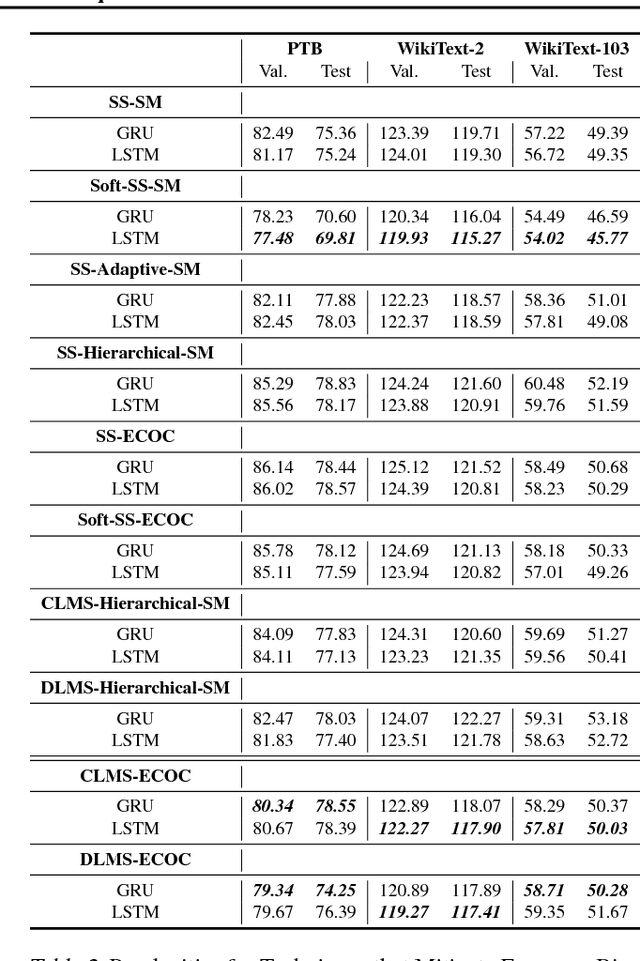
In this paper we propose a novel neural language modelling (NLM) method based on \textit{error-correcting output codes} (ECOC), abbreviated as ECOC-NLM. This latent variable based approach provides a principled way to choose a varying amount of latent output codes and avoids exact softmax normalization. Instead of minimizing measures between the predicted probability distribution and true distribution, we use error-correcting codes to represent both predictions and outputs. Secondly, we propose multiple ways to improve accuracy and convergence rates by maximizing the separability between codes that correspond to classes proportional to word embedding similarities. Lastly, we introduce a novel method called \textit{Latent Mixture Sampling}, a technique that is used to mitigate exposure bias and can be integrated into training latent-based neural language models. This involves mixing the latent codes (i.e variables) of past predictions and past targets in one of two ways: (1) according to a predefined sampling schedule or (2) a differentiable sampling procedure whereby the mixing probability is learned throughout training by replacing the greedy argmax operation with a smooth approximation. In evaluating Codeword Mixture Sampling for ECOC-NLM, we also baseline it against CWMS in a closely related Hierarhical Softmax-based NLM.
Analysing Dropout and Compounding Errors in Neural Language Models
Nov 02, 2018
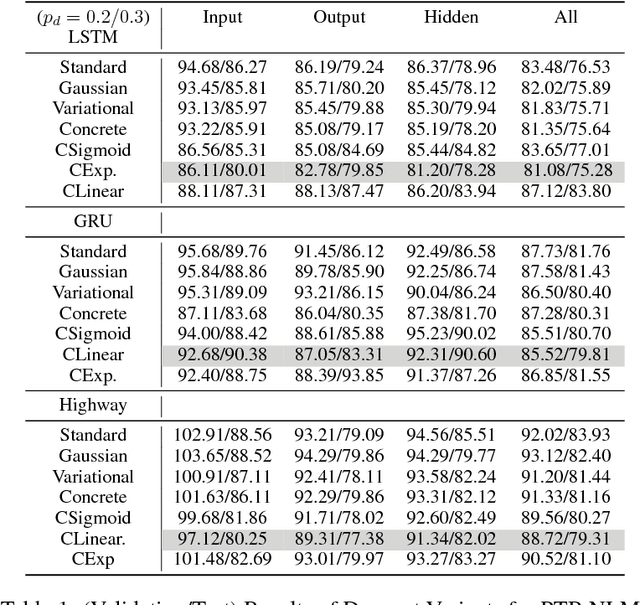
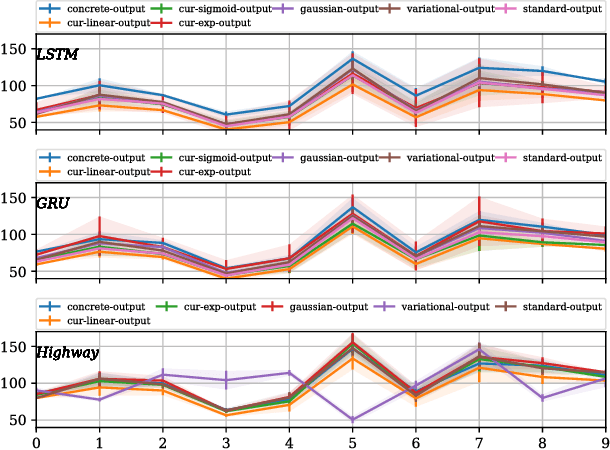
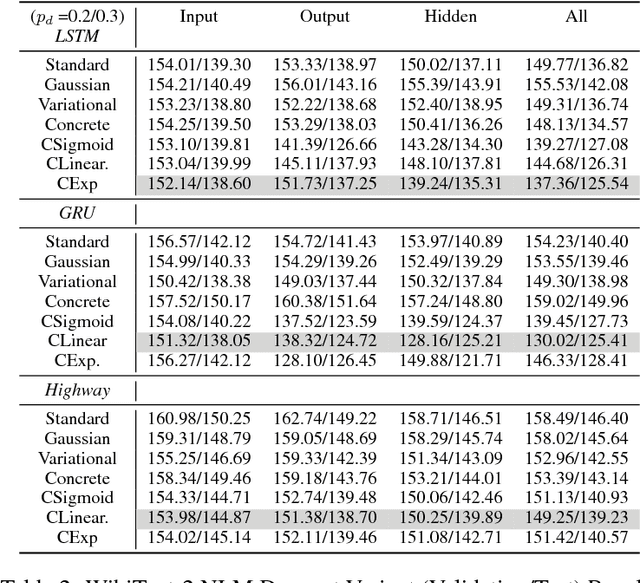
This paper carries out an empirical analysis of various dropout techniques for language modelling, such as Bernoulli dropout, Gaussian dropout, Curriculum Dropout, Variational Dropout and Concrete Dropout. Moreover, we propose an extension of variational dropout to concrete dropout and curriculum dropout with varying schedules. We find these extensions to perform well when compared to standard dropout approaches, particularly variational curriculum dropout with a linear schedule. Largest performance increases are made when applying dropout on the decoder layer. Lastly, we analyze where most of the errors occur at test time as a post-analysis step to determine if the well-known problem of compounding errors is apparent and to what end do the proposed methods mitigate this issue for each dataset. We report results on a 2-hidden layer LSTM, GRU and Highway network with embedding dropout, dropout on the gated hidden layers and the output projection layer for each model. We report our results on Penn-TreeBank and WikiText-2 word-level language modelling datasets, where the former reduces the long-tail distribution through preprocessing and one which preserves rare words in the training and test set.
Curriculum-Based Neighborhood Sampling For Sequence Prediction
Sep 16, 2018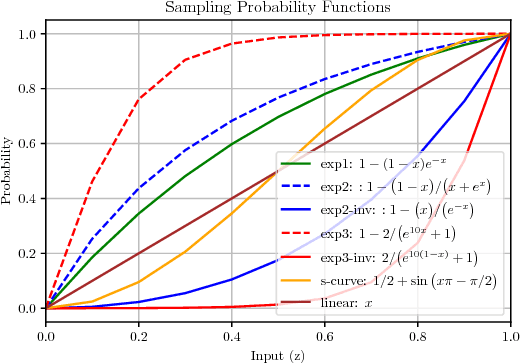
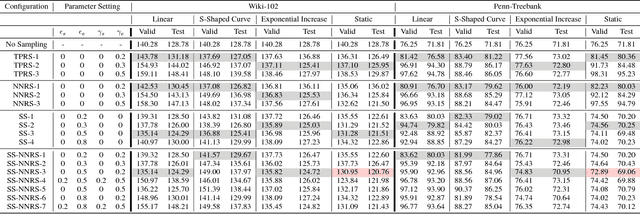
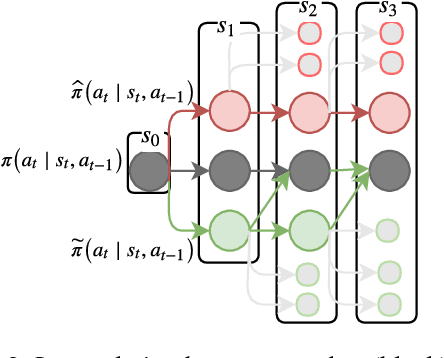
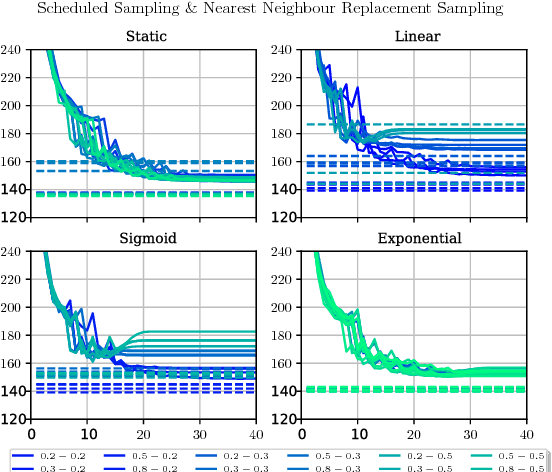
The task of multi-step ahead prediction in language models is challenging considering the discrepancy between training and testing. At test time, a language model is required to make predictions given past predictions as input, instead of the past targets that are provided during training. This difference, known as exposure bias, can lead to the compounding of errors along a generated sequence at test time. In order to improve generalization in neural language models and address compounding errors, we propose a curriculum learning based method that gradually changes an initially deterministic teacher policy to a gradually more stochastic policy, which we refer to as \textit{Nearest-Neighbor Replacement Sampling}. A chosen input at a given timestep is replaced with a sampled nearest neighbor of the past target with a truncated probability proportional to the cosine similarity between the original word and its top $k$ most similar words. This allows the teacher to explore alternatives when the teacher provides a sub-optimal policy or when the initial policy is difficult for the learner to model. The proposed strategy is straightforward, online and requires little additional memory requirements. We report our main findings on two language modelling benchmarks and find that the proposed approach performs particularly well when used in conjunction with scheduled sampling, that too attempts to mitigate compounding errors in language models.
Dropping Networks for Transfer Learning
Sep 16, 2018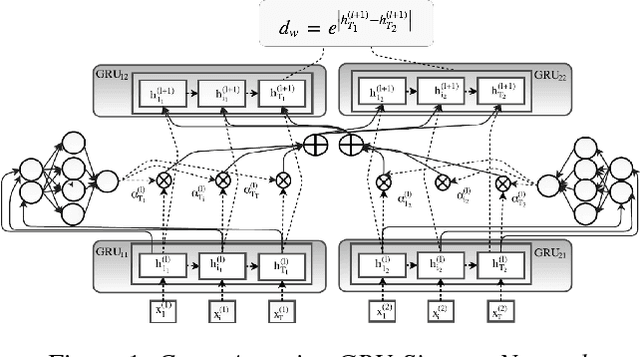

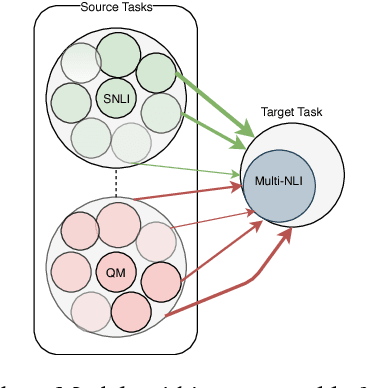
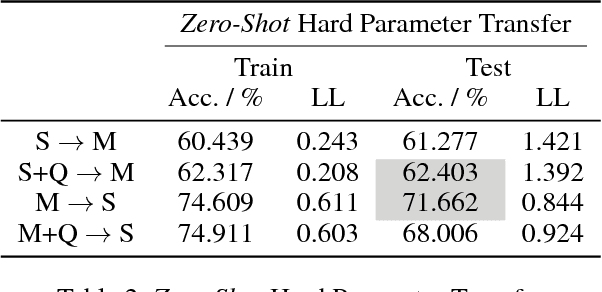
Many tasks in natural language understanding require learning relationships between two sequences for various tasks such as natural language inference, paraphrasing and entailment. These aforementioned tasks are similar in nature, yet they are often modeled individually. Knowledge transfer can be effective for closely related tasks. However, transferring all knowledge, some of which irrelevant for a target task, can lead to sub-optimal results due to \textit{negative} transfer. Hence, this paper focuses on the transferability of both instances and parameters across natural language understanding tasks by proposing an ensemble-based transfer learning method. \newline The primary contribution of this paper is the combination of both \textit{Dropout} and \textit{Bagging} for improved transferability in neural networks, referred to as \textit{Dropping} herein. We present a straightforward yet novel approach for incorporating source \textit{Dropping} Networks to a target task for few-shot learning that mitigates \textit{negative} transfer. This is achieved by using a decaying parameter chosen according to the slope changes of a smoothed spline error curve at sub-intervals during training. We compare the proposed approach against hard parameter sharing and soft parameter sharing transfer methods in the few-shot learning case. We also compare against models that are fully trained on the target task in the standard supervised learning setup. The aforementioned adjustment leads to improved transfer learning performance and comparable results to the current state of the art only using a fraction of the data from the target task.
Semi-Supervised Multi-Task Word Embeddings
Sep 16, 2018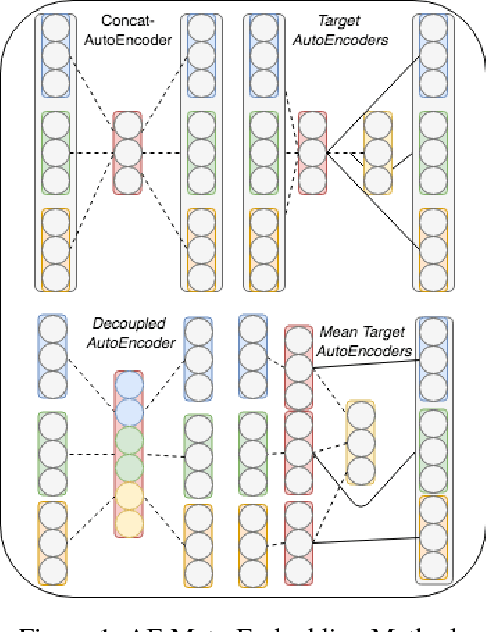
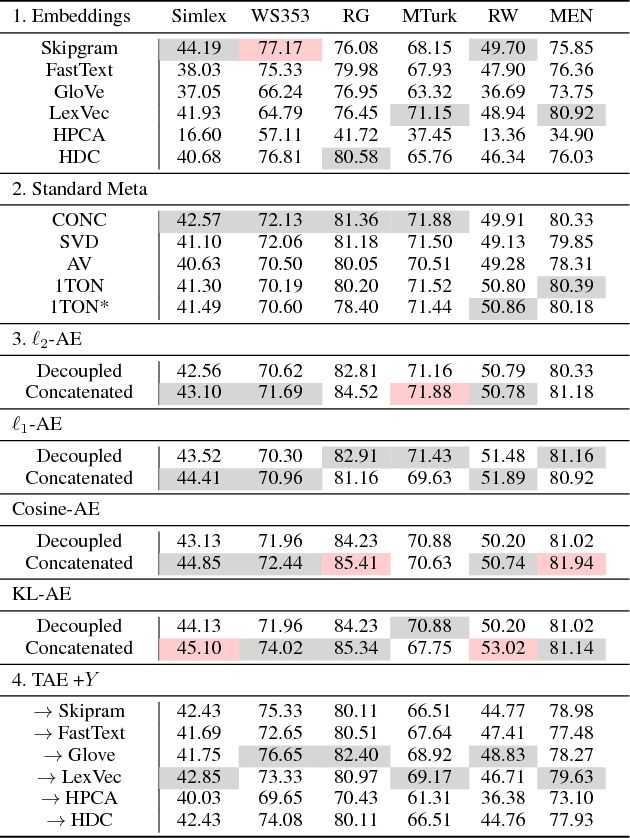
Word embeddings have been shown to benefit from ensembling several word embedding sources, often carried out using straightforward mathematical operations over the set of vectors to produce a meta-embedding representation. More recently, unsupervised learning has been used to find a lower-dimensional representation, similar in size to that of the word embeddings within the ensemble. However, these methods do not use the available manual labeled datasets that are often used solely for the purpose of evaluation. We propose to improve word embeddings by simultaneously learning to reconstruct an ensemble of pretrained word embeddings with supervision from various labeled word similarity datasets. This involves reconstructing word meta-embeddings while simultaneously using a Siamese Network to also learn word similarity where both processes share a hidden layer. Experiments are carried out on 6 word similarity datasets and 3 analogy datasets. We find that performance is improved for all word similarity datasets when compared to unsupervised learning methods with a mean increase of 11.33 in the Spearman Correlation coefficient. Moreover, 4 of 6 of word similarity datasets from our approach show best performance when using of a cosine loss for reconstruction and Brier's loss for word similarity.
Angular-Based Word Meta-Embedding Learning
Aug 13, 2018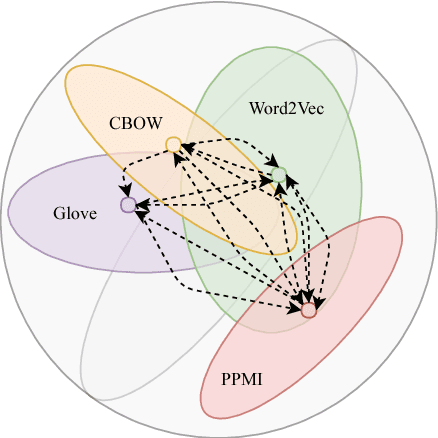
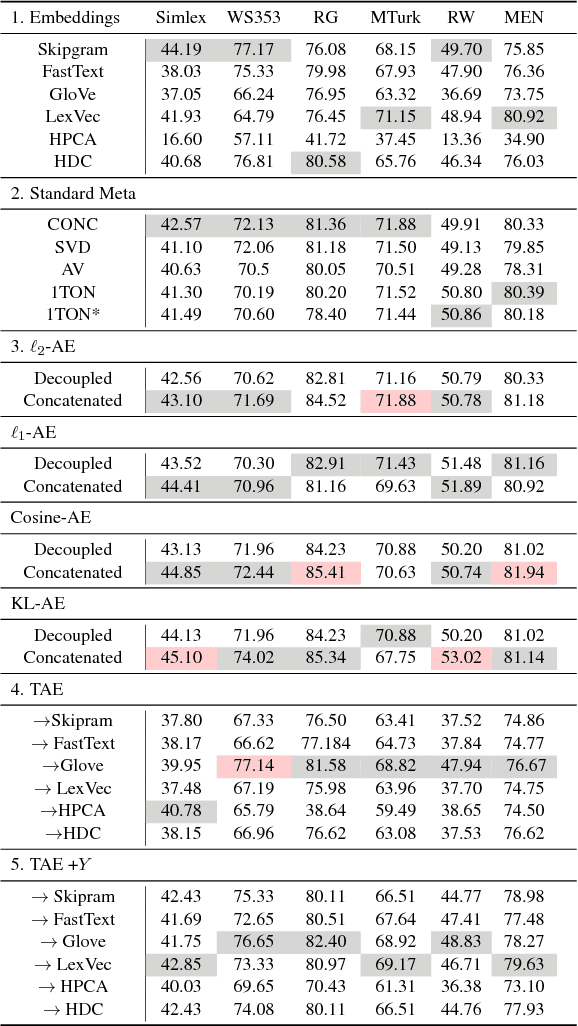
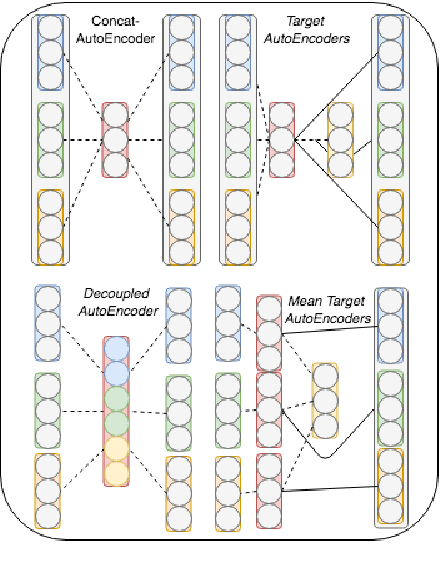
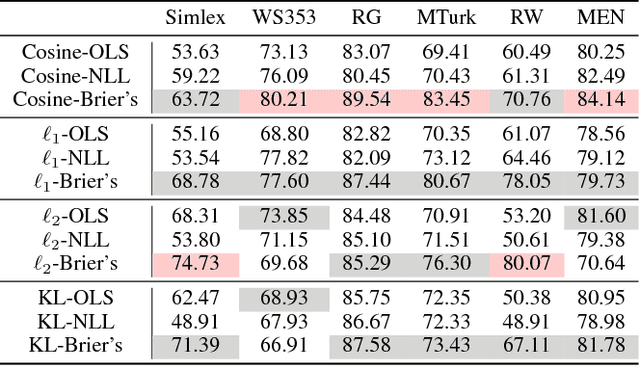
Ensembling word embeddings to improve distributed word representations has shown good success for natural language processing tasks in recent years. These approaches either carry out straightforward mathematical operations over a set of vectors or use unsupervised learning to find a lower-dimensional representation. This work compares meta-embeddings trained for different losses, namely loss functions that account for angular distance between the reconstructed embedding and the target and those that account normalized distances based on the vector length. We argue that meta-embeddings are better to treat the ensemble set equally in unsupervised learning as the respective quality of each embedding is unknown for upstream tasks prior to meta-embedding. We show that normalization methods that account for this such as cosine and KL-divergence objectives outperform meta-embedding trained on standard $\ell_1$ and $\ell_2$ loss on \textit{defacto} word similarity and relatedness datasets and find it outperforms existing meta-learning strategies.
Siamese Capsule Networks
May 18, 2018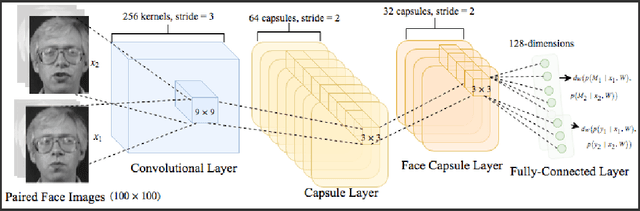
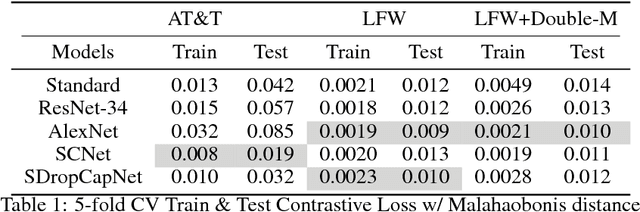
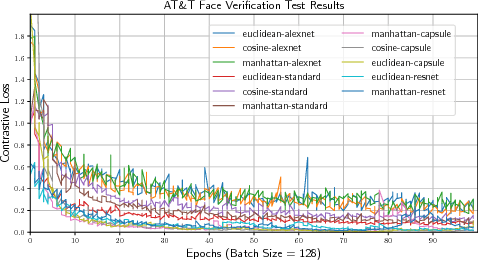
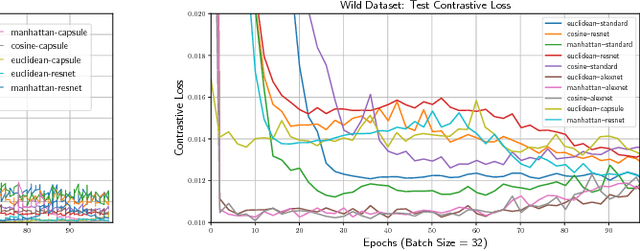
Capsule Networks have shown encouraging results on \textit{defacto} benchmark computer vision datasets such as MNIST, CIFAR and smallNORB. Although, they are yet to be tested on tasks where (1) the entities detected inherently have more complex internal representations and (2) there are very few instances per class to learn from and (3) where point-wise classification is not suitable. Hence, this paper carries out experiments on face verification in both controlled and uncontrolled settings that together address these points. In doing so we introduce \textit{Siamese Capsule Networks}, a new variant that can be used for pairwise learning tasks. The model is trained using contrastive loss with $\ell_2$-normalized capsule encoded pose features. We find that \textit{Siamese Capsule Networks} perform well against strong baselines on both pairwise learning datasets, yielding best results in the few-shot learning setting where image pairs in the test set contain unseen subjects.