 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Gaussian Processes with Spherical Harmonic Features Revisited
Mar 28, 2023


We revisit the Gaussian process model with spherical harmonic features and study connections between the associated RKHS, its eigenstructure and deep models. Based on this, we introduce a new class of kernels which correspond to deep models of continuous depth. In our formulation, depth can be estimated as a kernel hyper-parameter by optimizing the evidence lower bound. Further, we introduce sparseness in the eigenbasis by variational learning of the spherical harmonic phases. This enables scaling to larger input dimensions than previously, while also allowing for learning of high frequency variations. We validate our approach on machine learning benchmark datasets.
Additive Gaussian Processes Revisited
Jun 20, 2022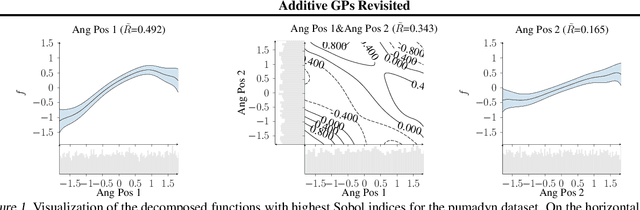
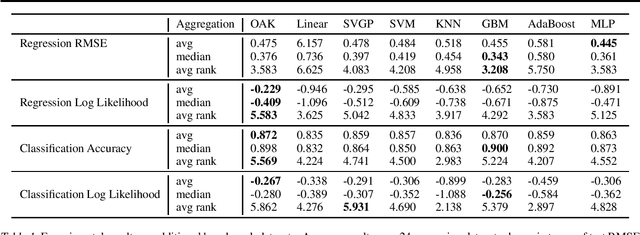
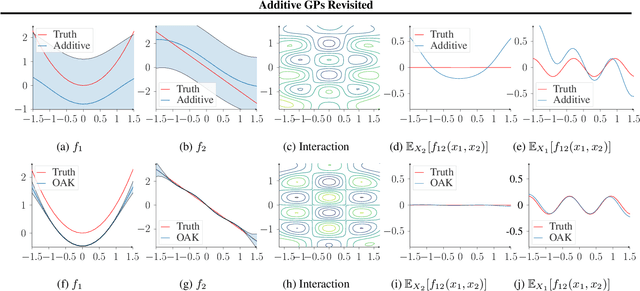
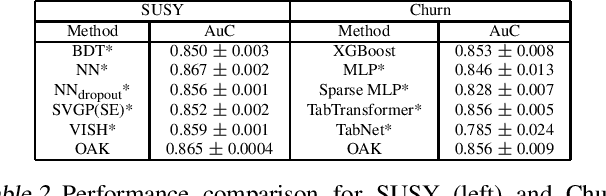
Gaussian Process (GP) models are a class of flexible non-parametric models that have rich representational power. By using a Gaussian process with additive structure, complex responses can be modelled whilst retaining interpretability. Previous work showed that additive Gaussian process models require high-dimensional interaction terms. We propose the orthogonal additive kernel (OAK), which imposes an orthogonality constraint on the additive functions, enabling an identifiable, low-dimensional representation of the functional relationship. We connect the OAK kernel to functional ANOVA decomposition, and show improved convergence rates for sparse computation methods. With only a small number of additive low-dimensional terms, we demonstrate the OAK model achieves similar or better predictive performance compared to black-box models, while retaining interpretability.
Deep Neural Networks as Point Estimates for Deep Gaussian Processes
May 10, 2021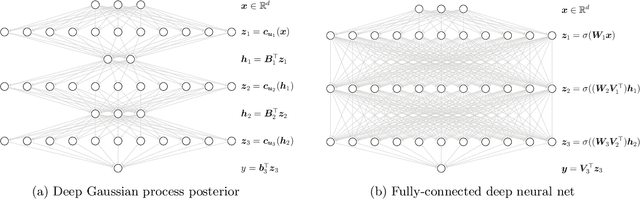
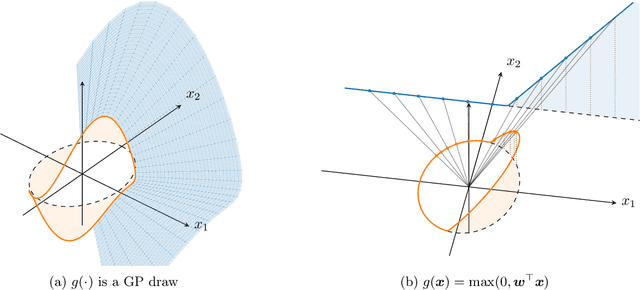
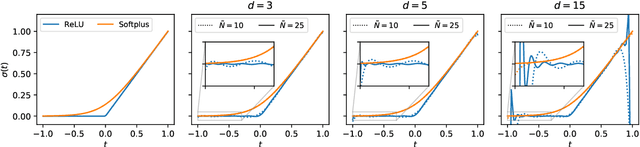
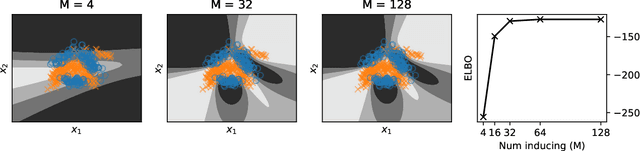
Deep Gaussian processes (DGPs) have struggled for relevance in applications due to the challenges and cost associated with Bayesian inference. In this paper we propose a sparse variational approximation for DGPs for which the approximate posterior mean has the same mathematical structure as a Deep Neural Network (DNN). We make the forward pass through a DGP equivalent to a ReLU DNN by finding an interdomain transformation that represents the GP posterior mean as a sum of ReLU basis functions. This unification enables the initialisation and training of the DGP as a neural network, leveraging the well established practice in the deep learning community, and so greatly aiding the inference task. The experiments demonstrate improved accuracy and faster training compared to current DGP methods, while retaining favourable predictive uncertainties.
GPflux: A Library for Deep Gaussian Processes
Apr 12, 2021
We introduce GPflux, a Python library for Bayesian deep learning with a strong emphasis on deep Gaussian processes (DGPs). Implementing DGPs is a challenging endeavour due to the various mathematical subtleties that arise when dealing with multivariate Gaussian distributions and the complex bookkeeping of indices. To date, there are no actively maintained, open-sourced and extendable libraries available that support research activities in this area. GPflux aims to fill this gap by providing a library with state-of-the-art DGP algorithms, as well as building blocks for implementing novel Bayesian and GP-based hierarchical models and inference schemes. GPflux is compatible with and built on top of the Keras deep learning eco-system. This enables practitioners to leverage tools from the deep learning community for building and training customised Bayesian models, and create hierarchical models that consist of Bayesian and standard neural network layers in a single coherent framework. GPflux relies on GPflow for most of its GP objects and operations, which makes it an efficient, modular and extensible library, while having a lean codebase.
Sparse Gaussian Processes with Spherical Harmonic Features
Jun 30, 2020



We introduce a new class of inter-domain variational Gaussian processes (GP) where data is mapped onto the unit hypersphere in order to use spherical harmonic representations. Our inference scheme is comparable to variational Fourier features, but it does not suffer from the curse of dimensionality, and leads to diagonal covariance matrices between inducing variables. This enables a speed-up in inference, because it bypasses the need to invert large covariance matrices. Our experiments show that our model is able to fit a regression model for a dataset with 6 million entries two orders of magnitude faster compared to standard sparse GPs, while retaining state of the art accuracy. We also demonstrate competitive performance on classification with non-conjugate likelihoods.
Amortized variance reduction for doubly stochastic objectives
Mar 09, 2020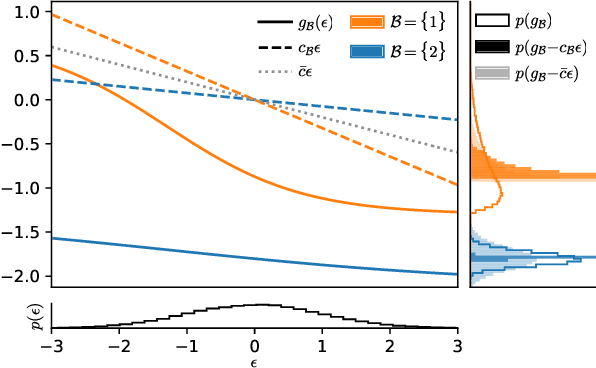
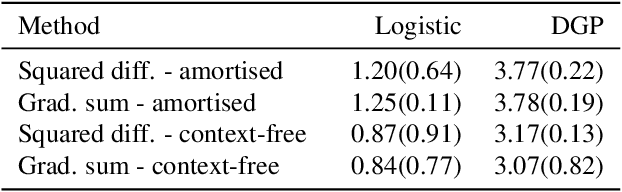
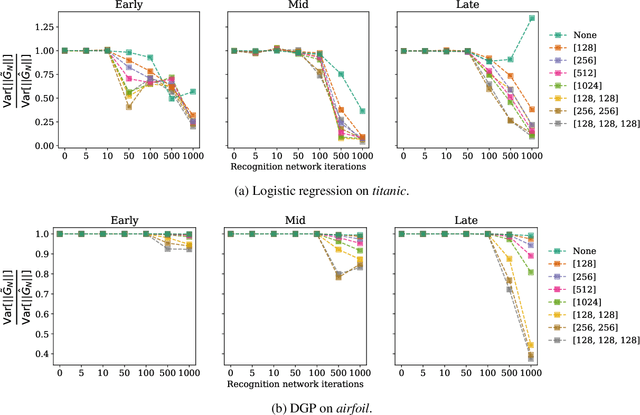
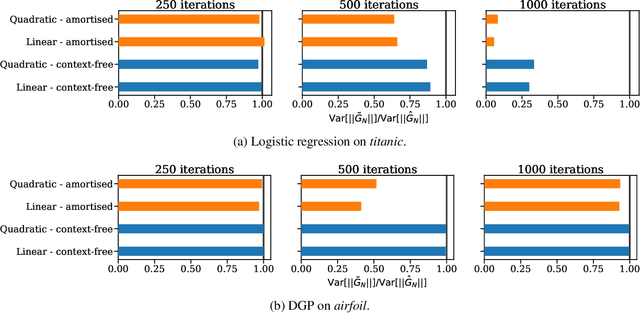
Approximate inference in complex probabilistic models such as deep Gaussian processes requires the optimisation of doubly stochastic objective functions. These objectives incorporate randomness both from mini-batch subsampling of the data and from Monte Carlo estimation of expectations. If the gradient variance is high, the stochastic optimisation problem becomes difficult with a slow rate of convergence. Control variates can be used to reduce the variance, but past approaches do not take into account how mini-batch stochasticity affects sampling stochasticity, resulting in sub-optimal variance reduction. We propose a new approach in which we use a recognition network to cheaply approximate the optimal control variate for each mini-batch, with no additional model gradient computations. We illustrate the properties of this proposal and test its performance on logistic regression and deep Gaussian processes.
A Framework for Interdomain and Multioutput Gaussian Processes
Mar 02, 2020
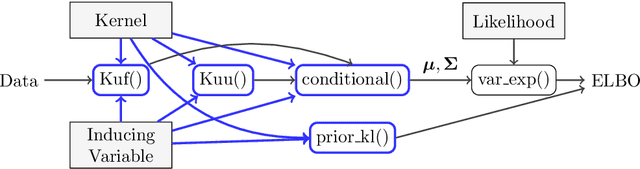

One obstacle to the use of Gaussian processes (GPs) in large-scale problems, and as a component in deep learning system, is the need for bespoke derivations and implementations for small variations in the model or inference. In order to improve the utility of GPs we need a modular system that allows rapid implementation and testing, as seen in the neural network community. We present a mathematical and software framework for scalable approximate inference in GPs, which combines interdomain approximations and multiple outputs. Our framework, implemented in GPflow, provides a unified interface for many existing multioutput models, as well as more recent convolutional structures. This simplifies the creation of deep models with GPs, and we hope that this work will encourage more interest in this approach.
Doubly Sparse Variational Gaussian Processes
Jan 15, 2020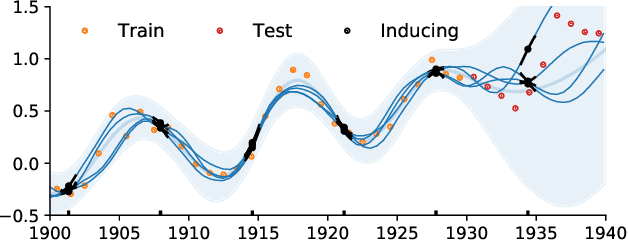


The use of Gaussian process models is typically limited to datasets with a few tens of thousands of observations due to their complexity and memory footprint. The two most commonly used methods to overcome this limitation are 1) the variational sparse approximation which relies on inducing points and 2) the state-space equivalent formulation of Gaussian processes which can be seen as exploiting some sparsity in the precision matrix. We propose to take the best of both worlds: we show that the inducing point framework is still valid for state space models and that it can bring further computational and memory savings. Furthermore, we provide the natural gradient formulation for the proposed variational parameterisation. Finally, this work makes it possible to use the state-space formulation inside deep Gaussian process models as illustrated in one of the experiments.
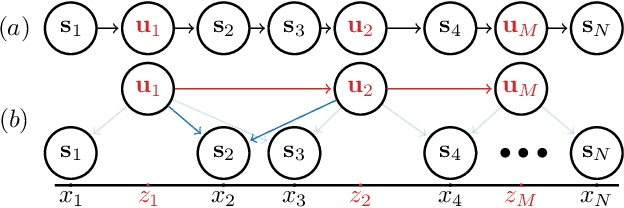
Overcoming Mean-Field Approximations in Recurrent Gaussian Process Models
Jun 13, 2019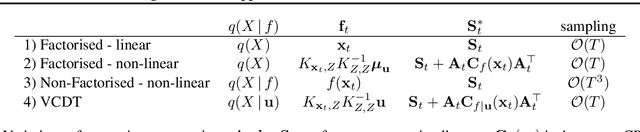
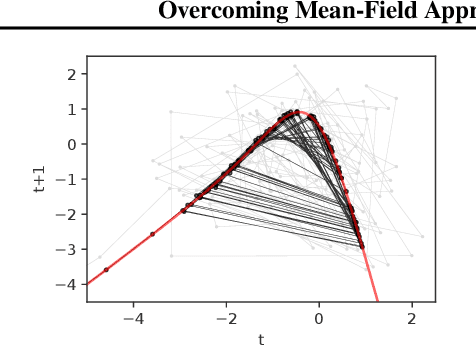
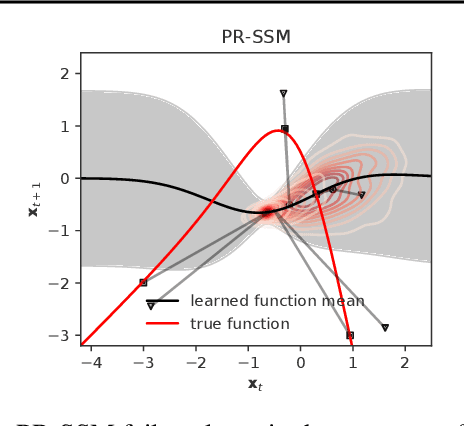

We identify a new variational inference scheme for dynamical systems whose transition function is modelled by a Gaussian process. Inference in this setting has either employed computationally intensive MCMC methods, or relied on factorisations of the variational posterior. As we demonstrate in our experiments, the factorisation between latent system states and transition function can lead to a miscalibrated posterior and to learning unnecessarily large noise terms. We eliminate this factorisation by explicitly modelling the dependence between state trajectories and the Gaussian process posterior. Samples of the latent states can then be tractably generated by conditioning on this representation. The method we obtain (VCDT: variationally coupled dynamics and trajectories) gives better predictive performance and more calibrated estimates of the transition function, yet maintains the same time and space complexities as mean-field methods. Code is available at: github.com/ialong/GPt.
* 10 pages, 4 figures, 3 tables. Published in the proceedings of the Thirty-sixth International Conference on Machine Learning (ICML), 2019
Deep Gaussian Processes with Importance-Weighted Variational Inference
May 14, 2019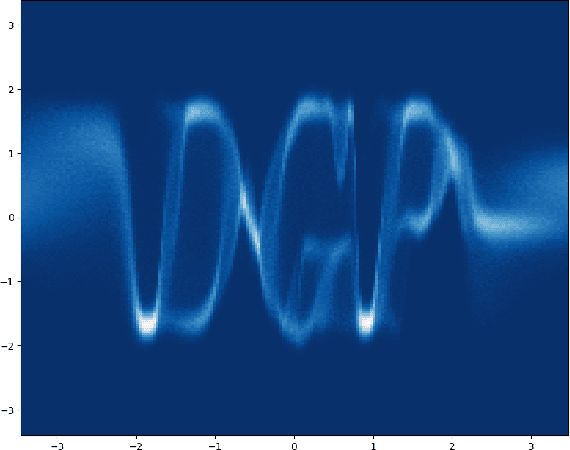
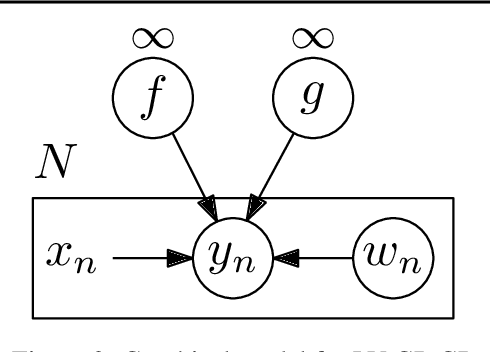
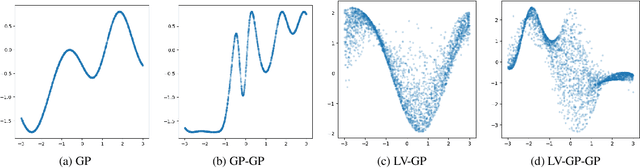
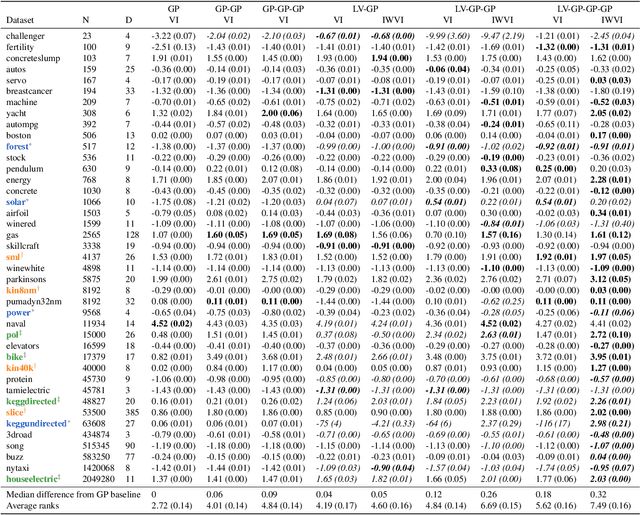
Deep Gaussian processes (DGPs) can model complex marginal densities as well as complex mappings. Non-Gaussian marginals are essential for modelling real-world data, and can be generated from the DGP by incorporating uncorrelated variables to the model. Previous work on DGP models has introduced noise additively and used variational inference with a combination of sparse Gaussian processes and mean-field Gaussians for the approximate posterior. Additive noise attenuates the signal, and the Gaussian form of variational distribution may lead to an inaccurate posterior. We instead incorporate noisy variables as latent covariates, and propose a novel importance-weighted objective, which leverages analytic results and provides a mechanism to trade off computation for improved accuracy. Our results demonstrate that the importance-weighted objective works well in practice and consistently outperforms classical variational inference, especially for deeper models.