 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJames Glass
Improved Speech Representations with Multi-Target Autoregressive Predictive Coding
Apr 11, 2020
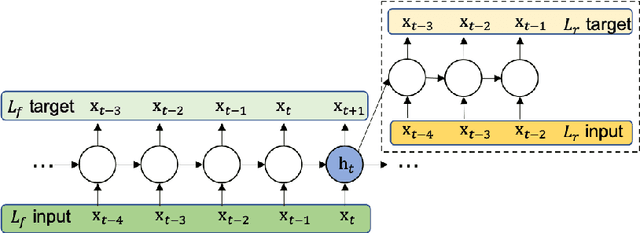
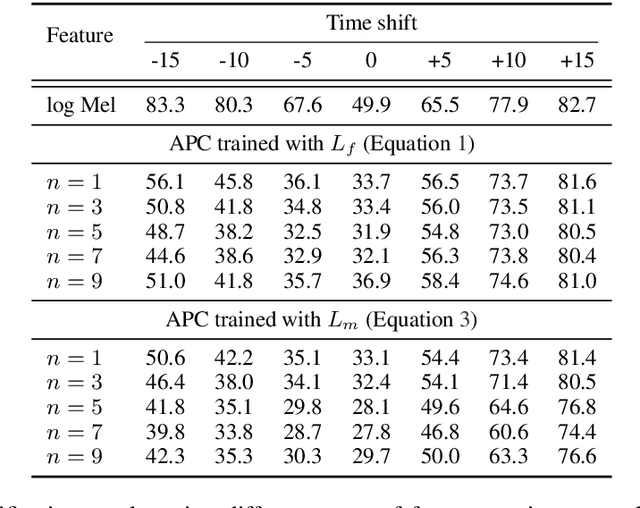
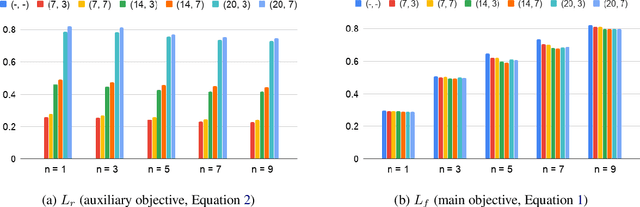

Training objectives based on predictive coding have recently been shown to be very effective at learning meaningful representations from unlabeled speech. One example is Autoregressive Predictive Coding (Chung et al., 2019), which trains an autoregressive RNN to generate an unseen future frame given a context such as recent past frames. The basic hypothesis of these approaches is that hidden states that can accurately predict future frames are a useful representation for many downstream tasks. In this paper we extend this hypothesis and aim to enrich the information encoded in the hidden states by training the model to make more accurate future predictions. We propose an auxiliary objective that serves as a regularization to improve generalization of the future frame prediction task. Experimental results on phonetic classification, speech recognition, and speech translation not only support the hypothesis, but also demonstrate the effectiveness of our approach in learning representations that contain richer phonetic content.
SemEval-2016 Task 3: Community Question Answering
Dec 03, 2019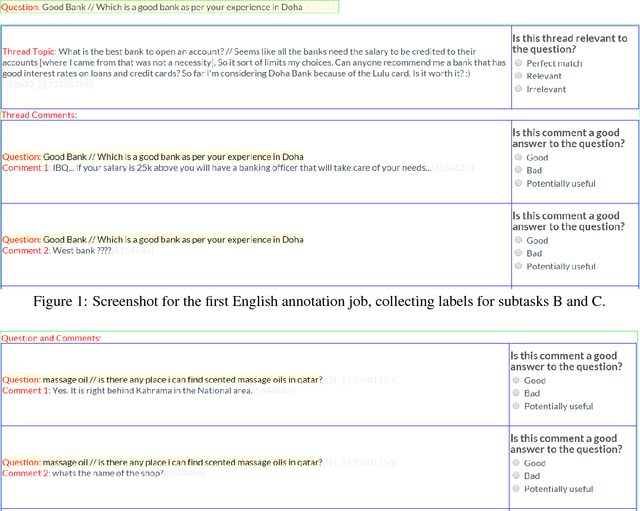
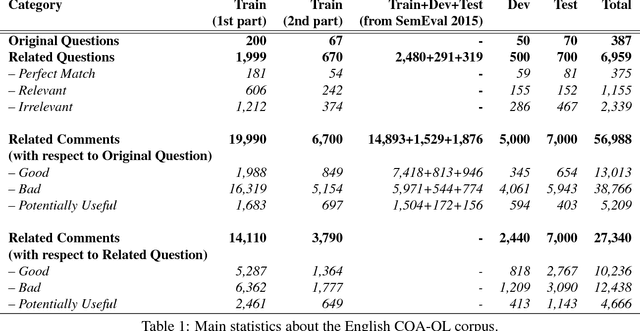
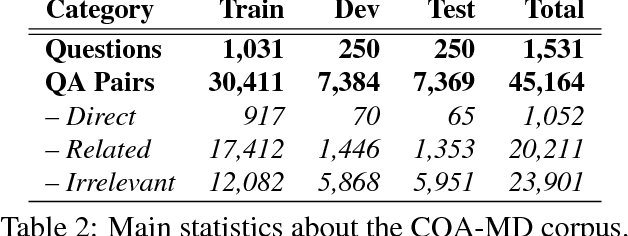
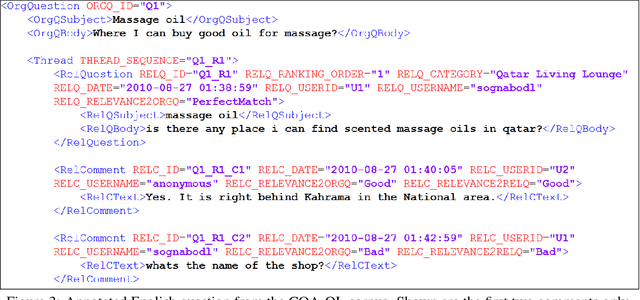
This paper describes the SemEval--2016 Task 3 on Community Question Answering, which we offered in English and Arabic. For English, we had three subtasks: Question--Comment Similarity (subtask A), Question--Question Similarity (B), and Question--External Comment Similarity (C). For Arabic, we had another subtask: Rerank the correct answers for a new question (D). Eighteen teams participated in the task, submitting a total of 95 runs (38 primary and 57 contrastive) for the four subtasks. A variety of approaches and features were used by the participating systems to address the different subtasks, which are summarized in this paper. The best systems achieved an official score (MAP) of 79.19, 76.70, 55.41, and 45.83 in subtasks A, B, C, and D, respectively. These scores are significantly better than those for the baselines that we provided. For subtask A, the best system improved over the 2015 winner by 3 points absolute in terms of Accuracy.
* community question answering, question-question similarity, question-comment similarity, answer reranking, English, Arabic. arXiv admin note: substantial text overlap with arXiv:1912.00730
SemEval-2015 Task 3: Answer Selection in Community Question Answering
Nov 26, 2019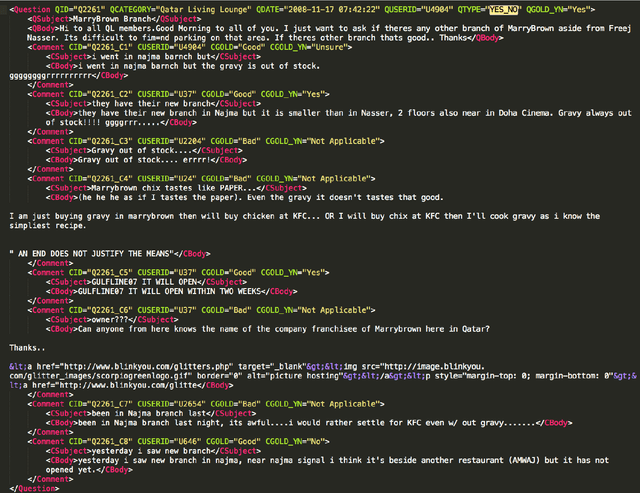
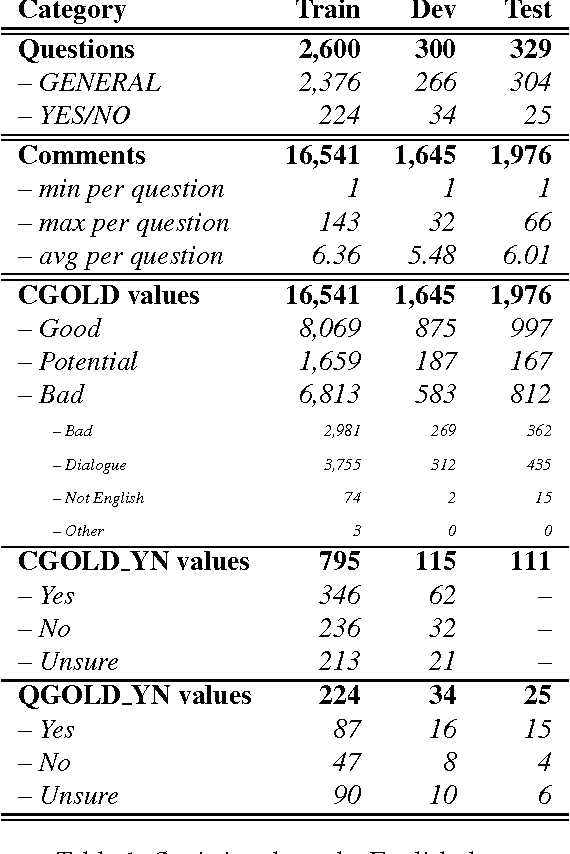
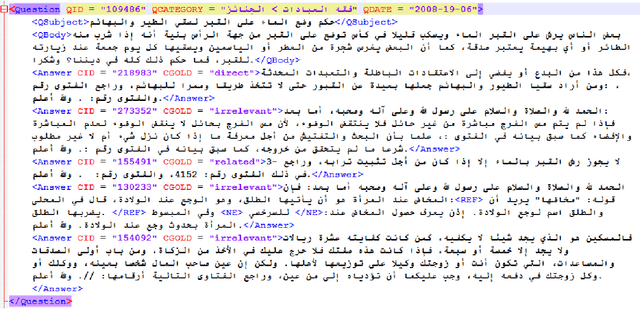
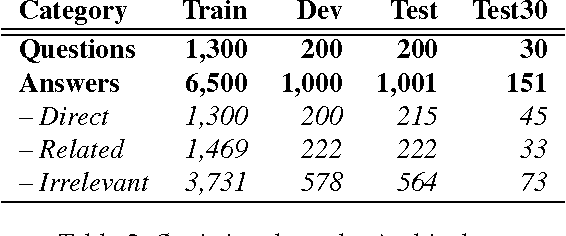
Community Question Answering (cQA) provides new interesting research directions to the traditional Question Answering (QA) field, e.g., the exploitation of the interaction between users and the structure of related posts. In this context, we organized SemEval-2015 Task 3 on "Answer Selection in cQA", which included two subtasks: (a) classifying answers as "good", "bad", or "potentially relevant" with respect to the question, and (b) answering a YES/NO question with "yes", "no", or "unsure", based on the list of all answers. We set subtask A for Arabic and English on two relatively different cQA domains, i.e., the Qatar Living website for English, and a Quran-related website for Arabic. We used crowdsourcing on Amazon Mechanical Turk to label a large English training dataset, which we released to the research community. Thirteen teams participated in the challenge with a total of 61 submissions: 24 primary and 37 contrastive. The best systems achieved an official score (macro-averaged F1) of 57.19 and 63.7 for the English subtasks A and B, and 78.55 for the Arabic subtask A.
* community question answering, answer selection, English, Arabic
Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech
Nov 21, 2019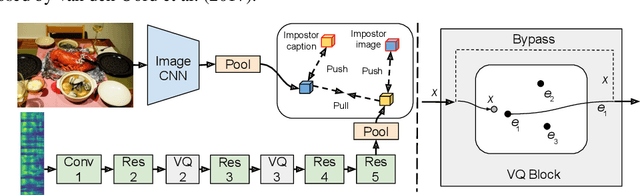
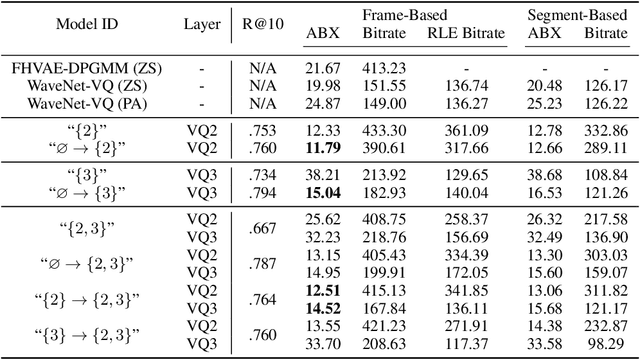
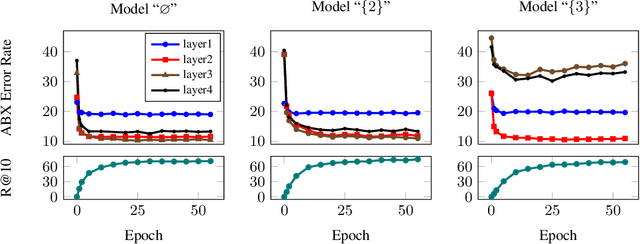
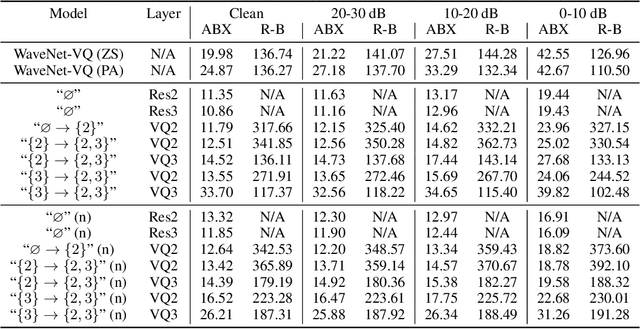
In this paper, we present a method for learning discrete linguistic units by incorporating vector quantization layers into neural models of visually grounded speech. We show that our method is capable of capturing both word-level and sub-word units, depending on how it is configured. What differentiates this paper from prior work on speech unit learning is the choice of training objective. Rather than using a reconstruction-based loss, we use a discriminative, multimodal grounding objective which forces the learned units to be useful for semantic image retrieval. We evaluate the sub-word units on the ZeroSpeech 2019 challenge, achieving a 27.3\% reduction in ABX error rate over the top-performing submission, while keeping the bitrate approximately the same. We also present experiments demonstrating the noise robustness of these units. Finally, we show that a model with multiple quantizers can simultaneously learn phone-like detectors at a lower layer and word-like detectors at a higher layer. We show that these detectors are highly accurate, discovering 279 words with an F1 score of greater than 0.5.
On the Linguistic Representational Power of Neural Machine Translation Models
Nov 01, 2019
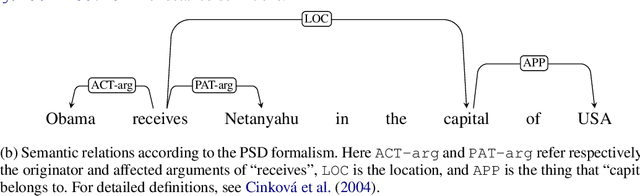

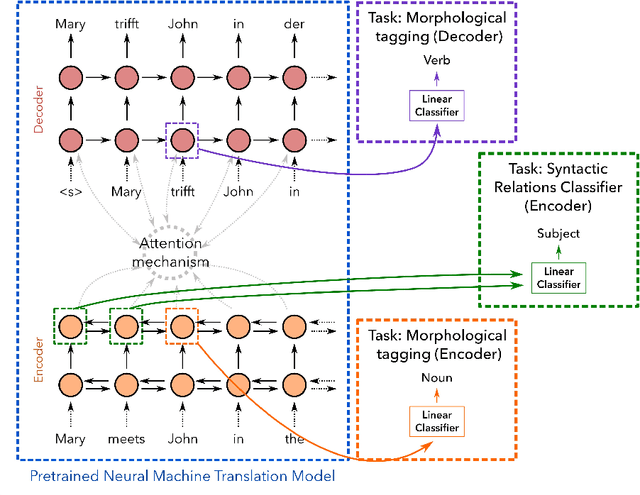
Despite the recent success of deep neural networks in natural language processing (NLP), their interpretability remains a challenge. We analyze the representations learned by neural machine translation models at various levels of granularity and evaluate their quality through relevant extrinsic properties. In particular, we seek answers to the following questions: (i) How accurately is word-structure captured within the learned representations, an important aspect in translating morphologically-rich languages? (ii) Do the representations capture long-range dependencies, and effectively handle syntactically divergent languages? (iii) Do the representations capture lexical semantics? We conduct a thorough investigation along several parameters: (i) Which layers in the architecture capture each of these linguistic phenomena; (ii) How does the choice of translation unit (word, character, or subword unit) impact the linguistic properties captured by the underlying representations? (iii) Do the encoder and decoder learn differently and independently? (iv) Do the representations learned by multilingual NMT models capture the same amount of linguistic information as their bilingual counterparts? Our data-driven, quantitative evaluation illuminates important aspects in NMT models and their ability to capture various linguistic phenomena. We show that deep NMT models learn a non-trivial amount of linguistic information. Notable findings include: i) Word morphology and part-of-speech information are captured at the lower layers of the model; (ii) In contrast, lexical semantics or non-local syntactic and semantic dependencies are better represented at the higher layers; (iii) Representations learned using characters are more informed about wordmorphology compared to those learned using subword units; and (iv) Representations learned by multilingual models are richer compared to bilingual models.
Mix-review: Alleviate Forgetting in the Pretrain-Finetune Framework for Neural Language Generation Models
Oct 29, 2019
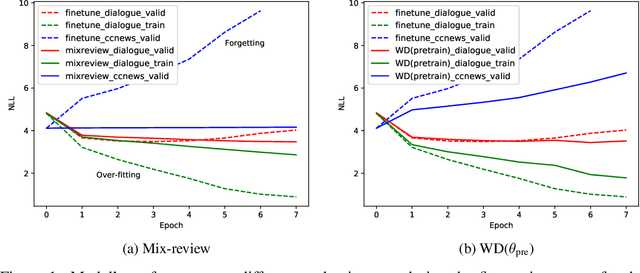
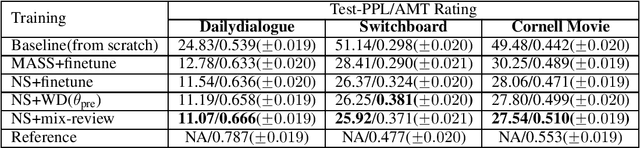
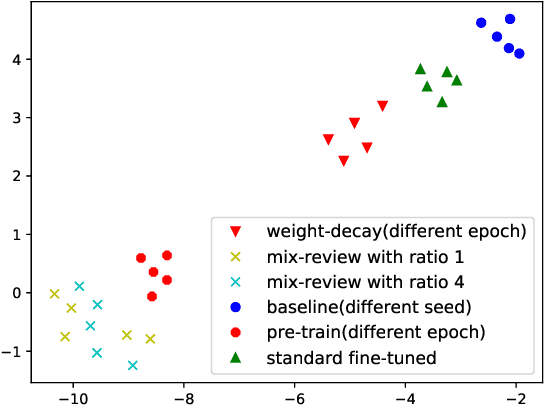
In this work, we study how the large-scale pretrain-finetune framework changes the behavior of a neural language generator. We focus on the transformer encoder-decoder model for the open-domain dialogue response generation task. We find that after standard fine-tuning, the model forgets important language generation skills acquired during large-scale pre-training. We demonstrate the forgetting phenomenon through a detailed behavior analysis from the perspectives of context sensitivity and knowledge transfer. Adopting the concept of data mixing, we propose an intuitive fine-tuning strategy named "mix-review". We find that mix-review effectively regularize the fine-tuning process, and the forgetting problem is largely alleviated. Finally, we discuss interesting behavior of the resulting dialogue model and its implications.
Generative Pre-Training for Speech with Autoregressive Predictive Coding
Oct 23, 2019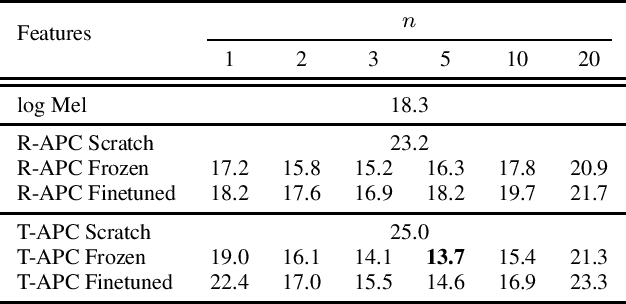
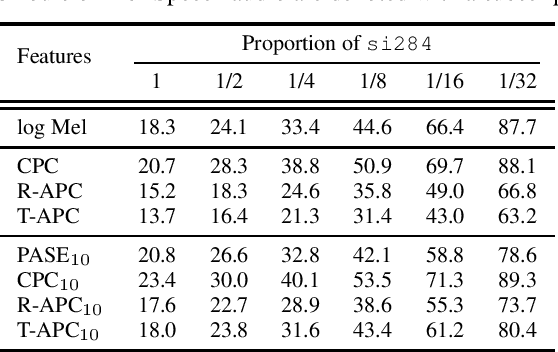
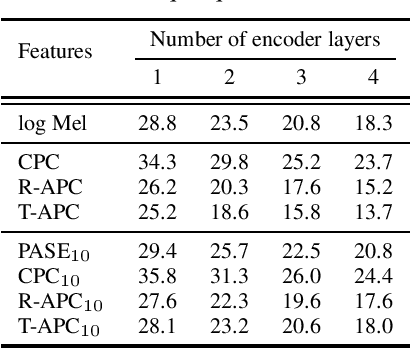
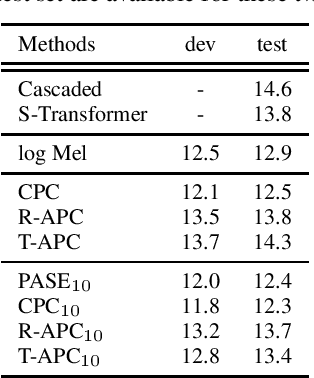
Learning meaningful and general representations from unannotated speech that are applicable to a wide range of tasks remains challenging. In this paper we propose to use autoregressive predictive coding (APC), a recently proposed self-supervised objective, as a generative pre-training approach for learning meaningful, non-specific, and transferable speech representations. We pre-train APC on large-scale unlabeled data and conduct transfer learning experiments on three speech applications that require different information about speech characteristics to perform well: speech recognition, speech translation, and speaker identification. Extensive experiments show that APC not only outperforms surface features (e.g., log Mel spectrograms) and other popular representation learning methods on all three tasks, but is also effective at reducing downstream labeled data size and model parameters. We also investigate the use of Transformers for modeling APC and find it superior to RNNs.
Tanbih: Get To Know What You Are Reading
Oct 04, 2019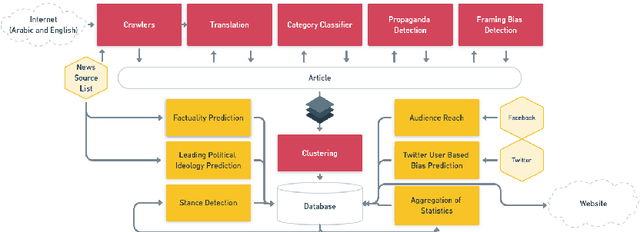
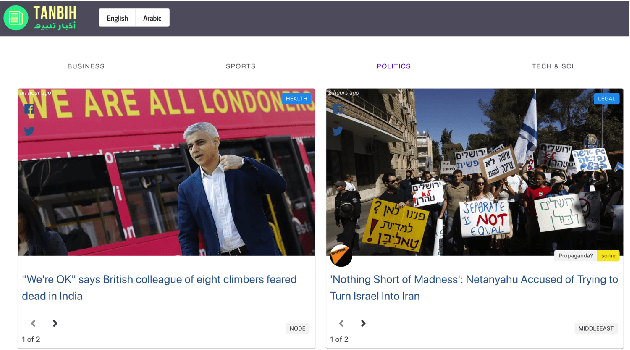
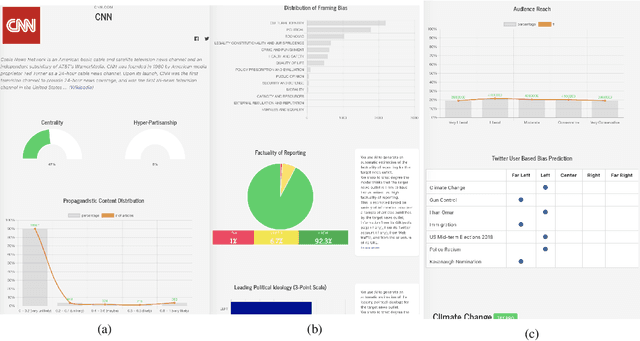
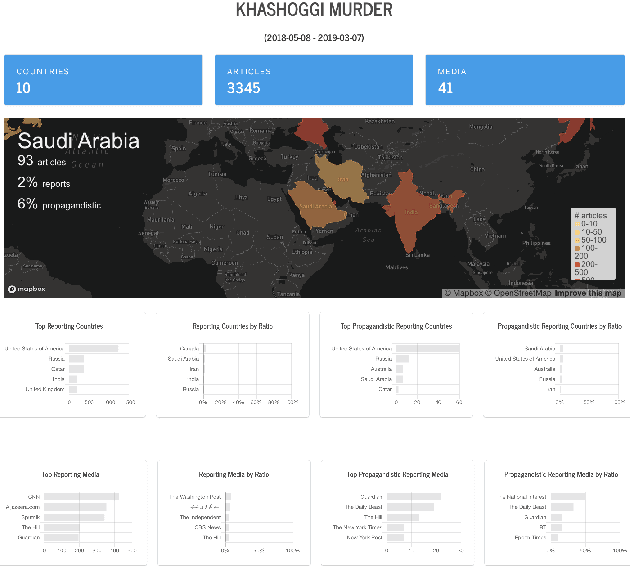
We introduce Tanbih, a news aggregator with intelligent analysis tools to help readers understanding what's behind a news story. Our system displays news grouped into events and generates media profiles that show the general factuality of reporting, the degree of propagandistic content, hyper-partisanship, leading political ideology, general frame of reporting, and stance with respect to various claims and topics of a news outlet. In addition, we automatically analyse each article to detect whether it is propagandistic and to determine its stance with respect to a number of controversial topics.