 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaehoon Lee
Dataset Meta-Learning from Kernel Ridge-Regression
Oct 30, 2020

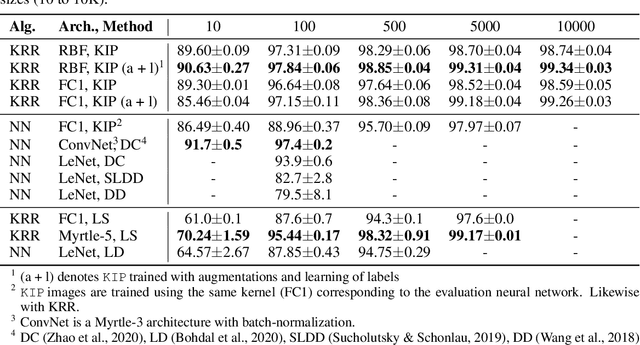
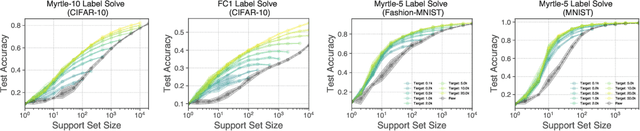
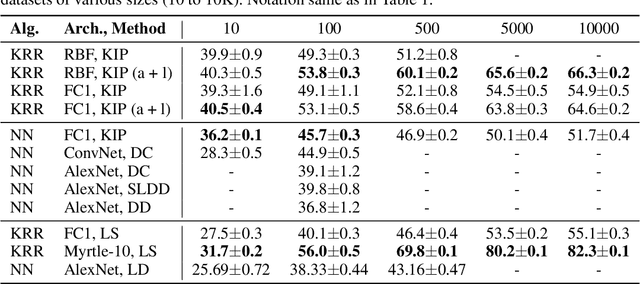
One of the most fundamental aspects of any machine learning algorithm is the training data used by the algorithm. We introduce the novel concept of $\epsilon$-approximation of datasets, obtaining datasets which are much smaller than or are significant corruptions of the original training data while maintaining similar model performance. We introduce a meta-learning algorithm called Kernel Inducing Points (KIP) for obtaining such remarkable datasets, inspired by the recent developments in the correspondence between infinitely-wide neural networks and kernel ridge-regression (KRR). For KRR tasks, we demonstrate that KIP can compress datasets by one or two orders of magnitude, significantly improving previous dataset distillation and subset selection methods while obtaining state of the art results for MNIST and CIFAR-10 classification. Furthermore, our KIP-learned datasets are transferable to the training of finite-width neural networks even beyond the lazy-training regime, which leads to state of the art results for neural network dataset distillation with potential applications to privacy-preservation.
Exploring the Uncertainty Properties of Neural Networks' Implicit Priors in the Infinite-Width Limit
Oct 14, 2020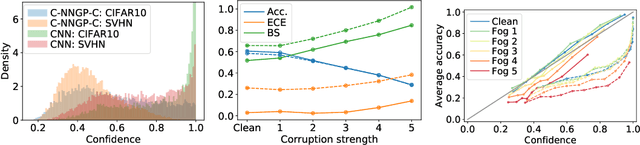
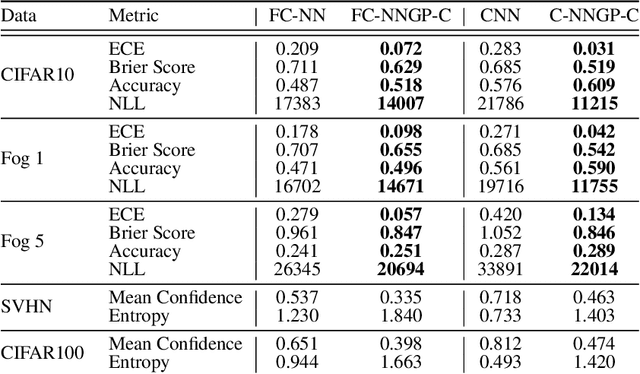

Modern deep learning models have achieved great success in predictive accuracy for many data modalities. However, their application to many real-world tasks is restricted by poor uncertainty estimates, such as overconfidence on out-of-distribution (OOD) data and ungraceful failing under distributional shift. Previous benchmarks have found that ensembles of neural networks (NNs) are typically the best calibrated models on OOD data. Inspired by this, we leverage recent theoretical advances that characterize the function-space prior of an ensemble of infinitely-wide NNs as a Gaussian process, termed the neural network Gaussian process (NNGP). We use the NNGP with a softmax link function to build a probabilistic model for multi-class classification and marginalize over the latent Gaussian outputs to sample from the posterior. This gives us a better understanding of the implicit prior NNs place on function space and allows a direct comparison of the calibration of the NNGP and its finite-width analogue. We also examine the calibration of previous approaches to classification with the NNGP, which treat classification problems as regression to the one-hot labels. In this case the Bayesian posterior is exact, and we compare several heuristics to generate a categorical distribution over classes. We find these methods are well calibrated under distributional shift. Finally, we consider an infinite-width final layer in conjunction with a pre-trained embedding. This replicates the important practical use case of transfer learning and allows scaling to significantly larger datasets. As well as achieving competitive predictive accuracy, this approach is better calibrated than its finite width analogue.
Finite Versus Infinite Neural Networks: an Empirical Study
Sep 08, 2020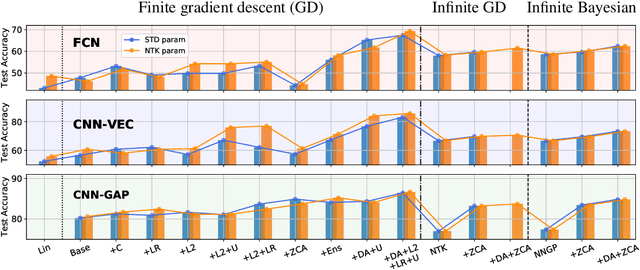



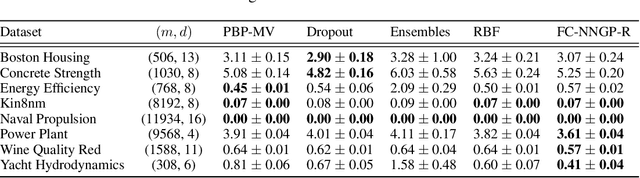
We perform a careful, thorough, and large scale empirical study of the correspondence between wide neural networks and kernel methods. By doing so, we resolve a variety of open questions related to the study of infinitely wide neural networks. Our experimental results include: kernel methods outperform fully-connected finite-width networks, but underperform convolutional finite width networks; neural network Gaussian process (NNGP) kernels frequently outperform neural tangent (NT) kernels; centered and ensembled finite networks have reduced posterior variance and behave more similarly to infinite networks; weight decay and the use of a large learning rate break the correspondence between finite and infinite networks; the NTK parameterization outperforms the standard parameterization for finite width networks; diagonal regularization of kernels acts similarly to early stopping; floating point precision limits kernel performance beyond a critical dataset size; regularized ZCA whitening improves accuracy; finite network performance depends non-monotonically on width in ways not captured by double descent phenomena; equivariance of CNNs is only beneficial for narrow networks far from the kernel regime. Our experiments additionally motivate an improved layer-wise scaling for weight decay which improves generalization in finite-width networks. Finally, we develop improved best practices for using NNGP and NT kernels for prediction, including a novel ensembling technique. Using these best practices we achieve state-of-the-art results on CIFAR-10 classification for kernels corresponding to each architecture class we consider.
Data-Efficient Deep Learning Method for Image Classification Using Data Augmentation, Focal Cosine Loss, and Ensemble
Jul 15, 2020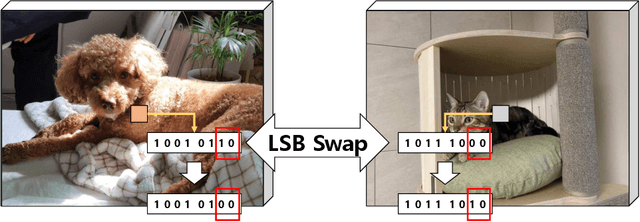

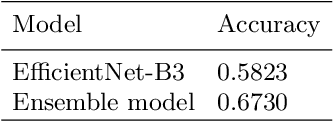
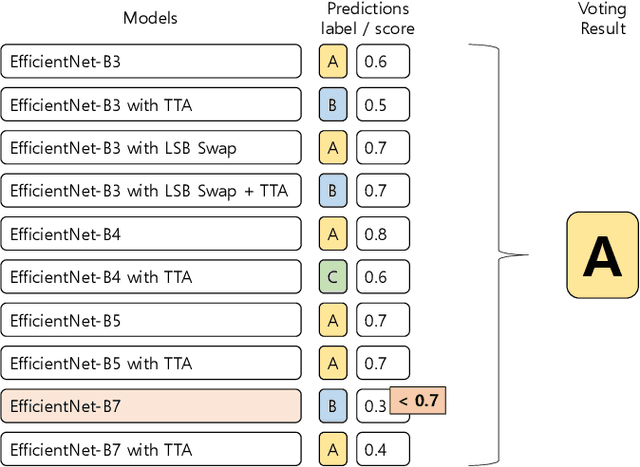
In general, sufficient data is essential for the better performance and generalization of deep-learning models. However, lots of limitations(cost, resources, etc.) of data collection leads to lack of enough data in most of the areas. In addition, various domains of each data sources and licenses also lead to difficulties in collection of sufficient data. This situation makes us hard to utilize not only the pre-trained model, but also the external knowledge. Therefore, it is important to leverage small dataset effectively for achieving the better performance. We applied some techniques in three aspects: data, loss function, and prediction to enable training from scratch with less data. With these methods, we obtain high accuracy by leveraging ImageNet data which consist of only 50 images per class. Furthermore, our model is ranked 4th in Visual Inductive Printers for Data-Effective Computer Vision Challenge.
NTIRE 2020 Challenge on Video Quality Mapping: Methods and Results
May 06, 2020

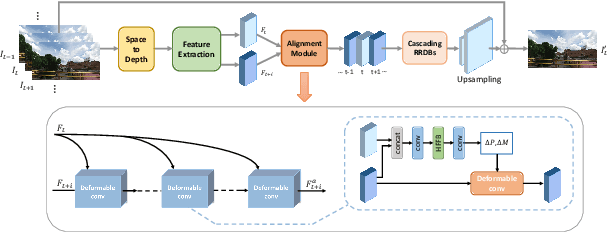
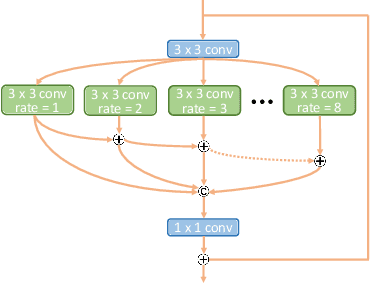
This paper reviews the NTIRE 2020 challenge on video quality mapping (VQM), which addresses the issues of quality mapping from source video domain to target video domain. The challenge includes both a supervised track (track 1) and a weakly-supervised track (track 2) for two benchmark datasets. In particular, track 1 offers a new Internet video benchmark, requiring algorithms to learn the map from more compressed videos to less compressed videos in a supervised training manner. In track 2, algorithms are required to learn the quality mapping from one device to another when their quality varies substantially and weakly-aligned video pairs are available. For track 1, in total 7 teams competed in the final test phase, demonstrating novel and effective solutions to the problem. For track 2, some existing methods are evaluated, showing promising solutions to the weakly-supervised video quality mapping problem.
On the infinite width limit of neural networks with a standard parameterization
Jan 25, 2020
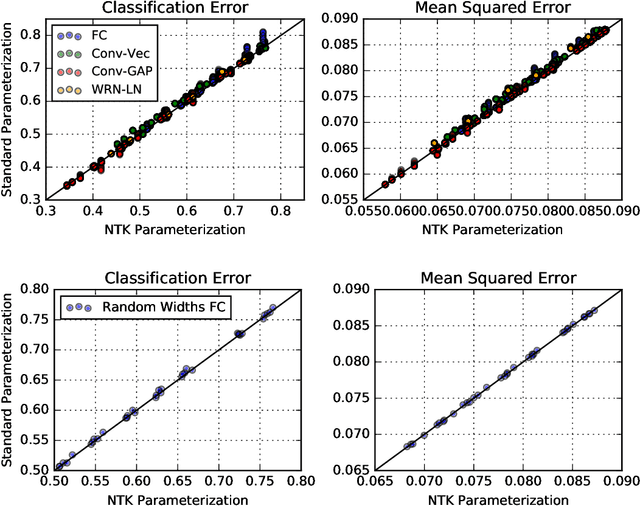
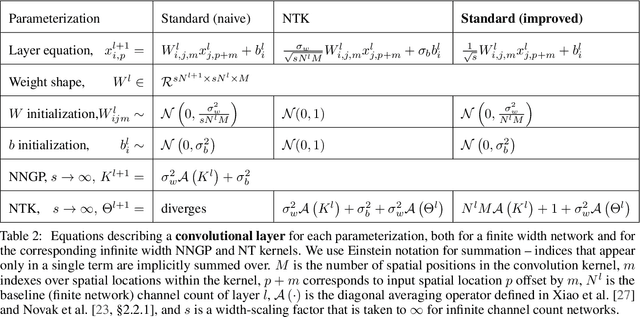
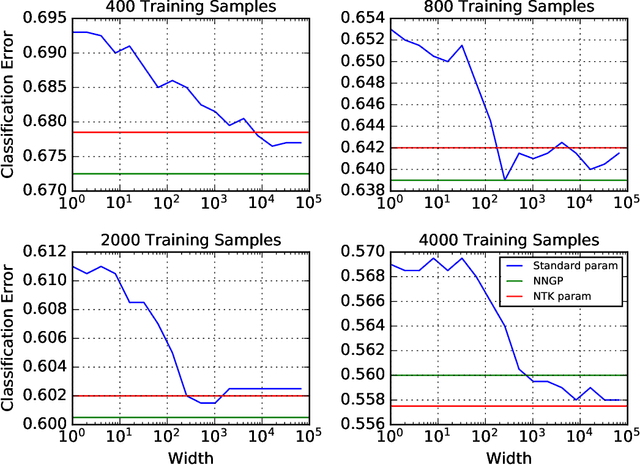
There are currently two parameterizations used to derive fixed kernels corresponding to infinite width neural networks, the NTK (Neural Tangent Kernel) parameterization and the naive standard parameterization. However, the extrapolation of both of these parameterizations to infinite width is problematic. The standard parameterization leads to a divergent neural tangent kernel while the NTK parameterization fails to capture crucial aspects of finite width networks such as: the dependence of training dynamics on relative layer widths, the relative training dynamics of weights and biases, and a nonstandard learning rate scale. Here we propose an improved extrapolation of the standard parameterization that preserves all of these properties as width is taken to infinity and yields a well-defined neural tangent kernel. We show experimentally that the resulting kernels typically achieve similar accuracy to those resulting from an NTK parameterization, but with better correspondence to the parameterization of typical finite width networks. Additionally, with careful tuning of width parameters, the improved standard parameterization kernels can outperform those stemming from an NTK parameterization. We release code implementing this improved standard parameterization as part of the Neural Tangents library at https://github.com/google/neural-tangents.
Neural Tangents: Fast and Easy Infinite Neural Networks in Python
Dec 05, 2019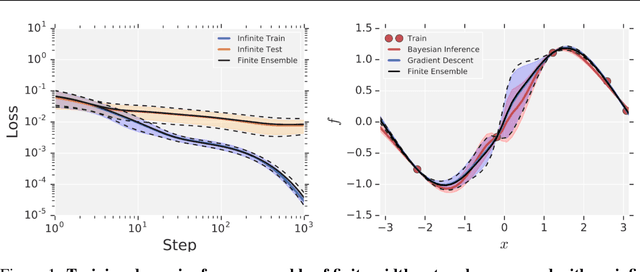
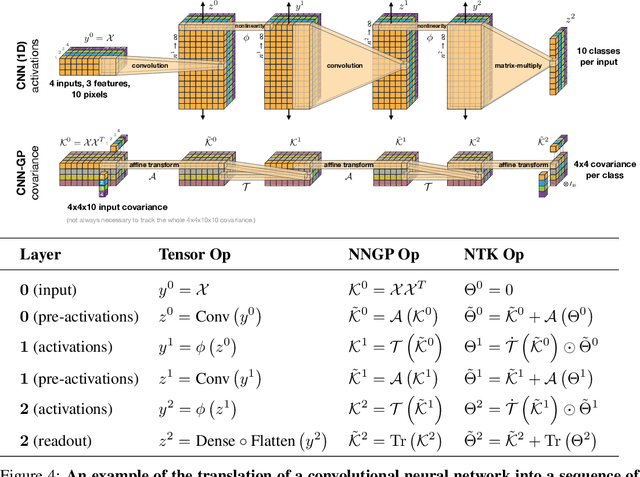
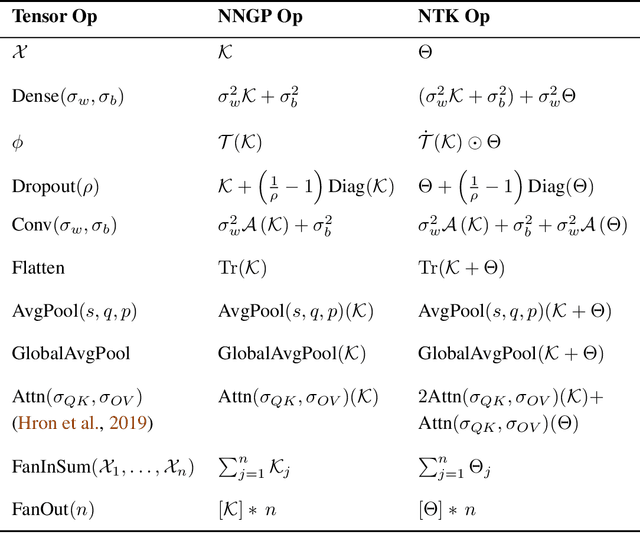
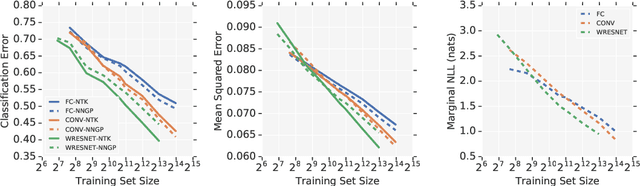
Neural Tangents is a library designed to enable research into infinite-width neural networks. It provides a high-level API for specifying complex and hierarchical neural network architectures. These networks can then be trained and evaluated either at finite-width as usual or in their infinite-width limit. Infinite-width networks can be trained analytically using exact Bayesian inference or using gradient descent via the Neural Tangent Kernel. Additionally, Neural Tangents provides tools to study gradient descent training dynamics of wide but finite networks in either function space or weight space. The entire library runs out-of-the-box on CPU, GPU, or TPU. All computations can be automatically distributed over multiple accelerators with near-linear scaling in the number of devices. Neural Tangents is available at www.github.com/google/neural-tangents. We also provide an accompanying interactive Colab notebook.
On Empirical Comparisons of Optimizers for Deep Learning
Oct 11, 2019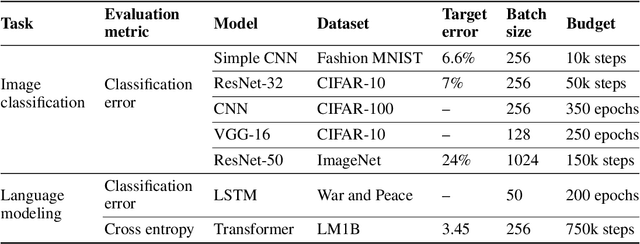
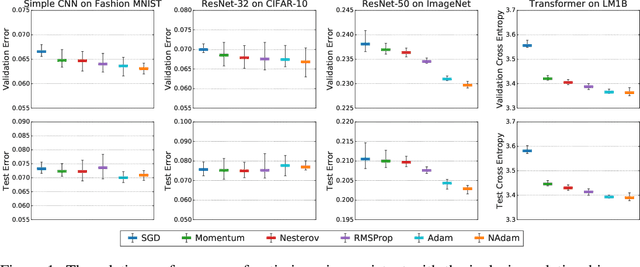
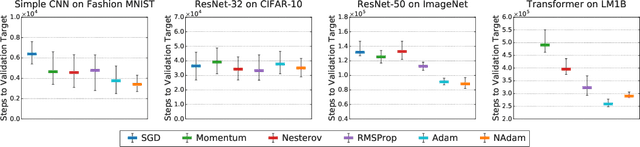

Selecting an optimizer is a central step in the contemporary deep learning pipeline. In this paper, we demonstrate the sensitivity of optimizer comparisons to the metaparameter tuning protocol. Our findings suggest that the metaparameter search space may be the single most important factor explaining the rankings obtained by recent empirical comparisons in the literature. In fact, we show that these results can be contradicted when metaparameter search spaces are changed. As tuning effort grows without bound, more general optimizers should never underperform the ones they can approximate (i.e., Adam should never perform worse than momentum), but recent attempts to compare optimizers either assume these inclusion relationships are not practically relevant or restrict the metaparameters in ways that break the inclusions. In our experiments, we find that inclusion relationships between optimizers matter in practice and always predict optimizer comparisons. In particular, we find that the popular adaptive gradient methods never underperform momentum or gradient descent. We also report practical tips around tuning often ignored metaparameters of adaptive gradient methods and raise concerns about fairly benchmarking optimizers for neural network training.