 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Prediction of Medieval Arabic Diacritics
Oct 11, 2020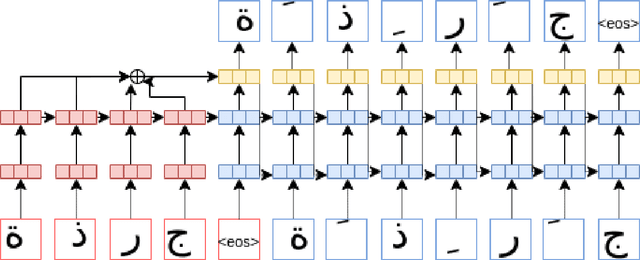

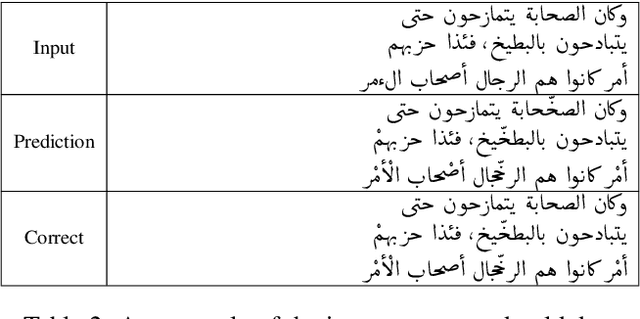
This study uses a character level neural machine translation approach trained on a long short-term memory-based bi-directional recurrent neural network architecture for diacritization of Medieval Arabic. The results improve from the online tool used as a baseline. A diacritization model have been published openly through an easy to use Python package available on PyPi and Zenodo. We have found that context size should be considered when optimizing a feasible prediction model.
Automatic Dialect Adaptation in Finnish and its Effect on Perceived Creativity
Sep 06, 2020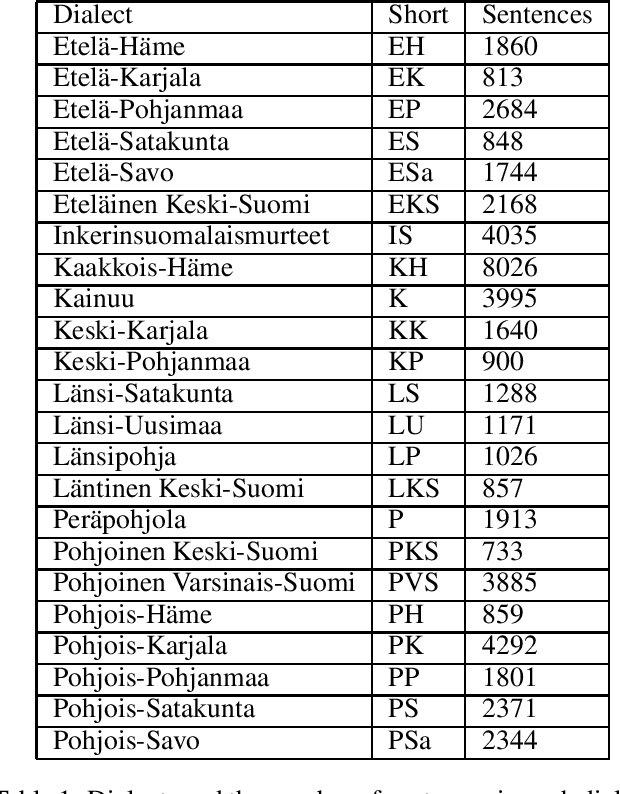

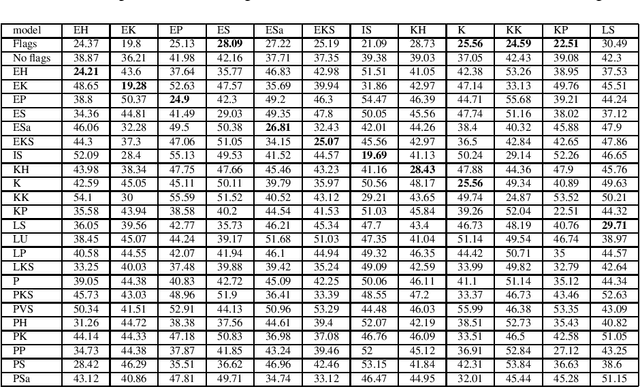
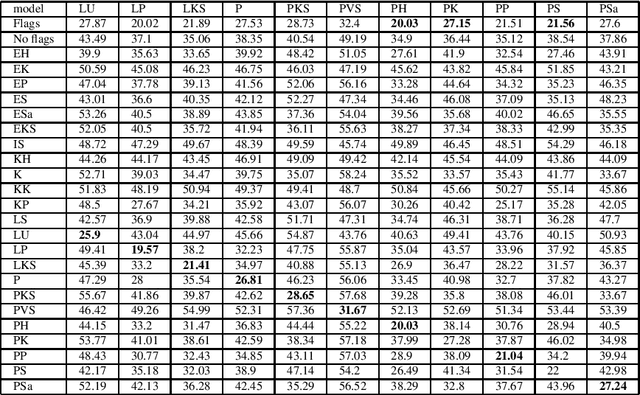
We present a novel approach for adapting text written in standard Finnish to different dialects. We experiment with character level NMT models both by using a multi-dialectal and transfer learning approaches. The models are tested with over 20 different dialects. The results seem to favor transfer learning, although not strongly over the multi-dialectal approach. We study the influence dialectal adaptation has on perceived creativity of computer generated poetry. Our results suggest that the more the dialect deviates from the standard Finnish, the lower scores people tend to give on an existing evaluation metric. However, on a word association test, people associate creativity and originality more with dialect and fluency more with standard Finnish.
FST Morphology for the Endangered Skolt Sami Language
Apr 09, 2020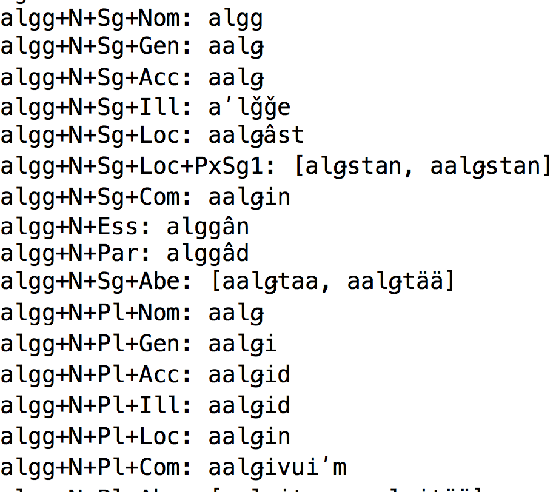

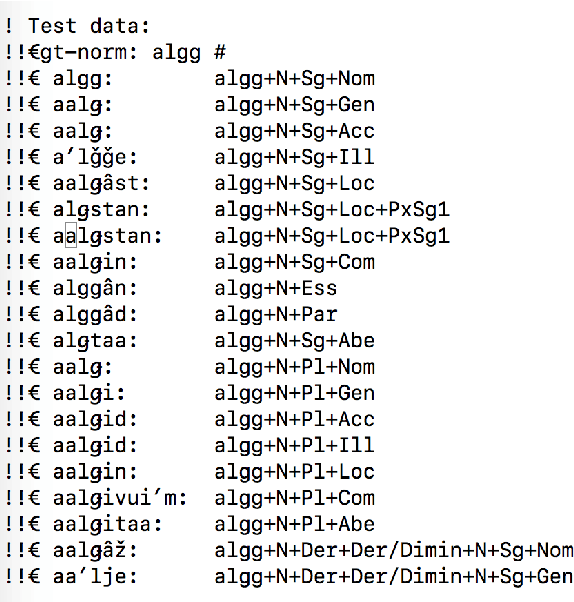
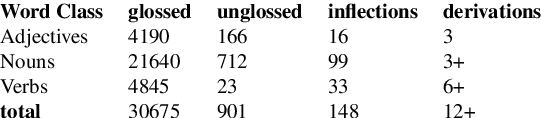
We present advances in the development of a FST-based morphological analyzer and generator for Skolt Sami. Like other minority Uralic languages, Skolt Sami exhibits a rich morphology, on the one hand, and there is little golden standard material for it, on the other. This makes NLP approaches for its study difficult without a solid morphological analysis. The language is severely endangered and the work presented in this paper forms a part of a greater whole in its revitalization efforts. Furthermore, we intersperse our description with facilitation and description practices not well documented in the infrastructure. Currently, the analyzer covers over 30,000 Skolt Sami words in 148 inflectional paradigms and over 12 derivational forms.