 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient K-means Clustering Algorithm for Analysing COVID-19
Dec 21, 2020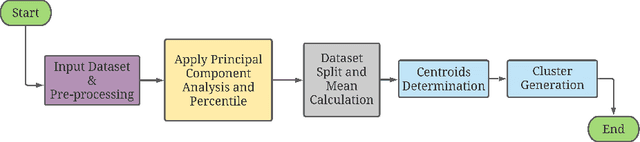
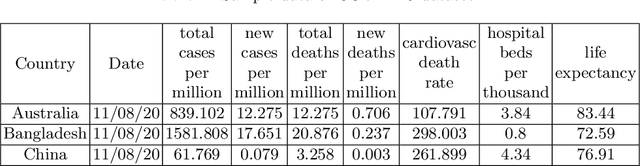
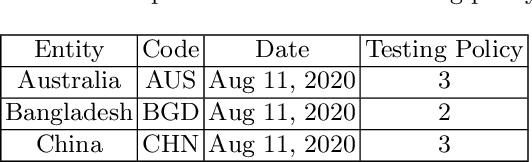
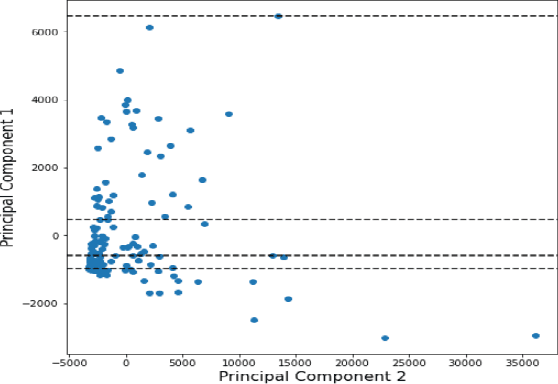
COVID-19 hits the world like a storm by arising pandemic situations for most of the countries around the world. The whole world is trying to overcome this pandemic situation. A better health care quality may help a country to tackle the pandemic. Making clusters of countries with similar types of health care quality provides an insight into the quality of health care in different countries. In the area of machine learning and data science, the K-means clustering algorithm is typically used to create clusters based on similarity. In this paper, we propose an efficient K-means clustering method that determines the initial centroids of the clusters efficiently. Based on this proposed method, we have determined health care quality clusters of countries utilizing the COVID-19 datasets. Experimental results show that our proposed method reduces the number of iterations and execution time to analyze COVID-19 while comparing with the traditional k-means clustering algorithm.
Predicting Individual Substance Abuse Vulnerability using Machine Learning Techniques
Dec 09, 2020Substance abuse is the unrestrained and detrimental use of psychoactive chemical substances, unauthorized drugs, and alcohol. Continuous use of these substances can ultimately lead a human to disastrous consequences. As patients display a high rate of relapse, prevention at an early stage can be an effective restraint. We therefore propose a binary classifier to identify any individual's present vulnerability towards substance abuse by analyzing subjects' socio-economic environment. We have collected data by a questionnaire which is created after carefully assessing the commonly involved factors behind substance abuse. Pearson's chi-squared test of independence is used to identify key feature variables influencing substance abuse. Later we build the predictive classifiers using machine learning classification algorithms on those variables. Logistic regression classifier trained with 18 features can predict individual vulnerability with the best accuracy.
An Isolation Forest Learning Based Outlier Detection Approach for Effectively Classifying Cyber Anomalies
Dec 09, 2020Cybersecurity has recently gained considerable interest in today's security issues because of the popularity of the Internet-of-Things (IoT), the considerable growth of mobile networks, and many related apps. Therefore, detecting numerous cyber-attacks in a network and creating an effective intrusion detection system plays a vital role in today's security. In this paper, we present an Isolation Forest Learning-Based Outlier Detection Model for effectively classifying cyber anomalies. In order to evaluate the efficacy of the resulting Outlier Detection model, we also use several conventional machine learning approaches, such as Logistic Regression (LR), Support Vector Machine (SVM), AdaBoost Classifier (ABC), Naive Bayes (NB), and K-Nearest Neighbor (KNN). The effectiveness of our proposed Outlier Detection model is evaluated by conducting experiments on Network Intrusion Dataset with evaluation metrics such as precision, recall, F1-score, and accuracy. Experimental results show that the classification accuracy of cyber anomalies has been improved after removing outliers.
SentiLSTM: A Deep Learning Approach for Sentiment Analysis of Restaurant Reviews
Nov 19, 2020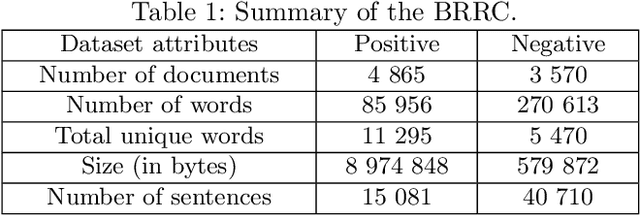
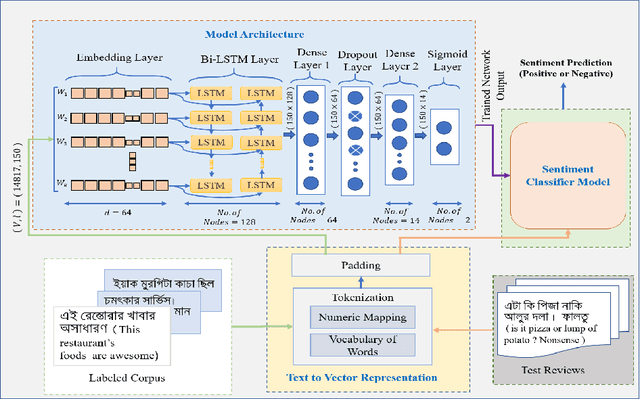
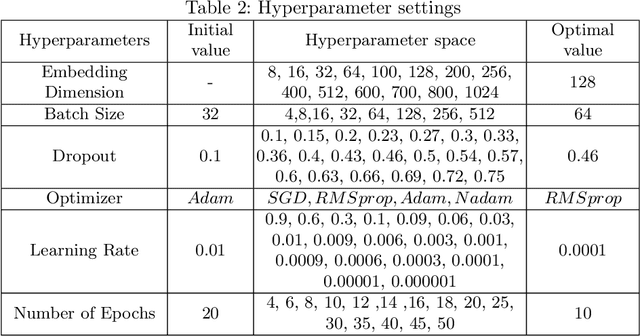
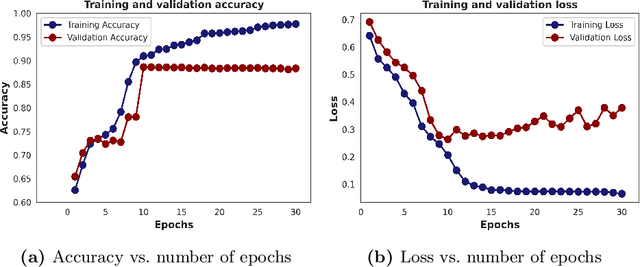
The amount of textual data generation has increased enormously due to the effortless access of the Internet and the evolution of various web 2.0 applications. These textual data productions resulted because of the people express their opinion, emotion or sentiment about any product or service in the form of tweets, Facebook post or status, blog write up, and reviews. Sentiment analysis deals with the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer's attitude toward a particular topic is positive, negative, or neutral. The impact of customer review is significant to perceive the customer attitude towards a restaurant. Thus, the automatic detection of sentiment from reviews is advantageous for the restaurant owners, or service providers and customers to make their decisions or services more satisfactory. This paper proposes, a deep learning-based technique (i.e., BiLSTM) to classify the reviews provided by the clients of the restaurant into positive and negative polarities. A corpus consists of 8435 reviews is constructed to evaluate the proposed technique. In addition, a comparative analysis of the proposed technique with other machine learning algorithms presented. The results of the evaluation on test dataset show that BiLSTM technique produced in the highest accuracy of 91.35%.
A Survey on the Use of AI and ML for Fighting the COVID-19 Pandemic
Aug 03, 2020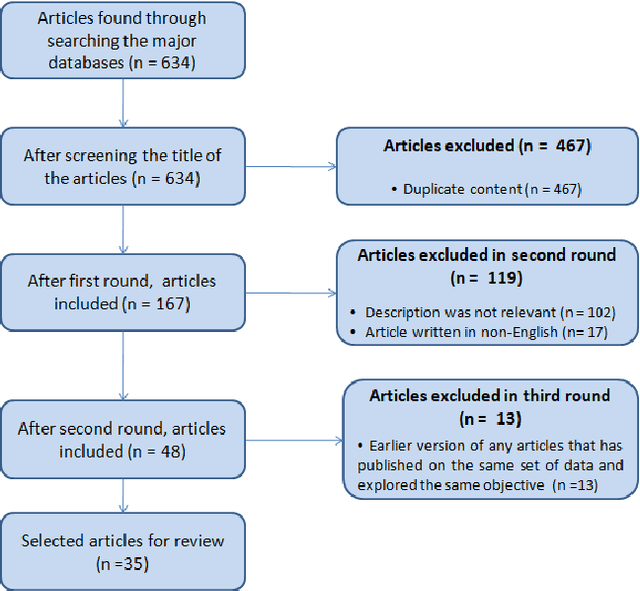
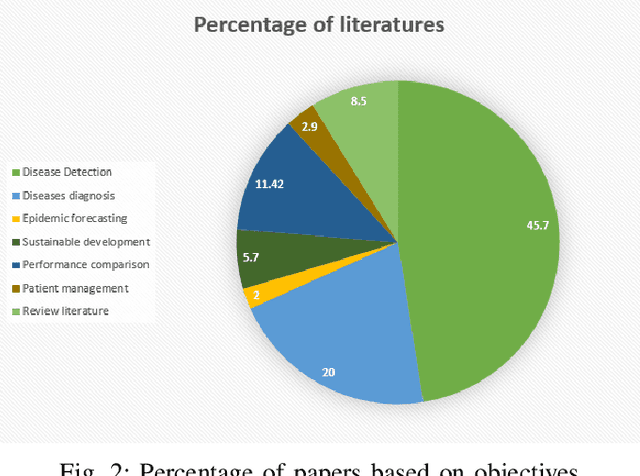
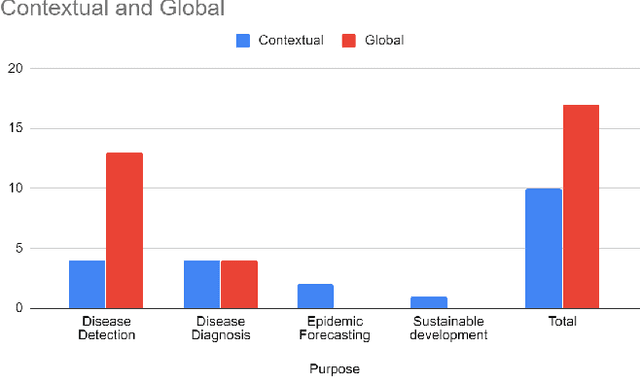
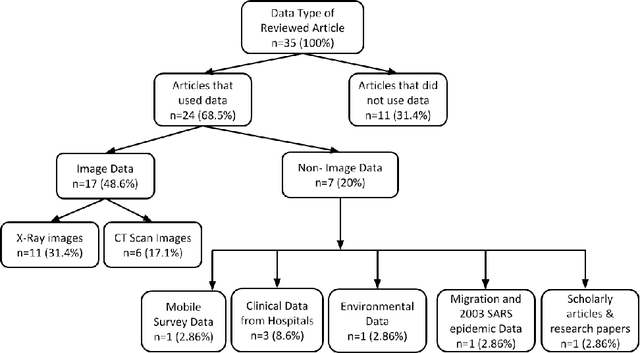
Artificial intelligence (AI) and machine learning (ML) have made a paradigm shift in health care which, eventually can be used for decision support and forecasting by exploring the medical data. Recent studies showed that AI and ML can be used to fight against the COVID-19 pandemic. Therefore, the objective of this review study is to summarize the recent AI and ML based studies that have focused to fight against COVID-19 pandemic. From an initial set of 634 articles, a total of 35 articles were finally selected through an extensive inclusion-exclusion process. In our review, we have explored the objectives/aims of the existing studies (i.e., the role of AI/ML in fighting COVID-19 pandemic); context of the study (i.e., study focused to a specific country-context or with a global perspective); type and volume of dataset; methodology, algorithms or techniques adopted in the prediction or diagnosis processes; and mapping the algorithms/techniques with the data type highlighting their prediction/classification accuracy. We particularly focused on the uses of AI/ML in analyzing the pandemic data in order to depict the most recent progress of AI for fighting against COVID-19 and pointed out the potential scope of further research.
Crime Prediction Using Spatio-Temporal Data
Mar 11, 2020
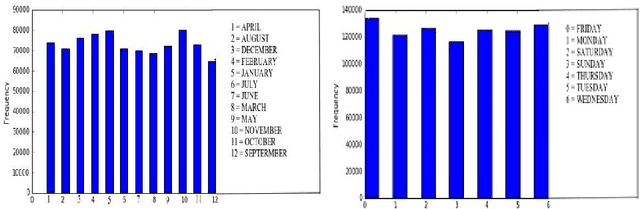
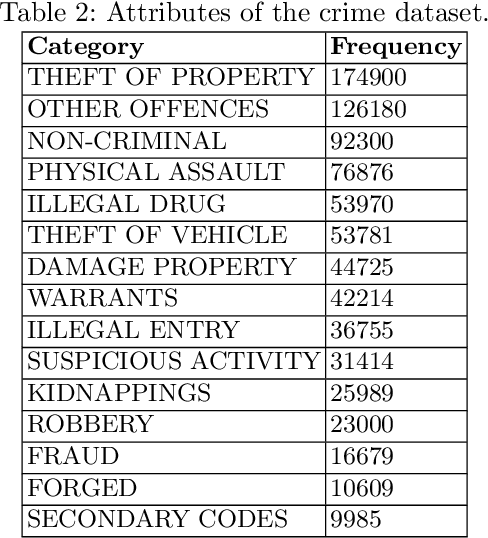
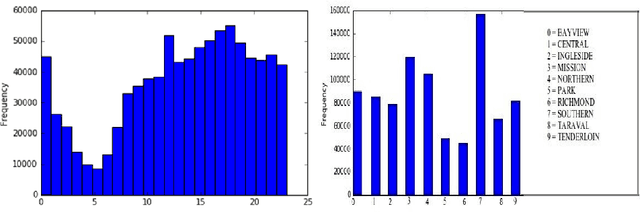
A crime is a punishable offence that is harmful for an individual and his society. It is obvious to comprehend the patterns of criminal activity to prevent them. Research can help society to prevent and solve crime activates. Study shows that only 10 percent offenders commits 50 percent of the total offences. The enforcement team can respond faster if they have early information and pre-knowledge about crime activities of the different points of a city. In this paper, supervised learning technique is used to predict crimes with better accuracy. The proposed system predicts crimes by analyzing data-set that contains records of previously committed crimes and their patterns. The system stands on two main algorithms - i) decision tree, and ii) k-nearest neighbor. Random Forest algorithm and Adaboost are used to increase the accuracy of the prediction. Finally, oversampling is used for better accuracy. The proposed system is feed with a criminal-activity data set of twelve years of San Francisco city.
BehavDT: A Behavioral Decision Tree Learning to Build User-Centric Context-Aware Predictive Model
Dec 17, 2019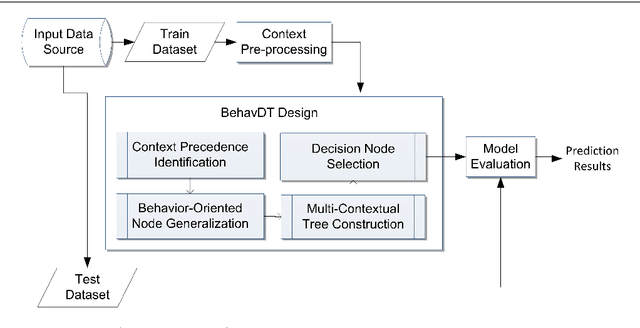
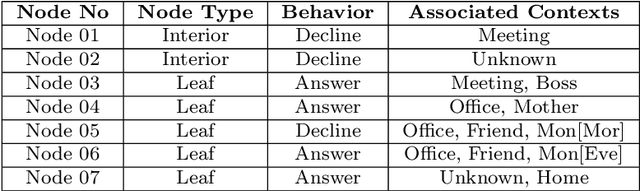
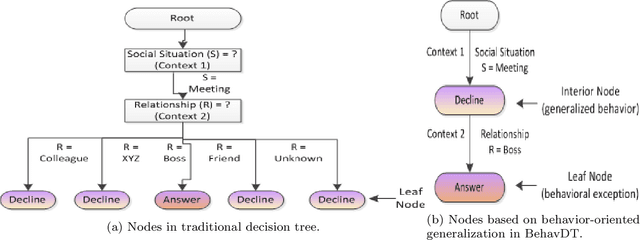
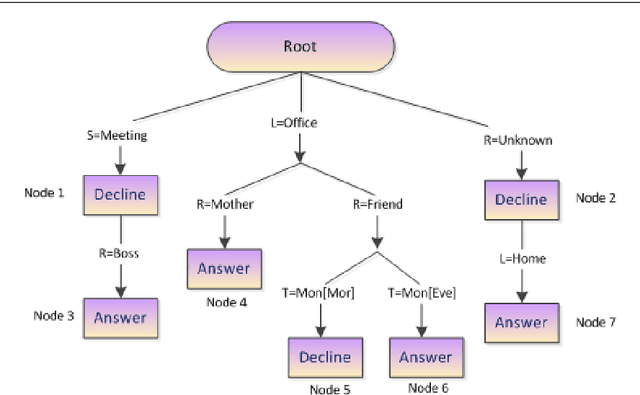
This paper formulates the problem of building a context-aware predictive model based on user diverse behavioral activities with smartphones. In the area of machine learning and data science, a tree-like model as that of decision tree is considered as one of the most popular classification techniques, which can be used to build a data-driven predictive model. The traditional decision tree model typically creates a number of leaf nodes as decision nodes that represent context-specific rigid decisions, and consequently may cause overfitting problem in behavior modeling. However, in many practical scenarios within the context-aware environment, the generalized outcomes could play an important role to effectively capture user behavior. In this paper, we propose a behavioral decision tree, "BehavDT" context-aware model that takes into account user behavior-oriented generalization according to individual preference level. The BehavDT model outputs not only the generalized decisions but also the context-specific decisions in relevant exceptional cases. The effectiveness of our BehavDT model is studied by conducting experiments on individual user real smartphone datasets. Our experimental results show that the proposed BehavDT context-aware model is more effective when compared with the traditional machine learning approaches, in predicting user diverse behaviors considering multi-dimensional contexts.
CalBehav: A Machine Learning based Personalized Calendar Behavioral Model using Time-Series Smartphone Data
Sep 02, 2019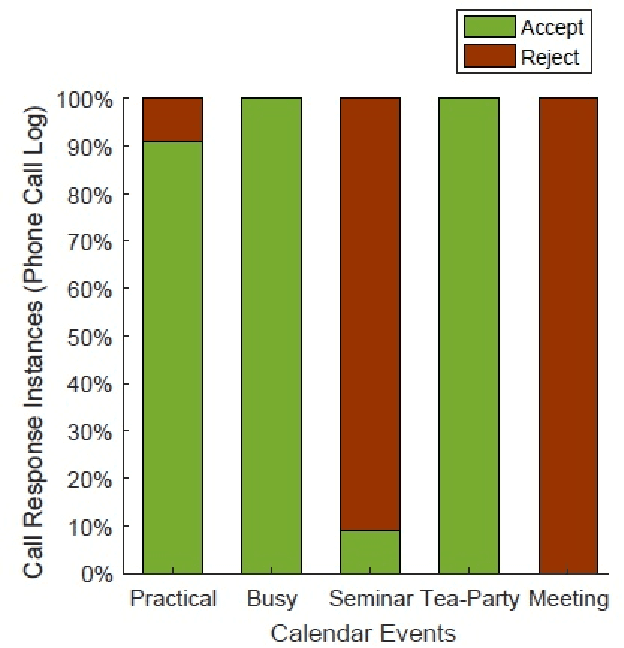
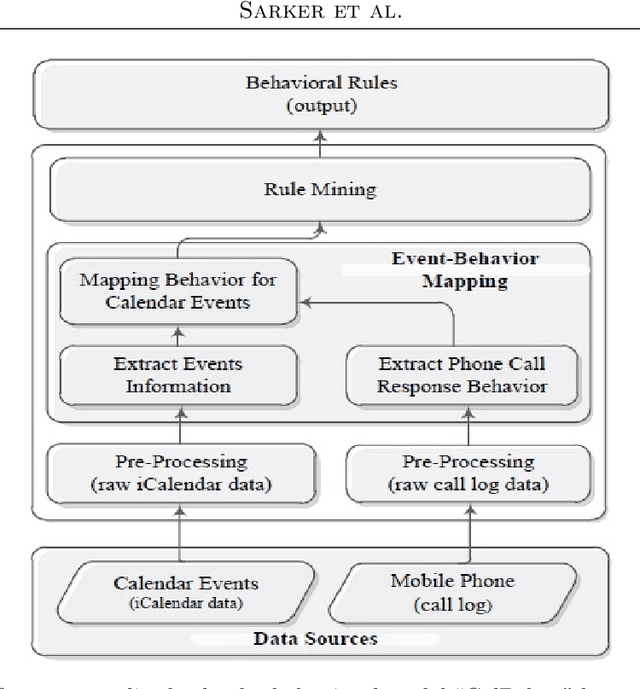
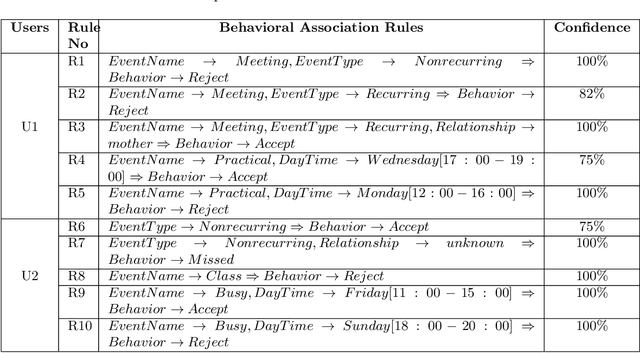
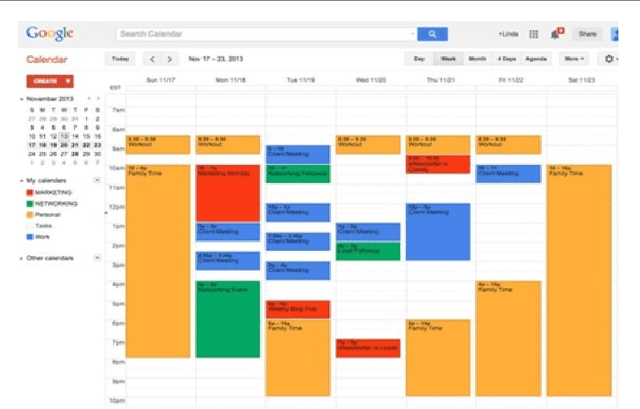
The electronic calendar is a valuable resource nowadays for managing our daily life appointments or schedules, also known as events, ranging from professional to highly personal. Researchers have studied various types of calendar events to predict smartphone user behavior for incoming mobile communications. However, these studies typically do not take into account behavioral variations between individuals. In the real world, smartphone users can differ widely from each other in how they respond to incoming communications during their scheduled events. Moreover, an individual user may respond the incoming communications differently in different contexts subject to what type of event is scheduled in her personal calendar. Thus, a static calendar-based behavioral model for individual smartphone users does not necessarily reflect their behavior to the incoming communications. In this paper, we present a machine learning based context-aware model that is personalized and dynamically identifies individual's dominant behavior for their scheduled events using logged time-series smartphone data, and shortly name as ``CalBehav''. The experimental results based on real datasets from calendar and phone logs, show that this data-driven personalized model is more effective for intelligently managing the incoming mobile communications compared to existing calendar-based approaches.
* 16 pages, double column
AppsPred: Predicting Context-Aware Smartphone Apps using Random Forest Learning
Aug 26, 2019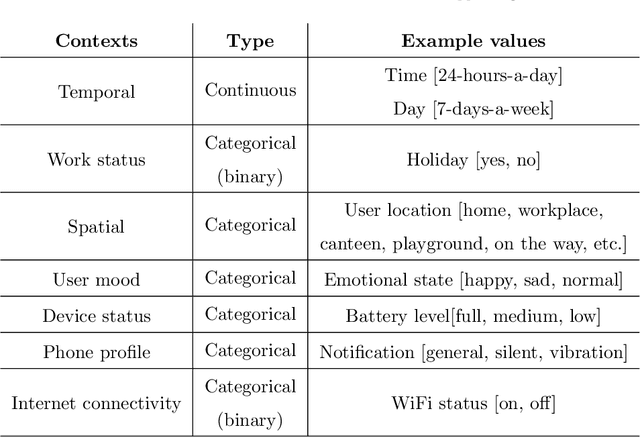
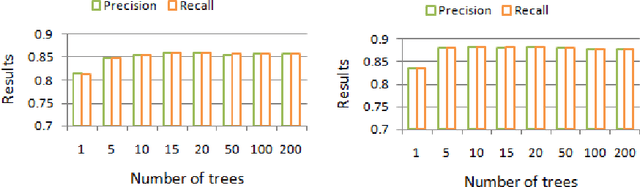
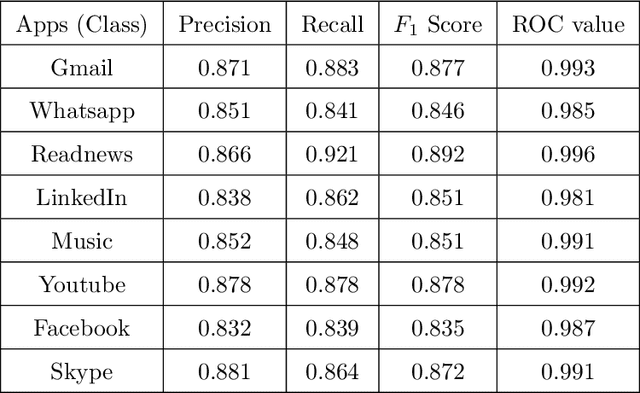
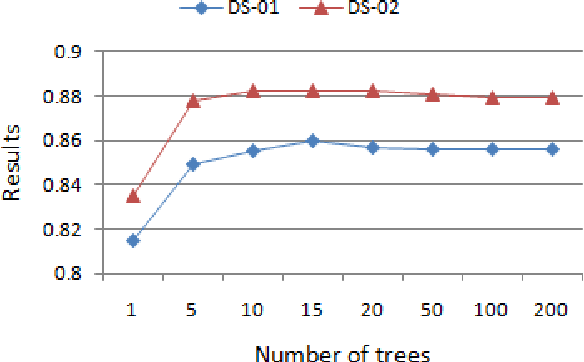
Due to the popularity of context-awareness in the Internet of Things (IoT) and the recent advanced features in the most popular IoT device, i.e., smartphone, modeling and predicting personalized usage behavior based on relevant contexts can be highly useful in assisting them to carry out daily routines and activities. Usage patterns of different categories smartphone apps such as social networking, communication, entertainment, or daily life services related apps usually vary greatly between individuals. People use these apps differently in different contexts, such as temporal context, spatial context, individual mood and preference, work status, Internet connectivity like Wifi? status, or device related status like phone profile, battery level etc. Thus, we consider individuals' apps usage as a multi-class context-aware problem for personalized modeling and prediction. Random Forest learning is one of the most popular machine learning techniques to build a multi-class prediction model. Therefore, in this paper, we present an effective context-aware smartphone apps prediction model, and name it "AppsPred" using random forest machine learning technique that takes into account optimal number of trees based on such multi-dimensional contexts to build the resultant forest. The effectiveness of this model is examined by conducting experiments on smartphone apps usage datasets collected from individual users. The experimental results show that our AppsPred significantly outperforms other popular machine learning classification approaches like ZeroR, Naive Bayes, Decision Tree, Support Vector Machines, Logistic Regression while predicting smartphone apps in various context-aware test cases.
* 28 pages
E-MIIM: An Ensemble Learning based Context-Aware Mobile Telephony Model for Intelligent Interruption Management
Aug 25, 2019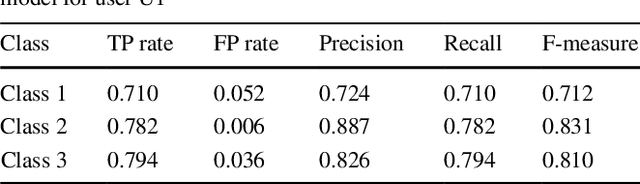
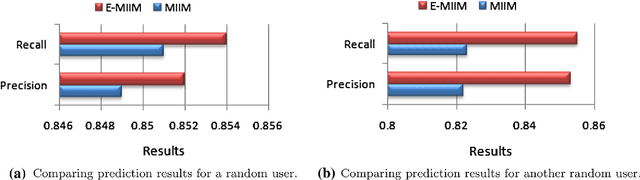
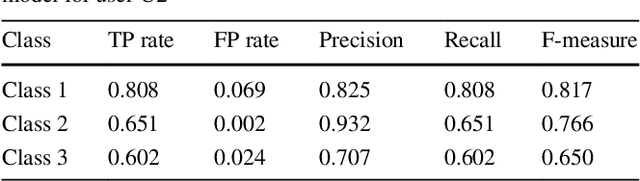
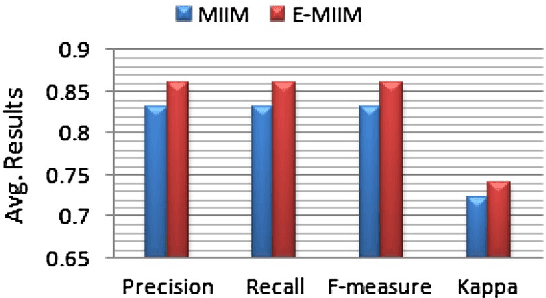
Nowadays, mobile telephony interruptions in our daily life activities are common because of the inappropriate ringing notifications of incoming phone calls in different contexts. Such interruptions may impact on the work attention not only for the mobile phone owners but also the surrounding people. Decision tree is the most popular machine learning classification technique that is used in existing context-aware mobile intelligent interruption management (MIIM) model to overcome such issues. However, a single decision tree based context-aware model may cause overfitting problem and thus decrease the prediction accuracy of the inferred model. Therefore, in this paper, we propose an ensemble machine learning based context-aware mobile telephony model for the purpose of intelligent interruption management by taking into account multi-dimensional contexts and name it "E-MIIM". The experimental results on individuals' real life mobile telephony datasets show that our E-MIIM model is more effective and outperforms existing MIIM model for predicting and managing individual's mobile telephony interruptions based on their relevant contextual information.
* 10 pages