 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive SVM+: Learning with Privileged Information for Domain Adaptation
Aug 30, 2017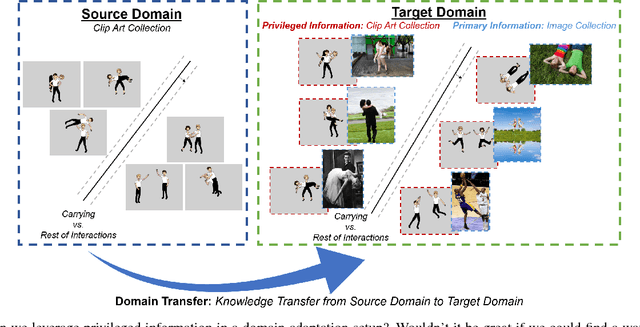
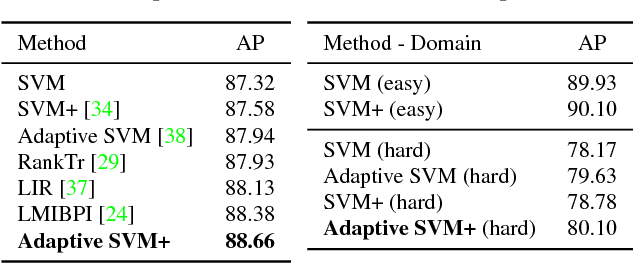
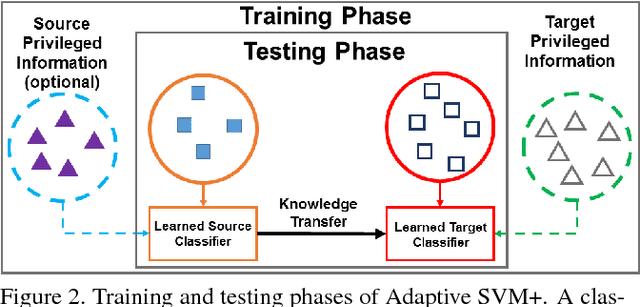

Incorporating additional knowledge in the learning process can be beneficial for several computer vision and machine learning tasks. Whether privileged information originates from a source domain that is adapted to a target domain, or as additional features available at training time only, using such privileged (i.e., auxiliary) information is of high importance as it improves the recognition performance and generalization. However, both primary and privileged information are rarely derived from the same distribution, which poses an additional challenge to the recognition task. To address these challenges, we present a novel learning paradigm that leverages privileged information in a domain adaptation setup to perform visual recognition tasks. The proposed framework, named Adaptive SVM+, combines the advantages of both the learning using privileged information (LUPI) paradigm and the domain adaptation framework, which are naturally embedded in the objective function of a regular SVM. We demonstrate the effectiveness of our approach on the publicly available Animals with Attributes and INTERACT datasets and report state-of-the-art results in both of them.
Curriculum Learning for Multi-Task Classification of Visual Attributes
Aug 29, 2017
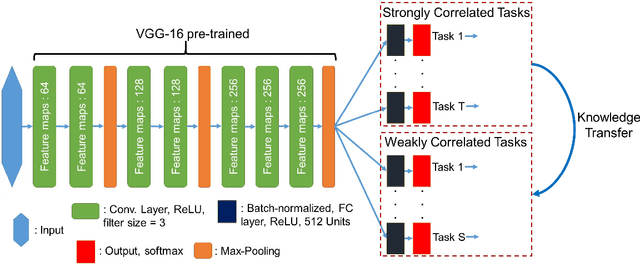
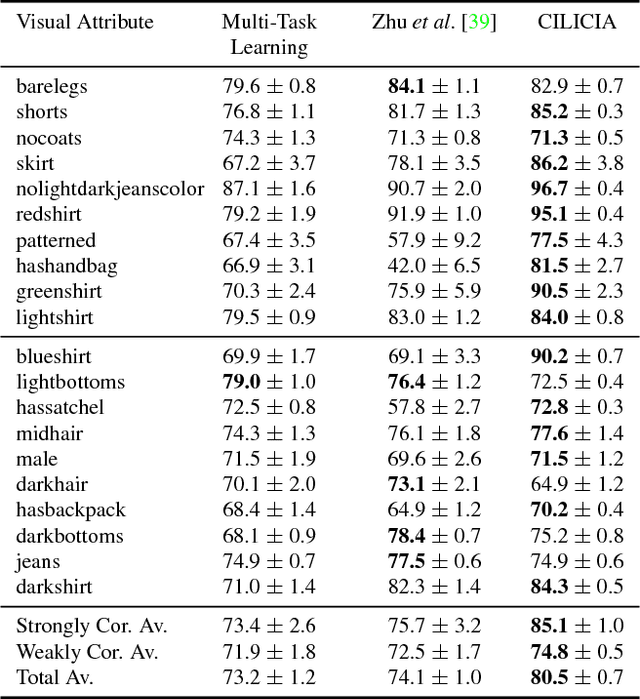
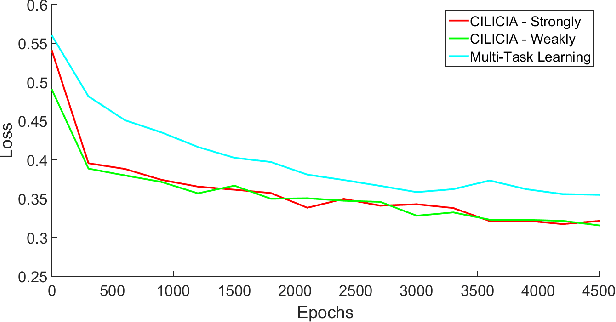
Visual attributes, from simple objects (e.g., backpacks, hats) to soft-biometrics (e.g., gender, height, clothing) have proven to be a powerful representational approach for many applications such as image description and human identification. In this paper, we introduce a novel method to combine the advantages of both multi-task and curriculum learning in a visual attribute classification framework. Individual tasks are grouped based on their correlation so that two groups of strongly and weakly correlated tasks are formed. The two groups of tasks are learned in a curriculum learning setup by transferring the acquired knowledge from the strongly to the weakly correlated. The learning process within each group though, is performed in a multi-task classification setup. The proposed method learns better and converges faster than learning all the tasks in a typical multi-task learning paradigm. We demonstrate the effectiveness of our approach on the publicly available, SoBiR, VIPeR and PETA datasets and report state-of-the-art results across the board.
End-to-end 3D face reconstruction with deep neural networks
Apr 17, 2017

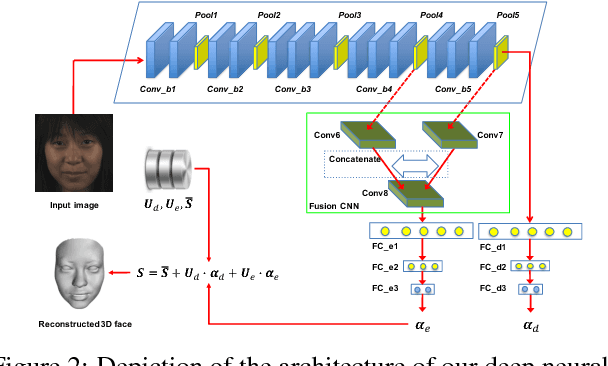

Monocular 3D facial shape reconstruction from a single 2D facial image has been an active research area due to its wide applications. Inspired by the success of deep neural networks (DNN), we propose a DNN-based approach for End-to-End 3D FAce Reconstruction (UH-E2FAR) from a single 2D image. Different from recent works that reconstruct and refine the 3D face in an iterative manner using both an RGB image and an initial 3D facial shape rendering, our DNN model is end-to-end, and thus the complicated 3D rendering process can be avoided. Moreover, we integrate in the DNN architecture two components, namely a multi-task loss function and a fusion convolutional neural network (CNN) to improve facial expression reconstruction. With the multi-task loss function, 3D face reconstruction is divided into neutral 3D facial shape reconstruction and expressive 3D facial shape reconstruction. The neutral 3D facial shape is class-specific. Therefore, higher layer features are useful. In comparison, the expressive 3D facial shape favors lower or intermediate layer features. With the fusion-CNN, features from different intermediate layers are fused and transformed for predicting the 3D expressive facial shape. Through extensive experiments, we demonstrate the superiority of our end-to-end framework in improving the accuracy of 3D face reconstruction.
Predicting Privileged Information for Height Estimation
Feb 09, 2017
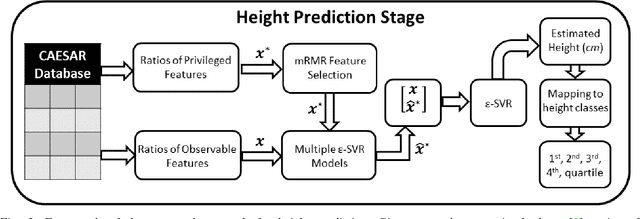
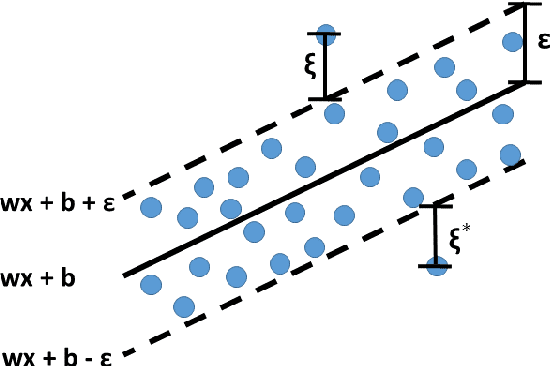
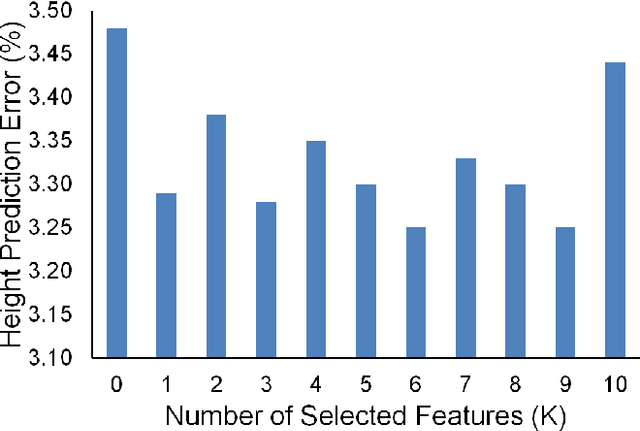
In this paper, we propose a novel regression-based method for employing privileged information to estimate the height using human metrology. The actual values of the anthropometric measurements are difficult to estimate accurately using state-of-the-art computer vision algorithms. Hence, we use ratios of anthropometric measurements as features. Since many anthropometric measurements are not available at test time in real-life scenarios, we employ a learning using privileged information (LUPI) framework in a regression setup. Instead of using the LUPI paradigm for regression in its original form (i.e., \epsilon-SVR+), we train regression models that predict the privileged information at test time. The predictions are then used, along with observable features, to perform height estimation. Once the height is estimated, a mapping to classes is performed. We demonstrate that the proposed approach can estimate the height better and faster than the \epsilon-SVR+ algorithm and report results for different genders and quartiles of humans.