 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIbrahim Abdelaziz
Neural Analogical Matching
Apr 27, 2020
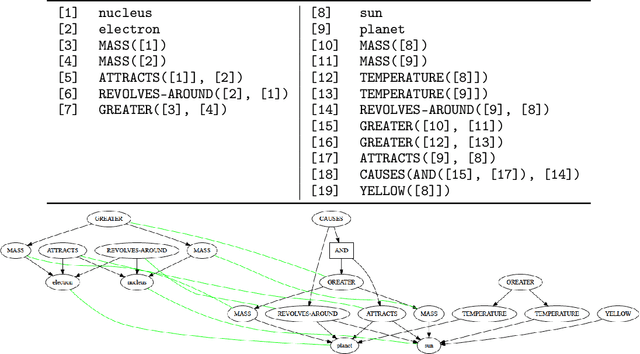
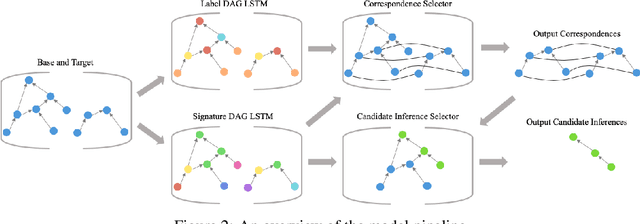

Analogy is core to human cognition. It allows us to solve problems based on prior experience, it governs the way we conceptualize new information, and it even influences our visual perception. The importance of analogy to humans has made it an active area of research in the broader field of artificial intelligence, resulting in data-efficient models that learn and reason in human-like ways. While analogy and deep learning have generally been studied independently of one another, the integration of the two lines of research seems like a promising step towards more robust and efficient learning techniques. As part of the first steps towards such an integration, we introduce the Analogical Matching Network: a neural architecture that learns to produce analogies between structured, symbolic representations that are largely consistent with the principles of Structure-Mapping Theory.
HandVoxNet: Deep Voxel-Based Network for 3D Hand Shape and Pose Estimation from a Single Depth Map
Apr 03, 2020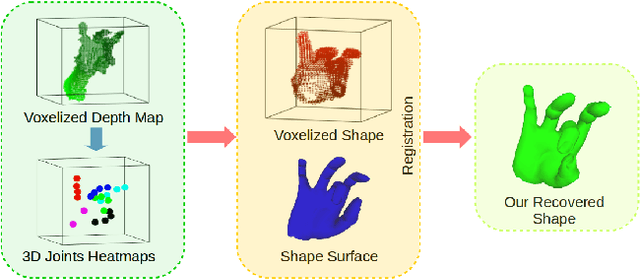

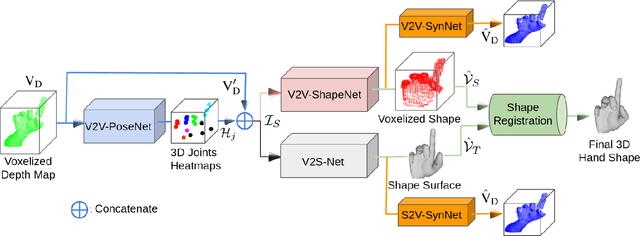

3D hand shape and pose estimation from a single depth map is a new and challenging computer vision problem with many applications. The state-of-the-art methods directly regress 3D hand meshes from 2D depth images via 2D convolutional neural networks, which leads to artefacts in the estimations due to perspective distortions in the images. In contrast, we propose a novel architecture with 3D convolutions trained in a weakly-supervised manner. The input to our method is a 3D voxelized depth map, and we rely on two hand shape representations. The first one is the 3D voxelized grid of the shape which is accurate but does not preserve the mesh topology and the number of mesh vertices. The second representation is the 3D hand surface which is less accurate but does not suffer from the limitations of the first representation. We combine the advantages of these two representations by registering the hand surface to the voxelized hand shape. In the extensive experiments, the proposed approach improves over the state of the art by 47.8% on the SynHand5M dataset. Moreover, our augmentation policy for voxelized depth maps further enhances the accuracy of 3D hand pose estimation on real data. Our method produces visually more reasonable and realistic hand shapes on NYU and BigHand2.2M datasets compared to the existing approaches.
Graph4Code: A Machine Interpretable Knowledge Graph for Code
Feb 21, 2020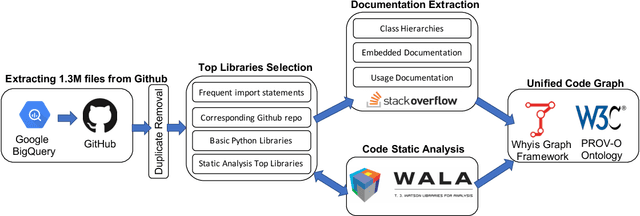
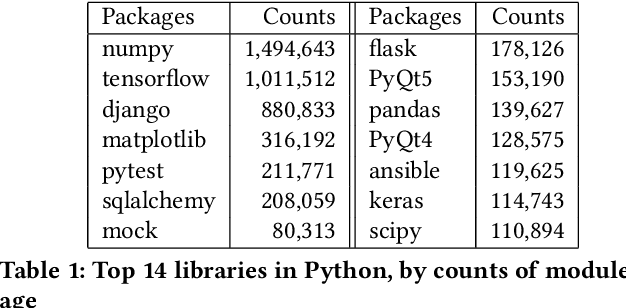
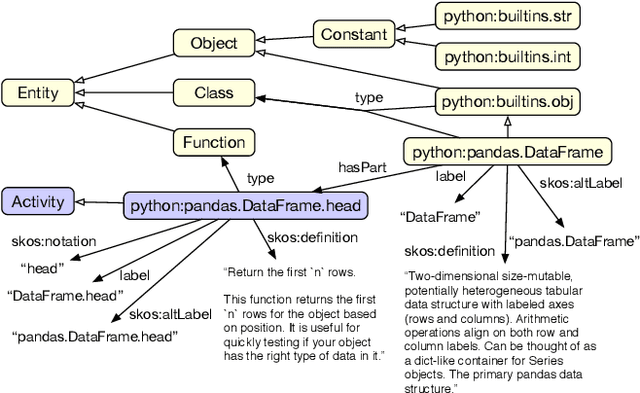

Knowledge graphs have proven to be extremely useful in powering diverse applications in semantic search, natural language understanding, and even image classification. Graph4Code attempts to build well structured knowledge graphs about program code to similarly revolutionize diverse applications such as code search, code understanding, refactoring, bug detection, and code automation. We build such a graph by applying a set of generic code analysis techniques to Python code on the web. Since use of popular Python modules is ubiquitous in code, calls to functions in Python modules serve as key nodes of the knowledge graph. The edges in the graph are based on 1) function usage in the wild (e.g., which other function tends to call this one, or which function tends to precede this one, as gleaned from program analysis), 2) documentation about the function (e.g., code documentation, usage documentation, or forum discussions such as StackOverflow), and 3) program specific features such as class hierarchies. We use the Whyis knowledge graph management framework to make the graph easily extensible. We apply these techniques to 1.3M Python files drawn from GitHub, and associated documentation on the web for over 400 popular libraries, as well as StackOverflow posts about the same set of libraries. This knowledge graph will be made available soon to the larger community for use.
Explainable Deep RDFS Reasoner
Feb 10, 2020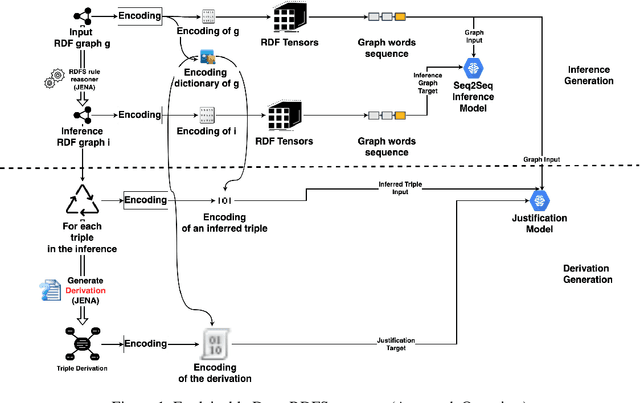
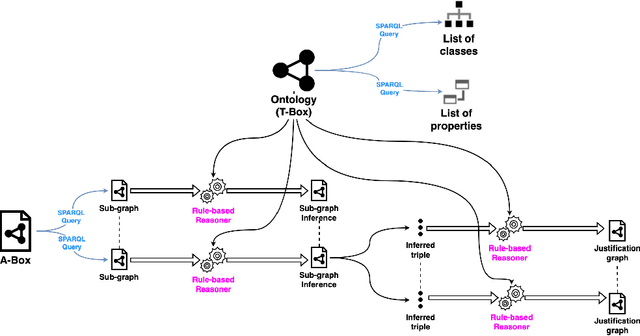
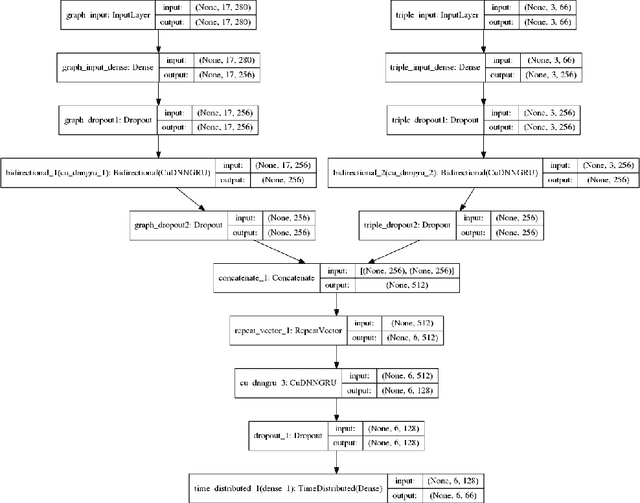
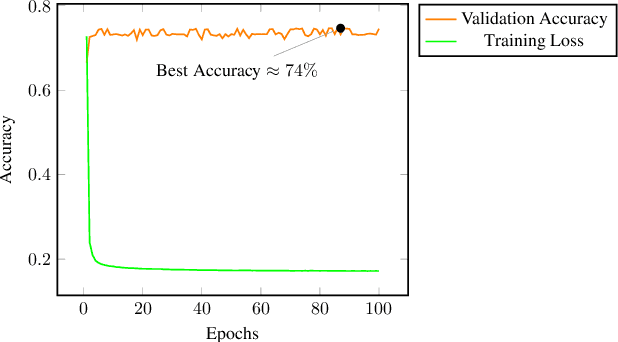
Recent research efforts aiming to bridge the Neural-Symbolic gap for RDFS reasoning proved empirically that deep learning techniques can be used to learn RDFS inference rules. However, one of their main deficiencies compared to rule-based reasoners is the lack of derivations for the inferred triples (i.e. explainability in AI terms). In this paper, we build on these approaches to provide not only the inferred graph but also explain how these triples were inferred. In the graph words approach, RDF graphs are represented as a sequence of graph words where inference can be achieved through neural machine translation. To achieve explainability in RDFS reasoning, we revisit this approach and introduce a new neural network model that gets the input graph--as a sequence of graph words-- as well as the encoding of the inferred triple and outputs the derivation for the inferred triple. We evaluated our justification model on two datasets: a synthetic dataset-- LUBM benchmark-- and a real-world dataset --ScholarlyData about conferences-- where the lowest validation accuracy approached 96%.
An Experimental Study of Formula Embeddings for Automated Theorem Proving in First-Order Logic
Feb 02, 2020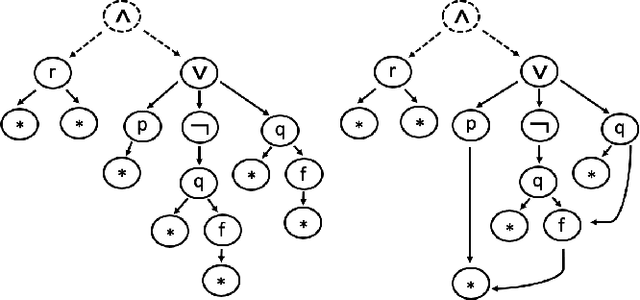
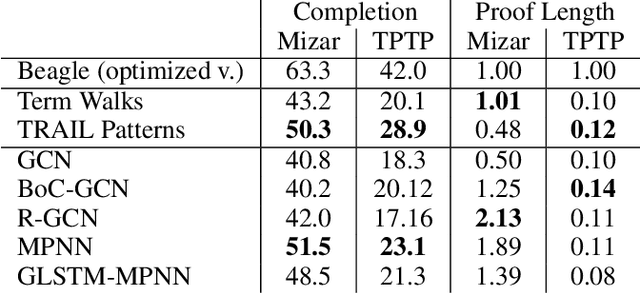
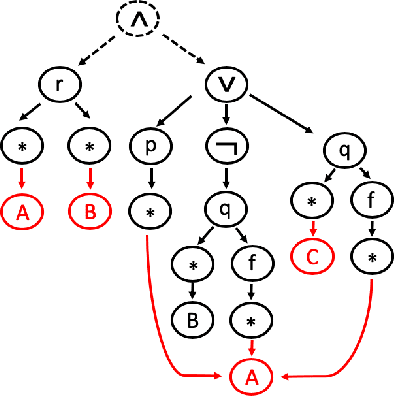
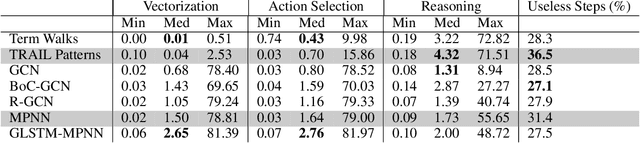
Automated theorem proving in first-order logic is an active research area which is successfully supported by machine learning. While there have been various proposals for encoding logical formulas into numerical vectors -- from simple strings to much more involved graph-based embeddings --, little is known about how these different encodings compare. In this paper, we study and experimentally compare pattern-based embeddings that are applied in current systems with popular graph-based encodings, most of which have not been considered in the theorem proving context before. Our experiments show that some graph-based encodings help finding much shorter proofs and may yield better performance in terms of number of completed proofs. However, as expected, a detailed analysis shows the trade-offs in terms of runtime.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019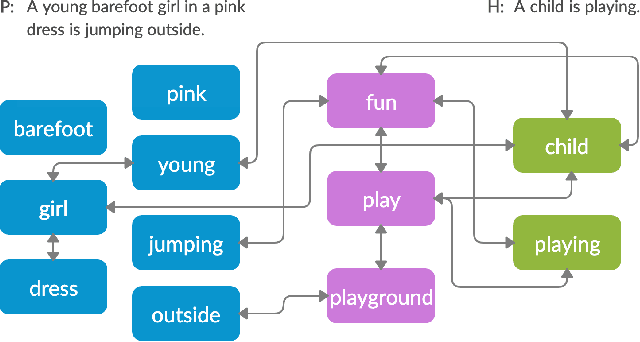

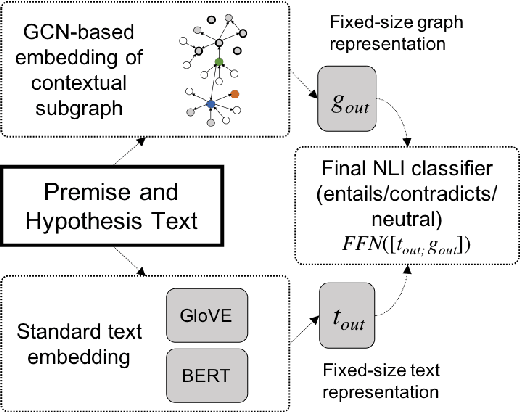
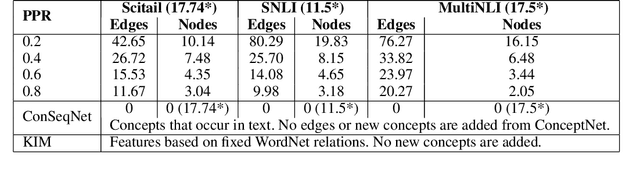
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
Improving Graph Neural Network Representations of Logical Formulae with Subgraph Pooling
Nov 15, 2019
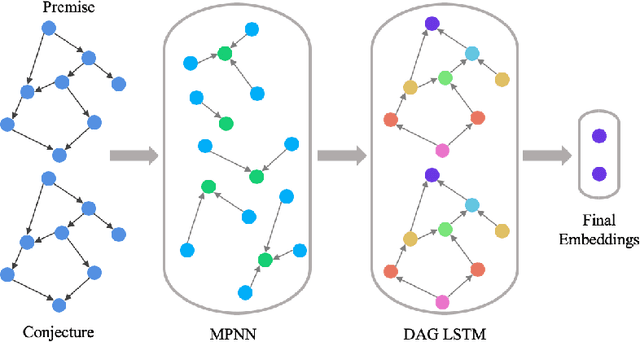
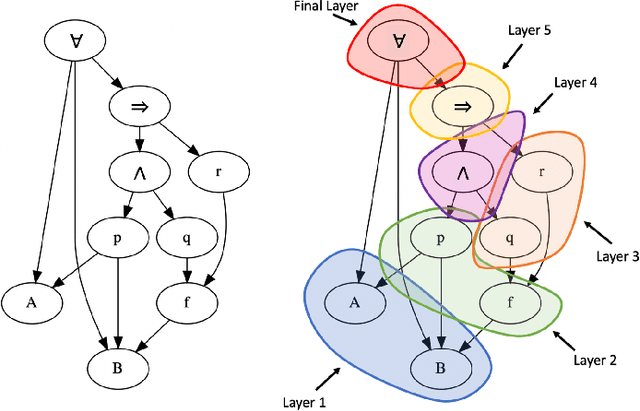
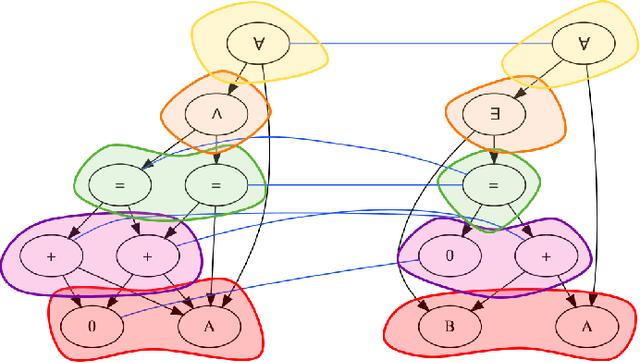
Recent advances in the integration of deep learning with automated theorem proving have centered around the representation of logical formulae as inputs to deep learning systems. In particular, there has been a shift from character and token-level representations to graph-structured representations, in large part driven by the rapidly emerging body of research on geometric deep learning. Typically, structure-aware neural methods for embedding logical formulae have been variants of either Tree LSTMs or GNNs. While more effective than character and token-level approaches, such methods have often made representational trade-offs that limited their ability to effectively represent the global structure of their inputs. In this work, we introduce a novel approach for embedding logical formulae using DAG LSTMs that is designed to overcome the limitations of both Tree LSTMs and GNNs. The effectiveness of the proposed framework is demonstrated on the tasks of premise selection and proof step classification where it achieves the state-of-the-art performance on two standard datasets.
A Deep Reinforcement Learning based Approach to Learning Transferable Proof Guidance Strategies
Nov 05, 2019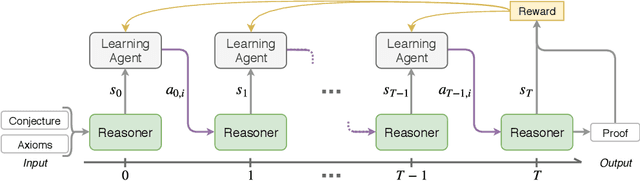
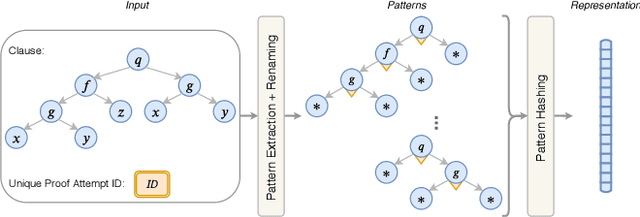

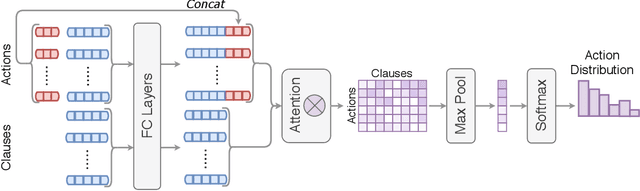
Traditional first-order logic (FOL) reasoning systems usually rely on manual heuristics for proof guidance. We propose TRAIL: a system that learns to perform proof guidance using reinforcement learning. A key design principle of our system is that it is general enough to allow transfer to problems in different domains that do not share the same vocabulary of the training set. To do so, we developed a novel representation of the internal state of a prover in terms of clauses and inference actions, and a novel neural-based attention mechanism to learn interactions between clauses. We demonstrate that this approach enables the system to generalize from training to test data across domains with different vocabularies, suggesting that the neural architecture in TRAIL is well suited for representing and processing of logical formalisms.