 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference on Word Embedding and Beyond
Jun 21, 2021


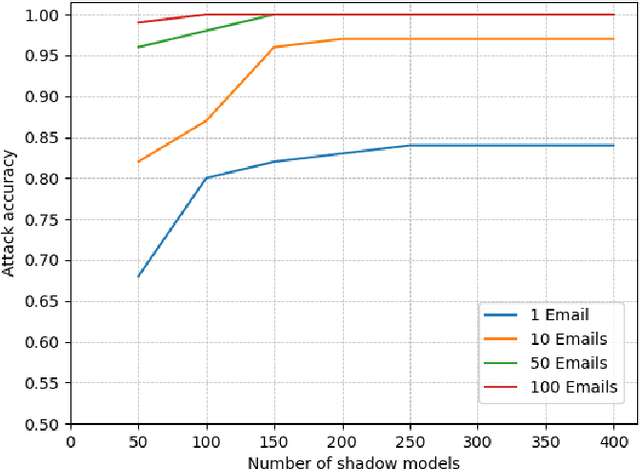
In the text processing context, most ML models are built on word embeddings. These embeddings are themselves trained on some datasets, potentially containing sensitive data. In some cases this training is done independently, in other cases, it occurs as part of training a larger, task-specific model. In either case, it is of interest to consider membership inference attacks based on the embedding layer as a way of understanding sensitive information leakage. But, somewhat surprisingly, membership inference attacks on word embeddings and their effect in other natural language processing (NLP) tasks that use these embeddings, have remained relatively unexplored. In this work, we show that word embeddings are vulnerable to black-box membership inference attacks under realistic assumptions. Furthermore, we show that this leakage persists through two other major NLP applications: classification and text-generation, even when the embedding layer is not exposed to the attacker. We show that our MI attack achieves high attack accuracy against a classifier model and an LSTM-based language model. Indeed, our attack is a cheaper membership inference attack on text-generative models, which does not require the knowledge of the target model or any expensive training of text-generative models as shadow models.
Privacy Regularization: Joint Privacy-Utility Optimization in Language Models
Mar 12, 2021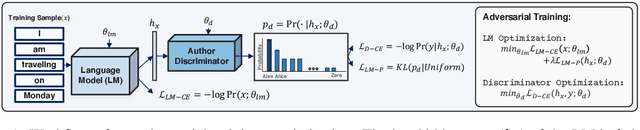
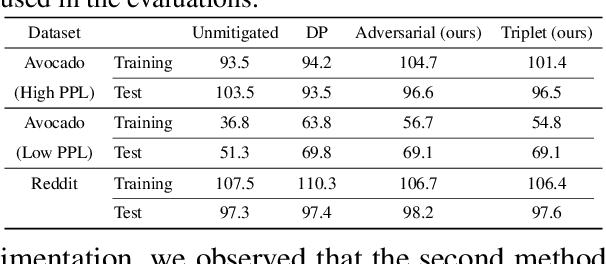
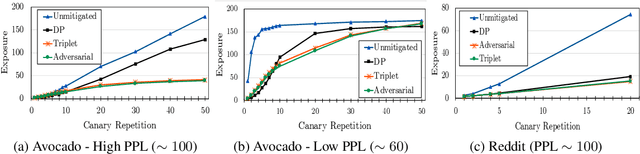

Neural language models are known to have a high capacity for memorization of training samples. This may have serious privacy implications when training models on user content such as email correspondence. Differential privacy (DP), a popular choice to train models with privacy guarantees, comes with significant costs in terms of utility degradation and disparate impact on subgroups of users. In this work, we introduce two privacy-preserving regularization methods for training language models that enable joint optimization of utility and privacy through (1) the use of a discriminator and (2) the inclusion of a triplet-loss term. We compare our methods with DP through extensive evaluation. We show the advantages of our regularizers with favorable utility-privacy trade-off, faster training with the ability to tap into existing optimization approaches, and ensuring uniform treatment of under-represented subgroups.
Privacy Analysis in Language Models via Training Data Leakage Report
Jan 14, 2021

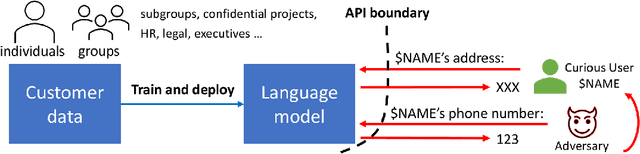
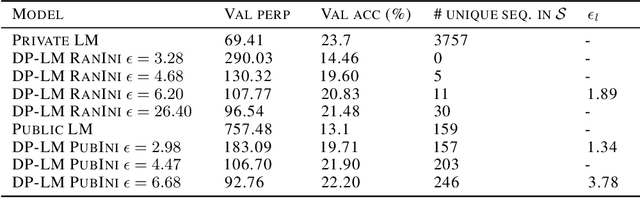
Recent advances in neural network based language models lead to successful deployments of such models, improving user experience in various applications. It has been demonstrated that strong performance of language models may come along with the ability to memorize rare training samples, which poses serious privacy threats in case the model training is conducted on confidential user content. This necessitates privacy monitoring techniques to minimize the chance of possible privacy breaches for the models deployed in practice. In this work, we introduce a methodology that investigates identifying the user content in the training data that could be leaked under a strong and realistic threat model. We propose two metrics to quantify user-level data leakage by measuring a model's ability to produce unique sentence fragments within training data. Our metrics further enable comparing different models trained on the same data in terms of privacy. We demonstrate our approach through extensive numerical studies on real-world datasets such as email and forum conversations. We further illustrate how the proposed metrics can be utilized to investigate the efficacy of mitigations like differentially private training or API hardening.
rTop-k: A Statistical Estimation Approach to Distributed SGD
May 21, 2020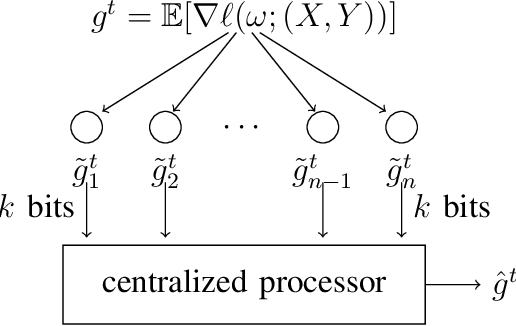
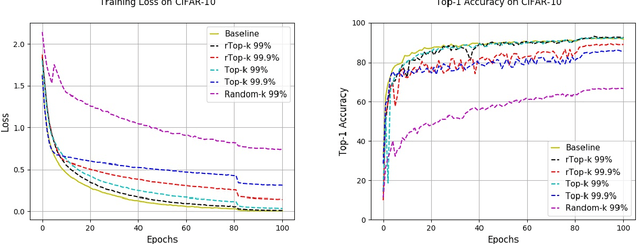
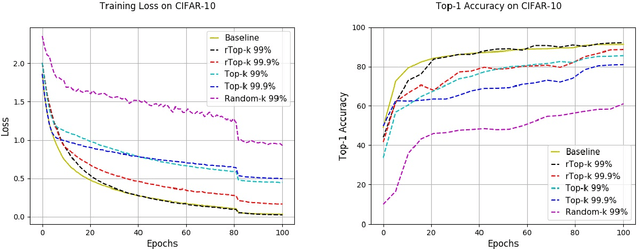
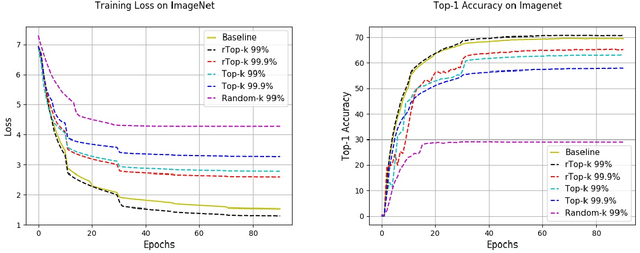
The large communication cost for exchanging gradients between different nodes significantly limits the scalability of distributed training for large-scale learning models. Motivated by this observation, there has been significant recent interest in techniques that reduce the communication cost of distributed Stochastic Gradient Descent (SGD), with gradient sparsification techniques such as top-k and random-k shown to be particularly effective. The same observation has also motivated a separate line of work in distributed statistical estimation theory focusing on the impact of communication constraints on the estimation efficiency of different statistical models. The primary goal of this paper is to connect these two research lines and demonstrate how statistical estimation models and their analysis can lead to new insights in the design of communication-efficient training techniques. We propose a simple statistical estimation model for the stochastic gradients which captures the sparsity and skewness of their distribution. The statistically optimal communication scheme arising from the analysis of this model leads to a new sparsification technique for SGD, which concatenates random-k and top-k, considered separately in the prior literature. We show through extensive experiments on both image and language domains with CIFAR-10, ImageNet, and Penn Treebank datasets that the concatenated application of these two sparsification methods consistently and significantly outperforms either method applied alone.
Improving Semantic Parsing with Neural Generator-Reranker Architecture
Sep 27, 2019
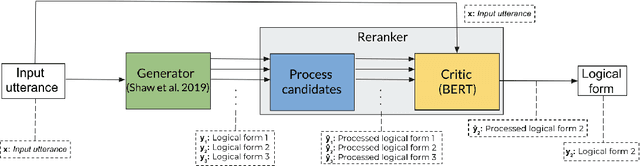


Semantic parsing is the problem of deriving machine interpretable meaning representations from natural language utterances. Neural models with encoder-decoder architectures have recently achieved substantial improvements over traditional methods. Although neural semantic parsers appear to have relatively high recall using large beam sizes, there is room for improvement with respect to one-best precision. In this work, we propose a generator-reranker architecture for semantic parsing. The generator produces a list of potential candidates and the reranker, which consists of a pre-processing step for the candidates followed by a novel critic network, reranks these candidates based on the similarity between each candidate and the input sentence. We show the advantages of this approach along with how it improves the parsing performance through extensive analysis. We experiment our model on three semantic parsing datasets (GEO, ATIS, and OVERNIGHT). The overall architecture achieves the state-of-the-art results in all three datasets.
Adaptive Mixture Methods Based on Bregman Divergences
Mar 20, 2012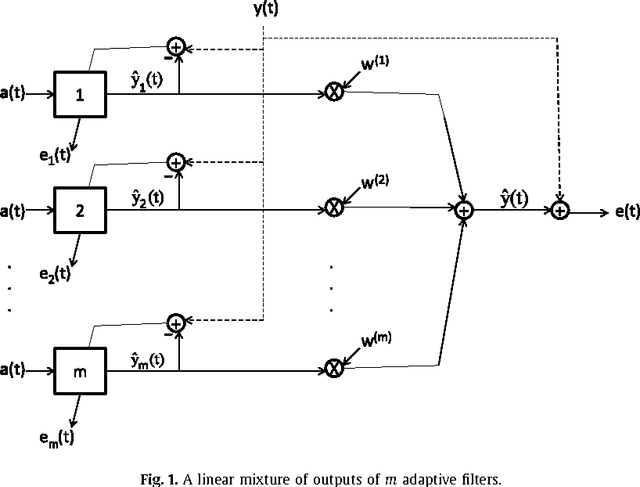
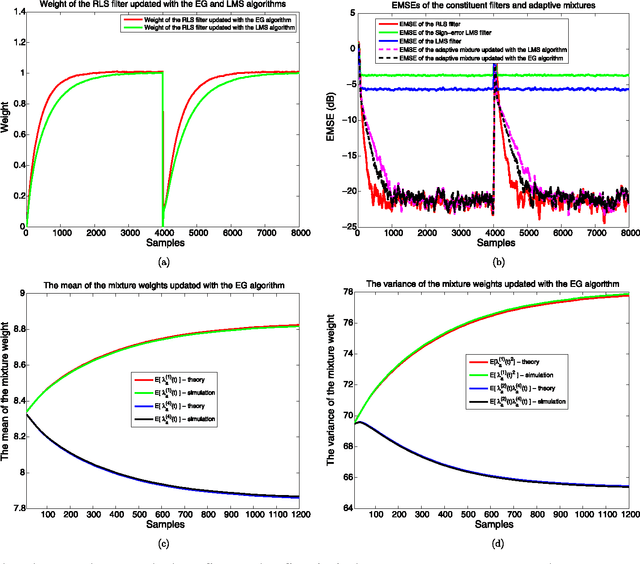
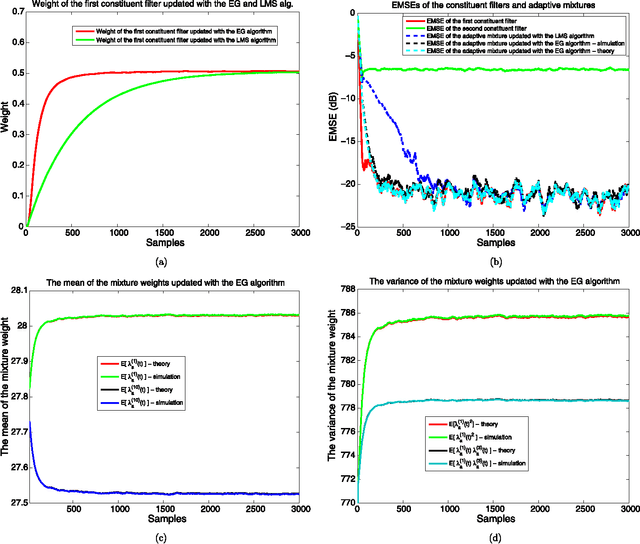
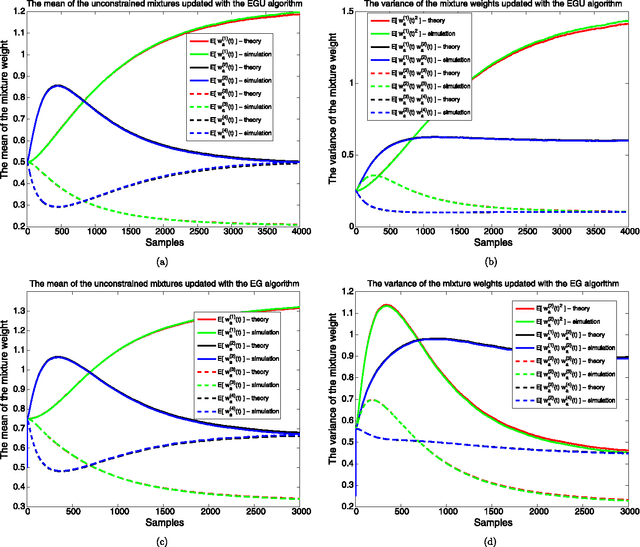
We investigate adaptive mixture methods that linearly combine outputs of $m$ constituent filters running in parallel to model a desired signal. We use "Bregman divergences" and obtain certain multiplicative updates to train the linear combination weights under an affine constraint or without any constraints. We use unnormalized relative entropy and relative entropy to define two different Bregman divergences that produce an unnormalized exponentiated gradient update and a normalized exponentiated gradient update on the mixture weights, respectively. We then carry out the mean and the mean-square transient analysis of these adaptive algorithms when they are used to combine outputs of $m$ constituent filters. We illustrate the accuracy of our results and demonstrate the effectiveness of these updates for sparse mixture systems.