 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHugo Jair Escalante
Multi-Branch Deep Radial Basis Function Networks for Facial Emotion Recognition
Sep 07, 2021
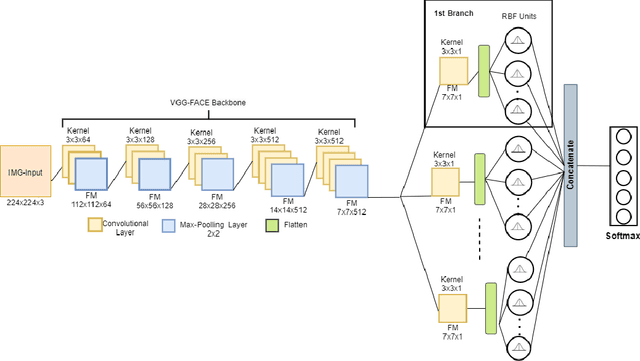
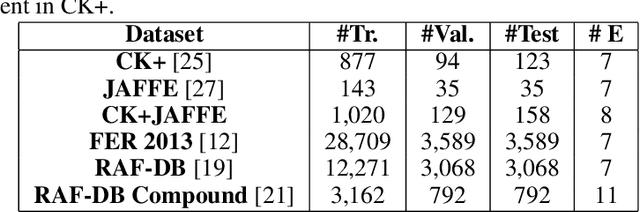
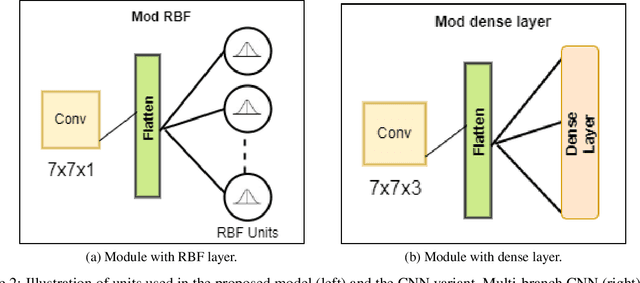
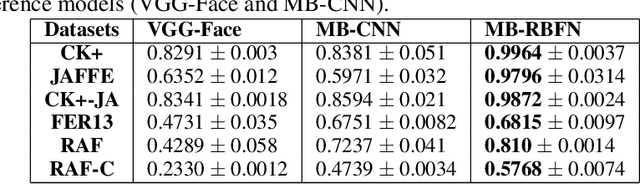
Emotion recognition (ER) from facial images is one of the landmark tasks in affective computing with major developments in the last decade. Initial efforts on ER relied on handcrafted features that were used to characterize facial images and then feed to standard predictive models. Recent methodologies comprise end-to-end trainable deep learning methods that simultaneously learn both, features and predictive model. Perhaps the most successful models are based on convolutional neural networks (CNNs). While these models have excelled at this task, they still fail at capturing local patterns that could emerge in the learning process. We hypothesize these patterns could be captured by variants based on locally weighted learning. Specifically, in this paper we propose a CNN based architecture enhanced with multiple branches formed by radial basis function (RBF) units that aims at exploiting local information at the final stage of the learning process. Intuitively, these RBF units capture local patterns shared by similar instances using an intermediate representation, then the outputs of the RBFs are feed to a softmax layer that exploits this information to improve the predictive performance of the model. This feature could be particularly advantageous in ER as cultural / ethnicity differences may be identified by the local units. We evaluate the proposed method in several ER datasets and show the proposed methodology achieves state-of-the-art in some of them, even when we adopt a pre-trained VGG-Face model as backbone. We show it is the incorporation of local information what makes the proposed model competitive.
Predicting students' performance in online courses using multiple data sources
Sep 07, 2021
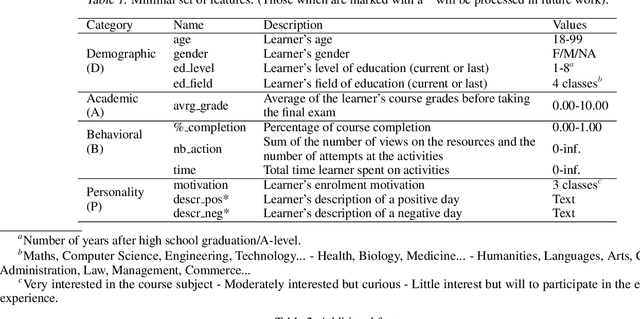
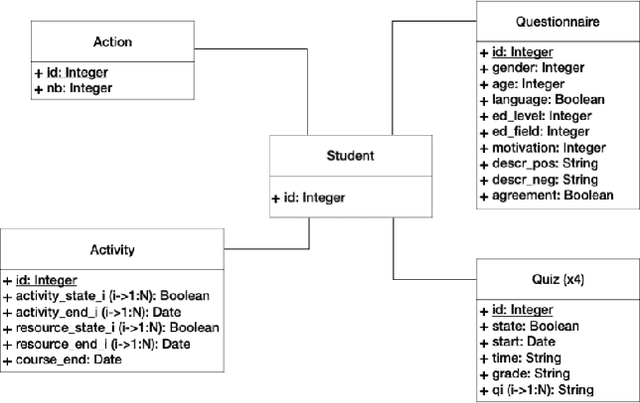
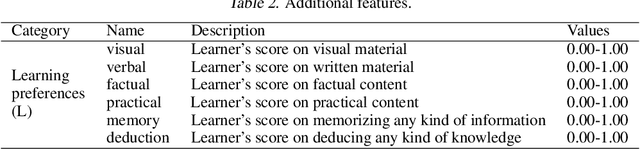
Data-driven decision making is serving and transforming education. We approached the problem of predicting students' performance by using multiple data sources which came from online courses, including one we created. Experimental results show preliminary conclusions towards which data are to be considered for the task.
3D High-Fidelity Mask Face Presentation Attack Detection Challenge
Aug 16, 2021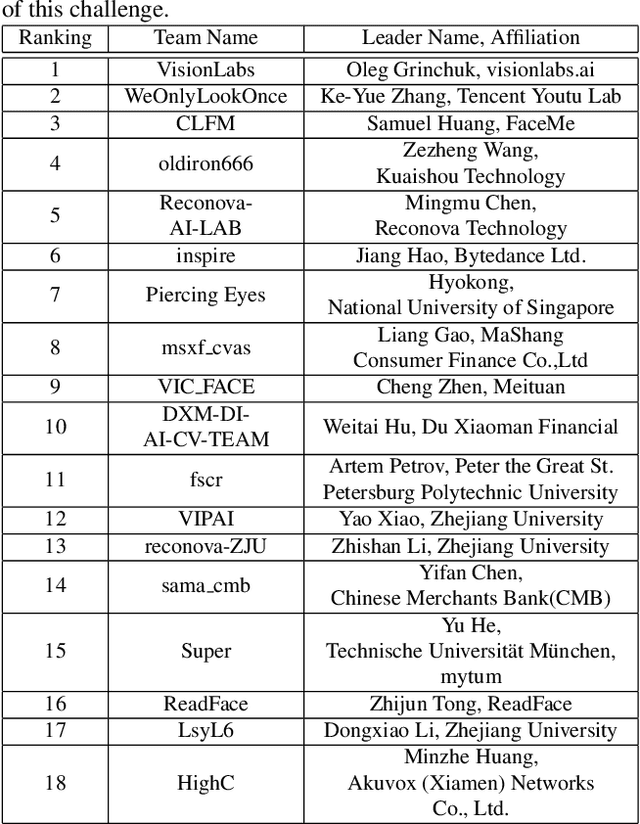
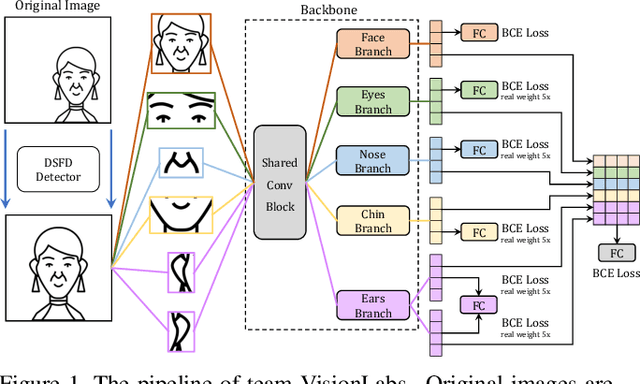
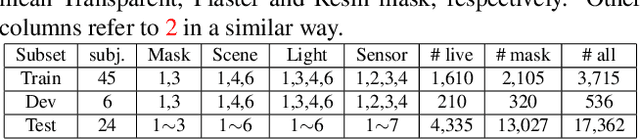
The threat of 3D masks to face recognition systems is increasingly serious and has been widely concerned by researchers. To facilitate the study of the algorithms, a large-scale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask) has been collected. Specifically, it consists of a total amount of 54, 600 videos which are recorded from 75 subjects with 225 realistic masks under 7 new kinds of sensors. Based on this dataset and Protocol 3 which evaluates both the discrimination and generalization ability of the algorithm under the open set scenarios, we organized a 3D High-Fidelity Mask Face Presentation Attack Detection Challenge to boost the research of 3D mask-based attack detection. It attracted 195 teams for the development phase with a total of 18 teams qualifying for the final round. All the results were verified and re-run by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including the introduction of the dataset used, the definition of the protocol, the calculation of the evaluation criteria, and the summary and publication of the competition results. Finally, we focus on introducing and analyzing the top ranking algorithms, the conclusion summary, and the research ideas for mask attack detection provided by this competition.
ChaLearn Looking at People: Inpainting and Denoising challenges
Jun 24, 2021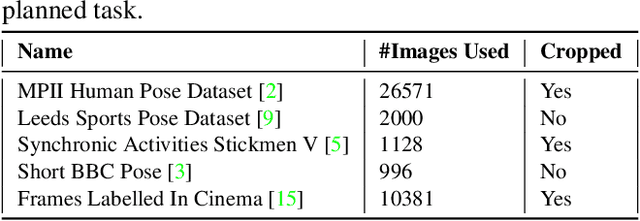
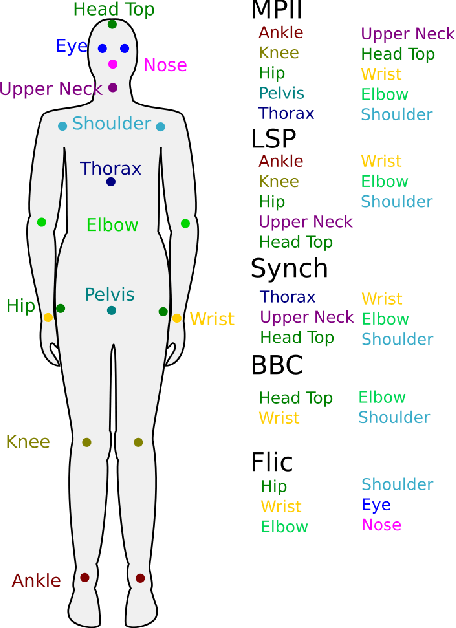
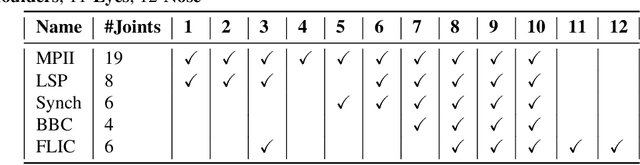

Dealing with incomplete information is a well studied problem in the context of machine learning and computational intelligence. However, in the context of computer vision, the problem has only been studied in specific scenarios (e.g., certain types of occlusions in specific types of images), although it is common to have incomplete information in visual data. This chapter describes the design of an academic competition focusing on inpainting of images and video sequences that was part of the competition program of WCCI2018 and had a satellite event collocated with ECCV2018. The ChaLearn Looking at People Inpainting Challenge aimed at advancing the state of the art on visual inpainting by promoting the development of methods for recovering missing and occluded information from images and video. Three tracks were proposed in which visual inpainting might be helpful but still challenging: human body pose estimation, text overlays removal and fingerprint denoising. This chapter describes the design of the challenge, which includes the release of three novel datasets, and the description of evaluation metrics, baselines and evaluation protocol. The results of the challenge are analyzed and discussed in detail and conclusions derived from this event are outlined.
Automated Machine Learning -- a brief review at the end of the early years
Aug 24, 2020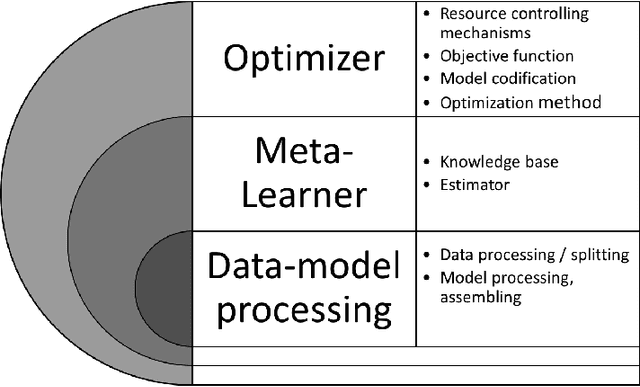
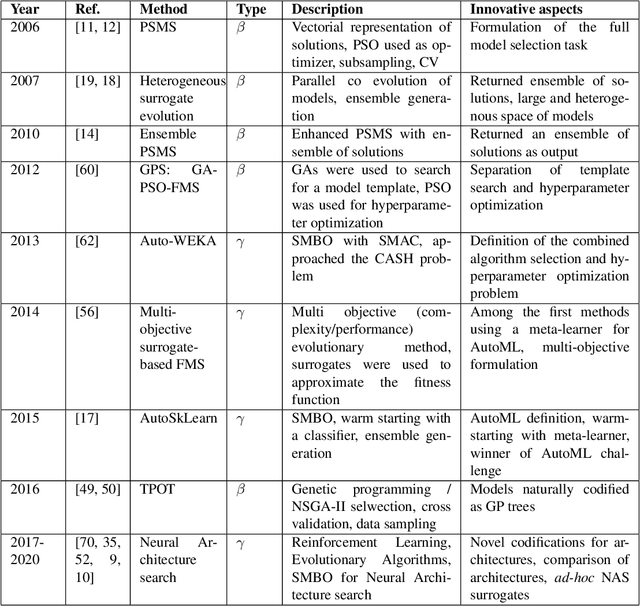
Automated machine learning (AutoML) is the sub-field of machine learning that aims at automating, to some extend, all stages of the design of a machine learning system. In the context of supervised learning, AutoML is concerned with feature extraction, pre processing, model design and post processing. Major contributions and achievements in AutoML have been taking place during the recent decade. We are therefore in perfect timing to look back and realize what we have learned. This chapter aims to summarize the main findings in the early years of AutoML. More specifically, in this chapter an introduction to AutoML for supervised learning is provided and an historical review of progress in this field is presented. Likewise, the main paradigms of AutoML are described and research opportunities are outlined.
Cross-ethnicity Face Anti-spoofing Recognition Challenge: A Review
Apr 23, 2020
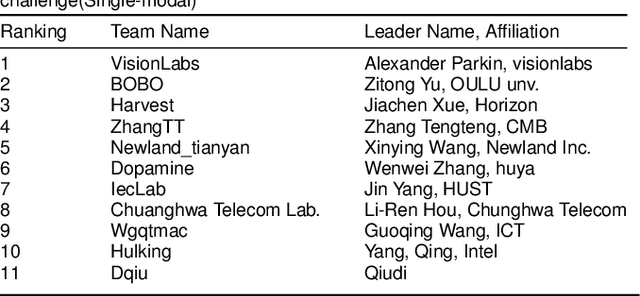
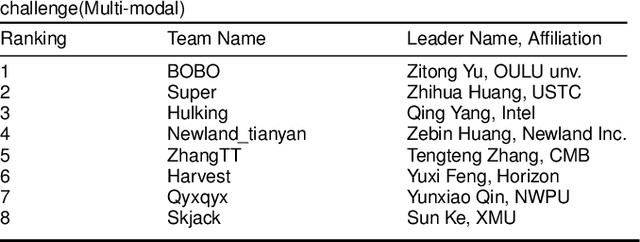
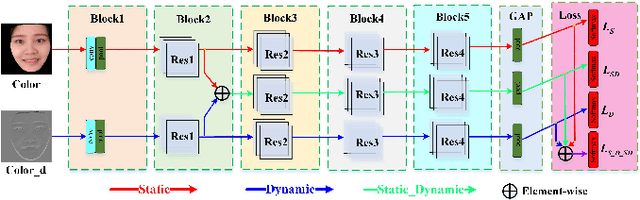
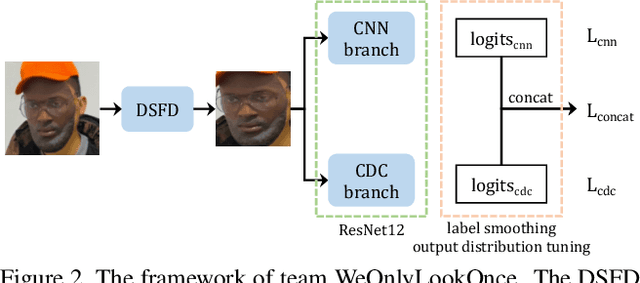
Face anti-spoofing is critical to prevent face recognition systems from a security breach. The biometrics community has %possessed achieved impressive progress recently due the excellent performance of deep neural networks and the availability of large datasets. Although ethnic bias has been verified to severely affect the performance of face recognition systems, it still remains an open research problem in face anti-spoofing. Recently, a multi-ethnic face anti-spoofing dataset, CASIA-SURF CeFA, has been released with the goal of measuring the ethnic bias. It is the largest up to date cross-ethnicity face anti-spoofing dataset covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, 2D plus 3D attack types, and the first dataset including explicit ethnic labels among the recently released datasets for face anti-spoofing. We organized the Chalearn Face Anti-spoofing Attack Detection Challenge which consists of single-modal (e.g., RGB) and multi-modal (e.g., RGB, Depth, Infrared (IR)) tracks around this novel resource to boost research aiming to alleviate the ethnic bias. Both tracks have attracted $340$ teams in the development stage, and finally 11 and 8 teams have submitted their codes in the single-modal and multi-modal face anti-spoofing recognition challenges, respectively. All the results were verified and re-ran by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including its design, evaluation protocol and a summary of results. We analyze the top ranked solutions and draw conclusions derived from the competition. In addition we outline future work directions.
CASIA-SURF: A Large-scale Multi-modal Benchmark for Face Anti-spoofing
Aug 28, 2019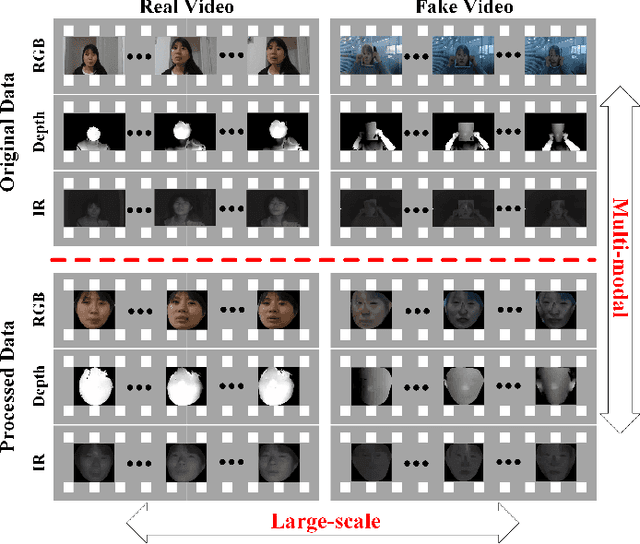


Face anti-spoofing is essential to prevent face recognition systems from a security breach. Much of the progresses have been made by the availability of face anti-spoofing benchmark datasets in recent years. However, existing face anti-spoofing benchmarks have limited number of subjects ($\le\negmedspace170$) and modalities ($\leq\negmedspace2$), which hinder the further development of the academic community. To facilitate face anti-spoofing research, we introduce a large-scale multi-modal dataset, namely CASIA-SURF, which is the largest publicly available dataset for face anti-spoofing in terms of both subjects and modalities. Specifically, it consists of $1,000$ subjects with $21,000$ videos and each sample has $3$ modalities (i.e., RGB, Depth and IR). We also provide comprehensive evaluation metrics, diverse evaluation protocols, training/validation/testing subsets and a measurement tool, developing a new benchmark for face anti-spoofing. Moreover, we present a novel multi-modal multi-scale fusion method as a strong baseline, which performs feature re-weighting to select the more informative channel features while suppressing the less useful ones for each modality across different scales. Extensive experiments have been conducted on the proposed dataset to verify its significance and generalization capability. The dataset is available at https://sites.google.com/qq.com/chalearnfacespoofingattackdete
Towards AutoML in the presence of Drift: first results
Jul 24, 2019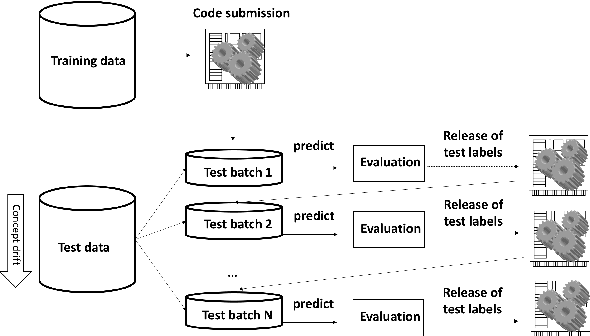
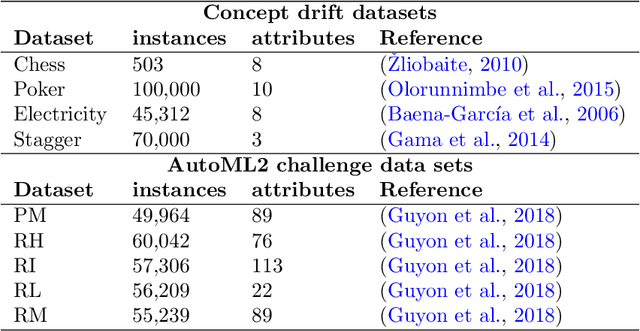
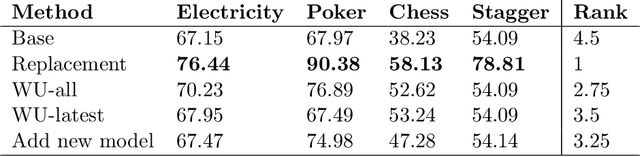
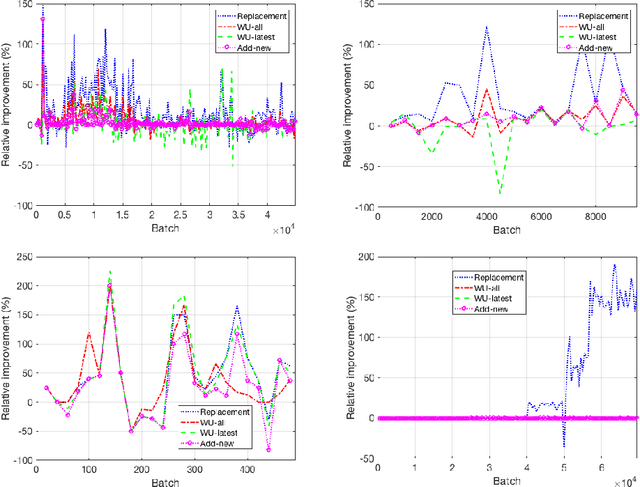
Research progress in AutoML has lead to state of the art solutions that can cope quite wellwith supervised learning task, e.g., classification with AutoSklearn. However, so far thesesystems do not take into account the changing nature of evolving data over time (i.e., theystill assume i.i.d. data); even when this sort of domains are increasingly available in realapplications (e.g., spam filtering, user preferences, etc.). We describe a first attempt to de-velop an AutoML solution for scenarios in which data distribution changes relatively slowlyover time and in which the problem is approached in a lifelong learning setting. We extendAuto-Sklearn with sound and intuitive mechanisms that allow it to cope with this sort ofproblems. The extended Auto-Sklearn is combined with concept drift detection techniquesthat allow it to automatically determine when the initial models have to be adapted. Wereport experimental results in benchmark data from AutoML competitions that adhere tothis scenario. Results demonstrate the effectiveness of the proposed methodology.
Meta-learning of textual representations
Jul 19, 2019
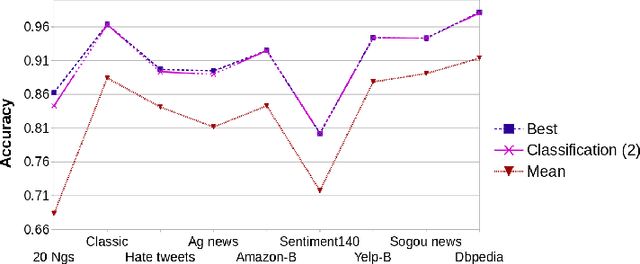

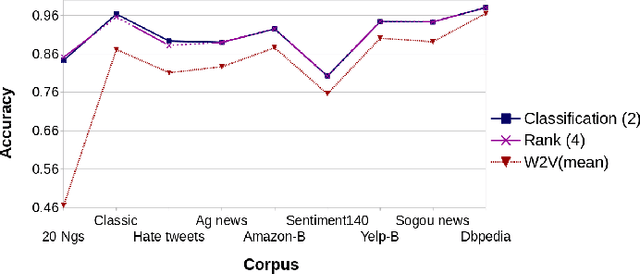
Recent progress in AutoML has lead to state-of-the-art methods (e.g., AutoSKLearn) that can be readily used by non-experts to approach any supervised learning problem. Whereas these methods are quite effective, they are still limited in the sense that they work for tabular (matrix formatted) data only. This paper describes one step forward in trying to automate the design of supervised learning methods in the context of text mining. We introduce a meta learning methodology for automatically obtaining a representation for text mining tasks starting from raw text. We report experiments considering 60 different textual representations and more than 80 text mining datasets associated to a wide variety of tasks. Experimental results show the proposed methodology is a promising solution to obtain highly effective off the shell text classification pipelines.