 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHouqiang Li
Spatial Decomposition and Temporal Fusion based Inter Prediction for Learned Video Compression
Jan 29, 2024
Video compression performance is closely related to the accuracy of inter prediction. It tends to be difficult to obtain accurate inter prediction for the local video regions with inconsistent motion and occlusion. Traditional video coding standards propose various technologies to handle motion inconsistency and occlusion, such as recursive partitions, geometric partitions, and long-term references. However, existing learned video compression schemes focus on obtaining an overall minimized prediction error averaged over all regions while ignoring the motion inconsistency and occlusion in local regions. In this paper, we propose a spatial decomposition and temporal fusion based inter prediction for learned video compression. To handle motion inconsistency, we propose to decompose the video into structure and detail (SDD) components first. Then we perform SDD-based motion estimation and SDD-based temporal context mining for the structure and detail components to generate short-term temporal contexts. To handle occlusion, we propose to propagate long-term temporal contexts by recurrently accumulating the temporal information of each historical reference feature and fuse them with short-term temporal contexts. With the SDD-based motion model and long short-term temporal contexts fusion, our proposed learned video codec can obtain more accurate inter prediction. Comprehensive experimental results demonstrate that our codec outperforms the reference software of H.266/VVC on all common test datasets for both PSNR and MS-SSIM.
Exploiting GPT-4 Vision for Zero-shot Point Cloud Understanding
Jan 15, 2024In this study, we tackle the challenge of classifying the object category in point clouds, which previous works like PointCLIP struggle to address due to the inherent limitations of the CLIP architecture. Our approach leverages GPT-4 Vision (GPT-4V) to overcome these challenges by employing its advanced generative abilities, enabling a more adaptive and robust classification process. We adapt the application of GPT-4V to process complex 3D data, enabling it to achieve zero-shot recognition capabilities without altering the underlying model architecture. Our methodology also includes a systematic strategy for point cloud image visualization, mitigating domain gap and enhancing GPT-4V's efficiency. Experimental validation demonstrates our approach's superiority in diverse scenarios, setting a new benchmark in zero-shot point cloud classification.
Passive Non-Line-of-Sight Imaging with Light Transport Modulation
Dec 26, 2023Passive non-line-of-sight (NLOS) imaging has witnessed rapid development in recent years, due to its ability to image objects that are out of sight. The light transport condition plays an important role in this task since changing the conditions will lead to different imaging models. Existing learning-based NLOS methods usually train independent models for different light transport conditions, which is computationally inefficient and impairs the practicality of the models. In this work, we propose NLOS-LTM, a novel passive NLOS imaging method that effectively handles multiple light transport conditions with a single network. We achieve this by inferring a latent light transport representation from the projection image and using this representation to modulate the network that reconstructs the hidden image from the projection image. We train a light transport encoder together with a vector quantizer to obtain the light transport representation. To further regulate this representation, we jointly learn both the reconstruction network and the reprojection network during training. A set of light transport modulation blocks is used to modulate the two jointly trained networks in a multi-scale way. Extensive experiments on a large-scale passive NLOS dataset demonstrate the superiority of the proposed method. The code is available at https://github.com/JerryOctopus/NLOS-LTM.
TinySAM: Pushing the Envelope for Efficient Segment Anything Model
Dec 21, 2023Recently segment anything model (SAM) has shown powerful segmentation capability and has drawn great attention in computer vision fields. Massive following works have developed various applications based on the pretrained SAM and achieved impressive performance on downstream vision tasks. However, SAM consists of heavy architectures and requires massive computational capacity, which hinders the further application of SAM on computation constrained edge devices. To this end, in this paper we propose a framework to obtain a tiny segment anything model (TinySAM) while maintaining the strong zero-shot performance. We first propose a full-stage knowledge distillation method with online hard prompt sampling strategy to distill a lightweight student model. We also adapt the post-training quantization to the promptable segmentation task and further reduce the computational cost. Moreover, a hierarchical segmenting everything strategy is proposed to accelerate the everything inference by $2\times$ with almost no performance degradation. With all these proposed methods, our TinySAM leads to orders of magnitude computational reduction and pushes the envelope for efficient segment anything task. Extensive experiments on various zero-shot transfer tasks demonstrate the significantly advantageous performance of our TinySAM against counterpart methods. Pre-trained models and codes will be available at https://github.com/xinghaochen/TinySAM and https://gitee.com/mindspore/models/tree/master/research/cv/TinySAM.
DanZero+: Dominating the GuanDan Game through Reinforcement Learning
Dec 05, 2023The utilization of artificial intelligence (AI) in card games has been a well-explored subject within AI research for an extensive period. Recent advancements have propelled AI programs to showcase expertise in intricate card games such as Mahjong, DouDizhu, and Texas Hold'em. In this work, we aim to develop an AI program for an exceptionally complex and popular card game called GuanDan. This game involves four players engaging in both competitive and cooperative play throughout a long process to upgrade their level, posing great challenges for AI due to its expansive state and action space, long episode length, and complex rules. Employing reinforcement learning techniques, specifically Deep Monte Carlo (DMC), and a distributed training framework, we first put forward an AI program named DanZero for this game. Evaluation against baseline AI programs based on heuristic rules highlights the outstanding performance of our bot. Besides, in order to further enhance the AI's capabilities, we apply policy-based reinforcement learning algorithm to GuanDan. To address the challenges arising from the huge action space, which will significantly impact the performance of policy-based algorithms, we adopt the pre-trained model to facilitate the training process and the achieved AI program manages to achieve a superior performance.
DocPedia: Unleashing the Power of Large Multimodal Model in the Frequency Domain for Versatile Document Understanding
Nov 30, 2023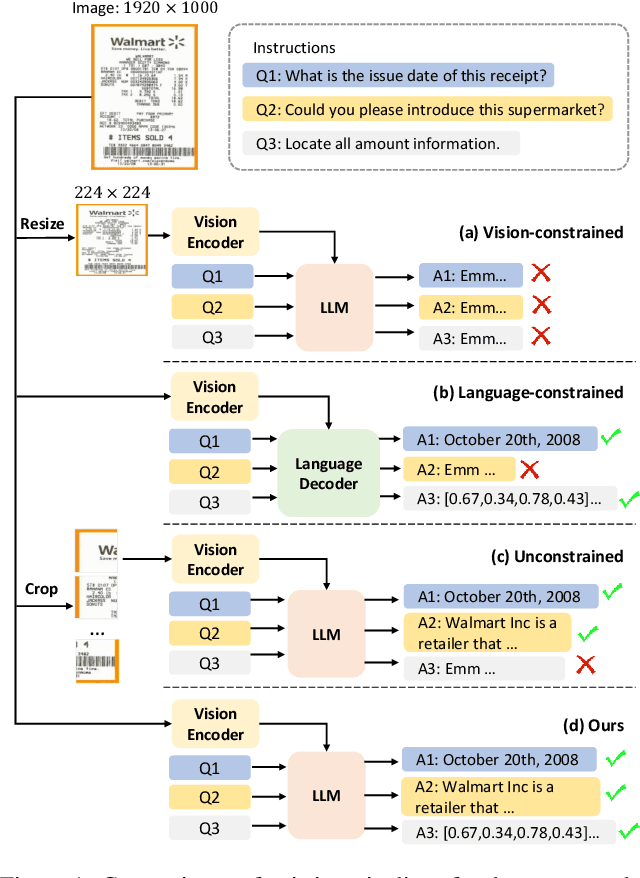
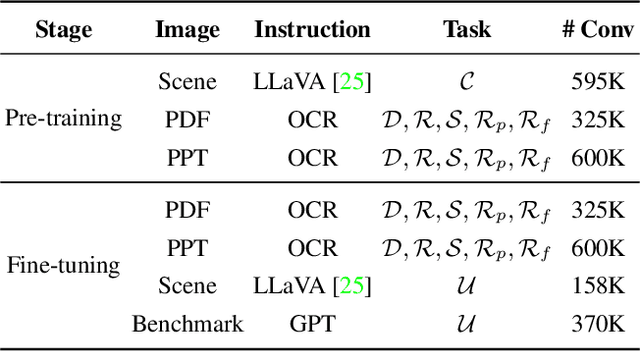
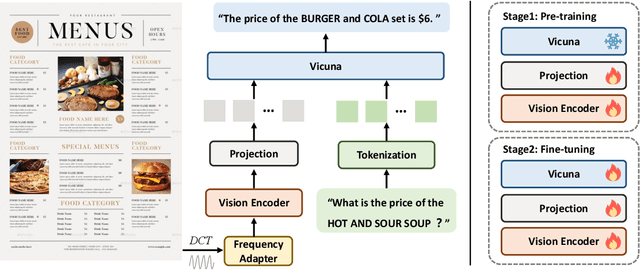
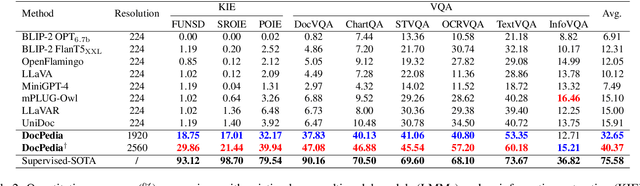
This work presents DocPedia, a novel large multimodal model (LMM) for versatile OCR-free document understanding, capable of parsing images up to 2,560$\times$2,560 resolution. Unlike existing work either struggle with high-resolution documents or give up the large language model thus vision or language ability constrained, our DocPedia directly processes visual input in the frequency domain rather than the pixel space. The unique characteristic enables DocPedia to capture a greater amount of visual and textual information using a limited number of visual tokens. To consistently enhance both perception and comprehension abilities of our model, we develop a dual-stage training strategy and enrich instructions/annotations of all training tasks covering multiple document types. Extensive quantitative and qualitative experiments conducted on various publicly available benchmarks confirm the mutual benefits of jointly learning perception and comprehension tasks. The results provide further evidence of the effectiveness and superior performance of our DocPedia over other methods.
Towards Improving Document Understanding: An Exploration on Text-Grounding via MLLMs
Nov 22, 2023In the field of document understanding, significant advances have been made in the fine-tuning of Multimodal Large Language Models (MLLMs) with instruction-following data. Nevertheless, the potential of text-grounding capability within text-rich scenarios remains underexplored. In this paper, we present a text-grounding document understanding model, termed TGDoc, which addresses this deficiency by enhancing MLLMs with the ability to discern the spatial positioning of text within images. Empirical evidence suggests that text-grounding improves the model's interpretation of textual content, thereby elevating its proficiency in comprehending text-rich images. Specifically, we compile a dataset containing 99K PowerPoint presentations sourced from the internet. We formulate instruction tuning tasks including text detection, recognition, and spotting to facilitate the cohesive alignment between the visual encoder and large language model. Moreover, we curate a collection of text-rich images and prompt the text-only GPT-4 to generate 12K high-quality conversations, featuring textual locations within text-rich scenarios. By integrating text location data into the instructions, TGDoc is adept at discerning text locations during the visual question process. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple text-rich benchmarks, validating the effectiveness of our method.
PersonMAE: Person Re-Identification Pre-Training with Masked AutoEncoders
Nov 08, 2023Pre-training is playing an increasingly important role in learning generic feature representation for Person Re-identification (ReID). We argue that a high-quality ReID representation should have three properties, namely, multi-level awareness, occlusion robustness, and cross-region invariance. To this end, we propose a simple yet effective pre-training framework, namely PersonMAE, which involves two core designs into masked autoencoders to better serve the task of Person Re-ID. 1) PersonMAE generates two regions from the given image with RegionA as the input and \textit{RegionB} as the prediction target. RegionA is corrupted with block-wise masking to mimic common occlusion in ReID and its remaining visible parts are fed into the encoder. 2) Then PersonMAE aims to predict the whole RegionB at both pixel level and semantic feature level. It encourages its pre-trained feature representations with the three properties mentioned above. These properties make PersonMAE compatible with downstream Person ReID tasks, leading to state-of-the-art performance on four downstream ReID tasks, i.e., supervised (holistic and occluded setting), and unsupervised (UDA and USL setting). Notably, on the commonly adopted supervised setting, PersonMAE with ViT-B backbone achieves 79.8% and 69.5% mAP on the MSMT17 and OccDuke datasets, surpassing the previous state-of-the-art by a large margin of +8.0 mAP, and +5.3 mAP, respectively.
Progressive Recurrent Network for Shadow Removal
Nov 01, 2023Single-image shadow removal is a significant task that is still unresolved. Most existing deep learning-based approaches attempt to remove the shadow directly, which can not deal with the shadow well. To handle this issue, we consider removing the shadow in a coarse-to-fine fashion and propose a simple but effective Progressive Recurrent Network (PRNet). The network aims to remove the shadow progressively, enabing us to flexibly adjust the number of iterations to strike a balance between performance and time. Our network comprises two parts: shadow feature extraction and progressive shadow removal. Specifically, the first part is a shallow ResNet which constructs the representations of the input shadow image on its original size, preventing the loss of high-frequency details caused by the downsampling operation. The second part has two critical components: the re-integration module and the update module. The proposed re-integration module can fully use the outputs of the previous iteration, providing input for the update module for further shadow removal. In this way, the proposed PRNet makes the whole process more concise and only uses 29% network parameters than the best published method. Extensive experiments on the three benchmarks, ISTD, ISTD+, and SRD, demonstrate that our method can effectively remove shadows and achieve superior performance.