 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongzhi Yin
Reinforcement Learning-enhanced Shared-account Cross-domain Sequential Recommendation
Jun 16, 2022
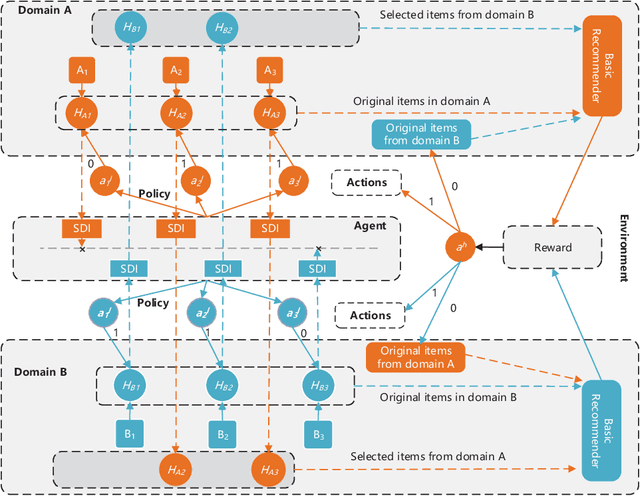
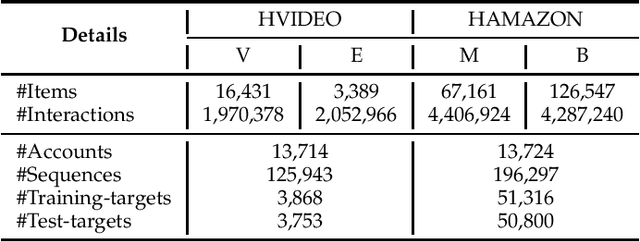
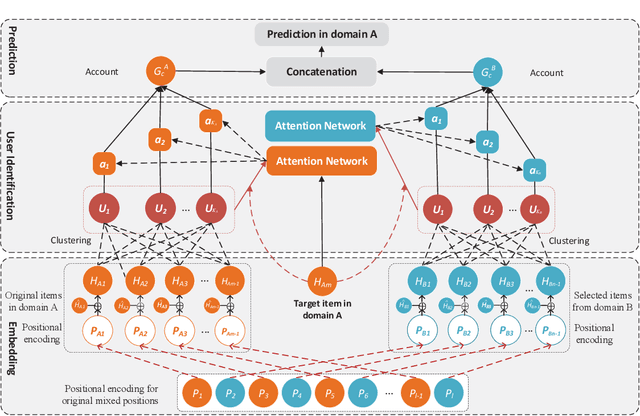
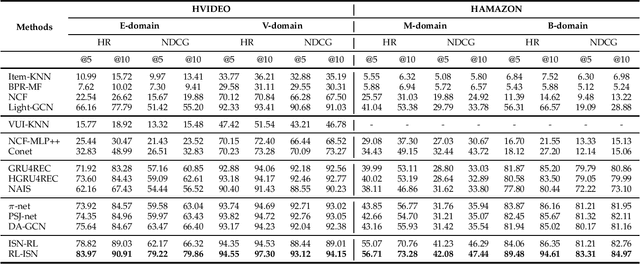
Shared-account Cross-domain Sequential Recommendation (SCSR) is an emerging yet challenging task that simultaneously considers the shared-account and cross-domain characteristics in the sequential recommendation. Existing works on SCSR are mainly based on Recurrent Neural Network (RNN) and Graph Neural Network (GNN) but they ignore the fact that although multiple users share a single account, it is mainly occupied by one user at a time. This observation motivates us to learn a more accurate user-specific account representation by attentively focusing on its recent behaviors. Furthermore, though existing works endow lower weights to irrelevant interactions, they may still dilute the domain information and impede the cross-domain recommendation. To address the above issues, we propose a reinforcement learning-based solution, namely RL-ISN, which consists of a basic cross-domain recommender and a reinforcement learning-based domain filter. Specifically, to model the account representation in the shared-account scenario, the basic recommender first clusters users' mixed behaviors as latent users, and then leverages an attention model over them to conduct user identification. To reduce the impact of irrelevant domain information, we formulate the domain filter as a hierarchical reinforcement learning task, where a high-level task is utilized to decide whether to revise the whole transferred sequence or not, and if it does, a low-level task is further performed to determine whether to remove each interaction within it or not. To evaluate the performance of our solution, we conduct extensive experiments on two real-world datasets, and the experimental results demonstrate the superiority of our RL-ISN method compared with the state-of-the-art recommendation methods.
Time Interval-enhanced Graph Neural Network for Shared-account Cross-domain Sequential Recommendation
Jun 16, 2022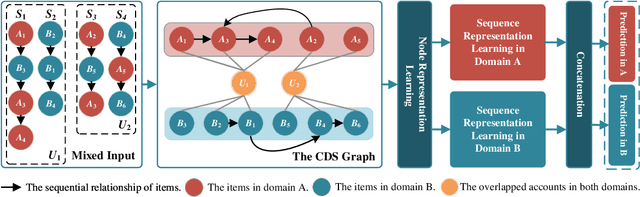
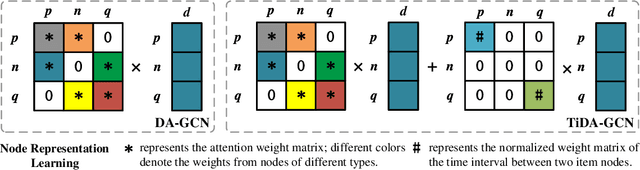
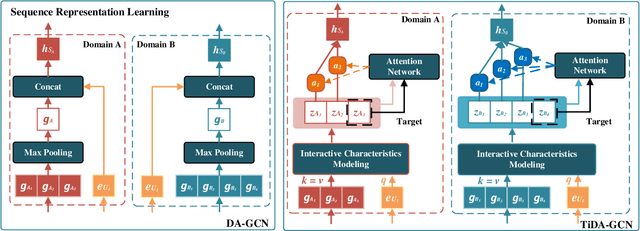
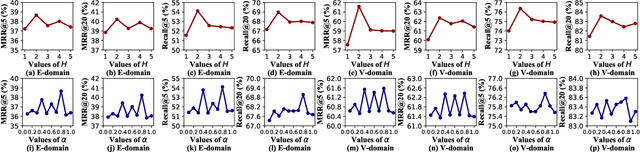
Shared-account Cross-domain Sequential Recommendation (SCSR) task aims to recommend the next item via leveraging the mixed user behaviors in multiple domains. It is gaining immense research attention as more and more users tend to sign up on different platforms and share accounts with others to access domain-specific services. Existing works on SCSR mainly rely on mining sequential patterns via Recurrent Neural Network (RNN)-based models, which suffer from the following limitations: 1) RNN-based methods overwhelmingly target discovering sequential dependencies in single-user behaviors. They are not expressive enough to capture the relationships among multiple entities in SCSR. 2) All existing methods bridge two domains via knowledge transfer in the latent space, and ignore the explicit cross-domain graph structure. 3) None existing studies consider the time interval information among items, which is essential in the sequential recommendation for characterizing different items and learning discriminative representations for them. In this work, we propose a new graph-based solution, namely TiDA-GCN, to address the above challenges. Specifically, we first link users and items in each domain as a graph. Then, we devise a domain-aware graph convolution network to learn userspecific node representations. To fully account for users' domainspecific preferences on items, two effective attention mechanisms are further developed to selectively guide the message passing process. Moreover, to further enhance item- and account-level representation learning, we incorporate the time interval into the message passing, and design an account-aware self-attention module for learning items' interactive characteristics. Experiments demonstrate the superiority of our proposed method from various aspects.
Comprehensive Privacy Analysis on Federated Recommender System against Attribute Inference Attacks
May 24, 2022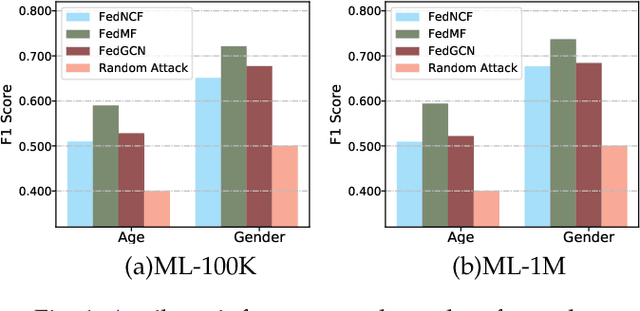

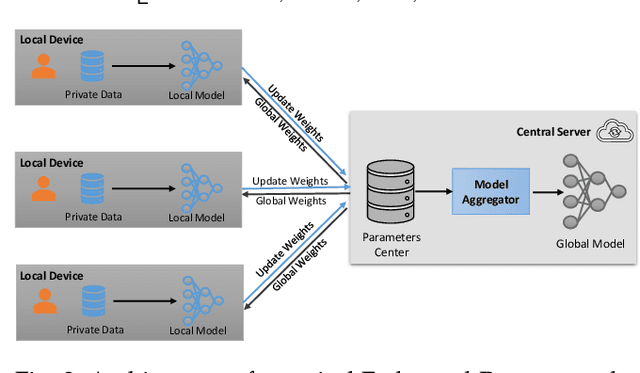
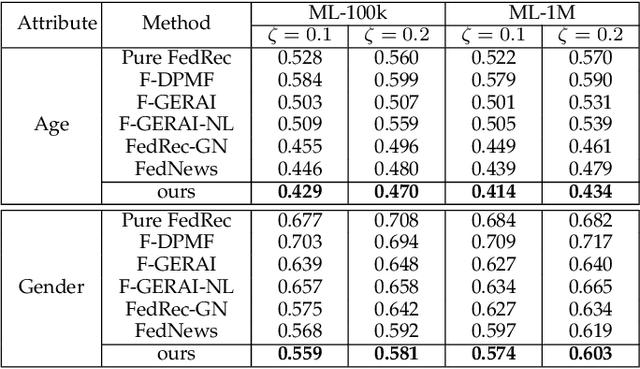
In recent years, recommender systems are crucially important for the delivery of personalized services that satisfy users' preferences. With personalized recommendation services, users can enjoy a variety of recommendations such as movies, books, ads, restaurants, and more. Despite the great benefits, personalized recommendations typically require the collection of personal data for user modelling and analysis, which can make users susceptible to attribute inference attacks. Specifically, the vulnerability of existing centralized recommenders under attribute inference attacks leaves malicious attackers a backdoor to infer users' private attributes, as the systems remember information of their training data (i.e., interaction data and side information). An emerging practice is to implement recommender systems in the federated setting, which enables all user devices to collaboratively learn a shared global recommender while keeping all the training data on device. However, the privacy issues in federated recommender systems have been rarely explored. In this paper, we first design a novel attribute inference attacker to perform a comprehensive privacy analysis of the state-of-the-art federated recommender models. The experimental results show that the vulnerability of each model component against attribute inference attack is varied, highlighting the need for new defense approaches. Therefore, we propose a novel adaptive privacy-preserving approach to protect users' sensitive data in the presence of attribute inference attacks and meanwhile maximize the recommendation accuracy. Extensive experimental results on two real-world datasets validate the superior performance of our model on both recommendation effectiveness and resistance to inference attacks.
Detecting Rumours with Latency Guarantees using Massive Streaming Data
May 13, 2022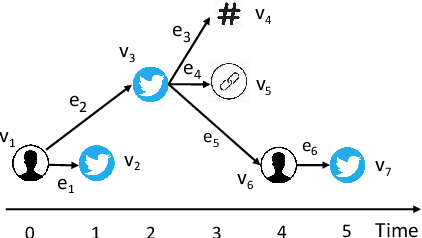

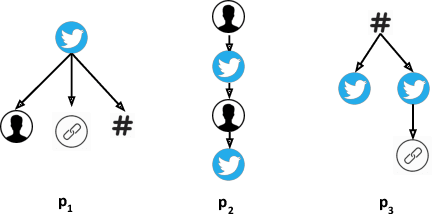
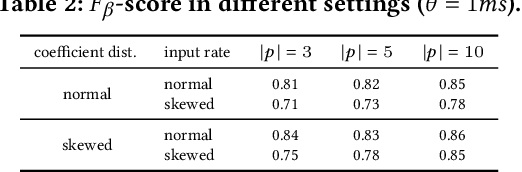
Today's social networks continuously generate massive streams of data, which provide a valuable starting point for the detection of rumours as soon as they start to propagate. However, rumour detection faces tight latency bounds, which cannot be met by contemporary algorithms, given the sheer volume of high-velocity streaming data emitted by social networks. Hence, in this paper, we argue for best-effort rumour detection that detects most rumours quickly rather than all rumours with a high delay. To this end, we combine techniques for efficient, graph-based matching of rumour patterns with effective load shedding that discards some of the input data while minimising the loss in accuracy. Experiments with large-scale real-world datasets illustrate the robustness of our approach in terms of runtime performance and detection accuracy under diverse streaming conditions.
Spatial-Temporal Meta-path Guided Explainable Crime Prediction
May 04, 2022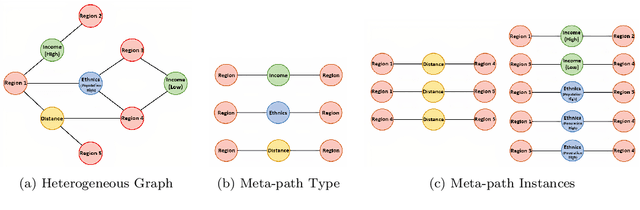

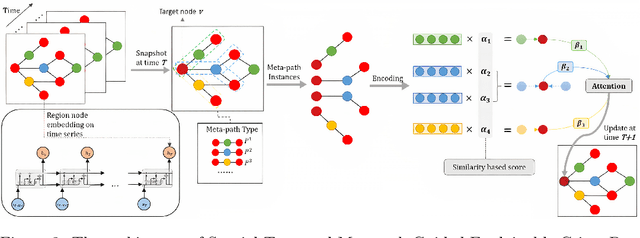
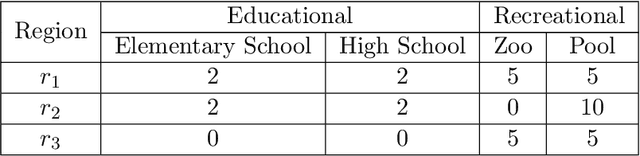
Exposure to crime and violence can harm individuals' quality of life and the economic growth of communities. In light of the rapid development in machine learning, there is a rise in the need to explore automated solutions to prevent crimes. With the increasing availability of both fine-grained urban and public service data, there is a recent surge in fusing such cross-domain information to facilitate crime prediction. By capturing the information about social structure, environment, and crime trends, existing machine learning predictive models have explored the dynamic crime patterns from different views. However, these approaches mostly convert such multi-source knowledge into implicit and latent representations (e.g., learned embeddings of districts), making it still a challenge to investigate the impacts of explicit factors for the occurrences of crimes behind the scenes. In this paper, we present a Spatial-Temporal Metapath guided Explainable Crime prediction (STMEC) framework to capture dynamic patterns of crime behaviours and explicitly characterize how the environmental and social factors mutually interact to produce the forecasts. Extensive experiments show the superiority of STMEC compared with other advanced spatiotemporal models, especially in predicting felonies (e.g., robberies and assaults with dangerous weapons).
On-Device Next-Item Recommendation with Self-Supervised Knowledge Distillation
Apr 23, 2022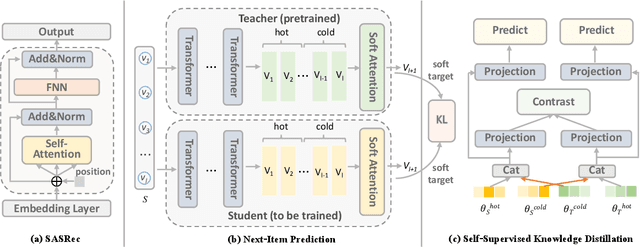
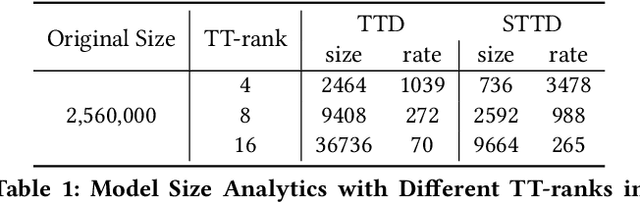
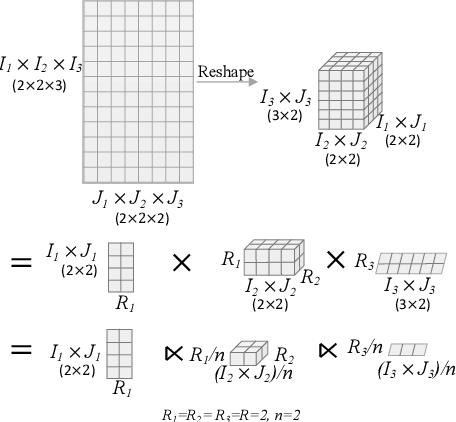

Modern recommender systems operate in a fully server-based fashion. To cater to millions of users, the frequent model maintaining and the high-speed processing for concurrent user requests are required, which comes at the cost of a huge carbon footprint. Meanwhile, users need to upload their behavior data even including the immediate environmental context to the server, raising the public concern about privacy. On-device recommender systems circumvent these two issues with cost-conscious settings and local inference. However, due to the limited memory and computing resources, on-device recommender systems are confronted with two fundamental challenges: (1) how to reduce the size of regular models to fit edge devices? (2) how to retain the original capacity? Previous research mostly adopts tensor decomposition techniques to compress the regular recommendation model with limited compression ratio so as to avoid drastic performance degradation. In this paper, we explore ultra-compact models for next-item recommendation, by loosing the constraint of dimensionality consistency in tensor decomposition. Meanwhile, to compensate for the capacity loss caused by compression, we develop a self-supervised knowledge distillation framework which enables the compressed model (student) to distill the essential information lying in the raw data, and improves the long-tail item recommendation through an embedding-recombination strategy with the original model (teacher). The extensive experiments on two benchmarks demonstrate that, with 30x model size reduction, the compressed model almost comes with no accuracy loss, and even outperforms its uncompressed counterpart in most cases.
Single-shot Embedding Dimension Search in Recommender System
Apr 15, 2022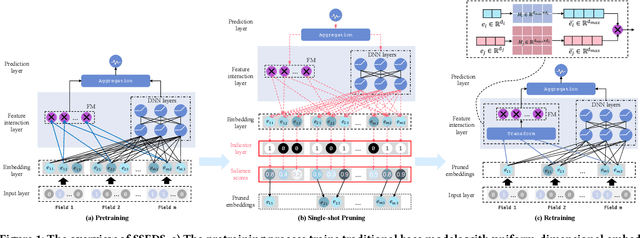
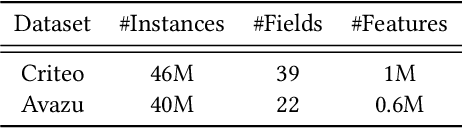
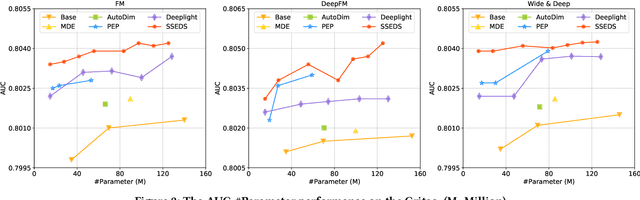
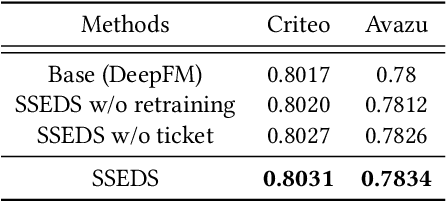
As a crucial component of most modern deep recommender systems, feature embedding maps high-dimensional sparse user/item features into low-dimensional dense embeddings. However, these embeddings are usually assigned a unified dimension, which suffers from the following issues: (1) high memory usage and computation cost. (2) sub-optimal performance due to inferior dimension assignments. In order to alleviate the above issues, some works focus on automated embedding dimension search by formulating it as hyper-parameter optimization or embedding pruning problems. However, they either require well-designed search space for hyperparameters or need time-consuming optimization procedures. In this paper, we propose a Single-Shot Embedding Dimension Search method, called SSEDS, which can efficiently assign dimensions for each feature field via a single-shot embedding pruning operation while maintaining the recommendation accuracy of the model. Specifically, it introduces a criterion for identifying the importance of each embedding dimension for each feature field. As a result, SSEDS could automatically obtain mixed-dimensional embeddings by explicitly reducing redundant embedding dimensions based on the corresponding dimension importance ranking and the predefined parameter budget. Furthermore, the proposed SSEDS is model-agnostic, meaning that it could be integrated into different base recommendation models. The extensive offline experiments are conducted on two widely used public datasets for CTR prediction tasks, and the results demonstrate that SSEDS can still achieve strong recommendation performance even if it has reduced 90\% parameters. Moreover, SSEDS has also been deployed on the WeChat Subscription platform for practical recommendation services. The 7-day online A/B test results show that SSEDS can significantly improve the performance of the online recommendation model.
Thinking inside The Box: Learning Hypercube Representations for Group Recommendation
Apr 06, 2022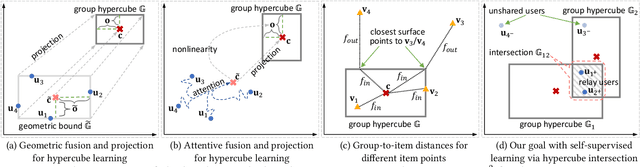
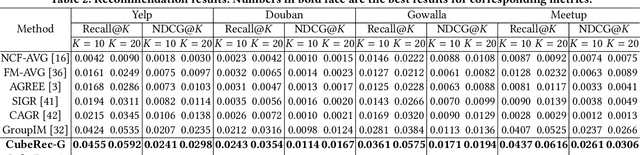
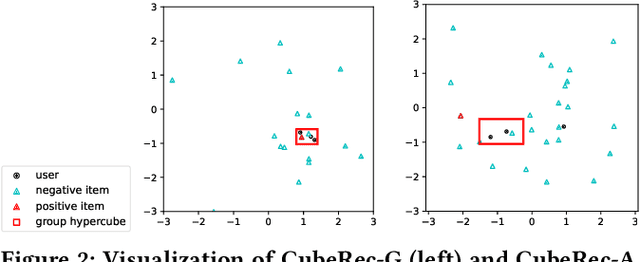
As a step beyond traditional personalized recommendation, group recommendation is the task of suggesting items that can satisfy a group of users. In group recommendation, the core is to design preference aggregation functions to obtain a quality summary of all group members' preferences. Such user and group preferences are commonly represented as points in the vector space (i.e., embeddings), where multiple user embeddings are compressed into one to facilitate ranking for group-item pairs. However, the resulted group representations, as points, lack adequate flexibility and capacity to account for the multi-faceted user preferences. Also, the point embedding-based preference aggregation is a less faithful reflection of a group's decision-making process, where all users have to agree on a certain value in each embedding dimension instead of a negotiable interval. In this paper, we propose a novel representation of groups via the notion of hypercubes, which are subspaces containing innumerable points in the vector space. Specifically, we design the hypercube recommender (CubeRec) to adaptively learn group hypercubes from user embeddings with minimal information loss during preference aggregation, and to leverage a revamped distance metric to measure the affinity between group hypercubes and item points. Moreover, to counteract the long-standing issue of data sparsity in group recommendation, we make full use of the geometric expressiveness of hypercubes and innovatively incorporate self-supervision by intersecting two groups. Experiments on four real-world datasets have validated the superiority of CubeRec over state-of-the-art baselines.
Diverse Preference Augmentation with Multiple Domains for Cold-start Recommendations
Apr 01, 2022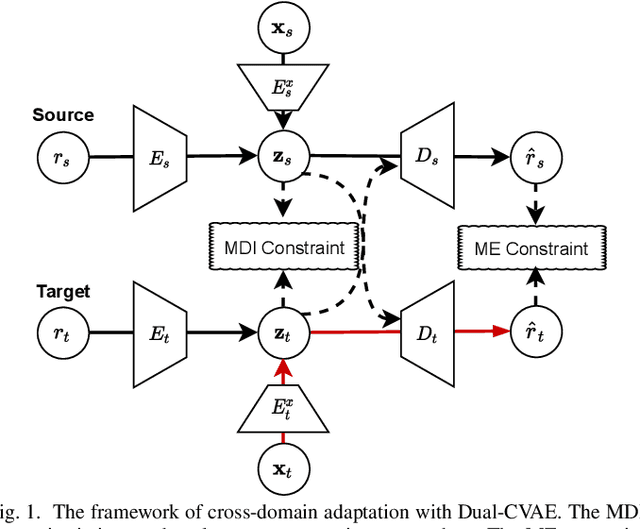
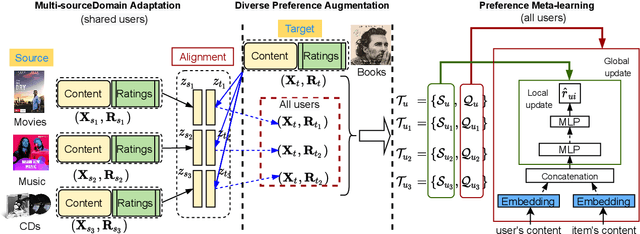
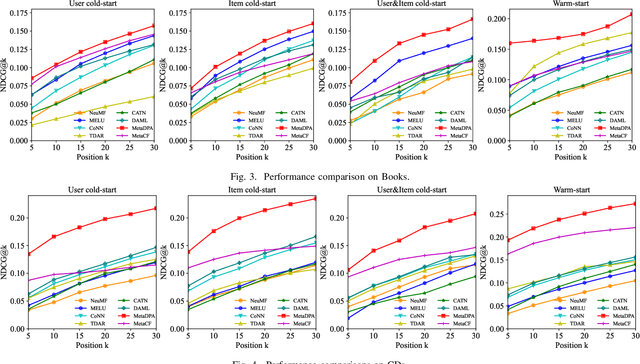
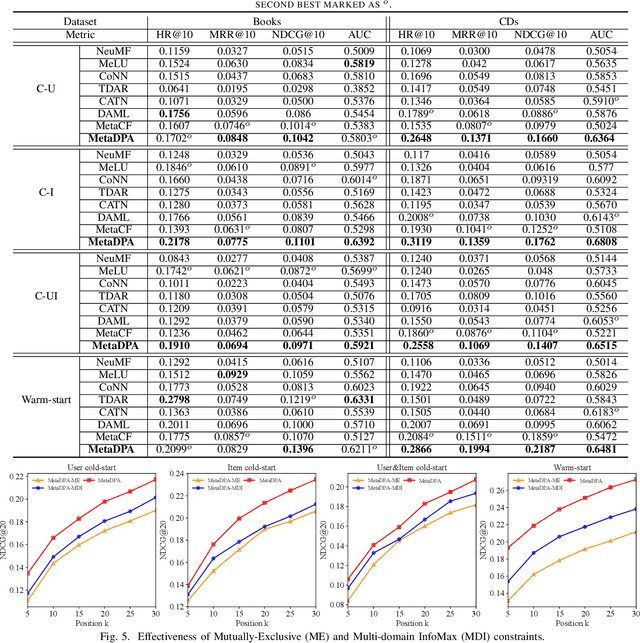
Cold-start issues have been more and more challenging for providing accurate recommendations with the fast increase of users and items. Most existing approaches attempt to solve the intractable problems via content-aware recommendations based on auxiliary information and/or cross-domain recommendations with transfer learning. Their performances are often constrained by the extremely sparse user-item interactions, unavailable side information, or very limited domain-shared users. Recently, meta-learners with meta-augmentation by adding noises to labels have been proven to be effective to avoid overfitting and shown good performance on new tasks. Motivated by the idea of meta-augmentation, in this paper, by treating a user's preference over items as a task, we propose a so-called Diverse Preference Augmentation framework with multiple source domains based on meta-learning (referred to as MetaDPA) to i) generate diverse ratings in a new domain of interest (known as target domain) to handle overfitting on the case of sparse interactions, and to ii) learn a preference model in the target domain via a meta-learning scheme to alleviate cold-start issues. Specifically, we first conduct multi-source domain adaptation by dual conditional variational autoencoders and impose a Multi-domain InfoMax (MDI) constraint on the latent representations to learn domain-shared and domain-specific preference properties. To avoid overfitting, we add a Mutually-Exclusive (ME) constraint on the output of decoders to generate diverse ratings given content data. Finally, these generated diverse ratings and the original ratings are introduced into the meta-training procedure to learn a preference meta-learner, which produces good generalization ability on cold-start recommendation tasks. Experiments on real-world datasets show our proposed MetaDPA clearly outperforms the current state-of-the-art baselines.