 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongyao Tang
HyAR: Addressing Discrete-Continuous Action Reinforcement Learning via Hybrid Action Representation
Sep 12, 2021
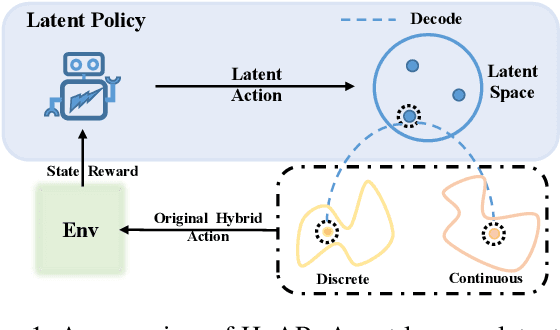
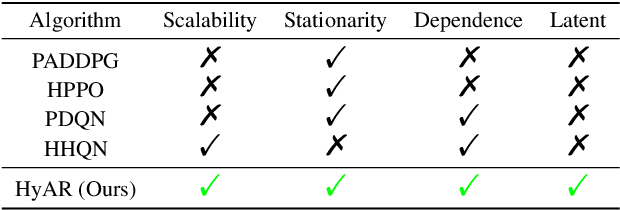
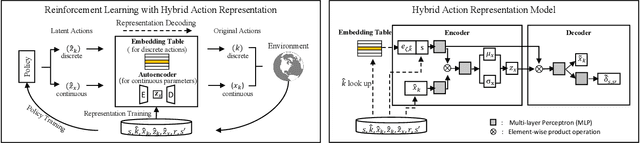
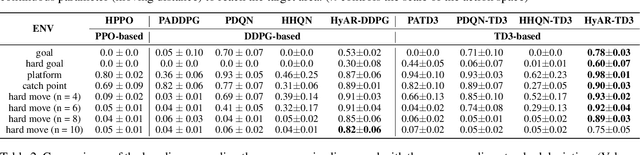
Discrete-continuous hybrid action space is a natural setting in many practical problems, such as robot control and game AI. However, most previous Reinforcement Learning (RL) works only demonstrate the success in controlling with either discrete or continuous action space, while seldom take into account the hybrid action space. One naive way to address hybrid action RL is to convert the hybrid action space into a unified homogeneous action space by discretization or continualization, so that conventional RL algorithms can be applied. However, this ignores the underlying structure of hybrid action space and also induces the scalability issue and additional approximation difficulties, thus leading to degenerated results. In this paper, we propose Hybrid Action Representation (HyAR) to learn a compact and decodable latent representation space for the original hybrid action space. HyAR constructs the latent space and embeds the dependence between discrete action and continuous parameter via an embedding table and conditional Variantional Auto-Encoder (VAE). To further improve the effectiveness, the action representation is trained to be semantically smooth through unsupervised environmental dynamics prediction. Finally, the agent then learns its policy with conventional DRL algorithms in the learned representation space and interacts with the environment by decoding the hybrid action embeddings to the original action space. We evaluate HyAR in a variety of environments with discrete-continuous action space. The results demonstrate the superiority of HyAR when compared with previous baselines, especially for high-dimensional action spaces.
Addressing Action Oscillations through Learning Policy Inertia
Mar 03, 2021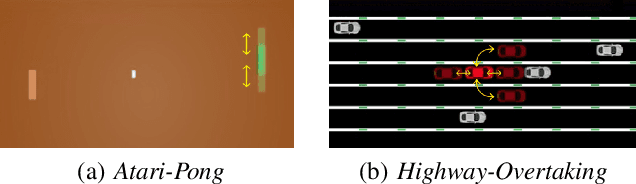
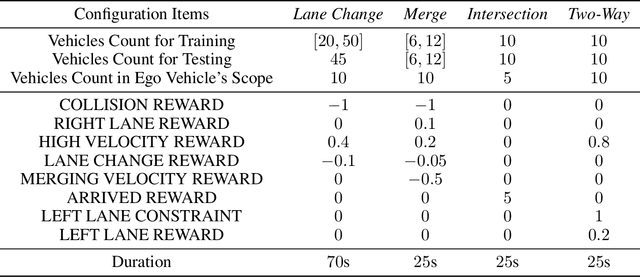
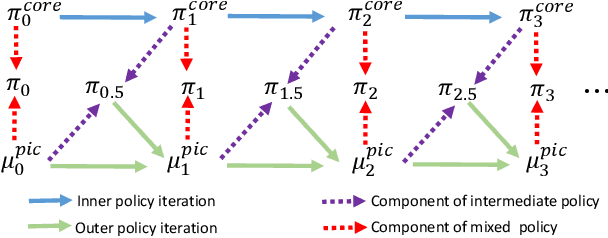

Deep reinforcement learning (DRL) algorithms have been demonstrated to be effective in a wide range of challenging decision making and control tasks. However, these methods typically suffer from severe action oscillations in particular in discrete action setting, which means that agents select different actions within consecutive steps even though states only slightly differ. This issue is often neglected since the policy is usually evaluated by its cumulative rewards only. Action oscillation strongly affects the user experience and can even cause serious potential security menace especially in real-world domains with the main concern of safety, such as autonomous driving. To this end, we introduce Policy Inertia Controller (PIC) which serves as a generic plug-in framework to off-the-shelf DRL algorithms, to enables adaptive trade-off between the optimality and smoothness of the learned policy in a formal way. We propose Nested Policy Iteration as a general training algorithm for PIC-augmented policy which ensures monotonically non-decreasing updates under some mild conditions. Further, we derive a practical DRL algorithm, namely Nested Soft Actor-Critic. Experiments on a collection of autonomous driving tasks and several Atari games suggest that our approach demonstrates substantial oscillation reduction in comparison to a range of commonly adopted baselines with almost no performance degradation.
Foresee then Evaluate: Decomposing Value Estimation with Latent Future Prediction
Mar 03, 2021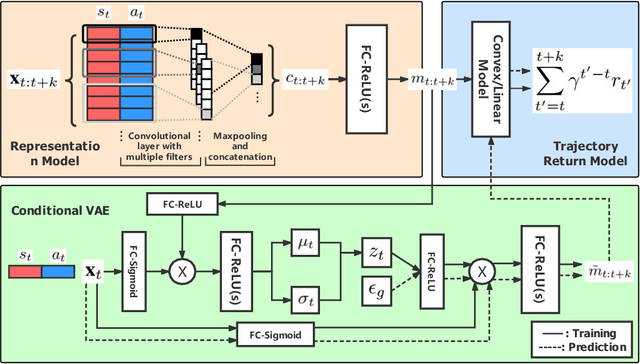

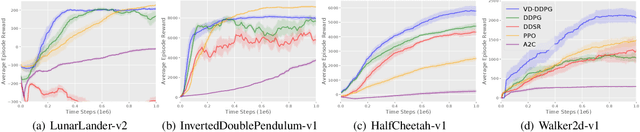
Value function is the central notion of Reinforcement Learning (RL). Value estimation, especially with function approximation, can be challenging since it involves the stochasticity of environmental dynamics and reward signals that can be sparse and delayed in some cases. A typical model-free RL algorithm usually estimates the values of a policy by Temporal Difference (TD) or Monte Carlo (MC) algorithms directly from rewards, without explicitly taking dynamics into consideration. In this paper, we propose Value Decomposition with Future Prediction (VDFP), providing an explicit two-step understanding of the value estimation process: 1) first foresee the latent future, 2) and then evaluate it. We analytically decompose the value function into a latent future dynamics part and a policy-independent trajectory return part, inducing a way to model latent dynamics and returns separately in value estimation. Further, we derive a practical deep RL algorithm, consisting of a convolutional model to learn compact trajectory representation from past experiences, a conditional variational auto-encoder to predict the latent future dynamics and a convex return model that evaluates trajectory representation. In experiments, we empirically demonstrate the effectiveness of our approach for both off-policy and on-policy RL in several OpenAI Gym continuous control tasks as well as a few challenging variants with delayed reward.
What About Taking Policy as Input of Value Function: Policy-extended Value Function Approximator
Oct 19, 2020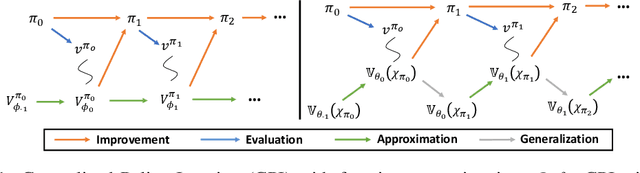

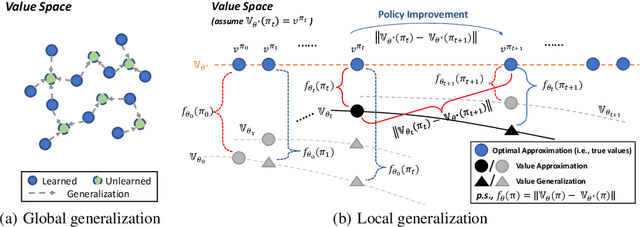
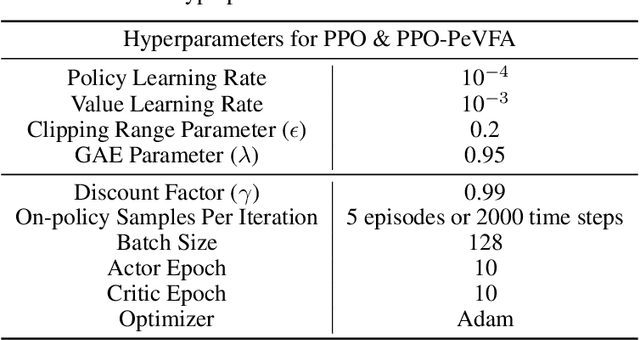
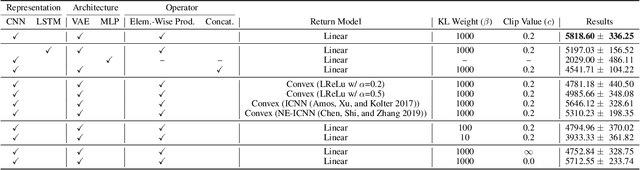
The value function lies in the heart of Reinforcement Learning (RL), which defines the long-term evaluation of a policy in a given state. In this paper, we propose Policy-extended Value Function Approximator (PeVFA) which extends the conventional value to be not only a function of state but also an explicit policy representation. Such an extension enables PeVFA to preserve values of multiple policies in contrast to a conventional one with limited capacity for only one policy, inducing the new characteristic of \emph{value generalization among policies}. From both the theoretical and empirical lens, we study value generalization along the policy improvement path (called local generalization), from which we derive a new form of Generalized Policy Iteration with PeVFA to improve the conventional learning process. Besides, we propose a framework to learn the representation of an RL policy, studying several different approaches to learn an effective policy representation from policy network parameters and state-action pairs through contrastive learning and action prediction. In our experiments, Proximal Policy Optimization (PPO) with PeVFA significantly outperforms its vanilla counterpart in MuJoCo continuous control tasks, demonstrating the effectiveness of value generalization offered by PeVFA and policy representation learning.
Towards Effective Context for Meta-Reinforcement Learning: an Approach based on Contrastive Learning
Oct 07, 2020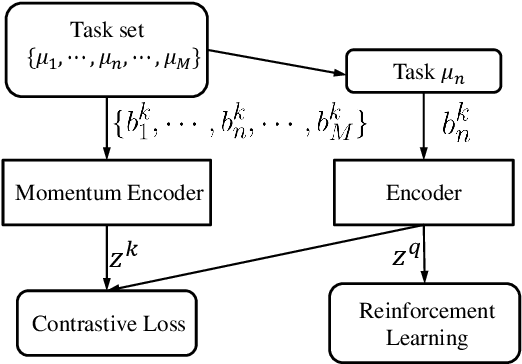

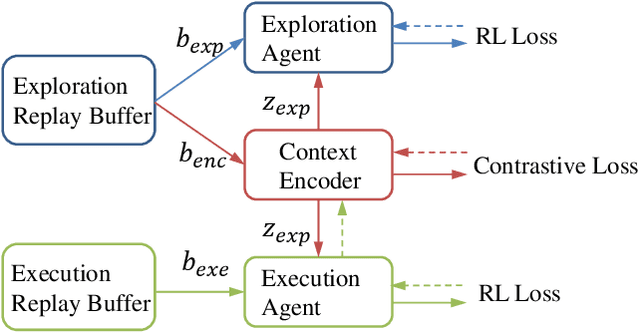
Context, the embedding of previous collected trajectories, is a powerful construct for Meta-Reinforcement Learning (Meta-RL) algorithms. By conditioning on an effective context, Meta-RL policies can easily generalize to new tasks within a few adaptation steps. We argue that improving the quality of context involves answering two questions: 1. How to train a compact and sufficient encoder that can embed the task-specific information contained in prior trajectories? 2. How to collect informative trajectories of which the corresponding context reflects the specification of tasks? To this end, we propose a novel Meta-RL framework called CCM (Contrastive learning augmented Context-based Meta-RL). We first focus on the contrastive nature behind different tasks and leverage it to train a compact and sufficient context encoder. Further, we train a separate exploration policy and theoretically derive a new information-gain-based objective which aims to collect informative trajectories in a few steps. Empirically, we evaluate our approaches on common benchmarks as well as several complex sparse-reward environments. The experimental results show that CCM outperforms state-of-the-art algorithms by addressing previously mentioned problems respectively.
KoGuN: Accelerating Deep Reinforcement Learning via Integrating Human Suboptimal Knowledge
Feb 18, 2020



Reinforcement learning agents usually learn from scratch, which requires a large number of interactions with the environment. This is quite different from the learning process of human. When faced with a new task, human naturally have the common sense and use the prior knowledge to derive an initial policy and guide the learning process afterwards. Although the prior knowledge may be not fully applicable to the new task, the learning process is significantly sped up since the initial policy ensures a quick-start of learning and intermediate guidance allows to avoid unnecessary exploration. Taking this inspiration, we propose knowledge guided policy network (KoGuN), a novel framework that combines human prior suboptimal knowledge with reinforcement learning. Our framework consists of a fuzzy rule controller to represent human knowledge and a refine module to fine-tune suboptimal prior knowledge. The proposed framework is end-to-end and can be combined with existing policy-based reinforcement learning algorithm. We conduct experiments on both discrete and continuous control tasks. The empirical results show that our approach, which combines human suboptimal knowledge and RL, achieves significant improvement on learning efficiency of flat RL algorithms, even with very low-performance human prior knowledge.
Efficient meta reinforcement learning via meta goal generation
Nov 10, 2019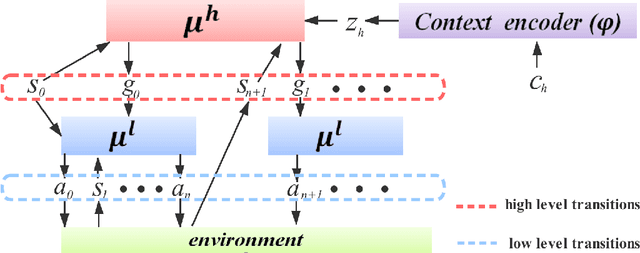
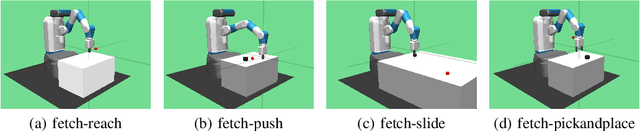
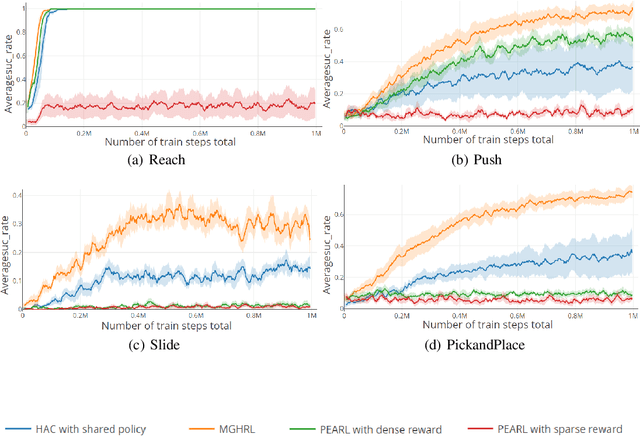
Meta reinforcement learning (meta-RL) is able to accelerate the acquisition of new tasks by learning from past experience. Current meta-RL methods usually learn to adapt to new tasks by directly optimizing the parameters of policies over primitive actions. However, for complex tasks which requires sophisticated control strategies, it would be quite inefficient to to directly learn such a meta-policy. Moreover, this problem can become more severe and even fail in spare reward settings, which is quite common in practice. To this end, we propose a new meta-RL algorithm called meta goal-generation for hierarchical RL (MGHRL) by leveraging hierarchical actor-critic framework. Instead of directly generate policies over primitive actions for new tasks, MGHRL learns to generate high-level meta strategies over subgoals given past experience and leaves the rest of how to achieve subgoals as independent RL subtasks. Our empirical results on several challenging simulated robotics environments show that our method enables more efficient and effective meta-learning from past experience and outperforms state-of-the-art meta-RL and Hierarchical-RL methods in sparse reward settings.