 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHisham Cholakkal
On the Robustness of 3D Object Detectors
Jul 20, 2022

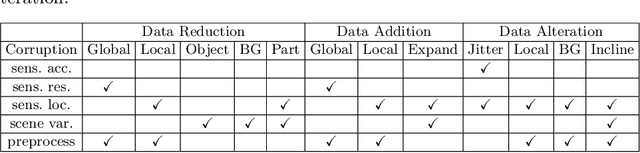

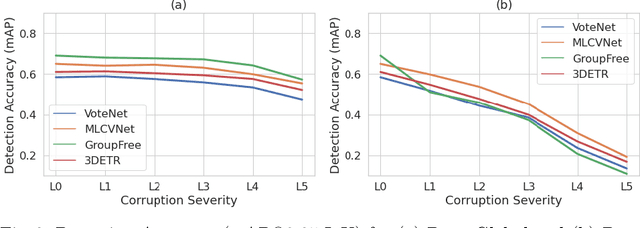
In recent years, significant progress has been achieved for 3D object detection on point clouds thanks to the advances in 3D data collection and deep learning techniques. Nevertheless, 3D scenes exhibit a lot of variations and are prone to sensor inaccuracies as well as information loss during pre-processing. Thus, it is crucial to design techniques that are robust against these variations. This requires a detailed analysis and understanding of the effect of such variations. This work aims to analyze and benchmark popular point-based 3D object detectors against several data corruptions. To the best of our knowledge, we are the first to investigate the robustness of point-based 3D object detectors. To this end, we design and evaluate corruptions that involve data addition, reduction, and alteration. We further study the robustness of different modules against local and global variations. Our experimental results reveal several intriguing findings. For instance, we show that methods that integrate Transformers at a patch or object level lead to increased robustness, compared to using Transformers at the point level.
EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications
Jun 21, 2022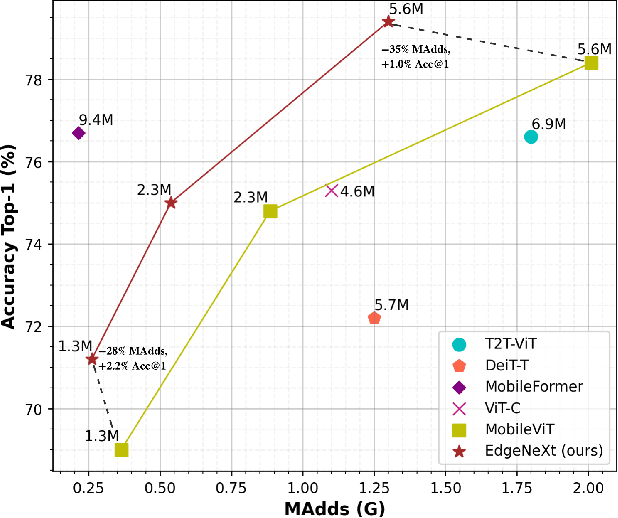
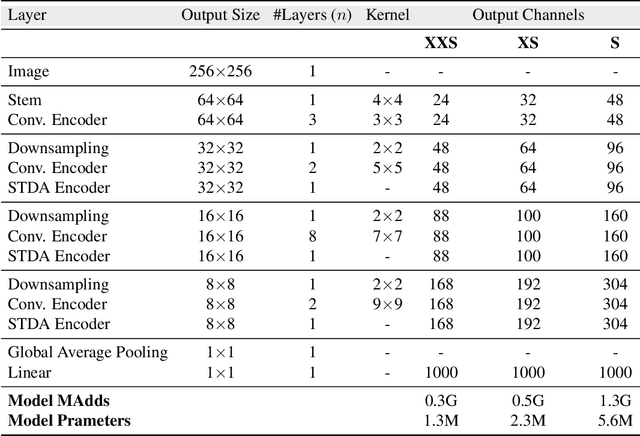
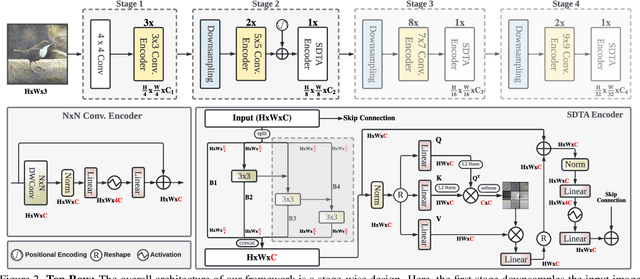
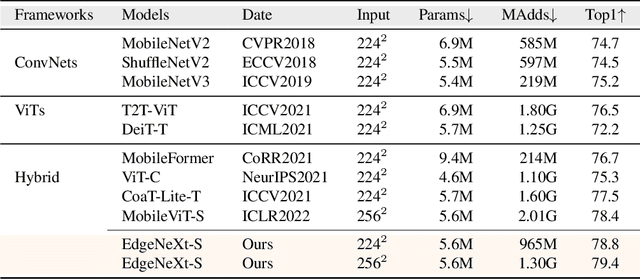
In the pursuit of achieving ever-increasing accuracy, large and complex neural networks are usually developed. Such models demand high computational resources and therefore cannot be deployed on edge devices. It is of great interest to build resource-efficient general purpose networks due to their usefulness in several application areas. In this work, we strive to effectively combine the strengths of both CNN and Transformer models and propose a new efficient hybrid architecture EdgeNeXt. Specifically in EdgeNeXt, we introduce split depth-wise transpose attention (SDTA) encoder that splits input tensors into multiple channel groups and utilizes depth-wise convolution along with self-attention across channel dimensions to implicitly increase the receptive field and encode multi-scale features. Our extensive experiments on classification, detection and segmentation tasks, reveal the merits of the proposed approach, outperforming state-of-the-art methods with comparatively lower compute requirements. Our EdgeNeXt model with 1.3M parameters achieves 71.2\% top-1 accuracy on ImageNet-1K, outperforming MobileViT with an absolute gain of 2.2\% with 28\% reduction in FLOPs. Further, our EdgeNeXt model with 5.6M parameters achieves 79.4\% top-1 accuracy on ImageNet-1K. The code and models are publicly available at https://t.ly/_Vu9.
PSTR: End-to-End One-Step Person Search With Transformers
Apr 07, 2022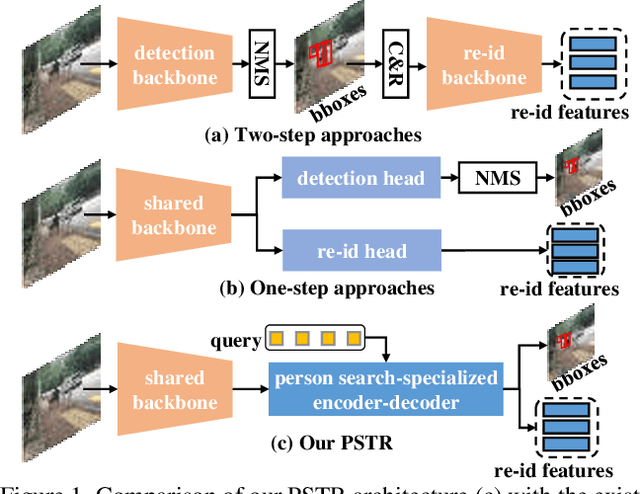
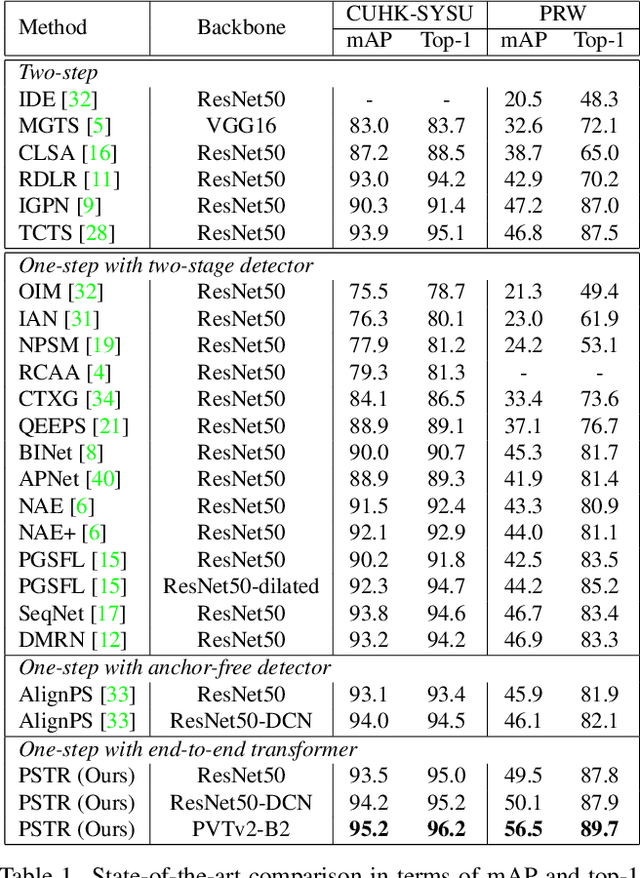
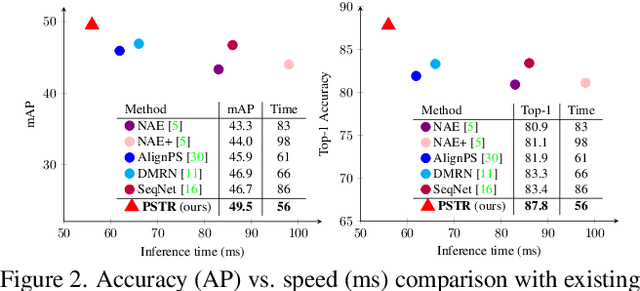
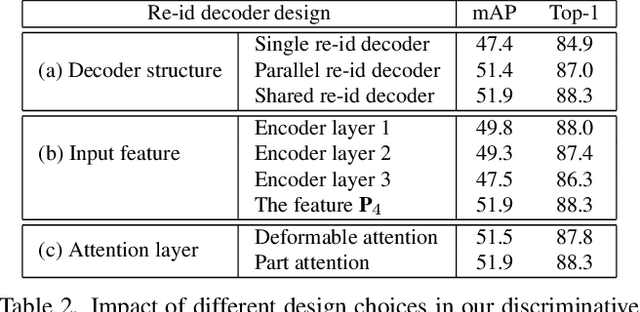
We propose a novel one-step transformer-based person search framework, PSTR, that jointly performs person detection and re-identification (re-id) in a single architecture. PSTR comprises a person search-specialized (PSS) module that contains a detection encoder-decoder for person detection along with a discriminative re-id decoder for person re-id. The discriminative re-id decoder utilizes a multi-level supervision scheme with a shared decoder for discriminative re-id feature learning and also comprises a part attention block to encode relationship between different parts of a person. We further introduce a simple multi-scale scheme to support re-id across person instances at different scales. PSTR jointly achieves the diverse objectives of object-level recognition (detection) and instance-level matching (re-id). To the best of our knowledge, we are the first to propose an end-to-end one-step transformer-based person search framework. Experiments are performed on two popular benchmarks: CUHK-SYSU and PRW. Our extensive ablations reveal the merits of the proposed contributions. Further, the proposed PSTR sets a new state-of-the-art on both benchmarks. On the challenging PRW benchmark, PSTR achieves a mean average precision (mAP) score of 56.5%. The source code is available at \url{https://github.com/JialeCao001/PSTR}.
Video Instance Segmentation via Multi-scale Spatio-temporal Split Attention Transformer
Mar 24, 2022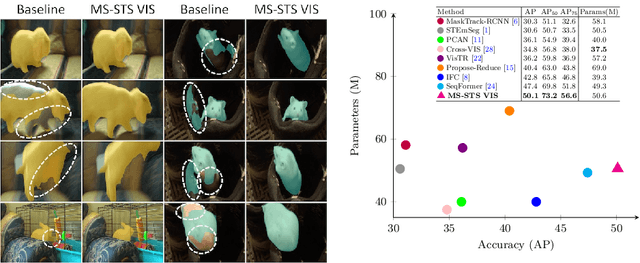
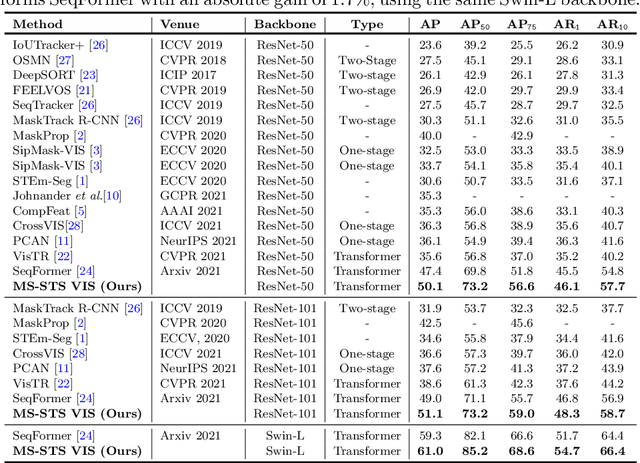
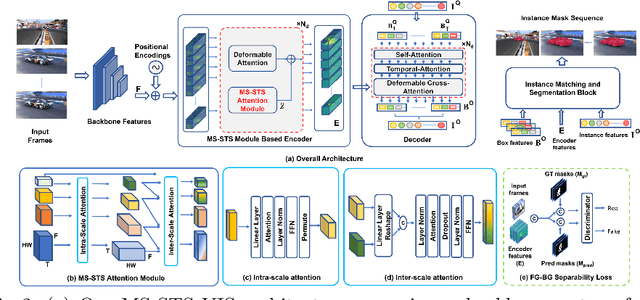
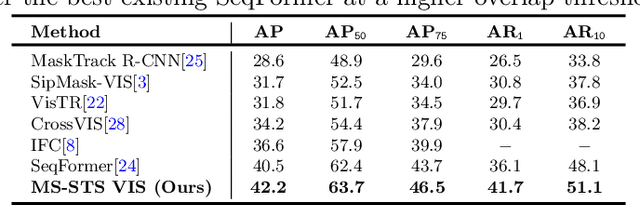
State-of-the-art transformer-based video instance segmentation (VIS) approaches typically utilize either single-scale spatio-temporal features or per-frame multi-scale features during the attention computations. We argue that such an attention computation ignores the multi-scale spatio-temporal feature relationships that are crucial to tackle target appearance deformations in videos. To address this issue, we propose a transformer-based VIS framework, named MS-STS VIS, that comprises a novel multi-scale spatio-temporal split (MS-STS) attention module in the encoder. The proposed MS-STS module effectively captures spatio-temporal feature relationships at multiple scales across frames in a video. We further introduce an attention block in the decoder to enhance the temporal consistency of the detected instances in different frames of a video. Moreover, an auxiliary discriminator is introduced during training to ensure better foreground-background separability within the multi-scale spatio-temporal feature space. We conduct extensive experiments on two benchmarks: Youtube-VIS (2019 and 2021). Our MS-STS VIS achieves state-of-the-art performance on both benchmarks. When using the ResNet50 backbone, our MS-STS achieves a mask AP of 50.1 %, outperforming the best reported results in literature by 2.7 % and by 4.8 % at higher overlap threshold of AP_75, while being comparable in model size and speed on Youtube-VIS 2019 val. set. When using the Swin Transformer backbone, MS-STS VIS achieves mask AP of 61.0 % on Youtube-VIS 2019 val. set. Our code and models are available at https://github.com/OmkarThawakar/MSSTS-VIS.
DoodleFormer: Creative Sketch Drawing with Transformers
Dec 06, 2021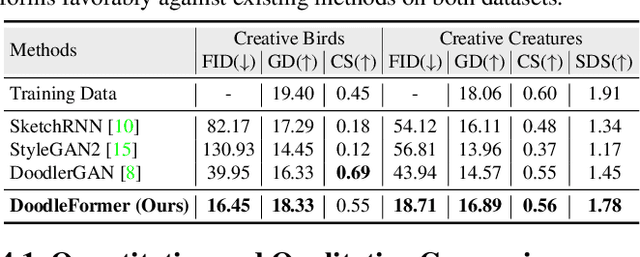
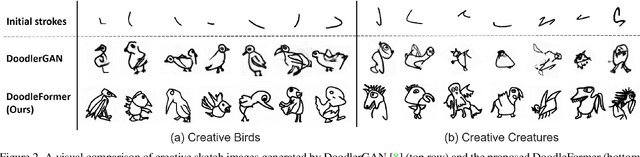
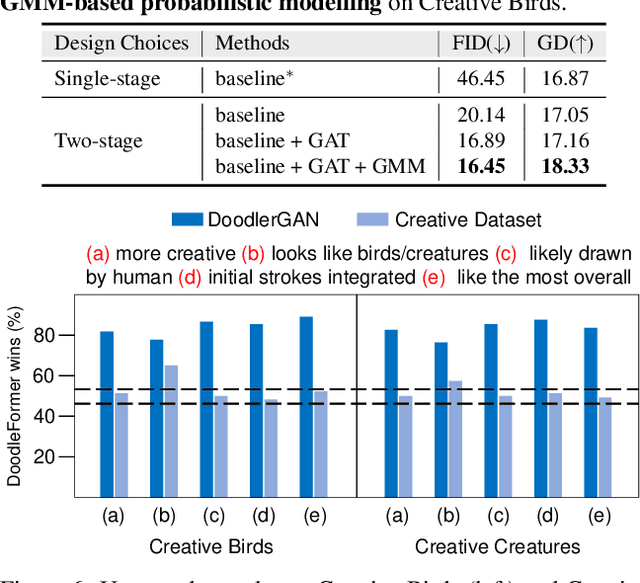
Creative sketching or doodling is an expressive activity, where imaginative and previously unseen depictions of everyday visual objects are drawn. Creative sketch image generation is a challenging vision problem, where the task is to generate diverse, yet realistic creative sketches possessing the unseen composition of the visual-world objects. Here, we propose a novel coarse-to-fine two-stage framework, DoodleFormer, that decomposes the creative sketch generation problem into the creation of coarse sketch composition followed by the incorporation of fine-details in the sketch. We introduce graph-aware transformer encoders that effectively capture global dynamic as well as local static structural relations among different body parts. To ensure diversity of the generated creative sketches, we introduce a probabilistic coarse sketch decoder that explicitly models the variations of each sketch body part to be drawn. Experiments are performed on two creative sketch datasets: Creative Birds and Creative Creatures. Our qualitative, quantitative and human-based evaluations show that DoodleFormer outperforms the state-of-the-art on both datasets, yielding realistic and diverse creative sketches. On Creative Creatures, DoodleFormer achieves an absolute gain of 25 in terms of Fr`echet inception distance (FID) over the state-of-the-art. We also demonstrate the effectiveness of DoodleFormer for related applications of text to creative sketch generation and sketch completion.
Structured Latent Embeddings for Recognizing Unseen Classes in Unseen Domains
Jul 12, 2021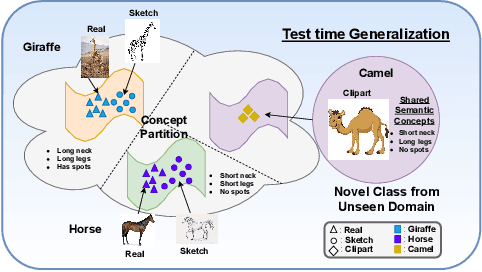
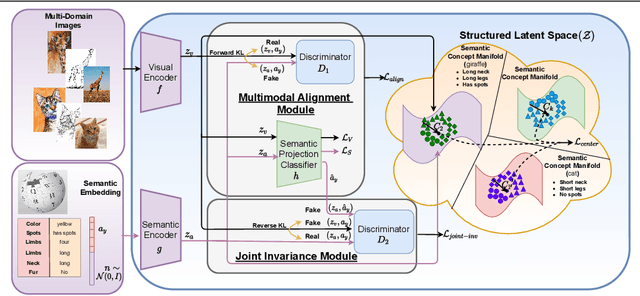
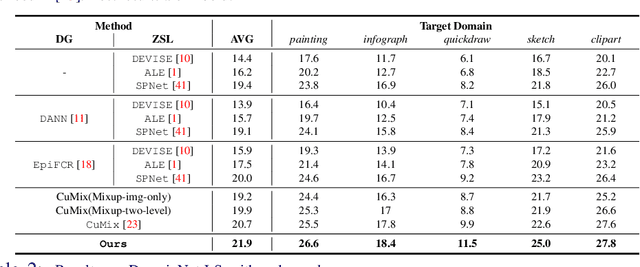
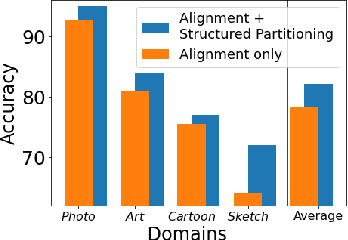
The need to address the scarcity of task-specific annotated data has resulted in concerted efforts in recent years for specific settings such as zero-shot learning (ZSL) and domain generalization (DG), to separately address the issues of semantic shift and domain shift, respectively. However, real-world applications often do not have constrained settings and necessitate handling unseen classes in unseen domains -- a setting called Zero-shot Domain Generalization, which presents the issues of domain and semantic shifts simultaneously. In this work, we propose a novel approach that learns domain-agnostic structured latent embeddings by projecting images from different domains as well as class-specific semantic text-based representations to a common latent space. In particular, our method jointly strives for the following objectives: (i) aligning the multimodal cues from visual and text-based semantic concepts; (ii) partitioning the common latent space according to the domain-agnostic class-level semantic concepts; and (iii) learning a domain invariance w.r.t the visual-semantic joint distribution for generalizing to unseen classes in unseen domains. Our experiments on the challenging DomainNet and DomainNet-LS benchmarks show the superiority of our approach over existing methods, with significant gains on difficult domains like quickdraw and sketch.
Handwriting Transformers
Apr 08, 2021



We propose a novel transformer-based styled handwritten text image generation approach, HWT, that strives to learn both style-content entanglement as well as global and local writing style patterns. The proposed HWT captures the long and short range relationships within the style examples through a self-attention mechanism, thereby encoding both global and local style patterns. Further, the proposed transformer-based HWT comprises an encoder-decoder attention that enables style-content entanglement by gathering the style representation of each query character. To the best of our knowledge, we are the first to introduce a transformer-based generative network for styled handwritten text generation. Our proposed HWT generates realistic styled handwritten text images and significantly outperforms the state-of-the-art demonstrated through extensive qualitative, quantitative and human-based evaluations. The proposed HWT can handle arbitrary length of text and any desired writing style in a few-shot setting. Further, our HWT generalizes well to the challenging scenario where both words and writing style are unseen during training, generating realistic styled handwritten text images.
D2-Net: Weakly-Supervised Action Localization via Discriminative Embeddings and Denoised Activations
Dec 11, 2020
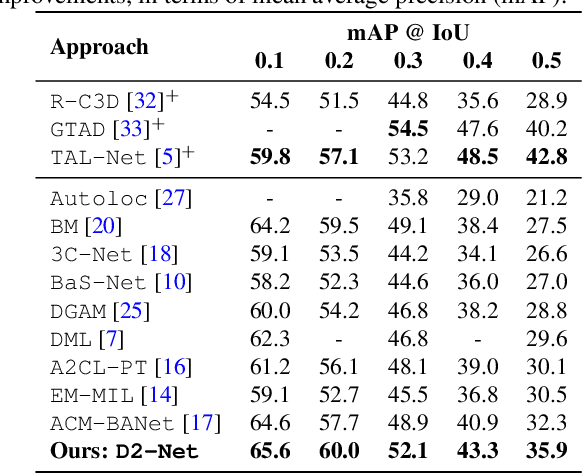
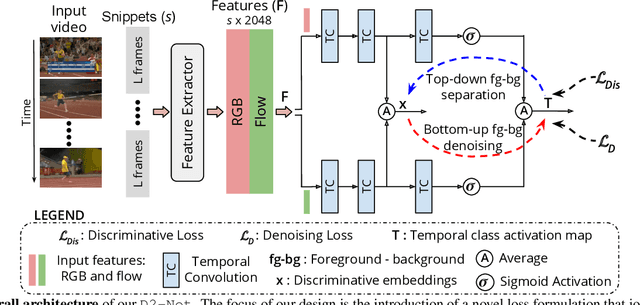
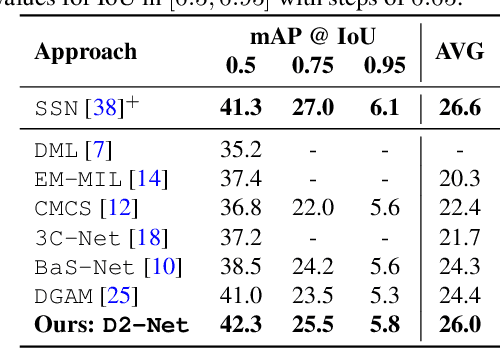
This work proposes a weakly-supervised temporal action localization framework, called D2-Net, which strives to temporally localize actions using video-level supervision. Our main contribution is the introduction of a novel loss formulation, which jointly enhances the discriminability of latent embeddings and robustness of the output temporal class activations with respect to foreground-background noise caused by weak supervision. The proposed formulation comprises a discriminative and a denoising loss term for enhancing temporal action localization. The discriminative term incorporates a classification loss and utilizes a top-down attention mechanism to enhance the separability of latent foreground-background embeddings. The denoising loss term explicitly addresses the foreground-background noise in class activations by simultaneously maximizing intra-video and inter-video mutual information using a bottom-up attention mechanism. As a result, activations in the foreground regions are emphasized whereas those in the background regions are suppressed, thereby leading to more robust predictions. Comprehensive experiments are performed on two benchmarks: THUMOS14 and ActivityNet1.2. Our D2-Net performs favorably in comparison to the existing methods on both datasets, achieving gains as high as 3.6% in terms of mean average precision on THUMOS14.
SipMask: Spatial Information Preservation for Fast Image and Video Instance Segmentation
Jul 29, 2020
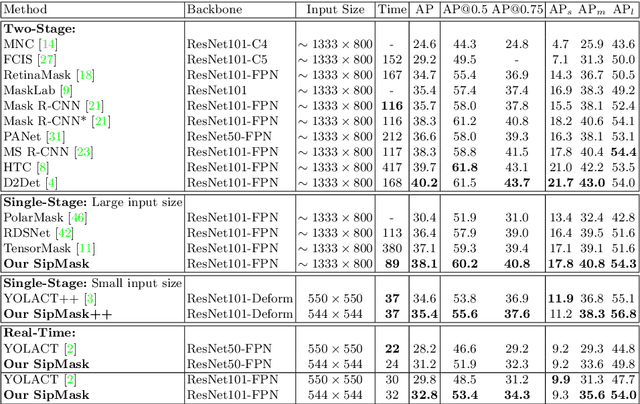
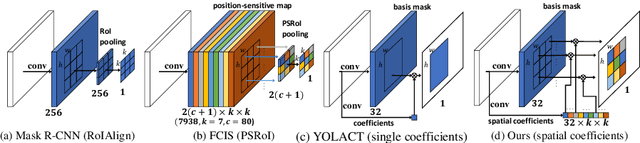
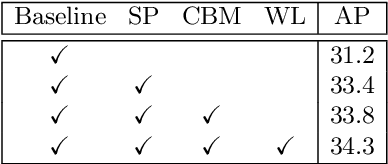
Single-stage instance segmentation approaches have recently gained popularity due to their speed and simplicity, but are still lagging behind in accuracy, compared to two-stage methods. We propose a fast single-stage instance segmentation method, called SipMask, that preserves instance-specific spatial information by separating mask prediction of an instance to different sub-regions of a detected bounding-box. Our main contribution is a novel light-weight spatial preservation (SP) module that generates a separate set of spatial coefficients for each sub-region within a bounding-box, leading to improved mask predictions. It also enables accurate delineation of spatially adjacent instances. Further, we introduce a mask alignment weighting loss and a feature alignment scheme to better correlate mask prediction with object detection. On COCO test-dev, our SipMask outperforms the existing single-stage methods. Compared to the state-of-the-art single-stage TensorMask, SipMask obtains an absolute gain of 1.0% (mask AP), while providing a four-fold speedup. In terms of real-time capabilities, SipMask outperforms YOLACT with an absolute gain of 3.0% (mask AP) under similar settings, while operating at comparable speed on a Titan Xp. We also evaluate our SipMask for real-time video instance segmentation, achieving promising results on YouTube-VIS dataset. The source code is available at https://github.com/JialeCao001/SipMask.
PSC-Net: Learning Part Spatial Co-occurence for Occluded Pedestrian Detection
Jan 25, 2020

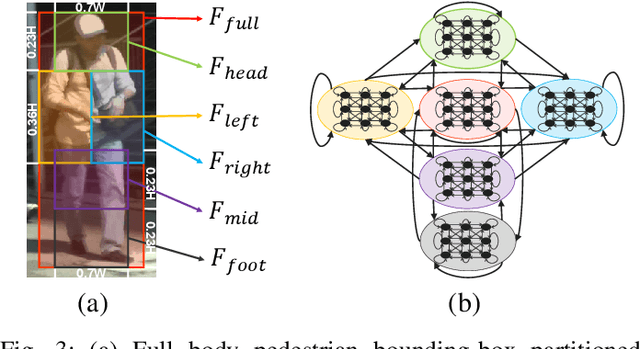
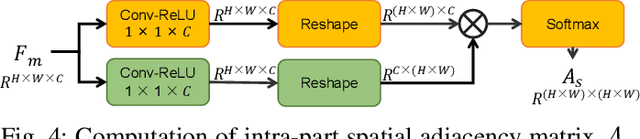
Detecting pedestrians, especially under heavy occlusions, is a challenging computer vision problem with numerous real-world applications. This paper introduces a novel approach, termed as PSC-Net, for occluded pedestrian detection. The proposed PSC-Net contains a dedicated module that is designed to explicitly capture both inter and intra-part co-occurrence information of different pedestrian body parts through a Graph Convolutional Network (GCN). Both inter and intra-part co-occurrence information contribute towards improving the feature representation for handling varying level of occlusions, ranging from partial to severe occlusions. Our PSC-Net exploits the topological structure of pedestrian and does not require part-based annotations or additional visible bounding-box (VBB) information to learn part spatial co-occurence. Comprehensive experiments are performed on two challenging datasets: CityPersons and Caltech datasets. The proposed PSC-Net achieives state-of-the-art detection performance on both. On the heavy occluded (HO) set of CityPerosns test set, our PSC-Net obtains an absolute gain of 3.6% in terms of log-average miss rate over the state-of-the-art with same backbone, input scale and without using additional VBB supervision. Further, PSC-Net improves the state-of-the-art from 37.9 to 34.9 in terms of log-average miss rate on Caltech (\textbf{HO}) test set.