 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeike Adel
An Analysis of Simple Data Augmentation for Named Entity Recognition
Oct 22, 2020
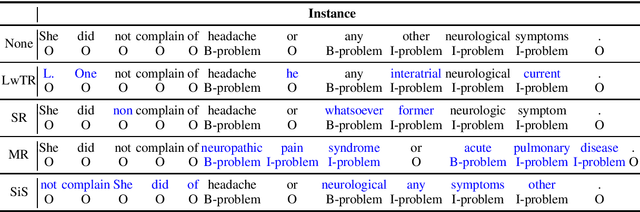
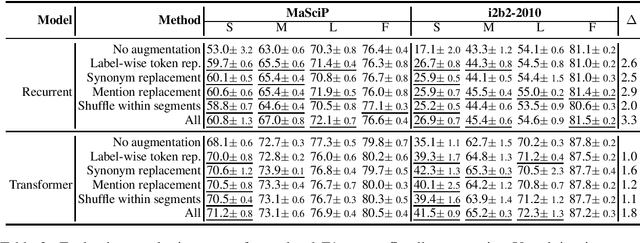
Simple yet effective data augmentation techniques have been proposed for sentence-level and sentence-pair natural language processing tasks. Inspired by these efforts, we design and compare data augmentation for named entity recognition, which is usually modeled as a token-level sequence labeling problem. Through experiments on two data sets from the biomedical and materials science domains (i2b2-2010 and MaSciP), we show that simple augmentation can boost performance for both recurrent and transformer-based models, especially for small training sets.
F1 is Not Enough! Models and Evaluation Towards User-Centered Explainable Question Answering
Oct 13, 2020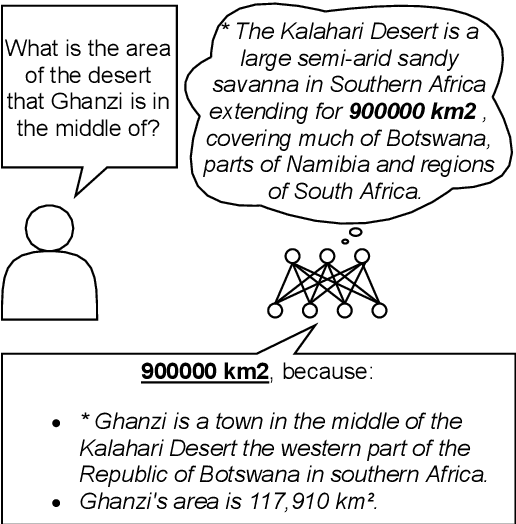
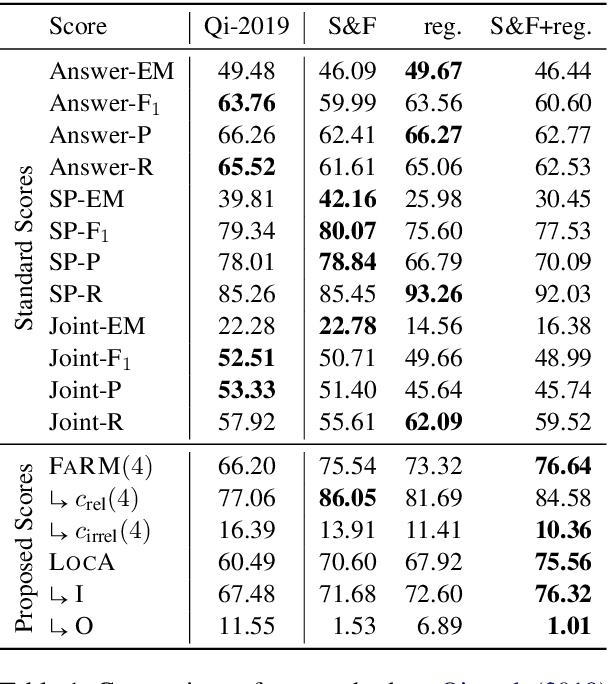
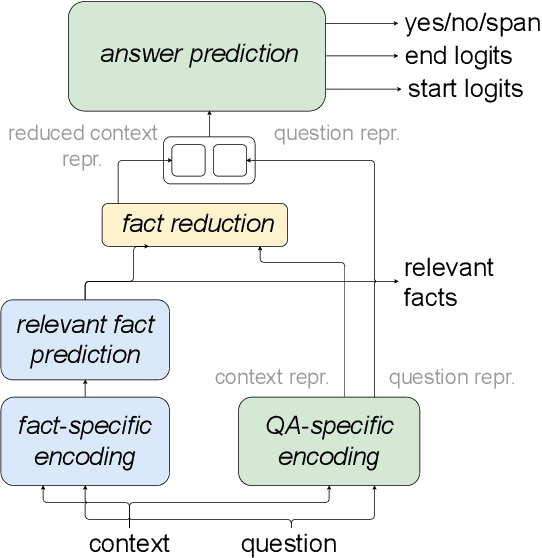
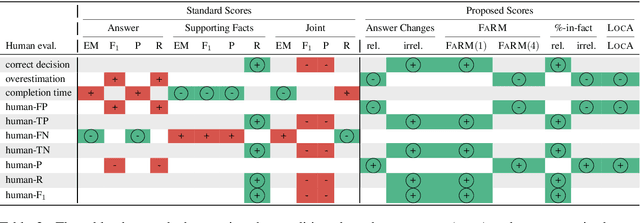
Explainable question answering systems predict an answer together with an explanation showing why the answer has been selected. The goal is to enable users to assess the correctness of the system and understand its reasoning process. However, we show that current models and evaluation settings have shortcomings regarding the coupling of answer and explanation which might cause serious issues in user experience. As a remedy, we propose a hierarchical model and a new regularization term to strengthen the answer-explanation coupling as well as two evaluation scores to quantify the coupling. We conduct experiments on the HOTPOTQA benchmark data set and perform a user study. The user study shows that our models increase the ability of the users to judge the correctness of the system and that scores like F1 are not enough to estimate the usefulness of a model in a practical setting with human users. Our scores are better aligned with user experience, making them promising candidates for model selection.
NLNDE: The Neither-Language-Nor-Domain-Experts' Way of Spanish Medical Document De-Identification
Jul 02, 2020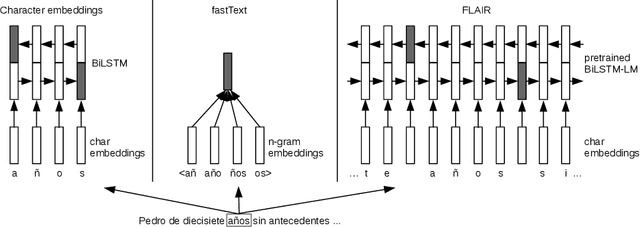
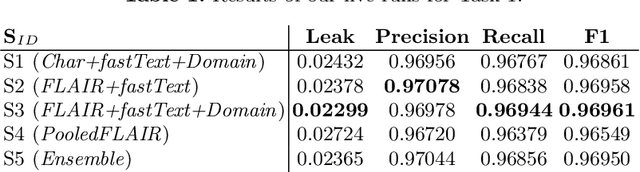

Natural language processing has huge potential in the medical domain which recently led to a lot of research in this field. However, a prerequisite of secure processing of medical documents, e.g., patient notes and clinical trials, is the proper de-identification of privacy-sensitive information. In this paper, we describe our NLNDE system, with which we participated in the MEDDOCAN competition, the medical document anonymization task of IberLEF 2019. We address the task of detecting and classifying protected health information from Spanish data as a sequence-labeling problem and investigate different embedding methods for our neural network. Despite dealing in a non-standard language and domain setting, the NLNDE system achieves promising results in the competition.
NLNDE: Enhancing Neural Sequence Taggers with Attention and Noisy Channel for Robust Pharmacological Entity Detection
Jul 02, 2020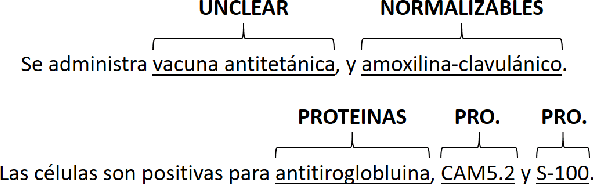
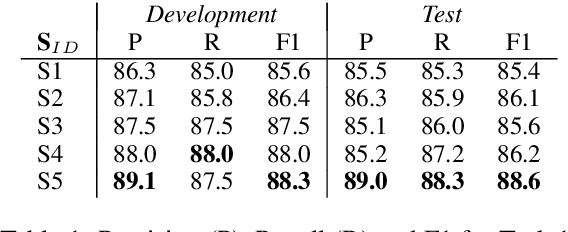
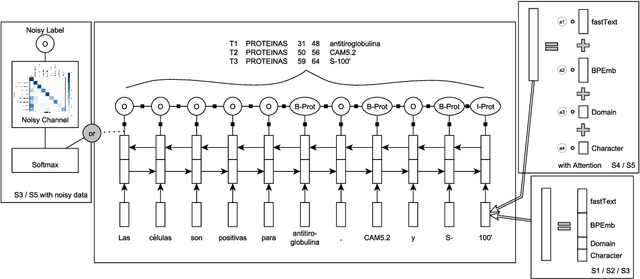
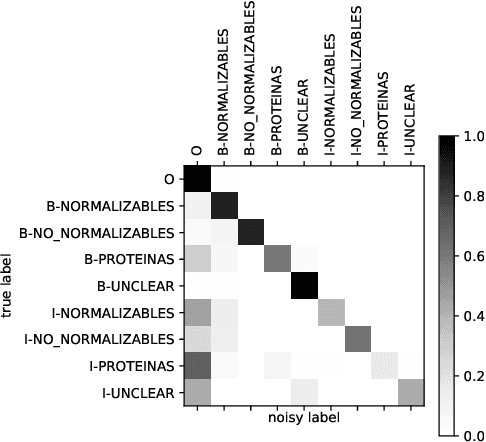
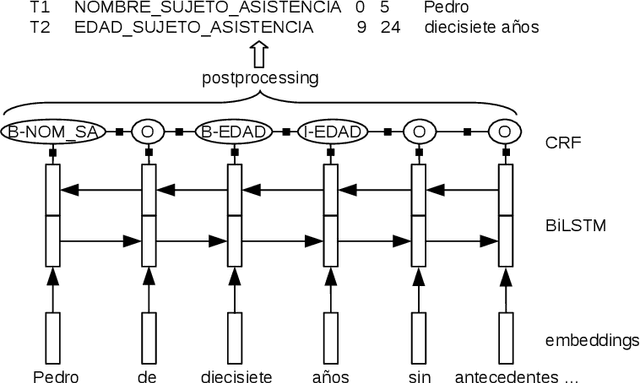
Named entity recognition has been extensively studied on English news texts. However, the transfer to other domains and languages is still a challenging problem. In this paper, we describe the system with which we participated in the first subtrack of the PharmaCoNER competition of the BioNLP Open Shared Tasks 2019. Aiming at pharmacological entity detection in Spanish texts, the task provides a non-standard domain and language setting. However, we propose an architecture that requires neither language nor domain expertise. We treat the task as a sequence labeling task and experiment with attention-based embedding selection and the training on automatically annotated data to further improve our system's performance. Our system achieves promising results, especially by combining the different techniques, and reaches up to 88.6% F1 in the competition.
The SOFC-Exp Corpus and Neural Approaches to Information Extraction in the Materials Science Domain
Jun 04, 2020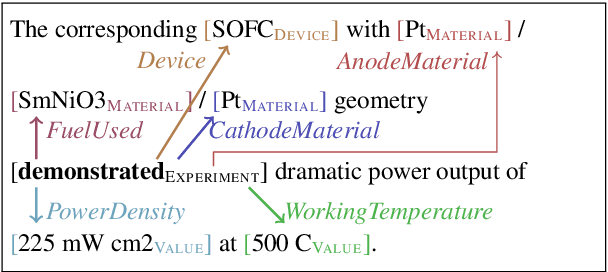
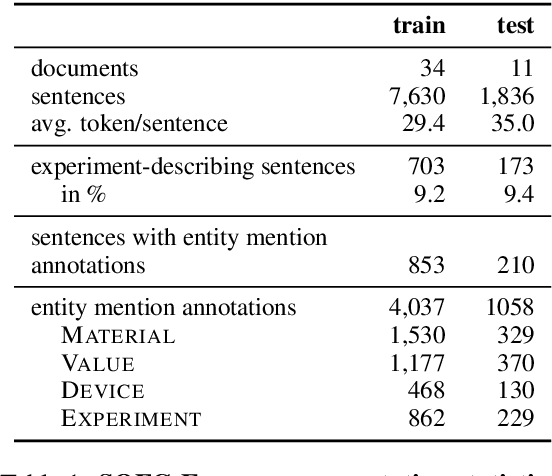
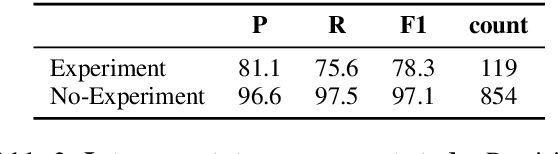
This paper presents a new challenging information extraction task in the domain of materials science. We develop an annotation scheme for marking information on experiments related to solid oxide fuel cells in scientific publications, such as involved materials and measurement conditions. With this paper, we publish our annotation guidelines, as well as our SOFC-Exp corpus consisting of 45 open-access scholarly articles annotated by domain experts. A corpus and an inter-annotator agreement study demonstrate the complexity of the suggested named entity recognition and slot filling tasks as well as high annotation quality. We also present strong neural-network based models for a variety of tasks that can be addressed on the basis of our new data set. On all tasks, using BERT embeddings leads to large performance gains, but with increasing task complexity, adding a recurrent neural network on top seems beneficial. Our models will serve as competitive baselines in future work, and analysis of their performance highlights difficult cases when modeling the data and suggests promising research directions.
Closing the Gap: Joint De-Identification and Concept Extraction in the Clinical Domain
May 19, 2020
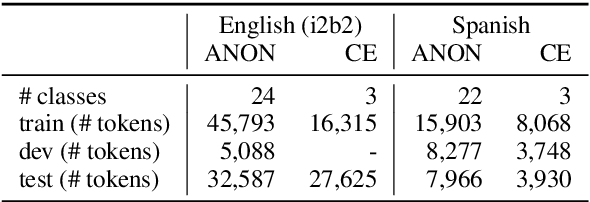
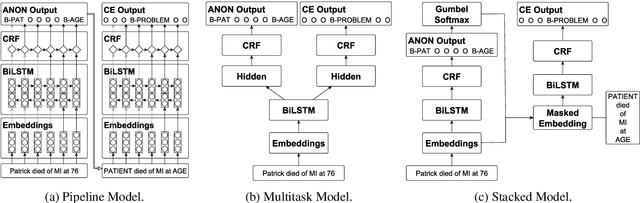
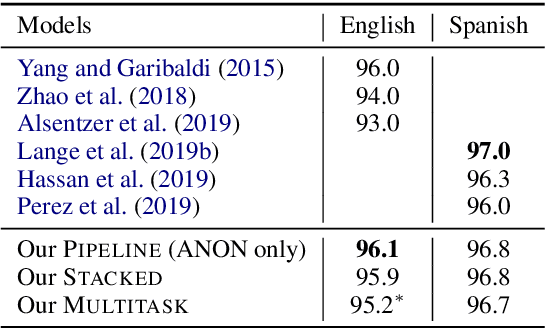
Exploiting natural language processing in the clinical domain requires de-identification, i.e., anonymization of personal information in texts. However, current research considers de-identification and downstream tasks, such as concept extraction, only in isolation and does not study the effects of de-identification on other tasks. In this paper, we close this gap by reporting concept extraction performance on automatically anonymized data and investigating joint models for de-identification and concept extraction. In particular, we propose a stacked model with restricted access to privacy-sensitive information and a multitask model. We set the new state of the art on benchmark datasets in English (96.1% F1 for de-identification and 88.9% F1 for concept extraction) and Spanish (91.4% F1 for concept extraction).
Adversarial Alignment of Multilingual Models for Extracting Temporal Expressions from Text
May 19, 2020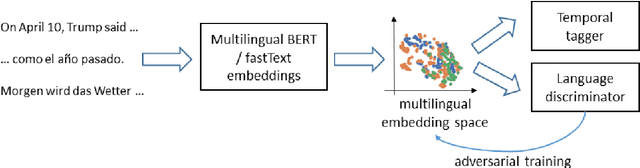
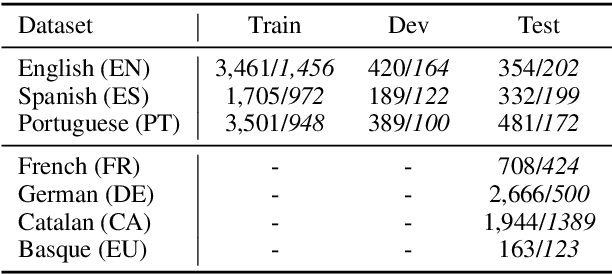
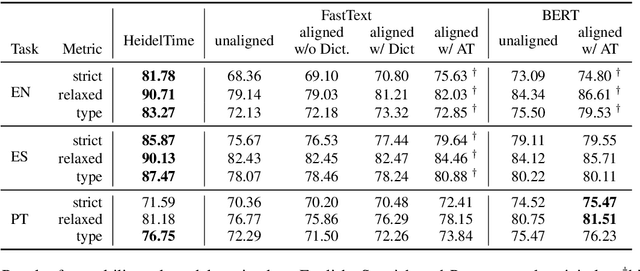
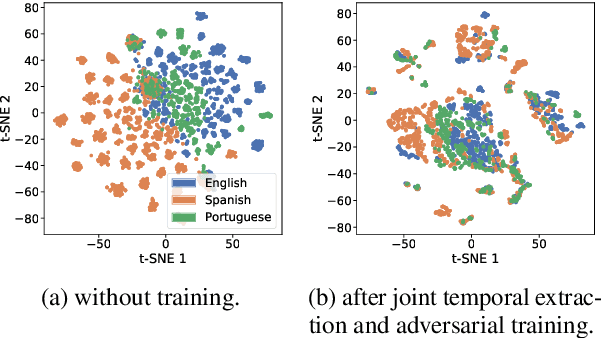
Although temporal tagging is still dominated by rule-based systems, there have been recent attempts at neural temporal taggers. However, all of them focus on monolingual settings. In this paper, we explore multilingual methods for the extraction of temporal expressions from text and investigate adversarial training for aligning embedding spaces to one common space. With this, we create a single multilingual model that can also be transferred to unseen languages and set the new state of the art in those cross-lingual transfer experiments.
On the Choice of Auxiliary Languages for Improved Sequence Tagging
May 19, 2020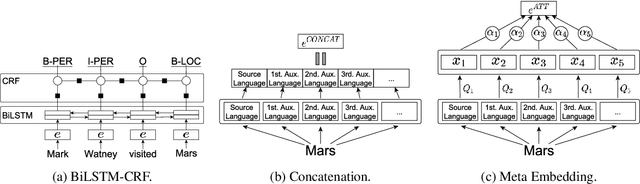
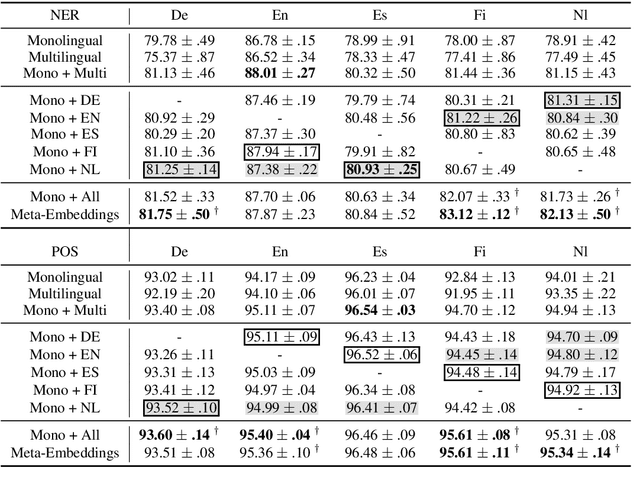
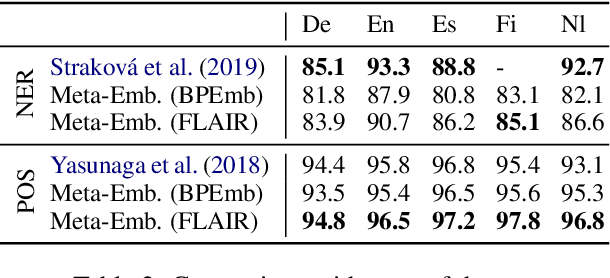
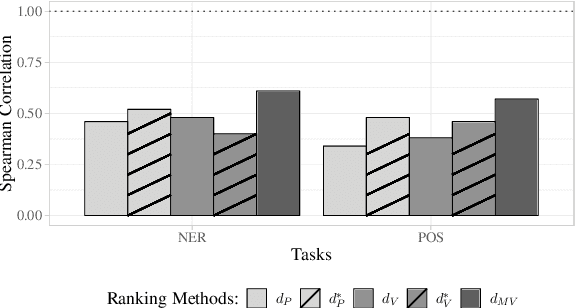
Recent work showed that embeddings from related languages can improve the performance of sequence tagging, even for monolingual models. In this analysis paper, we investigate whether the best auxiliary language can be predicted based on language distances and show that the most related language is not always the best auxiliary language. Further, we show that attention-based meta-embeddings can effectively combine pre-trained embeddings from different languages for sequence tagging and set new state-of-the-art results for part-of-speech tagging in five languages.
Type-aware Convolutional Neural Networks for Slot Filling
Oct 01, 2019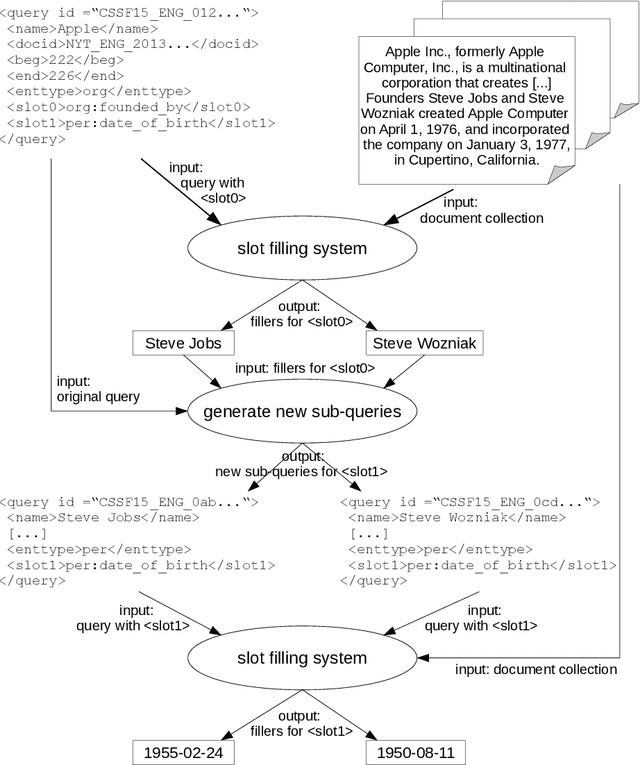
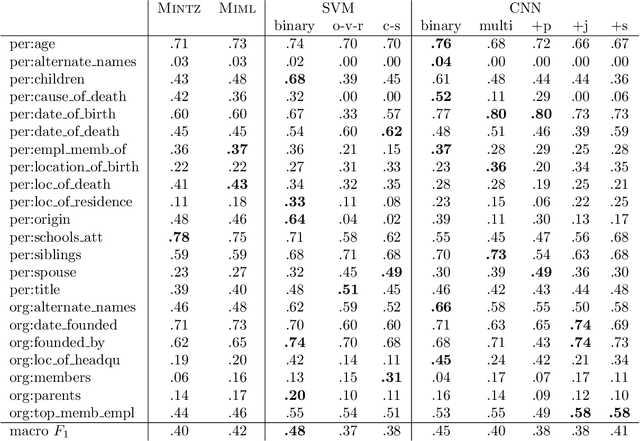
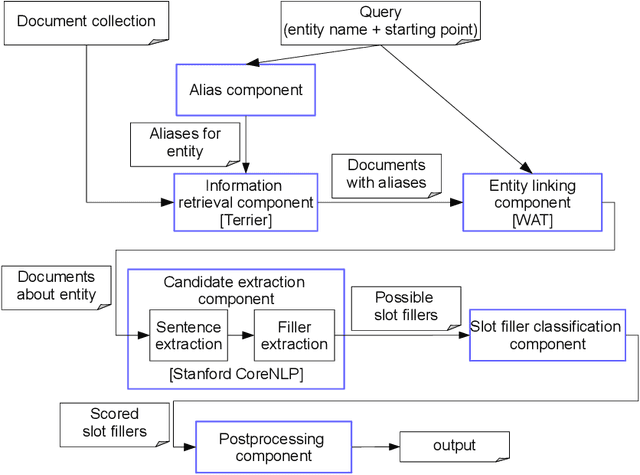
The slot filling task aims at extracting answers for queries about entities from text, such as "Who founded Apple". In this paper, we focus on the relation classification component of a slot filling system. We propose type-aware convolutional neural networks to benefit from the mutual dependencies between entity and relation classification. In particular, we explore different ways of integrating the named entity types of the relation arguments into a neural network for relation classification, including a joint training and a structured prediction approach. To the best of our knowledge, this is the first study on type-aware neural networks for slot filling. The type-aware models lead to the best results of our slot filling pipeline. Joint training performs comparable to structured prediction. To understand the impact of the different components of the slot filling pipeline, we perform a recall analysis, a manual error analysis and several ablation studies. Such analyses are of particular importance to other slot filling researchers since the official slot filling evaluations only assess pipeline outputs. The analyses show that especially coreference resolution and our convolutional neural networks have a large positive impact on the final performance of the slot filling pipeline. The presented models, the source code of our system as well as our coreference resource is publicy available.
Adversarial Training for Satire Detection: Controlling for Confounding Variables
Mar 01, 2019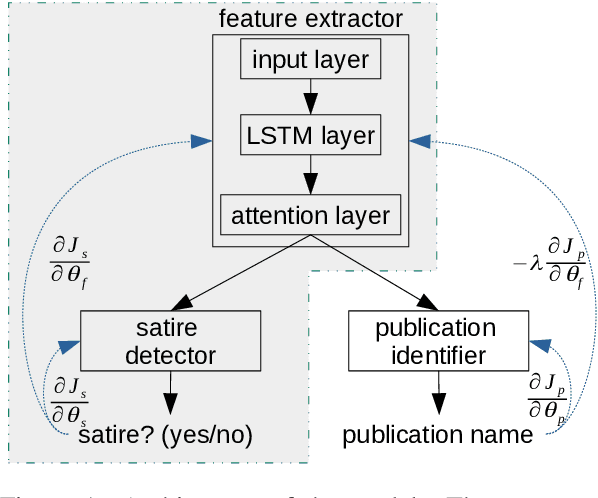
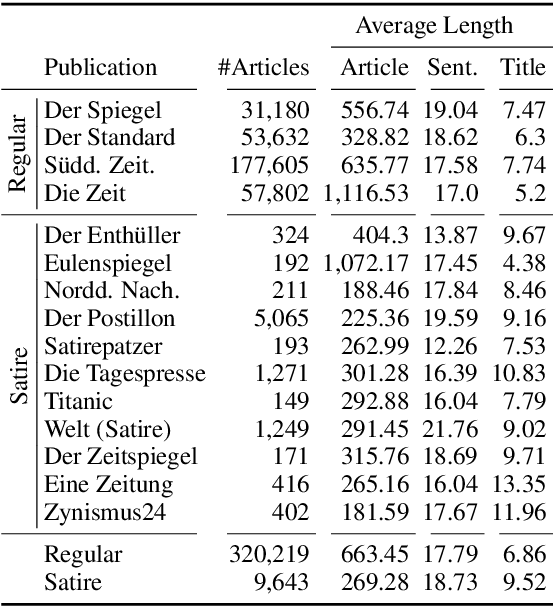
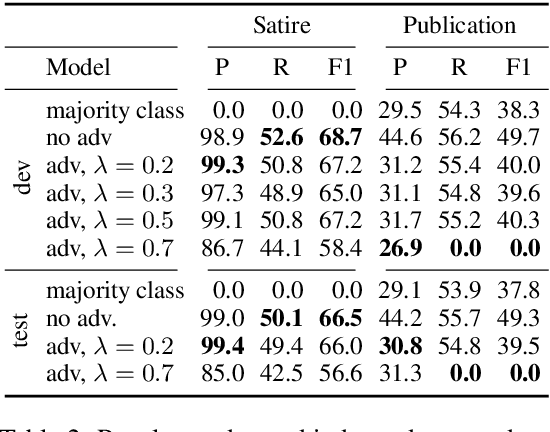

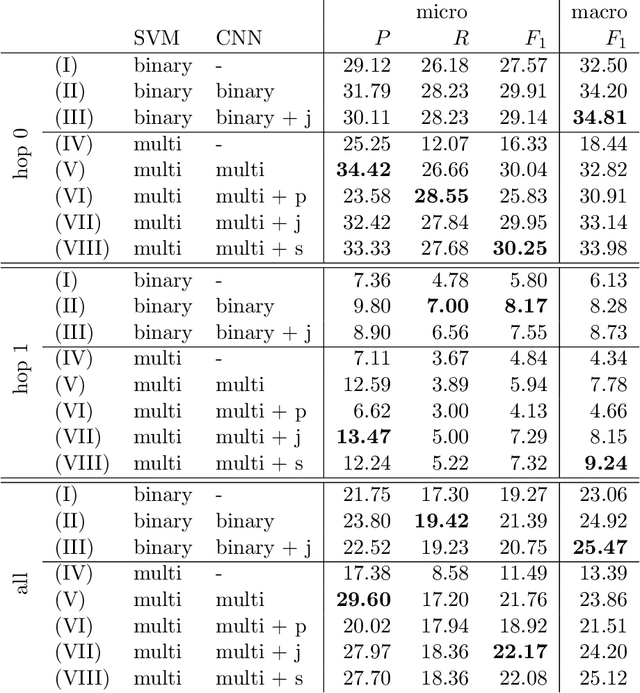
The automatic detection of satire vs. regular news is relevant for downstream applications (for instance, knowledge base population) and to improve the understanding of linguistic characteristics of satire. Recent approaches build upon corpora which have been labeled automatically based on article sources. We hypothesize that this encourages the models to learn characteristics for different publication sources (e.g., "The Onion" vs. "The Guardian") rather than characteristics of satire, leading to poor generalization performance to unseen publication sources. We therefore propose a novel model for satire detection with an adversarial component to control for the confounding variable of publication source. On a large novel data set collected from German news (which we make available to the research community), we observe comparable satire classification performance and, as desired, a considerable drop in publication classification performance with adversarial training. Our analysis shows that the adversarial component is crucial for the model to learn to pay attention to linguistic properties of satire.