 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHe Wang
Shape Completion with Points in the Shadow
Oct 04, 2022

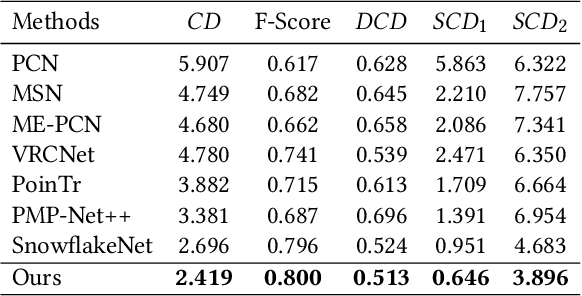
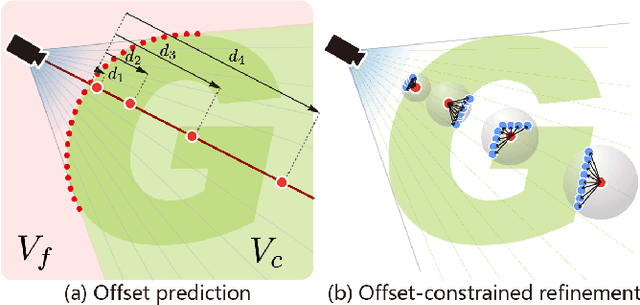
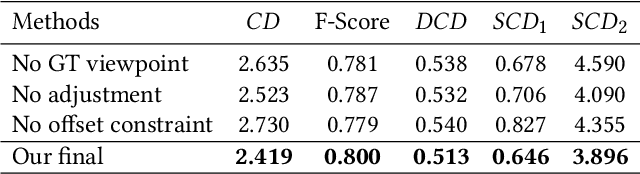
Single-view point cloud completion aims to recover the full geometry of an object based on only limited observation, which is extremely hard due to the data sparsity and occlusion. The core challenge is to generate plausible geometries to fill the unobserved part of the object based on a partial scan, which is under-constrained and suffers from a huge solution space. Inspired by the classic shadow volume technique in computer graphics, we propose a new method to reduce the solution space effectively. Our method considers the camera a light source that casts rays toward the object. Such light rays build a reasonably constrained but sufficiently expressive basis for completion. The completion process is then formulated as a point displacement optimization problem. Points are initialized at the partial scan and then moved to their goal locations with two types of movements for each point: directional movements along the light rays and constrained local movement for shape refinement. We design neural networks to predict the ideal point movements to get the completion results. We demonstrate that our method is accurate, robust, and generalizable through exhaustive evaluation and comparison. Moreover, it outperforms state-of-the-art methods qualitatively and quantitatively on MVP datasets.
Spatio-temporal Keyframe Control of Traffic Simulation using Coarse-to-Fine Optimization
Sep 26, 2022
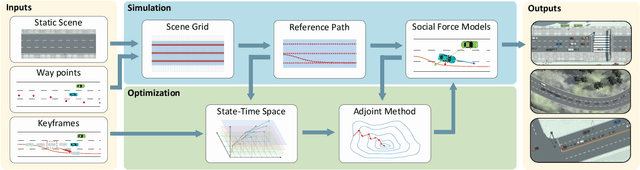

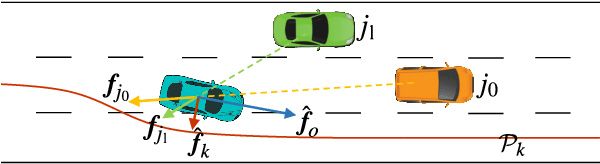
We present a novel traffic trajectory editing method which uses spatio-temporal keyframes to control vehicles during the simulation to generate desired traffic trajectories. By taking self-motivation, path following and collision avoidance into account, the proposed force-based traffic simulation framework updates vehicle's motions in both the Frenet coordinates and the Cartesian coordinates. With the way-points from users, lane-level navigation can be generated by reference path planning. With a given keyframe, the coarse-to-fine optimization is proposed to efficiently generate the plausible trajectory which can satisfy the spatio-temporal constraints. At first, a directed state-time graph constructed along the reference path is used to search for a coarse-grained trajectory by mapping the keyframe as the goal. Then, using the information extracted from the coarse trajectory as initialization, adjoint-based optimization is applied to generate a finer trajectory with smooth motions based on our force-based simulation. We validate our method with extensive experiments.
Tracking and Reconstructing Hand Object Interactions from Point Cloud Sequences in the Wild
Sep 24, 2022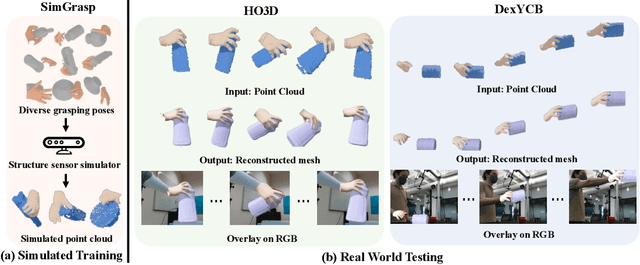
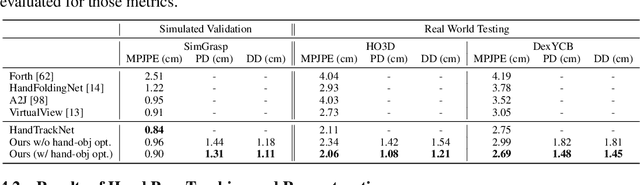
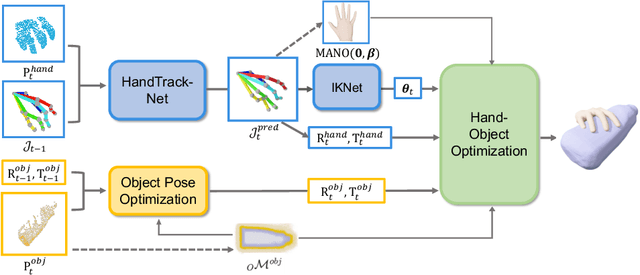
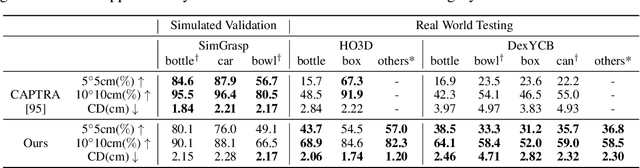
In this work, we tackle the challenging task of jointly tracking hand object pose and reconstructing their shapes from depth point cloud sequences in the wild, given the initial poses at frame 0. We for the first time propose a point cloud based hand joint tracking network, HandTrackNet, to estimate the inter-frame hand joint motion. Our HandTrackNet proposes a novel hand pose canonicalization module to ease the tracking task, yielding accurate and robust hand joint tracking. Our pipeline then reconstructs the full hand via converting the predicted hand joints into a template-based parametric hand model MANO. For object tracking, we devise a simple yet effective module that estimates the object SDF from the first frame and performs optimization-based tracking. Finally, a joint optimization step is adopted to perform joint hand and object reasoning, which alleviates the occlusion-induced ambiguity and further refines the hand pose. During training, the whole pipeline only sees purely synthetic data, which are synthesized with sufficient variations and by depth simulation for the ease of generalization. The whole pipeline is pertinent to the generalization gaps and thus directly transferable to real in-the-wild data. We evaluate our method on two real hand object interaction datasets, e.g. HO3D and DexYCB, without any finetuning. Our experiments demonstrate that the proposed method significantly outperforms the previous state-of-the-art depth-based hand and object pose estimation and tracking methods, running at a frame rate of 9 FPS.
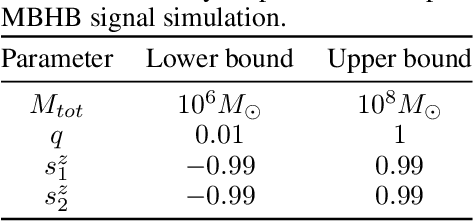
MLGWSC-1: The first Machine Learning Gravitational-Wave Search Mock Data Challenge
Sep 22, 2022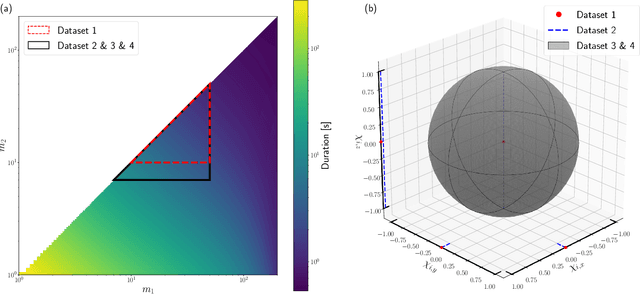
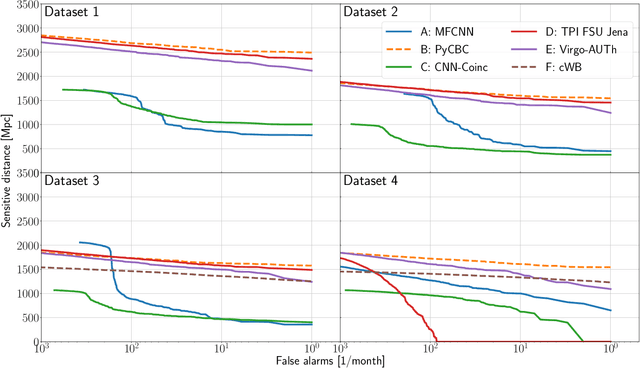
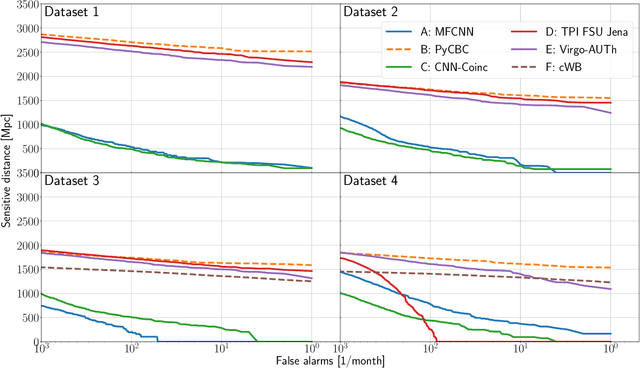
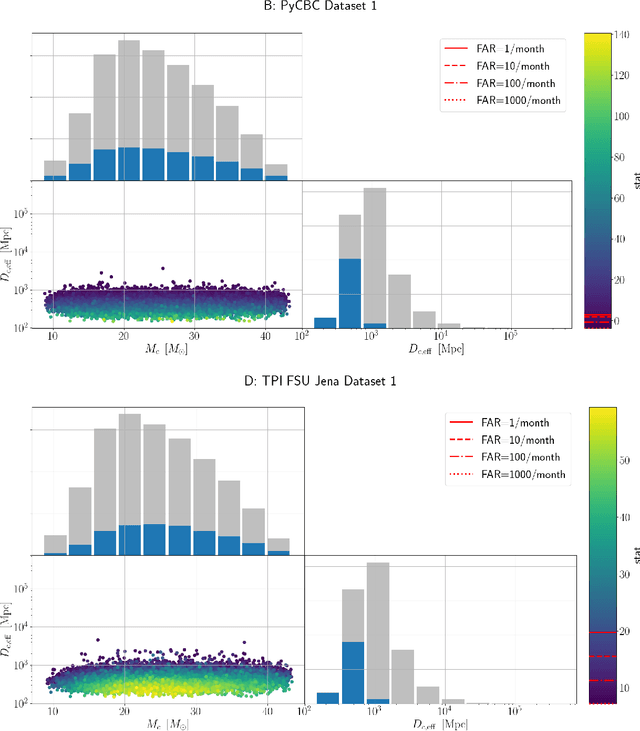
We present the results of the first Machine Learning Gravitational-Wave Search Mock Data Challenge (MLGWSC-1). For this challenge, participating groups had to identify gravitational-wave signals from binary black hole mergers of increasing complexity and duration embedded in progressively more realistic noise. The final of the 4 provided datasets contained real noise from the O3a observing run and signals up to a duration of 20 seconds with the inclusion of precession effects and higher order modes. We present the average sensitivity distance and runtime for the 6 entered algorithms derived from 1 month of test data unknown to the participants prior to submission. Of these, 4 are machine learning algorithms. We find that the best machine learning based algorithms are able to achieve up to 95% of the sensitive distance of matched-filtering based production analyses for simulated Gaussian noise at a false-alarm rate (FAR) of one per month. In contrast, for real noise, the leading machine learning search achieved 70%. For higher FARs the differences in sensitive distance shrink to the point where select machine learning submissions outperform traditional search algorithms at FARs $\geq 200$ per month on some datasets. Our results show that current machine learning search algorithms may already be sensitive enough in limited parameter regions to be useful for some production settings. To improve the state-of-the-art, machine learning algorithms need to reduce the false-alarm rates at which they are capable of detecting signals and extend their validity to regions of parameter space where modeled searches are computationally expensive to run. Based on our findings we compile a list of research areas that we believe are the most important to elevate machine learning searches to an invaluable tool in gravitational-wave signal detection.
Talking Head from Speech Audio using a Pre-trained Image Generator
Sep 09, 2022
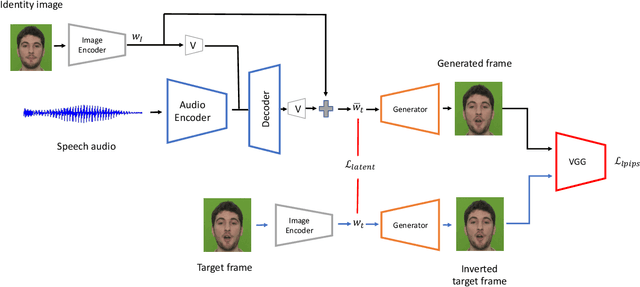
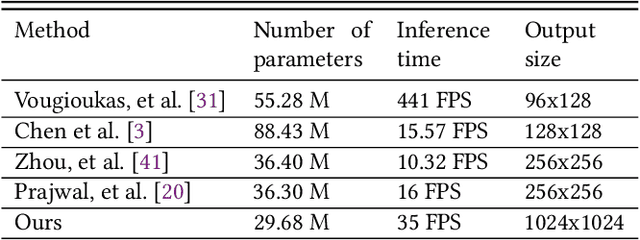

We propose a novel method for generating high-resolution videos of talking-heads from speech audio and a single 'identity' image. Our method is based on a convolutional neural network model that incorporates a pre-trained StyleGAN generator. We model each frame as a point in the latent space of StyleGAN so that a video corresponds to a trajectory through the latent space. Training the network is in two stages. The first stage is to model trajectories in the latent space conditioned on speech utterances. To do this, we use an existing encoder to invert the generator, mapping from each video frame into the latent space. We train a recurrent neural network to map from speech utterances to displacements in the latent space of the image generator. These displacements are relative to the back-projection into the latent space of an identity image chosen from the individuals depicted in the training dataset. In the second stage, we improve the visual quality of the generated videos by tuning the image generator on a single image or a short video of any chosen identity. We evaluate our model on standard measures (PSNR, SSIM, FID and LMD) and show that it significantly outperforms recent state-of-the-art methods on one of two commonly used datasets and gives comparable performance on the other. Finally, we report on ablation experiments that validate the components of the model. The code and videos from experiments can be found at https://mohammedalghamdi.github.io/talking-heads-acm-mm
Domain Randomization-Enhanced Depth Simulation and Restoration for Perceiving and Grasping Specular and Transparent Objects
Aug 07, 2022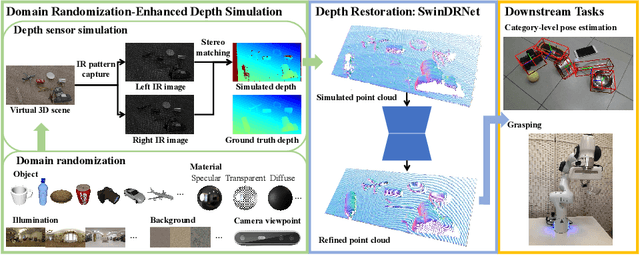
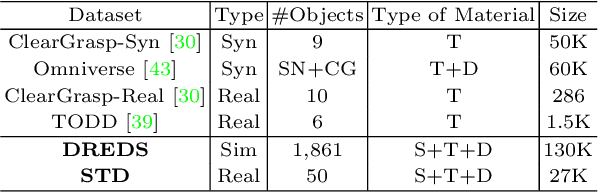
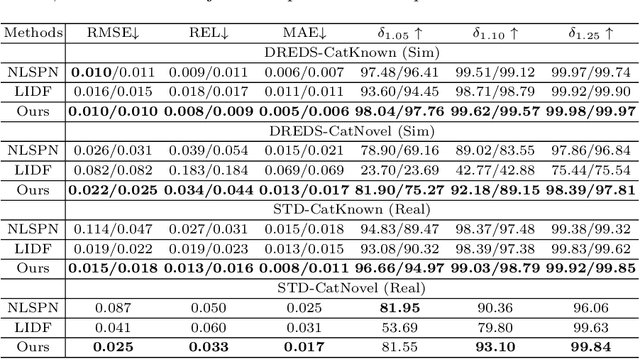

Commercial depth sensors usually generate noisy and missing depths, especially on specular and transparent objects, which poses critical issues to downstream depth or point cloud-based tasks. To mitigate this problem, we propose a powerful RGBD fusion network, SwinDRNet, for depth restoration. We further propose Domain Randomization-Enhanced Depth Simulation (DREDS) approach to simulate an active stereo depth system using physically based rendering and generate a large-scale synthetic dataset that contains 130K photorealistic RGB images along with their simulated depths carrying realistic sensor noises. To evaluate depth restoration methods, we also curate a real-world dataset, namely STD, that captures 30 cluttered scenes composed of 50 objects with different materials from specular, transparent, to diffuse. Experiments demonstrate that the proposed DREDS dataset bridges the sim-to-real domain gap such that, trained on DREDS, our SwinDRNet can seamlessly generalize to other real depth datasets, e.g. ClearGrasp, and outperform the competing methods on depth restoration with a real-time speed. We further show that our depth restoration effectively boosts the performance of downstream tasks, including category-level pose estimation and grasping tasks. Our data and code are available at https://github.com/PKU-EPIC/DREDS
Human Trajectory Prediction via Neural Social Physics
Jul 21, 2022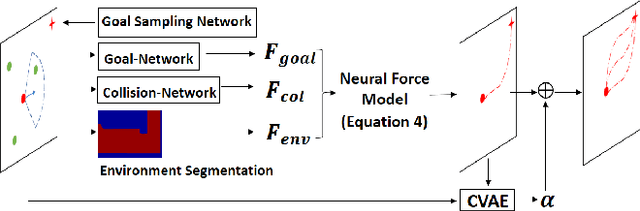
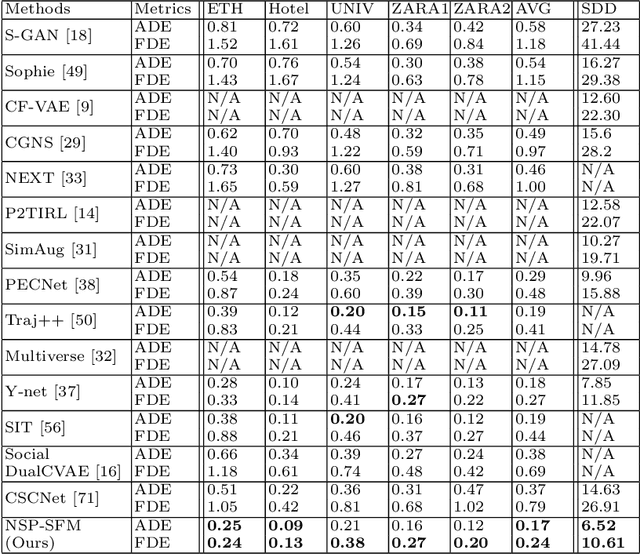
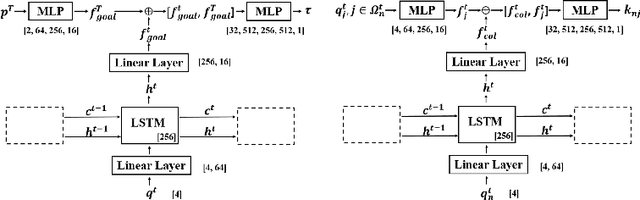
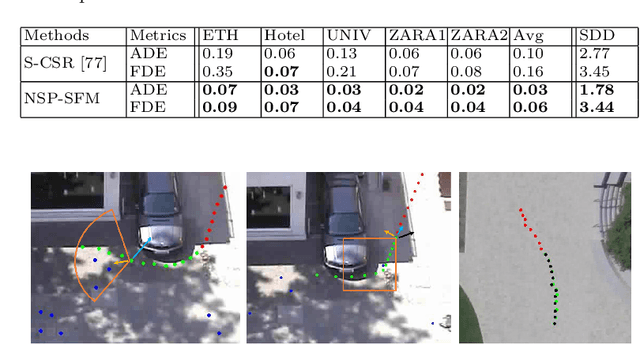
Trajectory prediction has been widely pursued in many fields, and many model-based and model-free methods have been explored. The former include rule-based, geometric or optimization-based models, and the latter are mainly comprised of deep learning approaches. In this paper, we propose a new method combining both methodologies based on a new Neural Differential Equation model. Our new model (Neural Social Physics or NSP) is a deep neural network within which we use an explicit physics model with learnable parameters. The explicit physics model serves as a strong inductive bias in modeling pedestrian behaviors, while the rest of the network provides a strong data-fitting capability in terms of system parameter estimation and dynamics stochasticity modeling. We compare NSP with 15 recent deep learning methods on 6 datasets and improve the state-of-the-art performance by 5.56%-70%. Besides, we show that NSP has better generalizability in predicting plausible trajectories in drastically different scenarios where the density is 2-5 times as high as the testing data. Finally, we show that the physics model in NSP can provide plausible explanations for pedestrian behaviors, as opposed to black-box deep learning. Code is available: https://github.com/realcrane/Human-Trajectory-Prediction-via-Neural-Social-Physics.
Space-based gravitational wave signal detection and extraction with deep neural network
Jul 15, 2022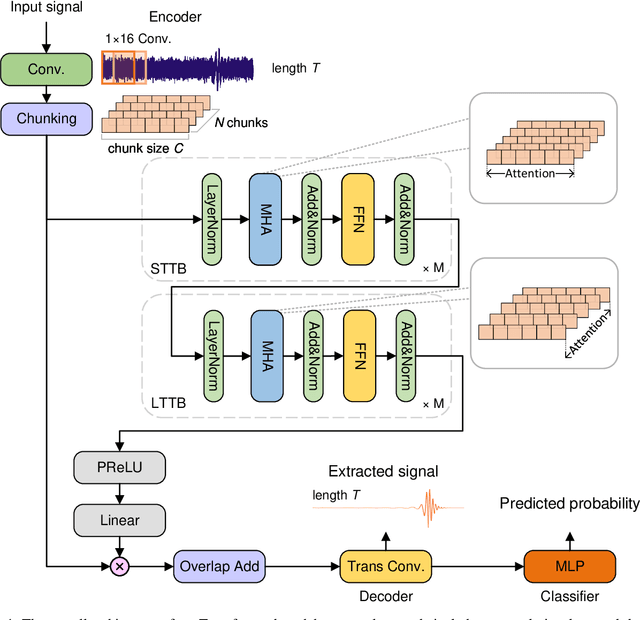

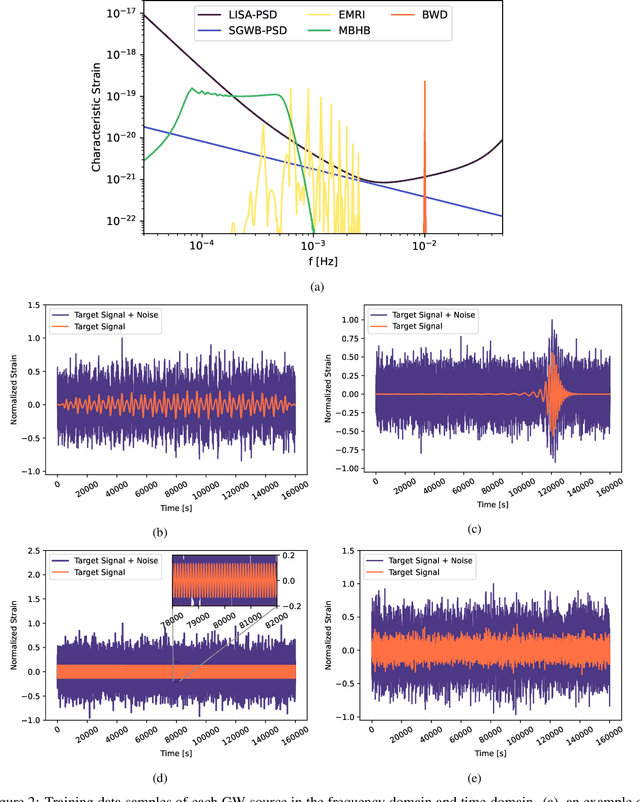
Space-based gravitational wave (GW) detectors will be able to observe signals from sources that are otherwise nearly impossible from current ground-based detection. Consequently, the well established signal detection method, matched filtering, will require a complex template bank, leading to a computational cost that is too expensive in practice. Here, we develop a high-accuracy GW signal detection and extraction method for all space-based GW sources. As a proof of concept, we show that a science-driven and uniform multi-stage deep neural network can identify synthetic signals that are submerged in Gaussian noise. Our method has more than 99% accuracy for signal detection of various sources while obtaining at least 95% similarity compared with target signals. We further demonstrate the interpretability and strong generalization behavior for several extended scenarios.
Underdetermined 2D-DOD and 2D-DOA Estimation for Bistatic Coprime EMVS-MIMO Radar: From the Difference Coarray Perspective
Jun 06, 2022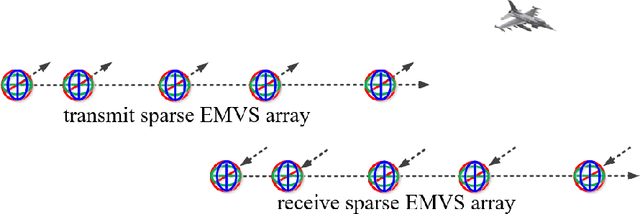
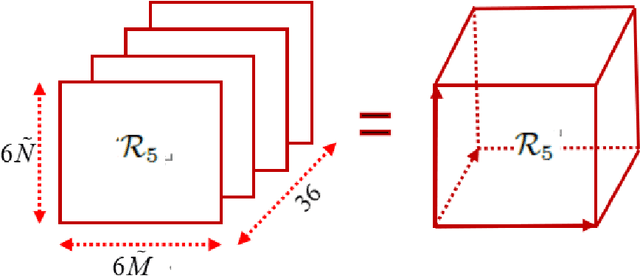
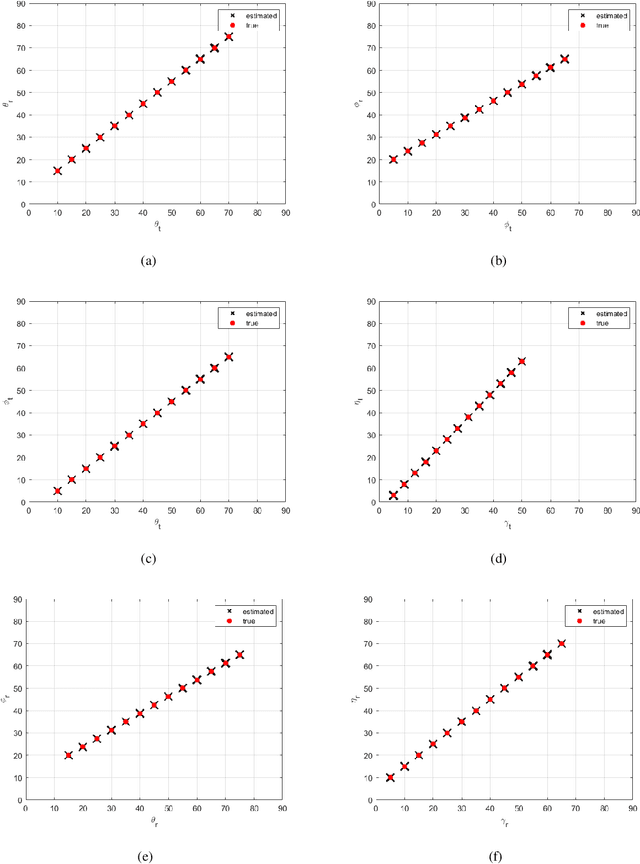
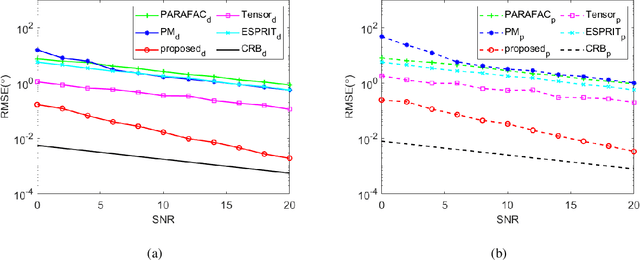
In this paper, the underdetermined 2D-DOD and 2D-DOA estimation for bistatic coprime EMVS-MIMO radar is considered. Firstly, a 5-D tensor model was constructed by using the multi-dimensional space-time characteristics of the received data. Then, an 8-D tensor has been obtained by using the auto-correlation calculation. To obtain the difference coarrays of transmit and receive EMVS, the de-coupling process between the spatial response of EMVS and the steering vector is inevitable. Thus, a new 6-D tensor can be constructed via the tensor permutation and the generalized tensorization of the canonical polyadic decomposition. {According} to the theory of the Tensor-Matrix Product operation, the duplicated elements in the difference coarrays can be removed by the utilization of two designed selection matrices. Due to the centrosymmetric geometry of the difference coarrays, two DFT beamspace matrices were subsequently designed to convert the complex steering matrices into the real-valued ones, whose advantage is to improve the estimation accuracy of the 2D-DODs and 2D-DOAs. Afterwards, a third-order tensor with the third-way fixed at 36 was constructed and the Parallel Factor algorithm was deployed, which can yield the closed-form automatically paired 2D-DOD and 2D-DOA estimation. The simulation results show that the proposed algorithm can exhibit superior estimation performance for the underdetermined 2D-DOD and 2D-DOA estimation.