 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models
Jun 16, 2023



Recent work has studied text-to-audio synthesis using large amounts of paired text-audio data. However, audio recordings with high-quality text annotations can be difficult to acquire. In this work, we approach text-to-audio synthesis using unlabeled videos and pretrained language-vision models. We propose to learn the desired text-audio correspondence by leveraging the visual modality as a bridge. We train a conditional diffusion model to generate the audio track of a video, given a video frame encoded by a pretrained contrastive language-image pretraining (CLIP) model. At test time, we first explore performing a zero-shot modality transfer and condition the diffusion model with a CLIP-encoded text query. However, we observe a noticeable performance drop with respect to image queries. To close this gap, we further adopt a pretrained diffusion prior model to generate a CLIP image embedding given a CLIP text embedding. Our results show the effectiveness of the proposed method, and that the pretrained diffusion prior can reduce the modality transfer gap. While we focus on text-to-audio synthesis, the proposed model can also generate audio from image queries, and it shows competitive performance against a state-of-the-art image-to-audio synthesis model in a subjective listening test. This study offers a new direction of approaching text-to-audio synthesis that leverages the naturally-occurring audio-visual correspondence in videos and the power of pretrained language-vision models.
CLIPSep: Learning Text-queried Sound Separation with Noisy Unlabeled Videos
Dec 14, 2022



Recent years have seen progress beyond domain-specific sound separation for speech or music towards universal sound separation for arbitrary sounds. Prior work on universal sound separation has investigated separating a target sound out of an audio mixture given a text query. Such text-queried sound separation systems provide a natural and scalable interface for specifying arbitrary target sounds. However, supervised text-queried sound separation systems require costly labeled audio-text pairs for training. Moreover, the audio provided in existing datasets is often recorded in a controlled environment, causing a considerable generalization gap to noisy audio in the wild. In this work, we aim to approach text-queried universal sound separation by using only unlabeled data. We propose to leverage the visual modality as a bridge to learn the desired audio-textual correspondence. The proposed CLIPSep model first encodes the input query into a query vector using the contrastive language-image pretraining (CLIP) model, and the query vector is then used to condition an audio separation model to separate out the target sound. While the model is trained on image-audio pairs extracted from unlabeled videos, at test time we can instead query the model with text inputs in a zero-shot setting, thanks to the joint language-image embedding learned by the CLIP model. Further, videos in the wild often contain off-screen sounds and background noise that may hinder the model from learning the desired audio-textual correspondence. To address this problem, we further propose an approach called noise invariant training for training a query-based sound separation model on noisy data. Experimental results show that the proposed models successfully learn text-queried universal sound separation using only noisy unlabeled videos, even achieving competitive performance against a supervised model in some settings.
Improving Choral Music Separation through Expressive Synthesized Data from Sampled Instruments
Sep 07, 2022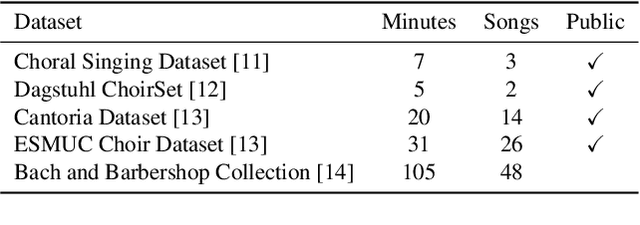
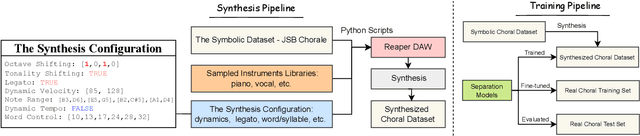
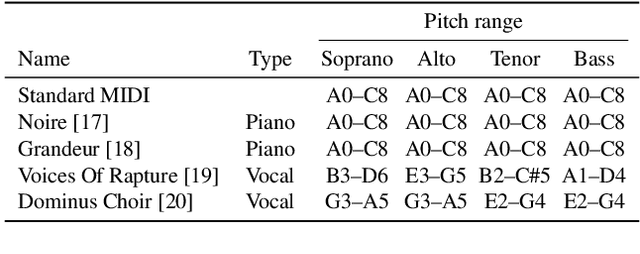

Choral music separation refers to the task of extracting tracks of voice parts (e.g., soprano, alto, tenor, and bass) from mixed audio. The lack of datasets has impeded research on this topic as previous work has only been able to train and evaluate models on a few minutes of choral music data due to copyright issues and dataset collection difficulties. In this paper, we investigate the use of synthesized training data for the source separation task on real choral music. We make three contributions: first, we provide an automated pipeline for synthesizing choral music data from sampled instrument plugins within controllable options for instrument expressiveness. This produces an 8.2-hour-long choral music dataset from the JSB Chorales Dataset and one can easily synthesize additional data. Second, we conduct an experiment to evaluate multiple separation models on available choral music separation datasets from previous work. To the best of our knowledge, this is the first experiment to comprehensively evaluate choral music separation. Third, experiments demonstrate that the synthesized choral data is of sufficient quality to improve the model's performance on real choral music datasets. This provides additional experimental statistics and data support for the choral music separation study.
* Camera Ready for Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022
Multitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments
Jul 14, 2022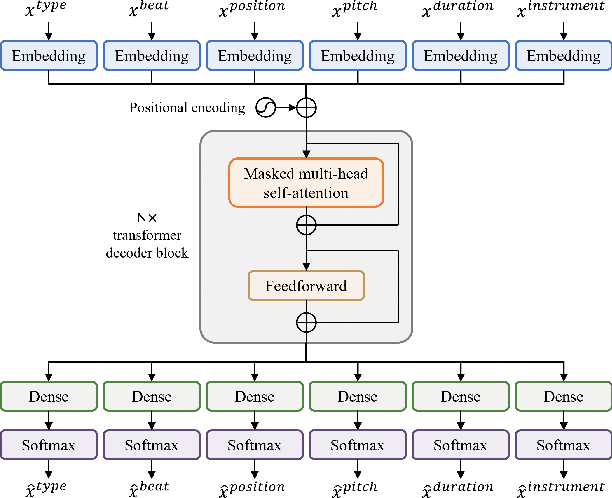
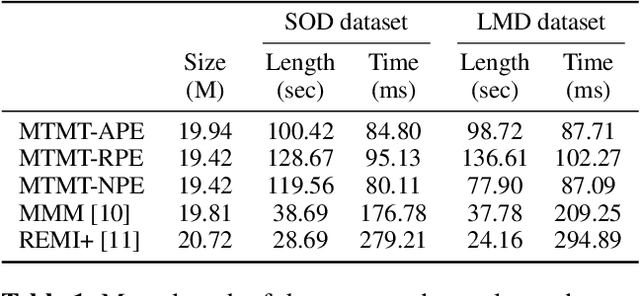
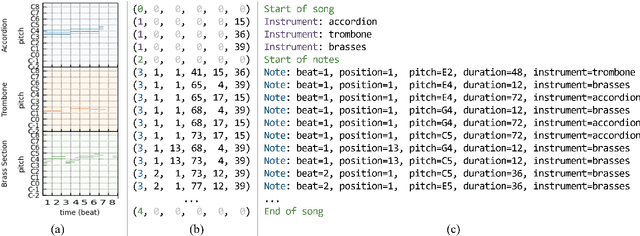
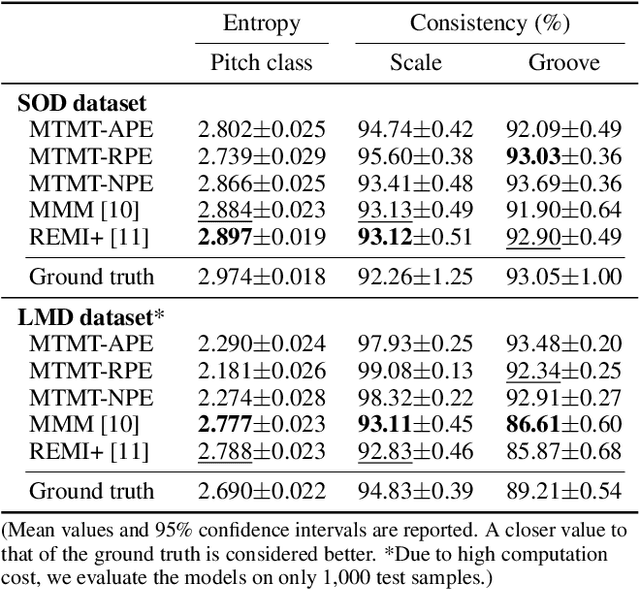
Existing approaches for generating multitrack music with transformer models have been limited to either a small set of instruments or short music segments. This is partly due to the memory requirements of the lengthy input sequences necessitated by existing representations for multitrack music. In this work, we propose a compact representation that allows a diverse set of instruments while keeping a short sequence length. Using our proposed representation, we present the Multitrack Music Transformer (MTMT) for learning long-term dependencies in multitrack music. In a subjective listening test, our proposed model achieves competitive quality on unconditioned generation against two baseline models. We also show that our proposed model can generate samples that are twice as long as those produced by the baseline models, and, further, can do so in half the inference time. Moreover, we propose a new measure for analyzing musical self-attentions and show that the trained model learns to pay less attention to notes that form a dissonant interval with the current note, yet attending more to notes that are 4N beats away from current. Finally, our findings provide a novel foundation for future work exploring longer-form multitrack music generation and improving self-attentions for music. All source code and audio samples can be found at https://salu133445.github.io/mtmt/ .
Deep Performer: Score-to-Audio Music Performance Synthesis
Feb 21, 2022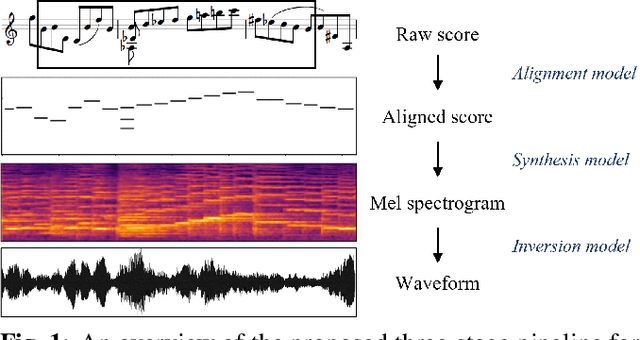

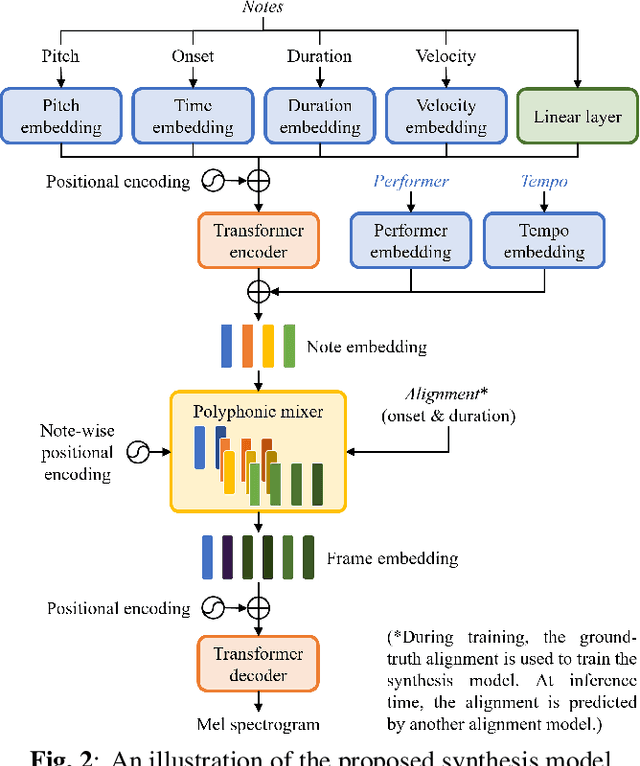

Music performance synthesis aims to synthesize a musical score into a natural performance. In this paper, we borrow recent advances in text-to-speech synthesis and present the Deep Performer -- a novel system for score-to-audio music performance synthesis. Unlike speech, music often contains polyphony and long notes. Hence, we propose two new techniques for handling polyphonic inputs and providing a fine-grained conditioning in a transformer encoder-decoder model. To train our proposed system, we present a new violin dataset consisting of paired recordings and scores along with estimated alignments between them. We show that our proposed model can synthesize music with clear polyphony and harmonic structures. In a listening test, we achieve competitive quality against the baseline model, a conditional generative audio model, in terms of pitch accuracy, timbre and noise level. Moreover, our proposed model significantly outperforms the baseline on an existing piano dataset in overall quality.
An Empirical Evaluation of End-to-End Polyphonic Optical Music Recognition
Aug 03, 2021
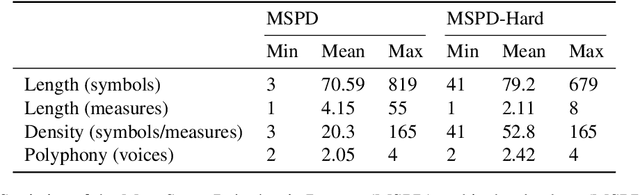
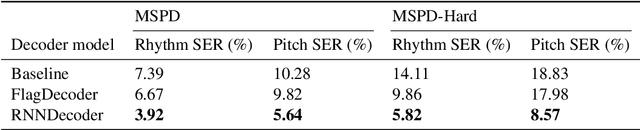
Previous work has shown that neural architectures are able to perform optical music recognition (OMR) on monophonic and homophonic music with high accuracy. However, piano and orchestral scores frequently exhibit polyphonic passages, which add a second dimension to the task. Monophonic and homophonic music can be described as homorhythmic, or having a single musical rhythm. Polyphonic music, on the other hand, can be seen as having multiple rhythmic sequences, or voices, concurrently. We first introduce a workflow for creating large-scale polyphonic datasets suitable for end-to-end recognition from sheet music publicly available on the MuseScore forum. We then propose two novel formulations for end-to-end polyphonic OMR -- one treating the problem as a type of multi-task binary classification, and the other treating it as multi-sequence detection. Building upon the encoder-decoder architecture and an image encoder proposed in past work on end-to-end OMR, we propose two novel decoder models -- FlagDecoder and RNNDecoder -- that correspond to the two formulations. Finally, we compare the empirical performance of these end-to-end approaches to polyphonic OMR and observe a new state-of-the-art performance with our multi-sequence detection decoder, RNNDecoder.
Towards Automatic Instrumentation by Learning to Separate Parts in Symbolic Multitrack Music
Jul 13, 2021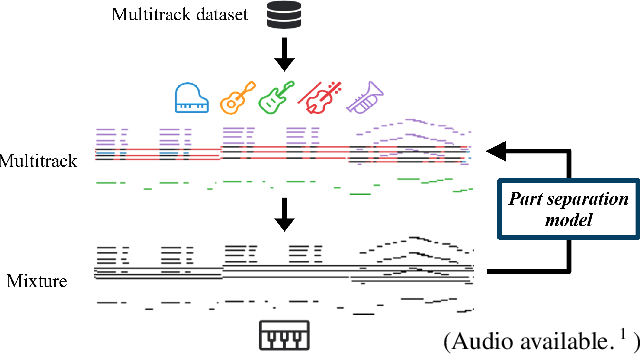


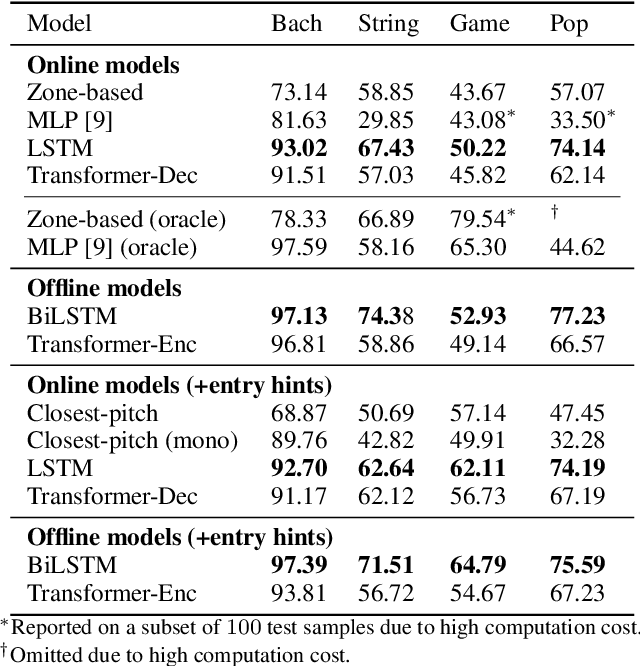
Modern keyboards allow a musician to play multiple instruments at the same time by assigning zones -- fixed pitch ranges of the keyboard -- to different instruments. In this paper, we aim to further extend this idea and examine the feasibility of automatic instrumentation -- dynamically assigning instruments to notes in solo music during performance. In addition to the online, real-time-capable setting for performative use cases, automatic instrumentation can also find applications in assistive composing tools in an offline setting. Due to the lack of paired data of original solo music and their full arrangements, we approach automatic instrumentation by learning to separate parts (e.g., voices, instruments and tracks) from their mixture in symbolic multitrack music, assuming that the mixture is to be played on a keyboard. We frame the task of part separation as a sequential multi-class classification problem and adopt machine learning to map sequences of notes into sequences of part labels. To examine the effectiveness of our proposed models, we conduct a comprehensive empirical evaluation over four diverse datasets of different genres and ensembles -- Bach chorales, string quartets, game music and pop music. Our experiments show that the proposed models outperform various baselines. We also demonstrate the potential for our proposed models to produce alternative convincing instrumentations for an existing arrangement by separating its mixture into parts. All source code and audio samples can be found at https://salu133445.github.io/arranger/ .
MusPy: A Toolkit for Symbolic Music Generation
Aug 05, 2020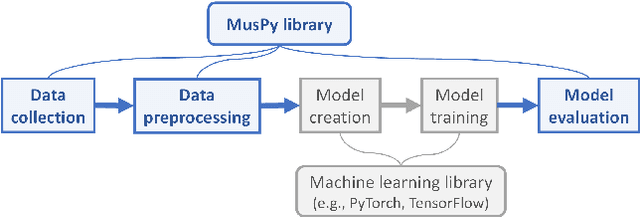
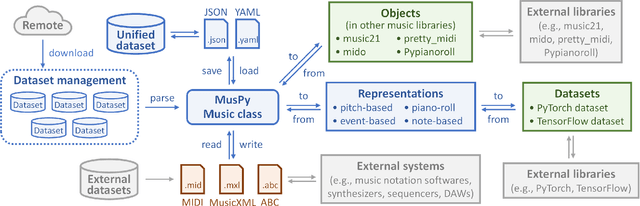
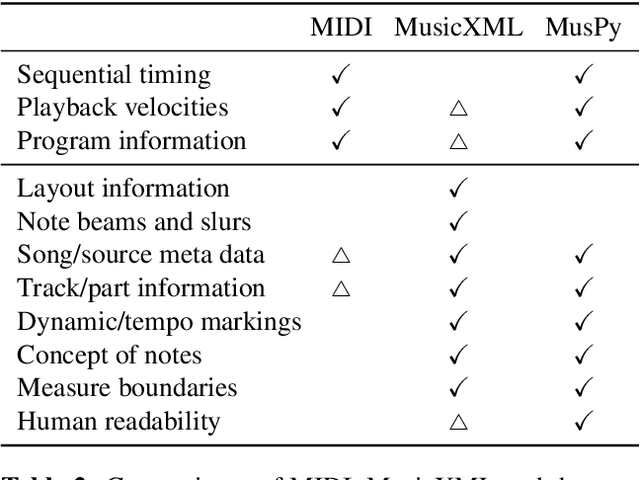
In this paper, we present MusPy, an open source Python library for symbolic music generation. MusPy provides easy-to-use tools for essential components in a music generation system, including dataset management, data I/O, data preprocessing and model evaluation. In order to showcase its potential, we present statistical analysis of the eleven datasets currently supported by MusPy. Moreover, we conduct a cross-dataset generalizability experiment by training an autoregressive model on each dataset and measuring held-out likelihood on the others---a process which is made easier by MusPy's dataset management system. The results provide a map of domain overlap between various commonly used datasets and show that some datasets contain more representative cross-genre samples than others. Along with the dataset analysis, these results might serve as a guide for choosing datasets in future research. Source code and documentation are available at https://github.com/salu133445/muspy .
Automatic Melody Harmonization with Triad Chords: A Comparative Study
Jan 08, 2020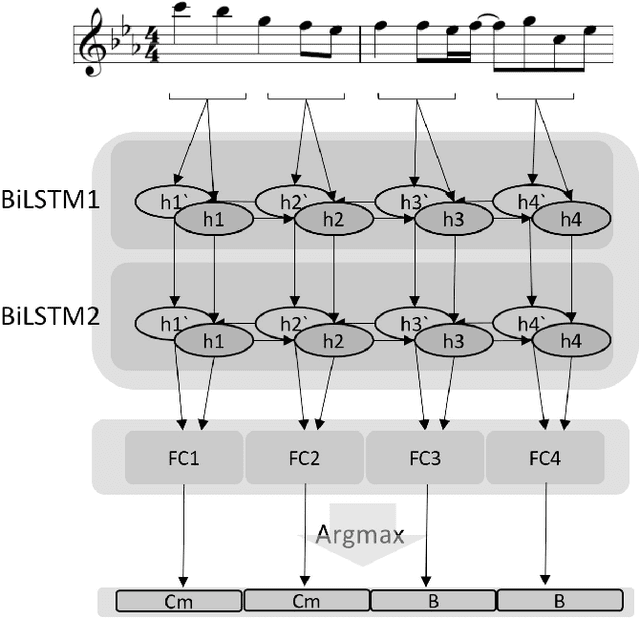
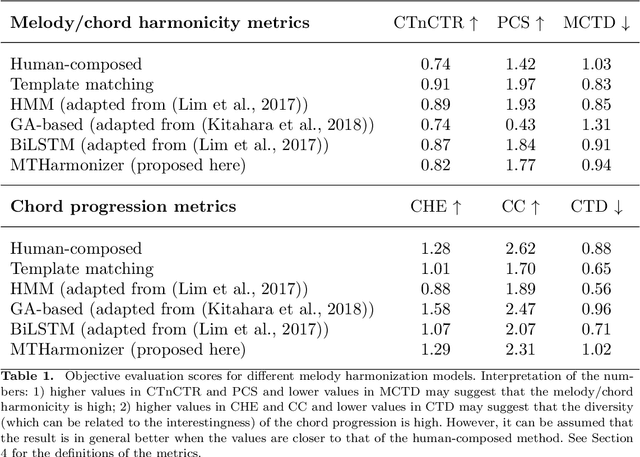
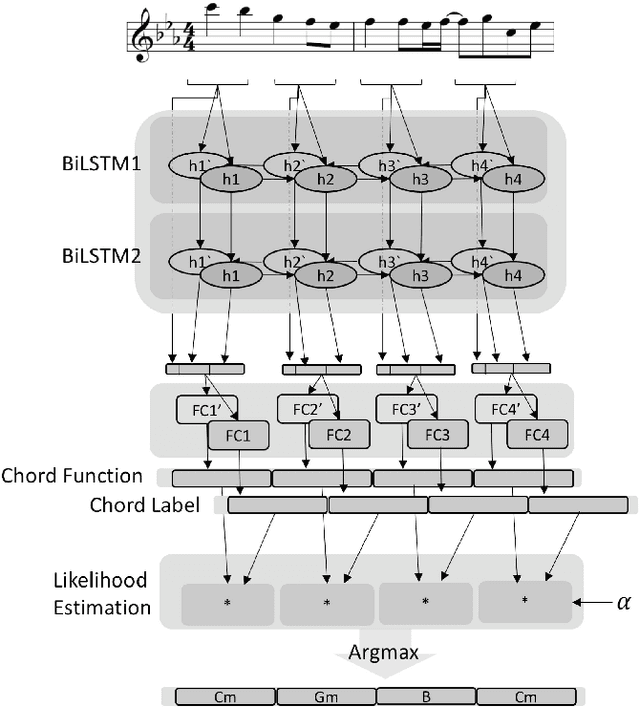

Several prior works have proposed various methods for the task of automatic melody harmonization, in which a model aims to generate a sequence of chords to serve as the harmonic accompaniment of a given multiple-bar melody sequence. In this paper, we present a comparative study evaluating and comparing the performance of a set of canonical approaches to this task, including a template matching based model, a hidden Markov based model, a genetic algorithm based model, and two deep learning based models. The evaluation is conducted on a dataset of 9,226 melody/chord pairs we newly collect for this study, considering up to 48 triad chords, using a standardized training/test split. We report the result of an objective evaluation using six different metrics and a subjective study with 202 participants.
Towards a Deeper Understanding of Adversarial Losses
Jan 25, 2019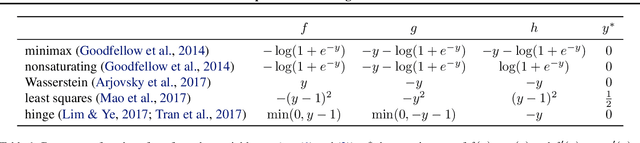

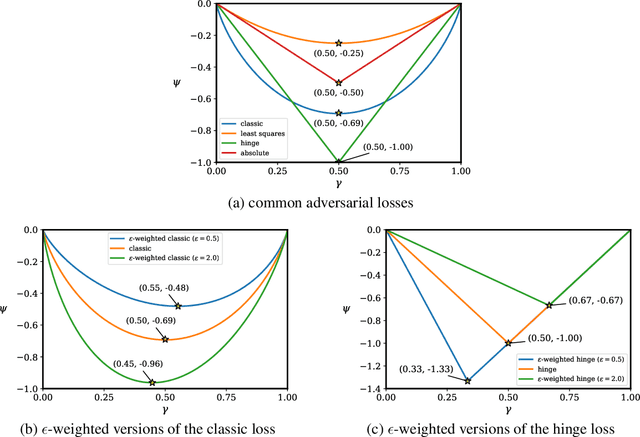

Recent work has proposed various adversarial losses for training generative adversarial networks. Yet, it remains unclear what certain types of functions are valid adversarial loss functions, and how these loss functions perform against one another. In this paper, we aim to gain a deeper understanding of adversarial losses by decoupling the effects of their component functions and regularization terms. We first derive some necessary and sufficient conditions of the component functions such that the adversarial loss is a divergence-like measure between the data and the model distributions. In order to systematically compare different adversarial losses, we then propose DANTest, a new, simple framework based on discriminative adversarial networks. With this framework, we evaluate an extensive set of adversarial losses by combining different component functions and regularization approaches. This study leads to some new insights into the adversarial losses. For reproducibility, all source code is available at https://github.com/salu133445/dan .