 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRDr: Automatic Masking of Exudates and Microaneurysms Caused By Diabetic Retinopathy Using Mask R-CNN and Transfer Learning
Jul 04, 2020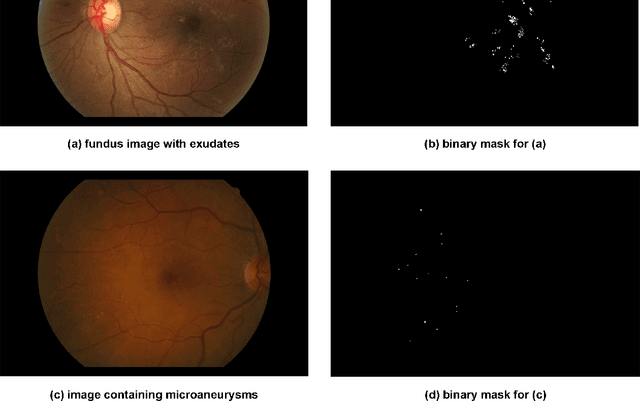

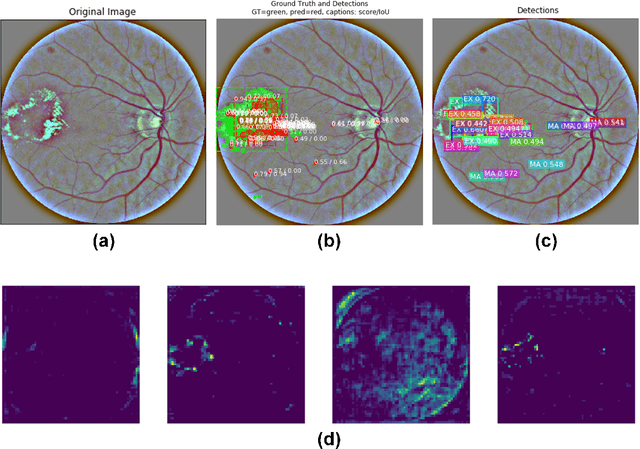
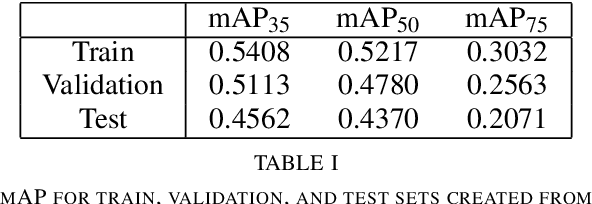
This paper addresses the problem of identifying two main types of lesions - Exudates and Microaneurysms - caused by Diabetic Retinopathy (DR) in the eyes of diabetic patients. We make use of Convolutional Neural Networks (CNNs) and Transfer Learning to locate and generate high-quality segmentation mask for each instance of the lesion that can be found in the patients' fundus images. We create our normalized database out of e-ophtha EX and e-ophtha MA and tweak Mask R-CNN to detect small lesions. Moreover, we employ data augmentation and the pre-trained weights of ResNet101 to compensate for our small dataset. Our model achieves promising test mAP of 0.45, altogether showing that it can aid clinicians and ophthalmologist in the process of detecting and treating the infamous DR.
On Parameter Tuning in Meta-learning for Computer Vision
Feb 11, 2020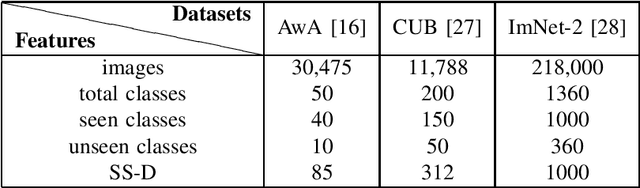
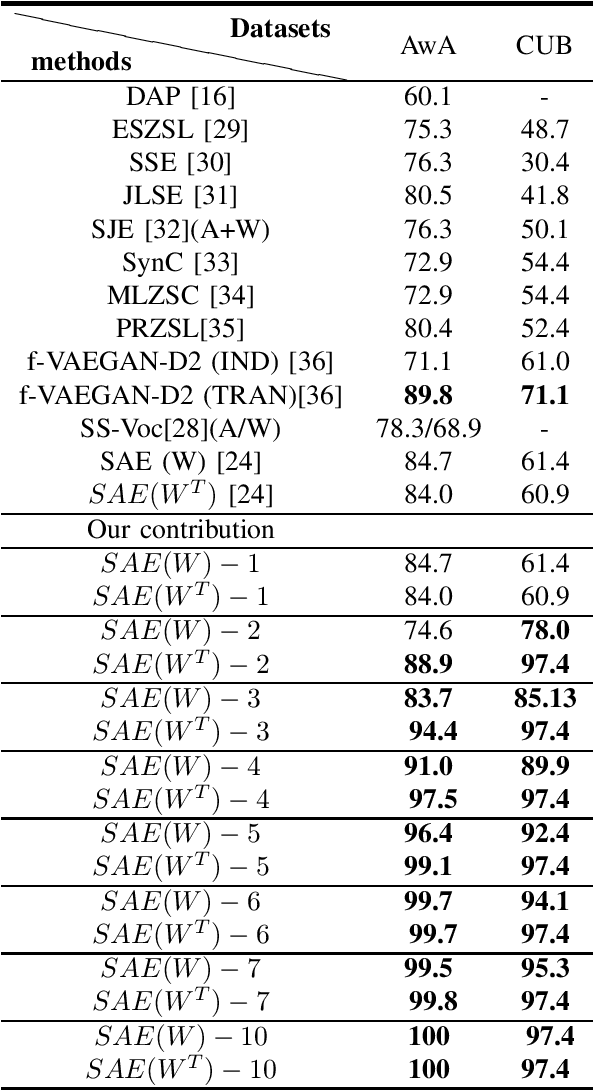
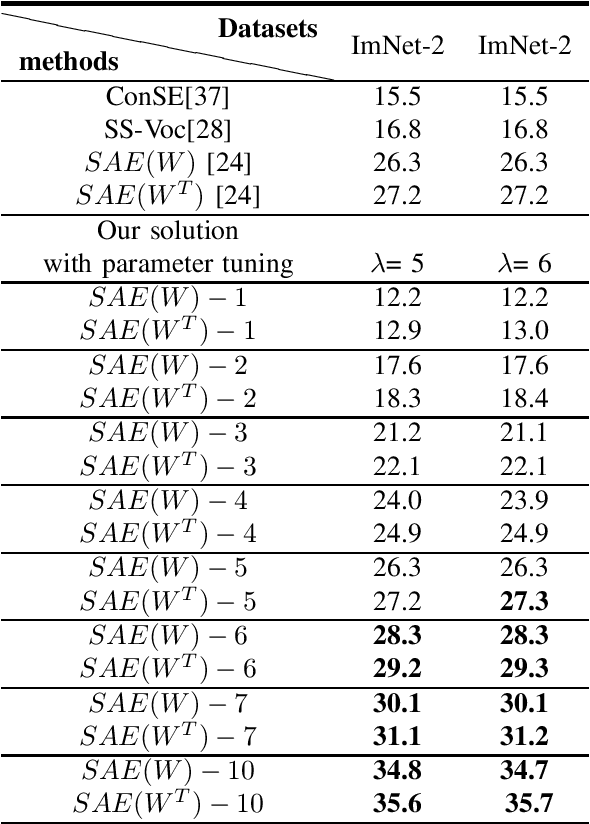
Learning to learn plays a pivotal role in meta-learning (MTL) to obtain an optimal learning model. In this paper, we investigate mage recognition for unseen categories of a given dataset with limited training information. We deploy a zero-shot learning (ZSL) algorithm to achieve this goal. We also explore the effect of parameter tuning on performance of semantic auto-encoder (SAE). We further address the parameter tuning problem for meta-learning, especially focusing on zero-shot learning. By combining different embedded parameters, we improved the accuracy of tuned-SAE. Advantages and disadvantages of parameter tuning and its application in image classification are also explored.
Deep Learning at the Edge
Oct 22, 2019The ever-increasing number of Internet of Things (IoT) devices has created a new computing paradigm, called edge computing, where most of the computations are performed at the edge devices, rather than on centralized servers. An edge device is an electronic device that provides connections to service providers and other edge devices; typically, such devices have limited resources. Since edge devices are resource-constrained, the task of launching algorithms, methods, and applications onto edge devices is considered to be a significant challenge. In this paper, we discuss one of the most widely used machine learning methods, namely, Deep Learning (DL) and offer a short survey on the recent approaches used to map DL onto the edge computing paradigm. We also provide relevant discussions about selected applications that would greatly benefit from DL at the edge.
An Introduction to Advanced Machine Learning : Meta Learning Algorithms, Applications and Promises
Aug 26, 2019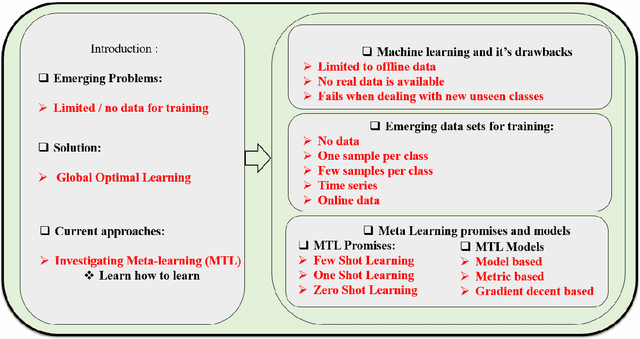
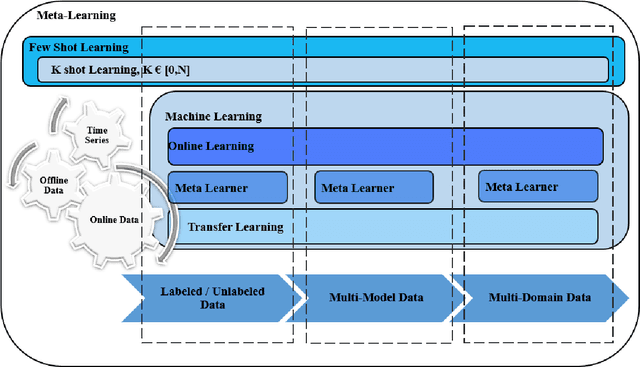
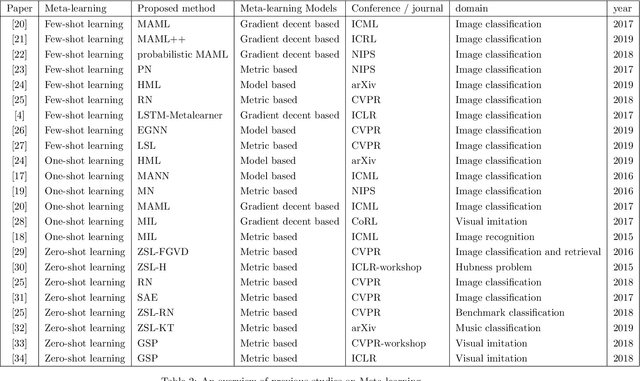
In [1, 2], we have explored the theoretical aspects of feature extraction optimization processes for solving largescale problems and overcoming machine learning limitations. Majority of optimization algorithms that have been introduced in [1, 2] guarantee the optimal performance of supervised learning, given offline and discrete data, to deal with curse of dimensionality (CoD) problem. These algorithms, however, are not tailored for solving emerging learning problems. One of the important issues caused by online data is lack of sufficient samples per class. Further, traditional machine learning algorithms cannot achieve accurate training based on limited distributed data, as data has proliferated and dispersed significantly. Machine learning employs a strict model or embedded engine to train and predict which still fails to learn unseen classes and sufficiently use online data. In this chapter, we introduce these challenges elaborately. We further investigate Meta-Learning (MTL) algorithm, and their application and promises to solve the emerging problems by answering how autonomous agents can learn to learn?.
Applications of Nature-Inspired Algorithms for Dimension Reduction: Enabling Efficient Data Analytics
Aug 22, 2019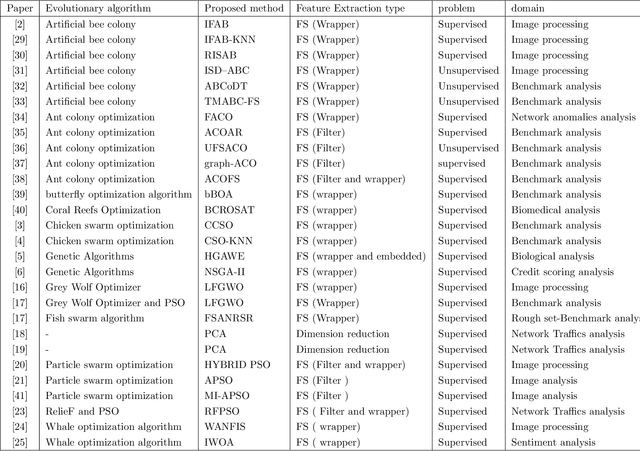
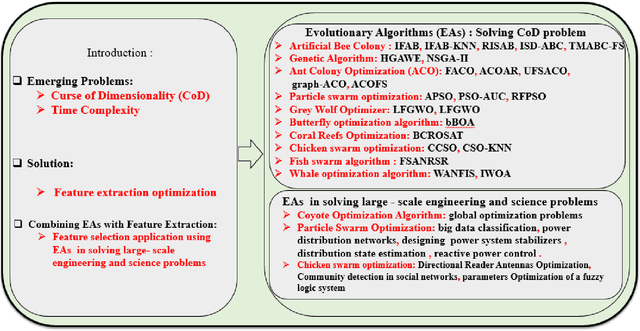
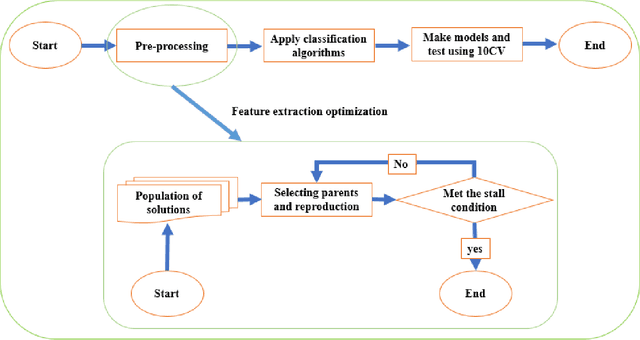
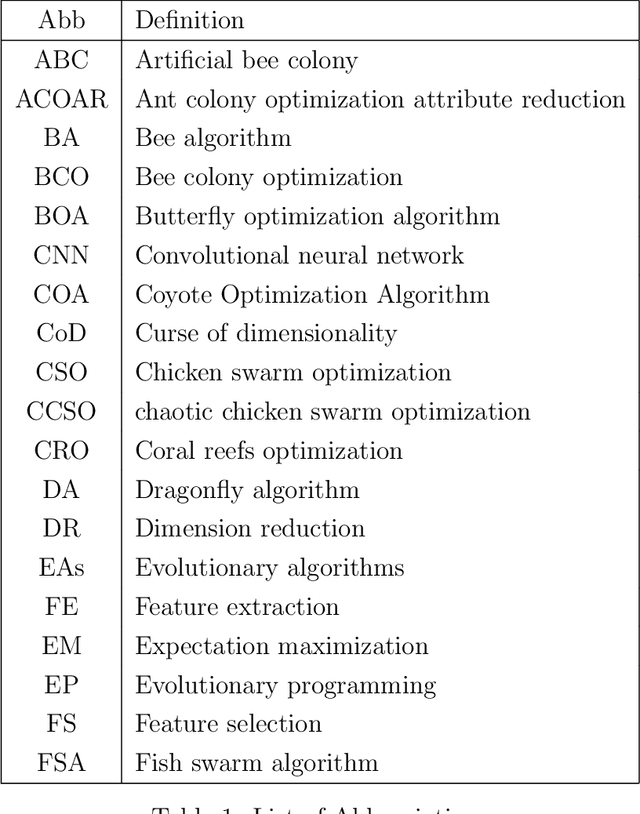
In [1], we have explored the theoretical aspects of feature selection and evolutionary algorithms. In this chapter, we focus on optimization algorithms for enhancing data analytic process, i.e., we propose to explore applications of nature-inspired algorithms in data science. Feature selection optimization is a hybrid approach leveraging feature selection techniques and evolutionary algorithms process to optimize the selected features. Prior works solve this problem iteratively to converge to an optimal feature subset. Feature selection optimization is a non-specific domain approach. Data scientists mainly attempt to find an advanced way to analyze data n with high computational efficiency and low time complexity, leading to efficient data analytics. Thus, by increasing generated/measured/sensed data from various sources, analysis, manipulation and illustration of data grow exponentially. Due to the large scale data sets, Curse of dimensionality (CoD) is one of the NP-hard problems in data science. Hence, several efforts have been focused on leveraging evolutionary algorithms (EAs) to address the complex issues in large scale data analytics problems. Dimension reduction, together with EAs, lends itself to solve CoD and solve complex problems, in terms of time complexity, efficiently. In this chapter, we first provide a brief overview of previous studies that focused on solving CoD using feature extraction optimization process. We then discuss practical examples of research studies are successfully tackled some application domains, such as image processing, sentiment analysis, network traffics / anomalies analysis, credit score analysis and other benchmark functions/data sets analysis.
Evolutionary Computation, Optimization and Learning Algorithms for Data Science
Aug 16, 2019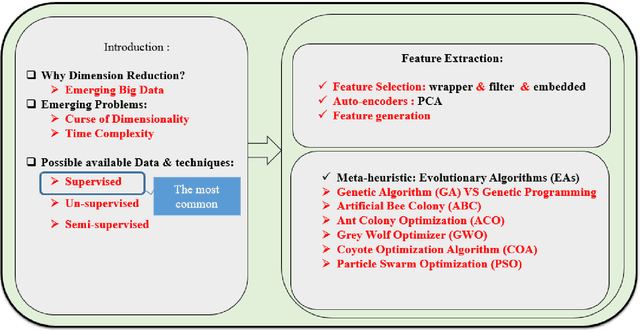

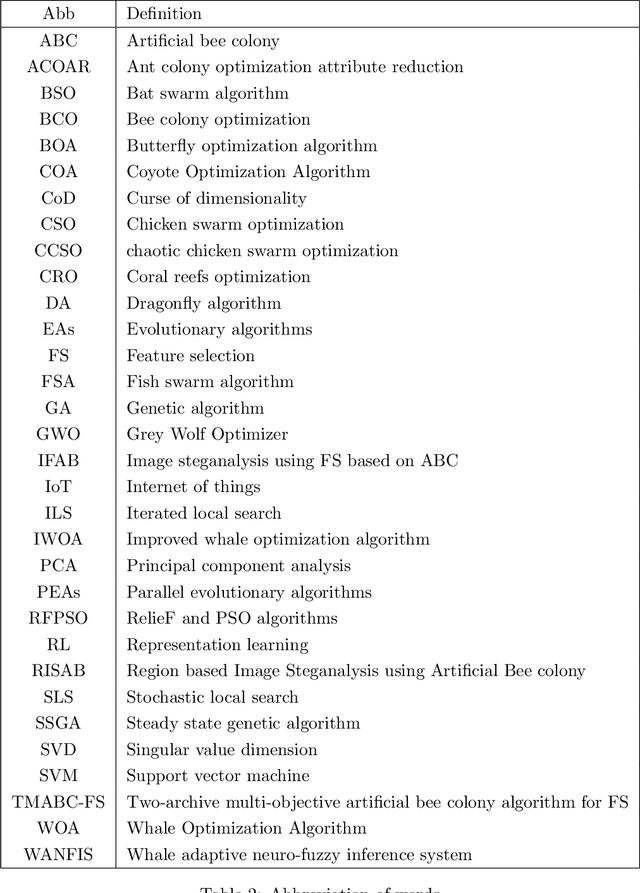
A large number of engineering, science and computational problems have yet to be solved in a computationally efficient way. One of the emerging challenges is how evolving technologies grow towards autonomy and intelligent decision making. This leads to collection of large amounts of data from various sensing and measurement technologies, e.g., cameras, smart phones, health sensors, smart electricity meters, and environment sensors. Hence, it is imperative to develop efficient algorithms for generation, analysis, classification, and illustration of data. Meanwhile, data is structured purposefully through different representations, such as large-scale networks and graphs. We focus on data science as a crucial area, specifically focusing on a curse of dimensionality (CoD) which is due to the large amount of generated/sensed/collected data. This motivates researchers to think about optimization and to apply nature-inspired algorithms, such as evolutionary algorithms (EAs) to solve optimization problems. Although these algorithms look un-deterministic, they are robust enough to reach an optimal solution. Researchers do not adopt evolutionary algorithms unless they face a problem which is suffering from placement in local optimal solution, rather than global optimal solution. In this chapter, we first develop a clear and formal definition of the CoD problem, next we focus on feature extraction techniques and categories, then we provide a general overview of meta-heuristic algorithms, its terminology, and desirable properties of evolutionary algorithms.
ISEA: Image Steganalysis using Evolutionary Algorithms
Jul 23, 2019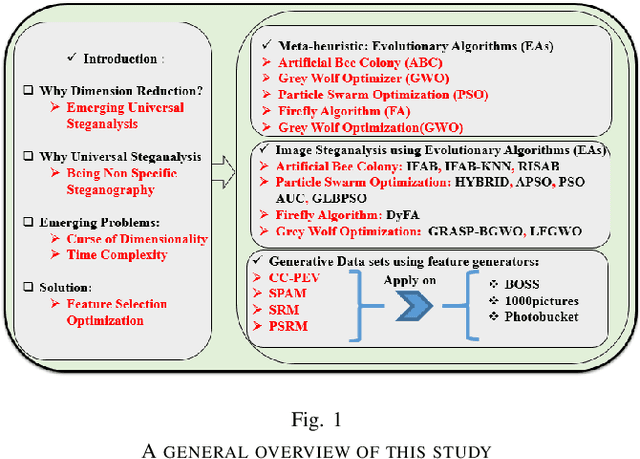
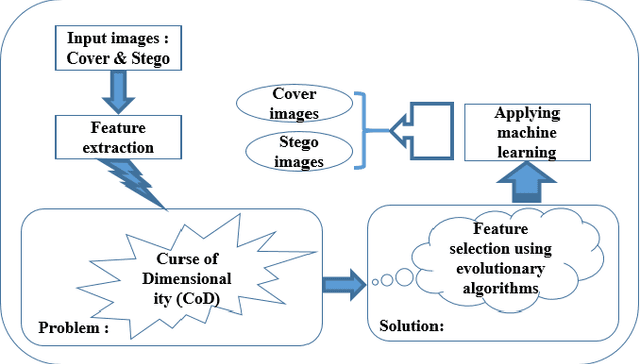
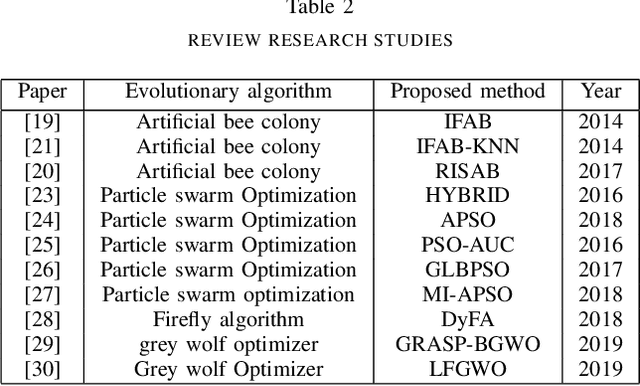
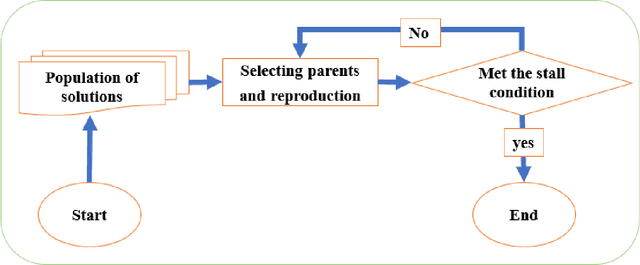
NP-hard problems always have been attracting scientists' attentions, and most often seen in the emerging challenging issues. The most interesting NP-hard problems emerging in the world of data science is Curse of dimensionality (CoD). Recently, this problem has penetrated most of high technology domains like advanced image processing, particularly image steganalysis. The universal and smarter steganalysis algorithms provide a huge number of attributes, which make working with data hard to process. In large data sets, finding a pattern which governs whole data takes long time, and yet no guarantee to reach the optimal pattern. In general, the purpose of the researchers in image steganalysis stands for distinguishing stego images from cover images. In this paper, we investigated recent works on detecting stego images, particularly those algorithms that adopted evolutionary algorithms. Thus, our work is categorized as supervised learning which consider ground truth to evaluate the performance of given algorithm. The objective is to provide a comprehensive understanding of evolutionary algorithms which are attempted to solve this NP-hard problems.
The SWAG Algorithm; a Mathematical Approach that Outperforms Traditional Deep Learning. Theory and Implementation
Nov 28, 2018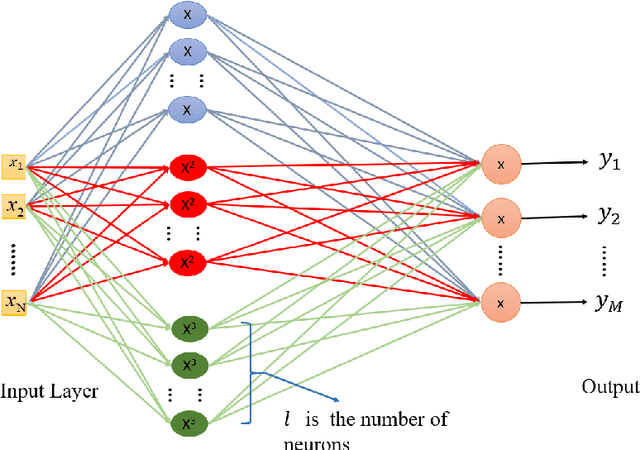
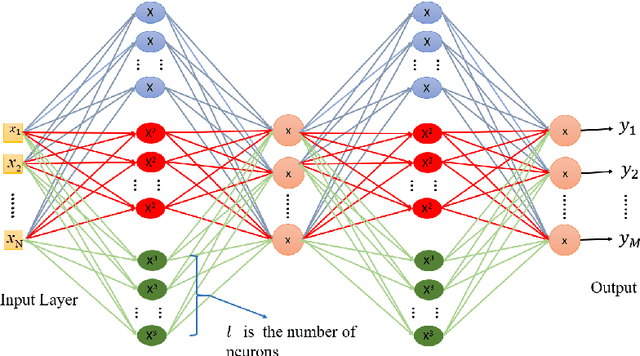
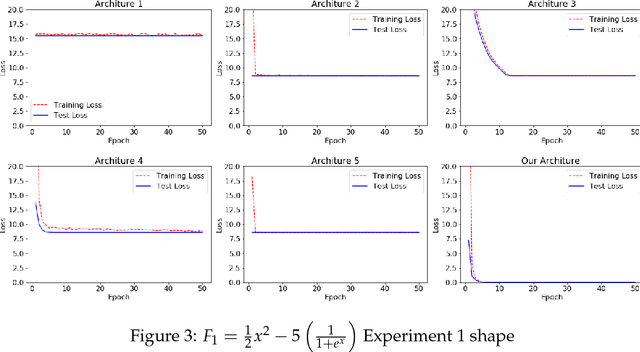
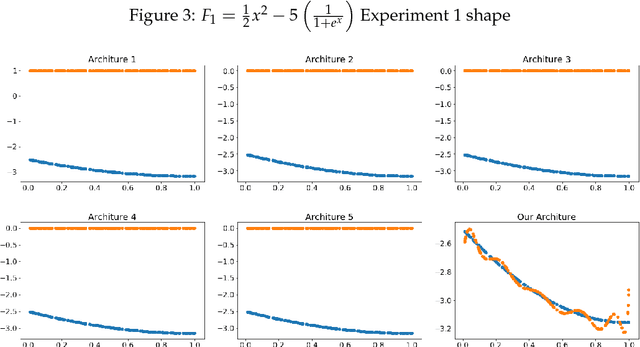
The performance of artificial neural networks (ANNs) is influenced by weight initialization, the nature of activation functions, and their architecture. There is a wide range of activation functions that are traditionally used to train a neural network, e.g. sigmoid, tanh, and Rectified Linear Unit (ReLU). A widespread practice is to use the same type of activation function in all neurons in a given layer. In this manuscript, we present a type of neural network in which the activation functions in every layer form a polynomial basis; we name this method SWAG after the initials of the last names of the authors. We tested SWAG on three complex highly non-linear functions as well as the MNIST handwriting data set. SWAG outperforms and converges faster than the state of the art performance in fully connected neural networks. Given the low computational complexity of SWAG, and the fact that it was capable of solving problems current architectures cannot, it has the potential to change the way that we approach deep learning.