 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigging Deeper into Egocentric Gaze Prediction
Apr 12, 2019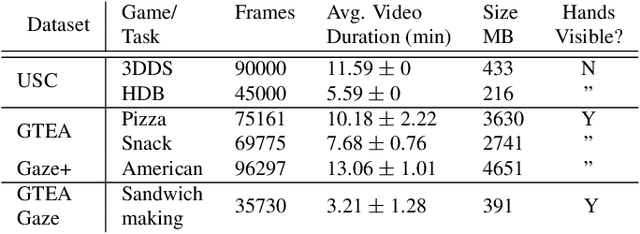

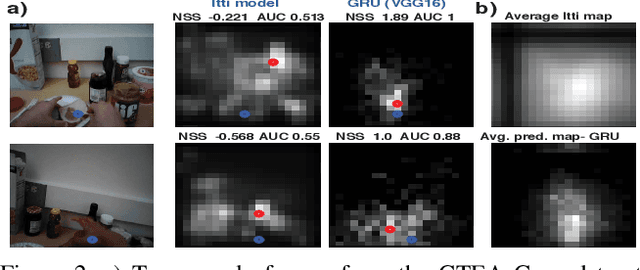
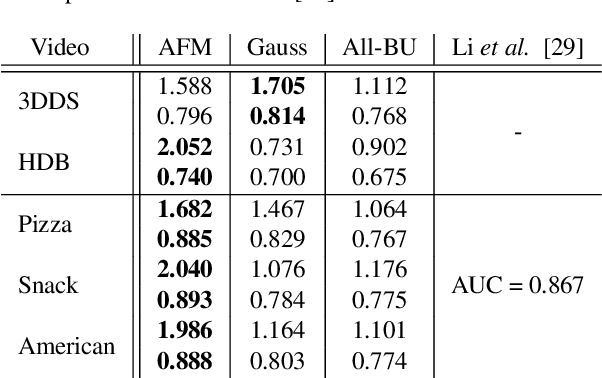
This paper digs deeper into factors that influence egocentric gaze. Instead of training deep models for this purpose in a blind manner, we propose to inspect factors that contribute to gaze guidance during daily tasks. Bottom-up saliency and optical flow are assessed versus strong spatial prior baselines. Task-specific cues such as vanishing point, manipulation point, and hand regions are analyzed as representatives of top-down information. We also look into the contribution of these factors by investigating a simple recurrent neural model for ego-centric gaze prediction. First, deep features are extracted for all input video frames. Then, a gated recurrent unit is employed to integrate information over time and to predict the next fixation. We also propose an integrated model that combines the recurrent model with several top-down and bottom-up cues. Extensive experiments over multiple datasets reveal that (1) spatial biases are strong in egocentric videos, (2) bottom-up saliency models perform poorly in predicting gaze and underperform spatial biases, (3) deep features perform better compared to traditional features, (4) as opposed to hand regions, the manipulation point is a strong influential cue for gaze prediction, (5) combining the proposed recurrent model with bottom-up cues, vanishing points and, in particular, manipulation point results in the best gaze prediction accuracy over egocentric videos, (6) the knowledge transfer works best for cases where the tasks or sequences are similar, and (7) task and activity recognition can benefit from gaze prediction. Our findings suggest that (1) there should be more emphasis on hand-object interaction and (2) the egocentric vision community should consider larger datasets including diverse stimuli and more subjects.
Understanding and Visualizing Deep Visual Saliency Models
Apr 03, 2019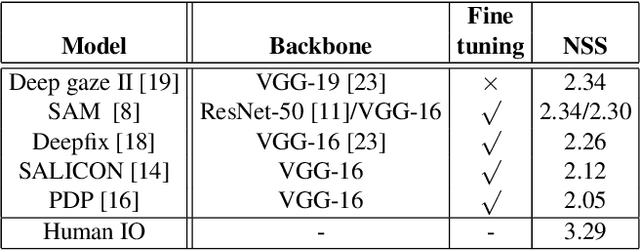
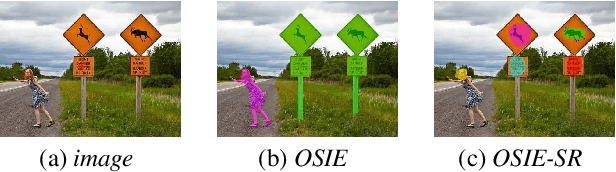

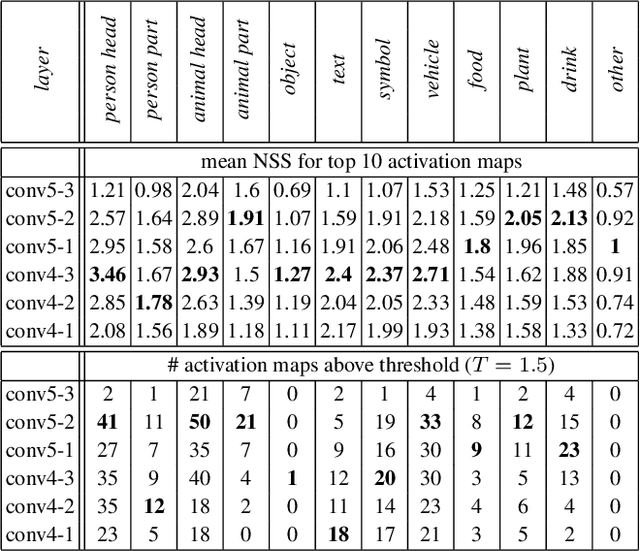
Recently, data-driven deep saliency models have achieved high performance and have outperformed classical saliency models, as demonstrated by results on datasets such as the MIT300 and SALICON. Yet, there remains a large gap between the performance of these models and the inter-human baseline. Some outstanding questions include what have these models learned, how and where they fail, and how they can be improved. This article attempts to answer these questions by analyzing the representations learned by individual neurons located at the intermediate layers of deep saliency models. To this end, we follow the steps of existing deep saliency models, that is borrowing a pre-trained model of object recognition to encode the visual features and learning a decoder to infer the saliency. We consider two cases when the encoder is used as a fixed feature extractor and when it is fine-tuned, and compare the inner representations of the network. To study how the learned representations depend on the task, we fine-tune the same network using the same image set but for two different tasks: saliency prediction versus scene classification. Our analyses reveal that: 1) some visual regions (e.g. head, text, symbol, vehicle) are already encoded within various layers of the network pre-trained for object recognition, 2) using modern datasets, we find that fine-tuning pre-trained models for saliency prediction makes them favor some categories (e.g. head) over some others (e.g. text), 3) although deep models of saliency outperform classical models on natural images, the converse is true for synthetic stimuli (e.g. pop-out search arrays), an evidence of significant difference between human and data-driven saliency models, and 4) we confirm that, after-fine tuning, the change in inner-representations is mostly due to the task and not the domain shift in the data.
A Synchronized Multi-Modal Attention-Caption Dataset and Analysis
Mar 06, 2019
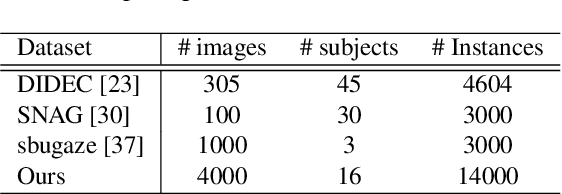
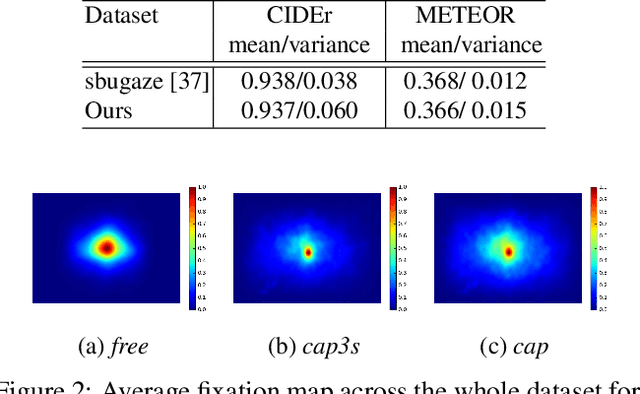

In this work, we present a novel multi-modal dataset consisting of eye movements and verbal descriptions recorded synchronously over images. Using this data, we study the differences between human attention in free-viewing and image captioning tasks. We look into the relationship between human attention and language constructs during perception and sentence articulation. We also compare human and machine attention, in particular the top-down soft attention approach that is argued to mimick human attention, in captioning tasks. Our study reveals that, (1) human attention behaviour in free-viewing is different than image description as humans tend to fixate on a greater variety of regions under the latter task; (2) there is a strong relationship between the described objects and the objects attended by subjects ($97\%$ of described objects are being attended); (3) a convolutional neural network as feature encoder captures regions that human attend under image captioning to a great extent (around $78\%$); (4) the soft-attention as the top-down mechanism does not agree with human attention behaviour neither spatially nor temporally; and (5) soft-attention does not add strong beneficial human-like attention behaviour for the task of captioning as it has low correlation between caption scores and attention consistency scores, indicating a large gap between human and machine in regard to top-down attention.
Semantic Matching by Weakly Supervised 2D Point Set Registration
Jan 24, 2019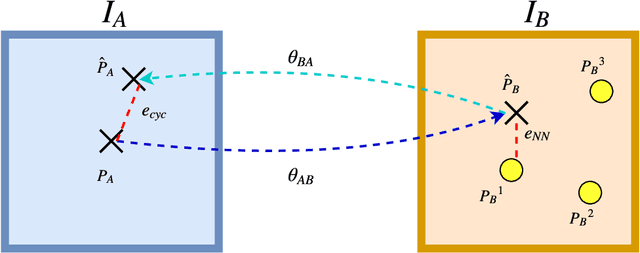
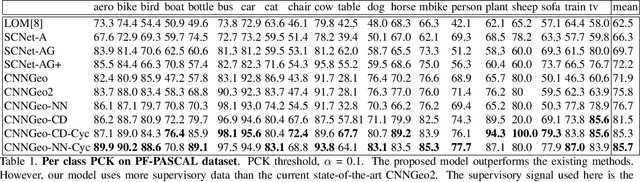

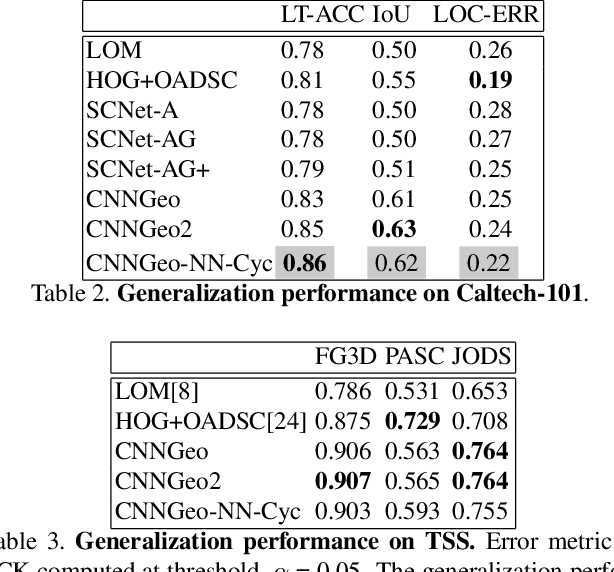
In this paper we address the problem of establishing correspondences between different instances of the same object. The problem is posed as finding the geometric transformation that aligns a given image pair. We use a convolutional neural network (CNN) to directly regress the parameters of the transformation model. The alignment problem is defined in the setting where an unordered set of semantic key-points per image are available, but, without the correspondence information. To this end we propose a novel loss function based on cyclic consistency that solves this 2D point set registration problem by inferring the optimal geometric transformation model parameters. We train and test our approach on a standard benchmark dataset Proposal-Flow (PF-PASCAL)\cite{proposal_flow}. The proposed approach achieves state-of-the-art results demonstrating the effectiveness of the method. In addition, we show our approach further benefits from additional training samples in PF-PASCAL generated by using category level information.
Bottom-up Attention, Models of
Oct 11, 2018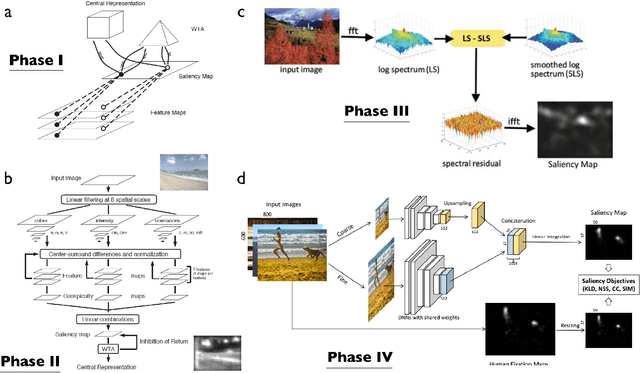

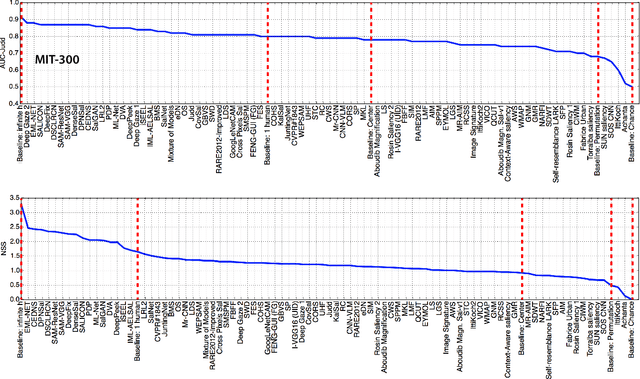
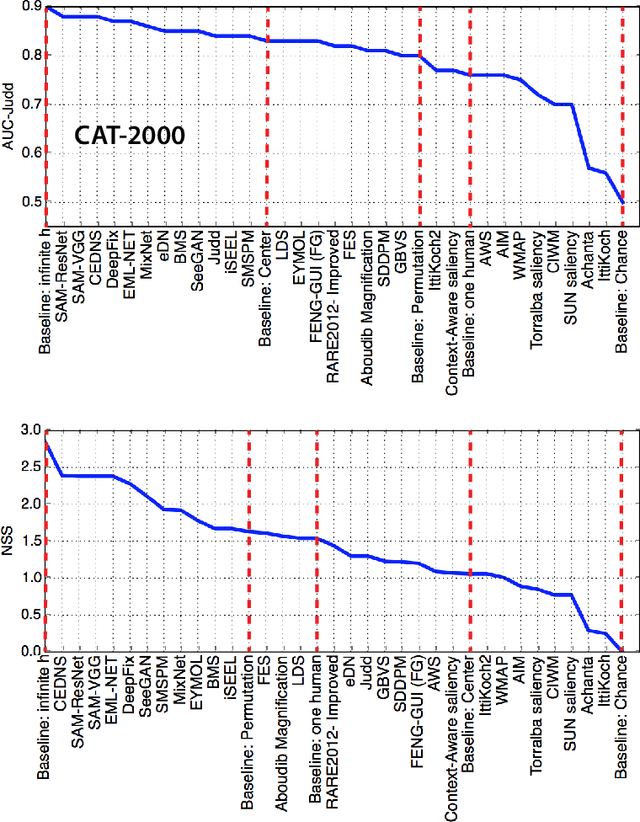
In this review, we examine the recent progress in saliency prediction and proposed several avenues for future research. In spite of tremendous efforts and huge progress, there is still room for improvement in terms finer-grained analysis of deep saliency models, evaluation measures, datasets, annotation methods, cognitive studies, and new applications. This chapter will appear in Encyclopedia of Computational Neuroscience.
Towards Instance Segmentation with Object Priority: Prominent Object Detection and Recognition
Aug 04, 2017

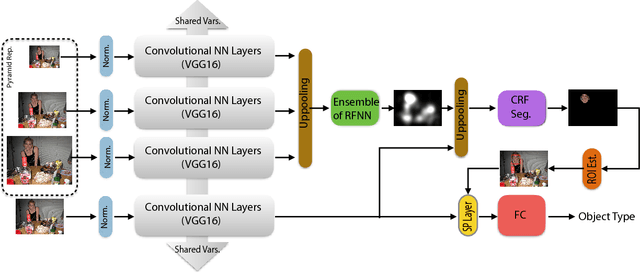
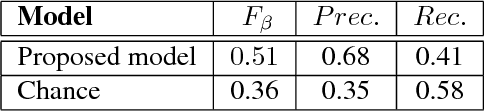
This manuscript introduces the problem of prominent object detection and recognition inspired by the fact that human seems to priorities perception of scene elements. The problem deals with finding the most important region of interest, segmenting the relevant item/object in that area, and assigning it an object class label. In other words, we are solving the three problems of saliency modeling, saliency detection, and object recognition under one umbrella. The motivation behind such a problem formulation is (1) the benefits to the knowledge representation-based vision pipelines, and (2) the potential improvements in emulating bio-inspired vision systems by solving these three problems together. We are foreseeing extending this problem formulation to fully semantically segmented scenes with instance object priority for high-level inferences in various applications including assistive vision. Along with a new problem definition, we also propose a method to achieve such a task. The proposed model predicts the most important area in the image, segments the associated objects, and labels them. The proposed problem and method are evaluated against human fixations, annotated segmentation masks, and object class categories. We define a chance level for each of the evaluation criterion to compare the proposed algorithm with. Despite the good performance of the proposed baseline, the overall evaluations indicate that the problem of prominent object detection and recognition is a challenging task that is still worth investigating further.
Paying Attention to Descriptions Generated by Image Captioning Models
Aug 04, 2017
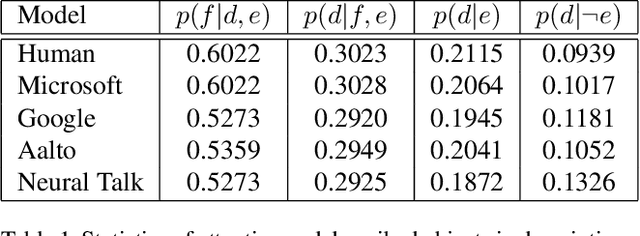
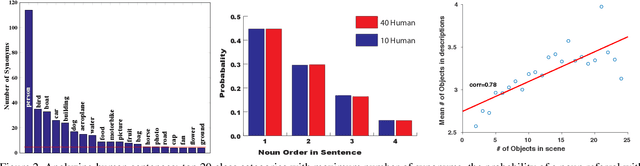
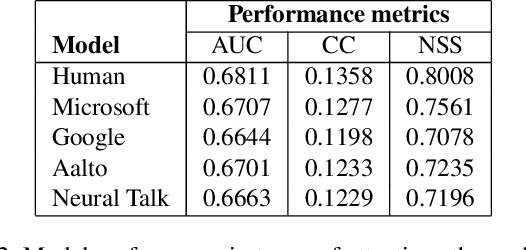
To bridge the gap between humans and machines in image understanding and describing, we need further insight into how people describe a perceived scene. In this paper, we study the agreement between bottom-up saliency-based visual attention and object referrals in scene description constructs. We investigate the properties of human-written descriptions and machine-generated ones. We then propose a saliency-boosted image captioning model in order to investigate benefits from low-level cues in language models. We learn that (1) humans mention more salient objects earlier than less salient ones in their descriptions, (2) the better a captioning model performs, the better attention agreement it has with human descriptions, (3) the proposed saliency-boosted model, compared to its baseline form, does not improve significantly on the MS COCO database, indicating explicit bottom-up boosting does not help when the task is well learnt and tuned on a data, (4) a better generalization is, however, observed for the saliency-boosted model on unseen data.
Saliency Revisited: Analysis of Mouse Movements versus Fixations
May 30, 2017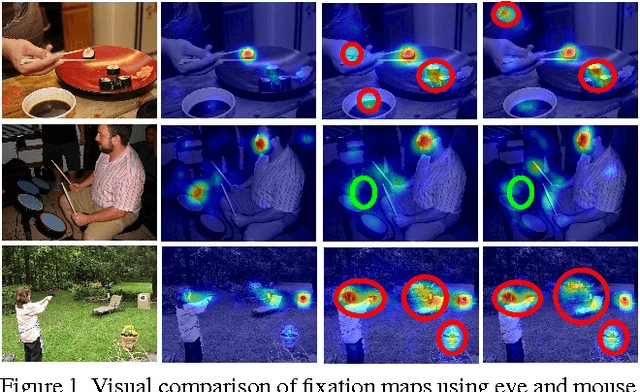
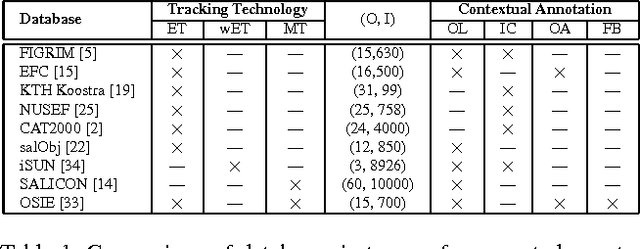
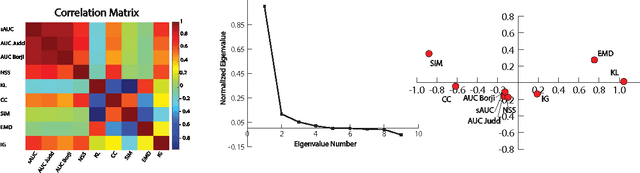

This paper revisits visual saliency prediction by evaluating the recent advancements in this field such as crowd-sourced mouse tracking-based databases and contextual annotations. We pursue a critical and quantitative approach towards some of the new challenges including the quality of mouse tracking versus eye tracking for model training and evaluation. We extend quantitative evaluation of models in order to incorporate contextual information by proposing an evaluation methodology that allows accounting for contextual factors such as text, faces, and object attributes. The proposed contextual evaluation scheme facilitates detailed analysis of models and helps identify their pros and cons. Through several experiments, we find that (1) mouse tracking data has lower inter-participant visual congruency and higher dispersion, compared to the eye tracking data, (2) mouse tracking data does not totally agree with eye tracking in general and in terms of different contextual regions in specific, and (3) mouse tracking data leads to acceptable results in training current existing models, and (4) mouse tracking data is less reliable for model selection and evaluation. The contextual evaluation also reveals that, among the studied models, there is no single model that performs best on all the tested annotations.
Investigating Natural Image Pleasantness Recognition using Deep Features and Eye Tracking for Loosely Controlled Human-computer Interaction
Apr 07, 2017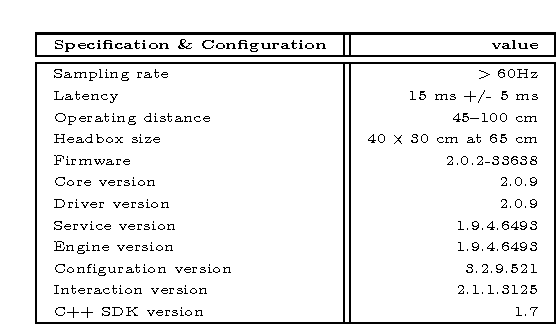
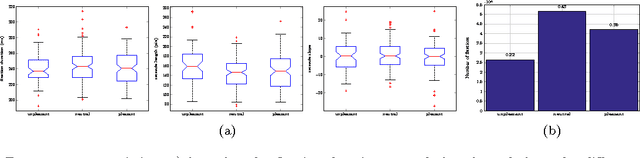
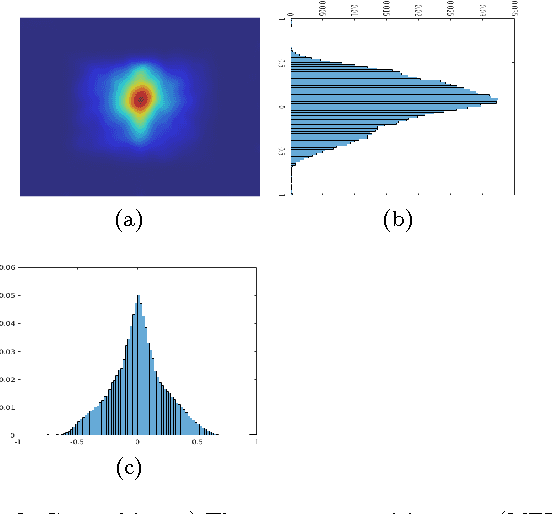
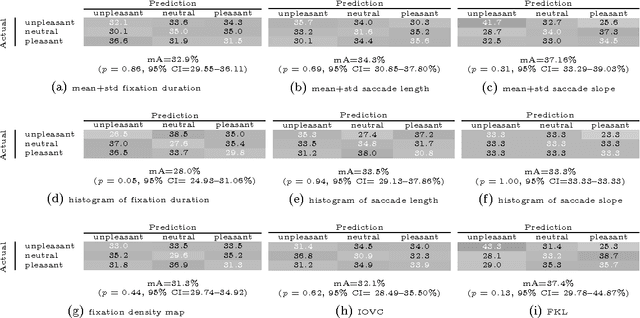
This paper revisits recognition of natural image pleasantness by employing deep convolutional neural networks and affordable eye trackers. There exist several approaches to recognize image pleasantness: (1) computer vision, and (2) psychophysical signals. For natural images, computer vision approaches have not been as successful as for abstract paintings and is lagging behind the psychophysical signals like eye movements. Despite better results, the scalability of eye movements is adversely affected by the sensor cost. While the introduction of affordable sensors have helped the scalability issue by making the sensors more accessible, the application of such sensors in a loosely controlled human-computer interaction setup is not yet studied for affective image tagging. On the other hand, deep convolutional neural networks have boosted the performance of vision-based techniques significantly in recent years. To investigate the current status in regard to affective image tagging, we (1) introduce a new eye movement dataset using an affordable eye tracker, (2) study the use of deep neural networks for pleasantness recognition, (3) investigate the gap between deep features and eye movements. To meet these ends, we record eye movements in a less controlled setup, akin to daily human-computer interaction. We assess features from eye movements, visual features, and their combination. Our results show that (1) recognizing natural image pleasantness from eye movement under less restricted setup is difficult and previously used techniques are prone to fail, and (2) visual class categories are strong cues for predicting pleasantness, due to their correlation with emotions, necessitating careful study of this phenomenon. This latter finding is alerting as some deep learning approaches may fit to the class category bias.