 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Suitability of Neural Networks as Building Blocks for The Design of Efficient Learned Indexes
Feb 21, 2022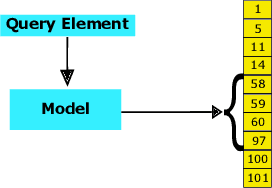
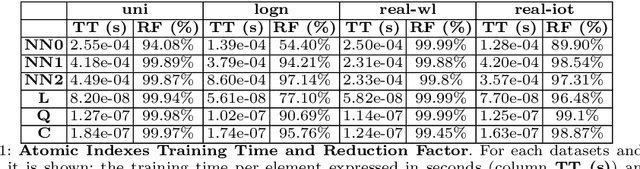


With the aim of obtaining time/space improvements in classic Data Structures, an emerging trend is to combine Machine Learning techniques with the ones proper of Data Structures. This new area goes under the name of Learned Data Structures. The motivation for its study is a perceived change of paradigm in Computer Architectures that would favour the use of Graphics Processing Units and Tensor Processing Units over conventional Central Processing Units. In turn, that would favour the use of Neural Networks as building blocks of Classic Data Structures. Indeed, Learned Bloom Filters, which are one of the main pillars of Learned Data Structures, make extensive use of Neural Networks to improve the performance of classic Filters. However, no use of Neural Networks is reported in the realm of Learned Indexes, which is another main pillar of that new area. In this contribution, we provide the first, and much needed, comparative experimental analysis regarding the use of Neural Networks as building blocks of Learned Indexes. The results reported here highlight the need for the design of very specialized Neural Networks tailored to Learned Indexes and it establishes a solid ground for those developments. Our findings, methodologically important, are of interest to both Scientists and Engineers working in Neural Networks Design and Implementation, in view also of the importance of the application areas involved, e.g., Computer Networks and Data Bases.