 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemifreddoNets: Partially Frozen Neural Networks for Efficient Computer Vision Systems
Jun 12, 2020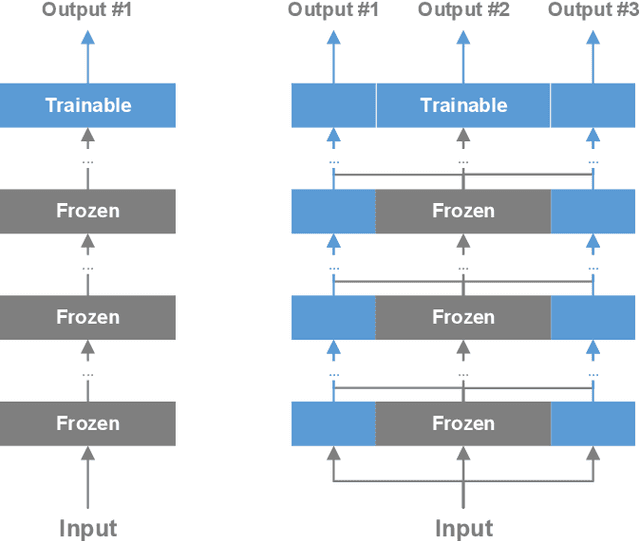
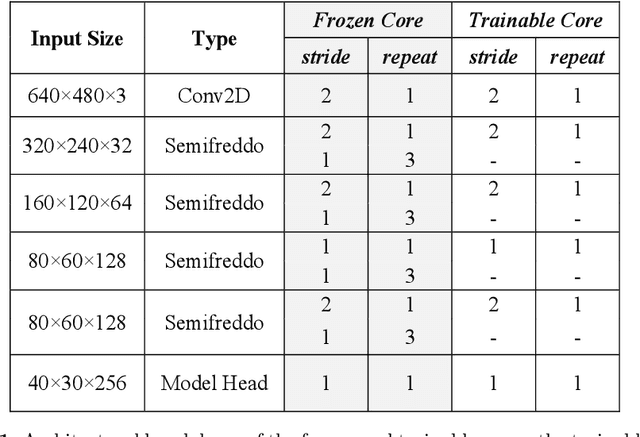
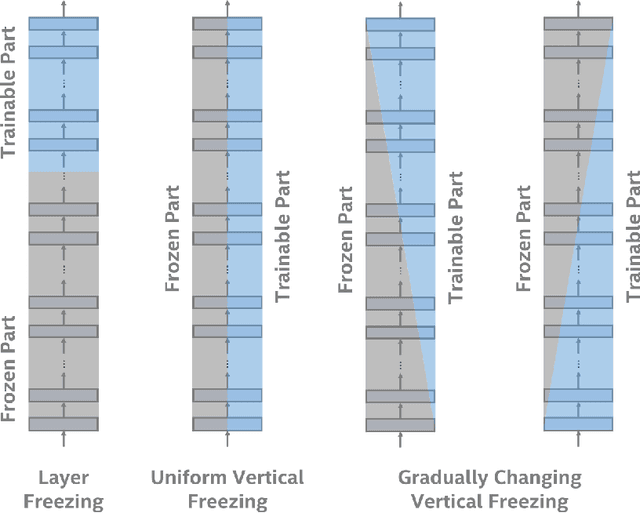
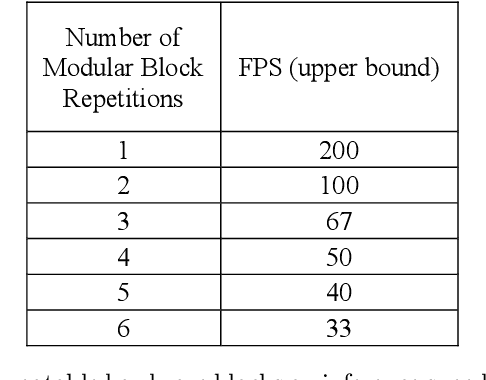
We propose a system comprised of fixed-topology neural networks having partially frozen weights, named SemifreddoNets. SemifreddoNets work as fully-pipelined hardware blocks that are optimized to have an efficient hardware implementation. Those blocks freeze a certain portion of the parameters at every layer and replace the corresponding multipliers with fixed scalers. Fixing the weights reduces the silicon area, logic delay, and memory requirements, leading to significant savings in cost and power consumption. Unlike traditional layer-wise freezing approaches, SemifreddoNets make a profitable trade between the cost and flexibility by having some of the weights configurable at different scales and levels of abstraction in the model. Although fixing the topology and some of the weights somewhat limits the flexibility, we argue that the efficiency benefits of this strategy outweigh the advantages of a fully configurable model for many use cases. Furthermore, our system uses repeatable blocks, therefore it has the flexibility to adjust model complexity without requiring any hardware change. The hardware implementation of SemifreddoNets provides up to an order of magnitude reduction in silicon area and power consumption as compared to their equivalent implementation on a general-purpose accelerator.
A Machine Learning Imaging Core using Separable FIR-IIR Filters
Jan 02, 2020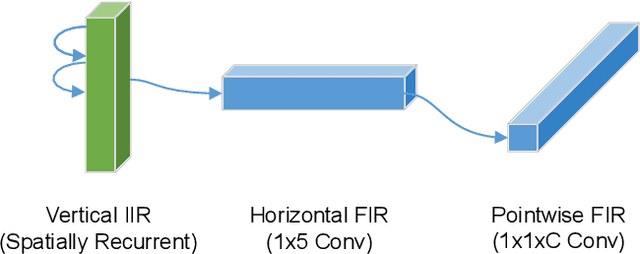
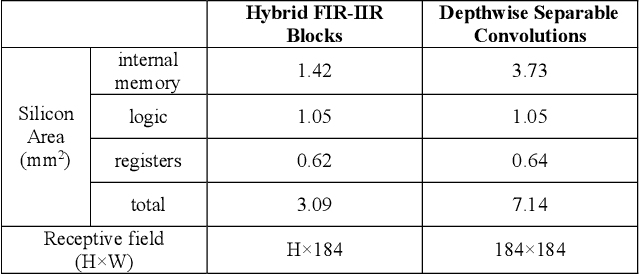
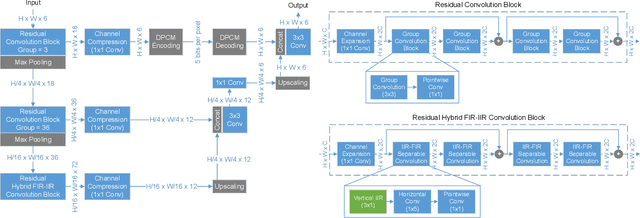
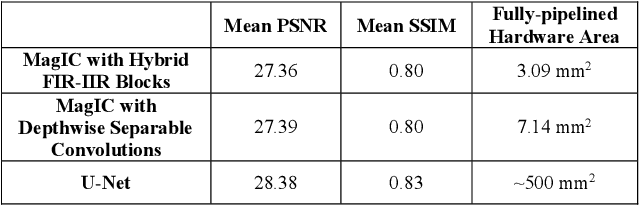
We propose fixed-function neural network hardware that is designed to perform pixel-to-pixel image transformations in a highly efficient way. We use a fully trainable, fixed-topology neural network to build a model that can perform a wide variety of image processing tasks. Our model uses compressed skip lines and hybrid FIR-IIR blocks to reduce the latency and hardware footprint. Our proposed Machine Learning Imaging Core, dubbed MagIC, uses a silicon area of ~3mm^2 (in TSMC 16nm), which is orders of magnitude smaller than a comparable pixel-wise dense prediction model. MagIC requires no DDR bandwidth, no SRAM, and practically no external memory. Each MagIC core consumes 56mW (215 mW max power) at 500MHz and achieves an energy-efficient throughput of 23TOPS/W/mm^2. MagIC can be used as a multi-purpose image processing block in an imaging pipeline, approximating compute-heavy image processing applications, such as image deblurring, denoising, and colorization, within the power and silicon area limits of mobile devices.
VisionISP: Repurposing the Image Signal Processor for Computer Vision Applications
Nov 14, 2019
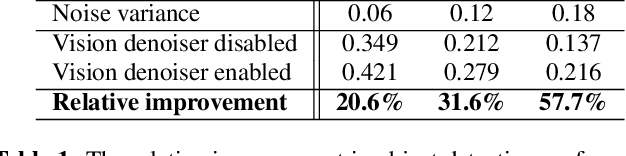


Traditional image signal processors (ISPs) are primarily designed and optimized to improve the image quality perceived by humans. However, optimal perceptual image quality does not always translate into optimal performance for computer vision applications. We propose a set of methods, which we collectively call VisionISP, to repurpose the ISP for machine consumption. VisionISP significantly reduces data transmission needs by reducing the bit-depth and resolution while preserving the relevant information. The blocks in VisionISP are simple, content-aware, and trainable. Experimental results show that VisionISP boosts the performance of a subsequent computer vision system trained to detect objects in an autonomous driving setting. The results demonstrate the potential and the practicality of VisionISP for computer vision applications.
Eye Contact Correction using Deep Neural Networks
Jun 12, 2019


In a typical video conferencing setup, it is hard to maintain eye contact during a call since it requires looking into the camera rather than the display. We propose an eye contact correction model that restores the eye contact regardless of the relative position of the camera and display. Unlike previous solutions, our model redirects the gaze from an arbitrary direction to the center without requiring a redirection angle or camera/display/user geometry as inputs. We use a deep convolutional neural network that inputs a monocular image and produces a vector field and a brightness map to correct the gaze. We train this model in a bi-directional way on a large set of synthetically generated photorealistic images with perfect labels. The learned model is a robust eye contact corrector which also predicts the input gaze implicitly at no additional cost. Our system is primarily designed to improve the quality of video conferencing experience. Therefore, we use a set of control mechanisms to prevent creepy results and to ensure a smooth and natural video conferencing experience. The entire eye contact correction system runs end-to-end in real-time on a commodity CPU and does not require any dedicated hardware, making our solution feasible for a variety of devices.
Automatic ISP image quality tuning using non-linear optimization
Feb 24, 2019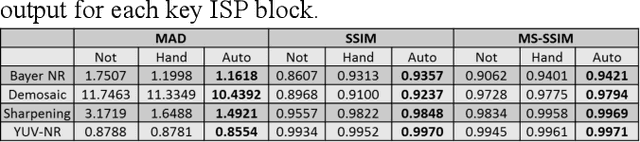

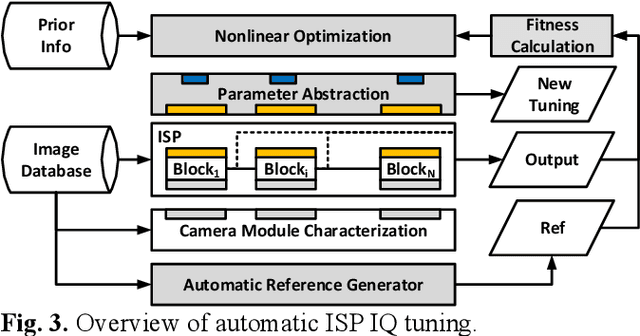
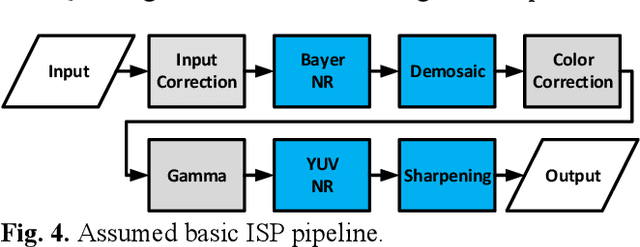
Image Signal Processor (ISP) comprises of various blocks to reconstruct image sensor raw data to final image consumed by human visual system or computer vision applications. Each block typically has many tuning parameters due to the complexity of the operation. These need to be hand tuned by Image Quality (IQ) experts, which takes considerable amount of time. In this paper, we present an automatic IQ tuning using nonlinear optimization and automatic reference generation algorithms. The proposed method can produce high quality IQ in minutes as compared with weeks of hand-tuned results by IQ experts. In addition, the proposed method can work with any algorithms without being aware of their specific implementation. It was found successful on multiple different processing blocks such as noise reduction, demosaic, and sharpening.
* 5 pages, 2018 25th IEEE International Conference on Image Processing (ICIP), 2471-2475