 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison between Supervised Learning Algorithms for Word Sense Disambiguation
Sep 22, 2000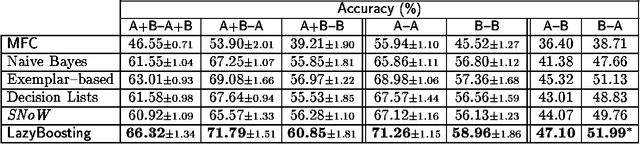
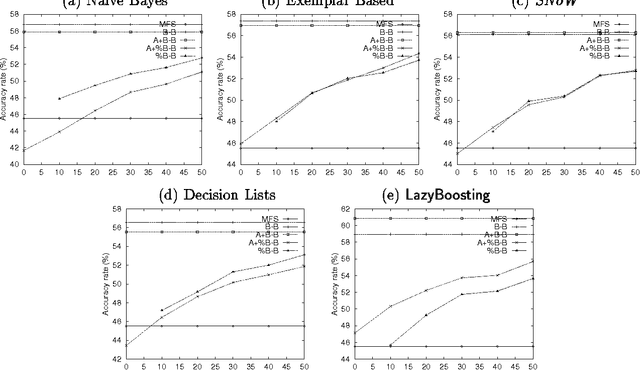
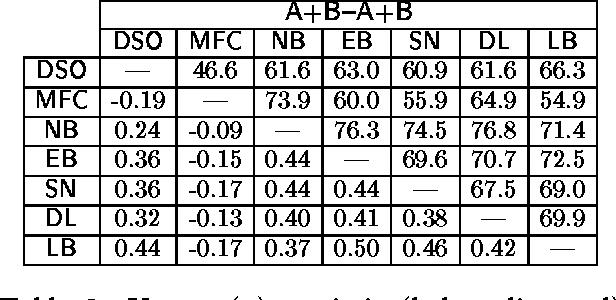
This paper describes a set of comparative experiments, including cross-corpus evaluation, between five alternative algorithms for supervised Word Sense Disambiguation (WSD), namely Naive Bayes, Exemplar-based learning, SNoW, Decision Lists, and Boosting. Two main conclusions can be drawn: 1) The LazyBoosting algorithm outperforms the other four state-of-the-art algorithms in terms of accuracy and ability to tune to new domains; 2) The domain dependence of WSD systems seems very strong and suggests that some kind of adaptation or tuning is required for cross-corpus application.
* 6 pages
Naive Bayes and Exemplar-Based approaches to Word Sense Disambiguation Revisited
Jul 07, 2000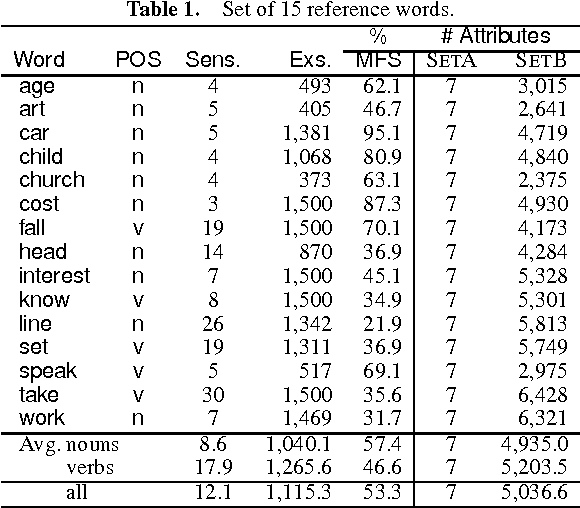
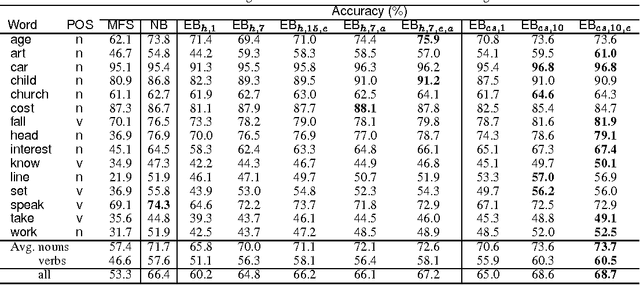


This paper describes an experimental comparison between two standard supervised learning methods, namely Naive Bayes and Exemplar-based classification, on the Word Sense Disambiguation (WSD) problem. The aim of the work is twofold. Firstly, it attempts to contribute to clarify some confusing information about the comparison between both methods appearing in the related literature. In doing so, several directions have been explored, including: testing several modifications of the basic learning algorithms and varying the feature space. Secondly, an improvement of both algorithms is proposed, in order to deal with large attribute sets. This modification, which basically consists in using only the positive information appearing in the examples, allows to improve greatly the efficiency of the methods, with no loss in accuracy. The experiments have been performed on the largest sense-tagged corpus available containing the most frequent and ambiguous English words. Results show that the Exemplar-based approach to WSD is generally superior to the Bayesian approach, especially when a specific metric for dealing with symbolic attributes is used.
* 5 pages
Boosting Applied to Word Sense Disambiguation
Jul 07, 2000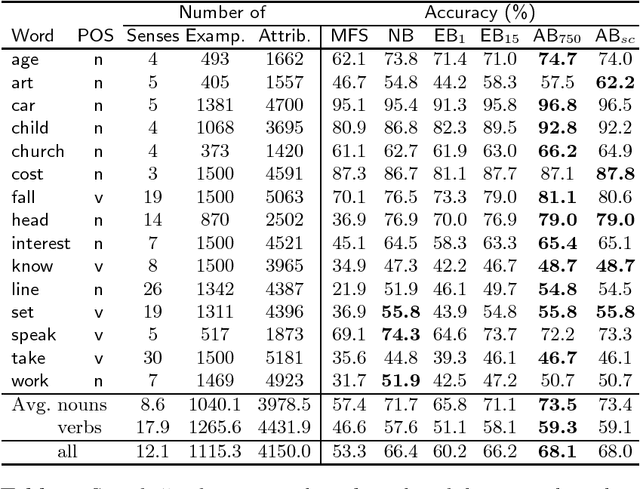
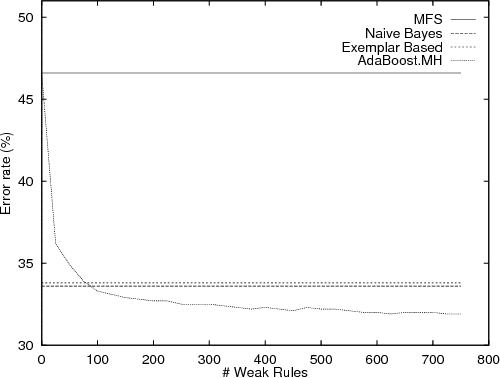
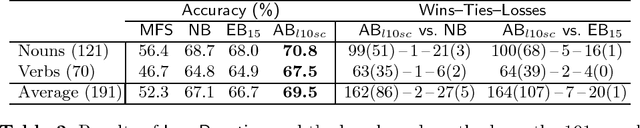
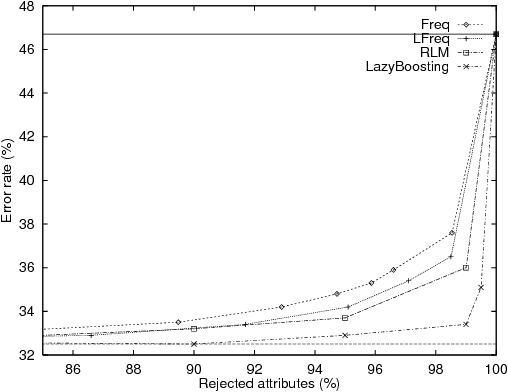
In this paper Schapire and Singer's AdaBoost.MH boosting algorithm is applied to the Word Sense Disambiguation (WSD) problem. Initial experiments on a set of 15 selected polysemous words show that the boosting approach surpasses Naive Bayes and Exemplar-based approaches, which represent state-of-the-art accuracy on supervised WSD. In order to make boosting practical for a real learning domain of thousands of words, several ways of accelerating the algorithm by reducing the feature space are studied. The best variant, which we call LazyBoosting, is tested on the largest sense-tagged corpus available containing 192,800 examples of the 191 most frequent and ambiguous English words. Again, boosting compares favourably to the other benchmark algorithms.
* 12 pages
Semantic Parsing based on Verbal Subcategorization
Jun 29, 2000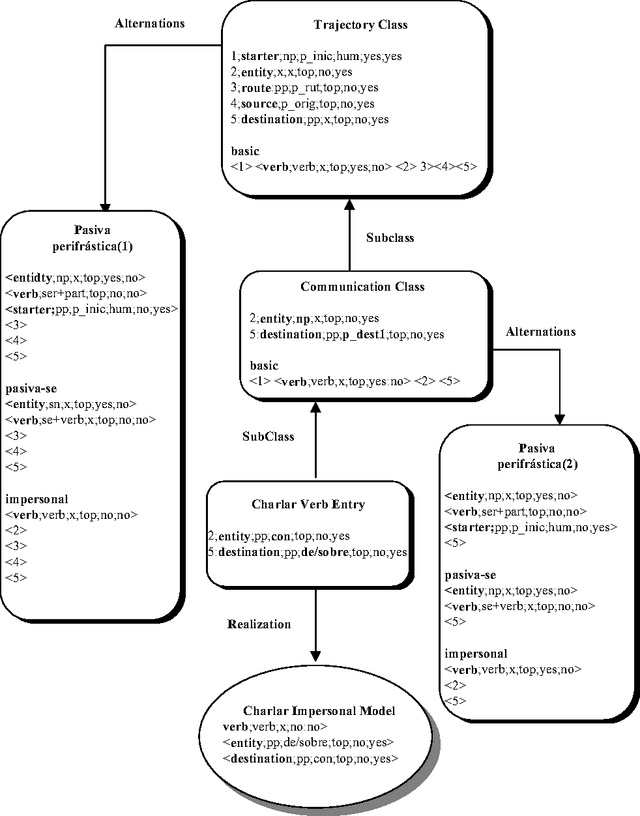
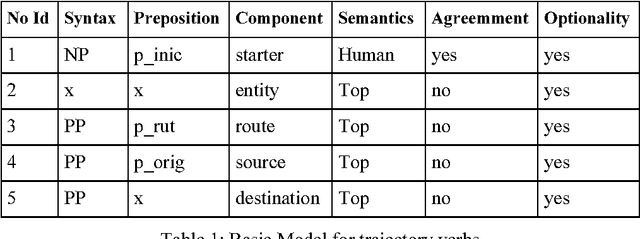
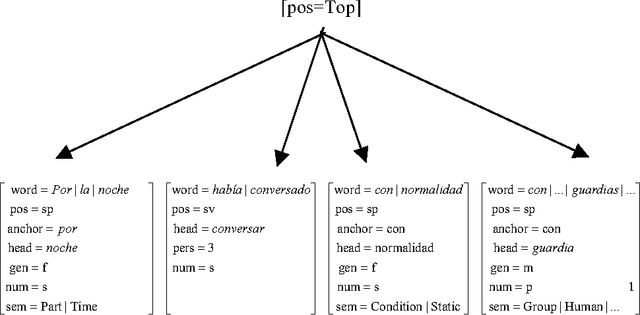

The aim of this work is to explore new methodologies on Semantic Parsing for unrestricted texts. Our approach follows the current trends in Information Extraction (IE) and is based on the application of a verbal subcategorization lexicon (LEXPIR) by means of complex pattern recognition techniques. LEXPIR is framed on the theoretical model of the verbal subcategorization developed in the Pirapides project.
* 12 pages, extended version of the paper. Spanish version of the paper also available from authors home page
Using a Diathesis Model for Semantic Parsing
Jun 29, 2000
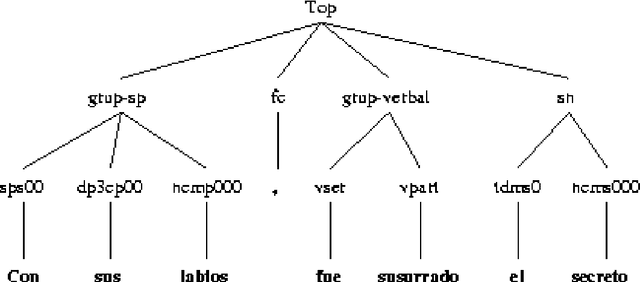
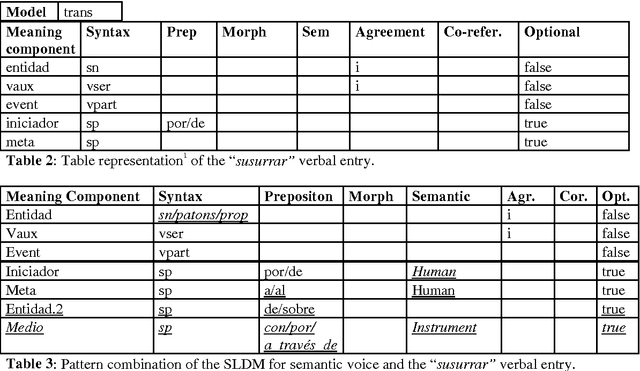
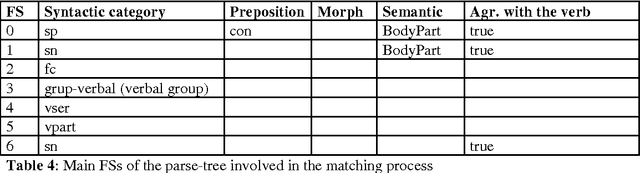
This paper presents a semantic parsing approach for unrestricted texts. Semantic parsing is one of the major bottlenecks of Natural Language Understanding (NLU) systems and usually requires building expensive resources not easily portable to other domains. Our approach obtains a case-role analysis, in which the semantic roles of the verb are identified. In order to cover all the possible syntactic realisations of a verb, our system combines their argument structure with a set of general semantic labelled diatheses models. Combining them, the system builds a set of syntactic-semantic patterns with their own role-case representation. Once the patterns are build, we use an approximate tree pattern-matching algorithm to identify the most reliable pattern for a sentence. The pattern matching is performed between the syntactic-semantic patterns and the feature-structure tree representing the morphological, syntactical and semantic information of the analysed sentence. For sentences assigned to the correct model, the semantic parsing system we are presenting identifies correctly more than 73% of possible semantic case-roles.
* 8 pages
Using WordNet for Building WordNets
Jun 23, 1998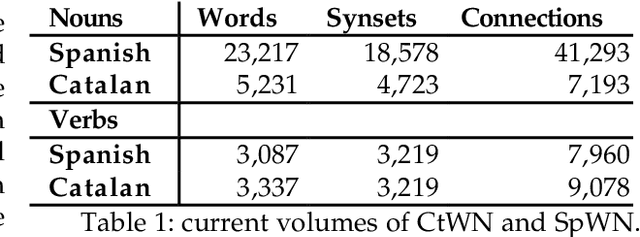
This paper summarises a set of methodologies and techniques for the fast construction of multilingual WordNets. The English WordNet is used in this approach as a backbone for Catalan and Spanish WordNets and as a lexical knowledge resource for several subtasks.
Building Accurate Semantic Taxonomies from Monolingual MRDs
Jun 23, 1998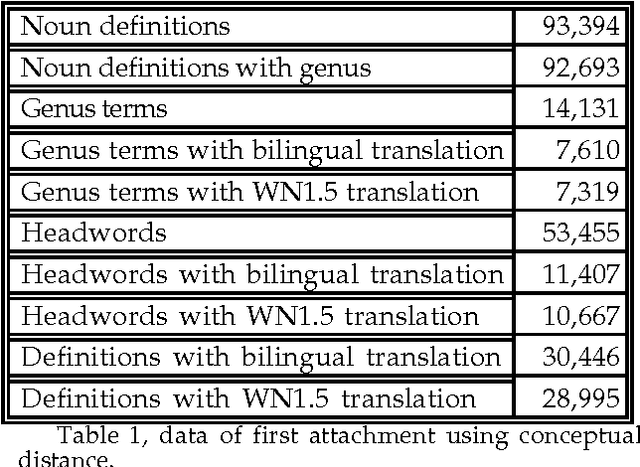
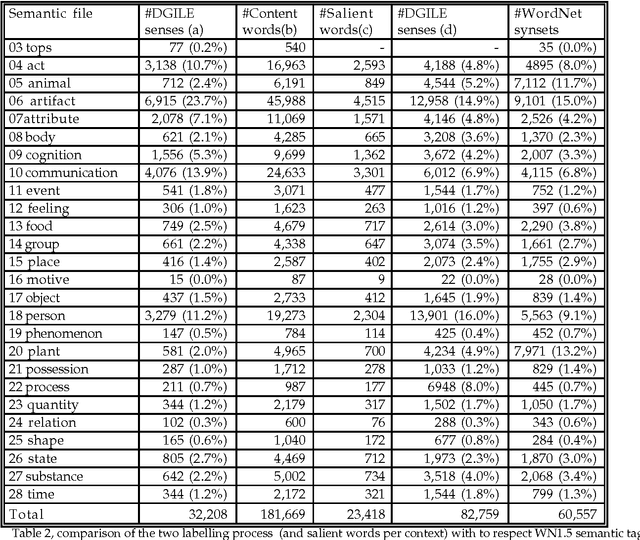
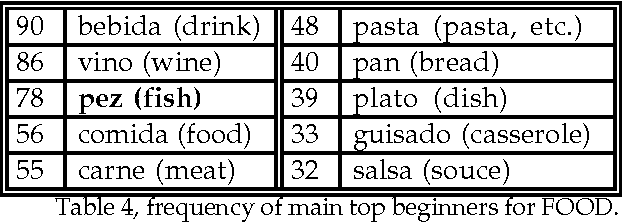
This paper presents a method that combines a set of unsupervised algorithms in order to accurately build large taxonomies from any machine-readable dictionary (MRD). Our aim is to profit from conventional MRDs, with no explicit semantic coding. We propose a system that 1) performs fully automatic exraction of taxonomic links from MRD entries and 2) ranks the extracted relations in a way that selective manual refinement is allowed. Tested accuracy can reach around 100% depending on the degree of coverage selected, showing that taxonomy building is not limited to structured dictionaries such as LDOCE.
Methods and Tools for Building the Catalan WordNet
Jun 11, 1998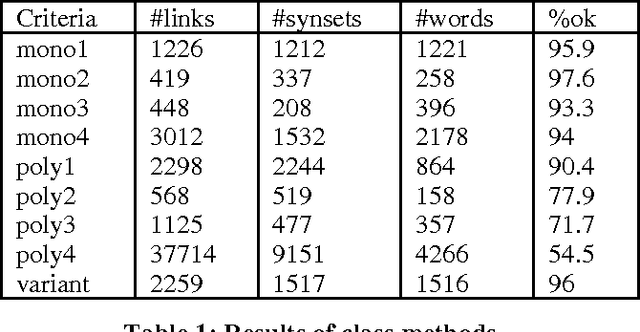
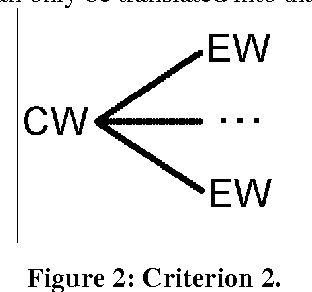
In this paper we introduce the methodology used and the basic phases we followed to develop the Catalan WordNet, and shich lexical resources have been employed in its building. This methodology, as well as the tools we made use of, have been thought in a general way so that they could be applied to any other language.
Combining Multiple Methods for the Automatic Construction of Multilingual WordNets
Sep 16, 1997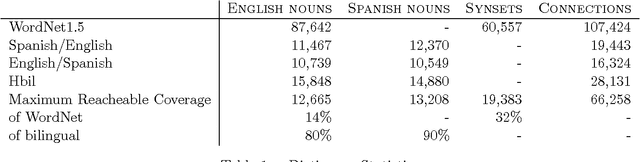
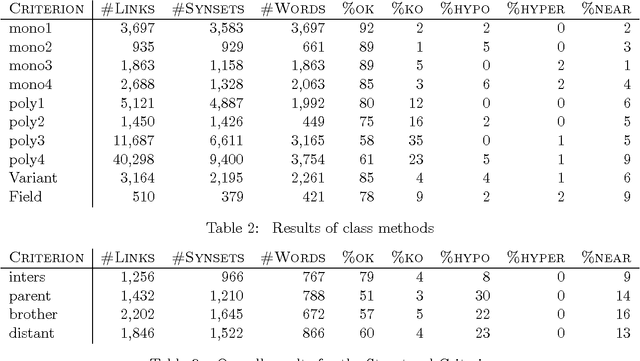
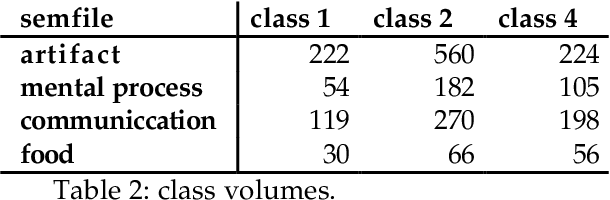
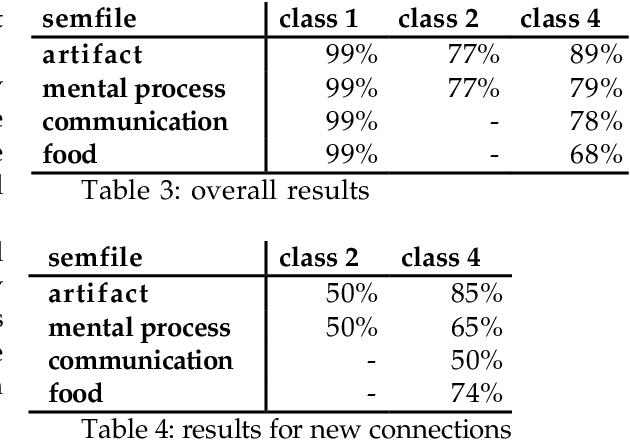
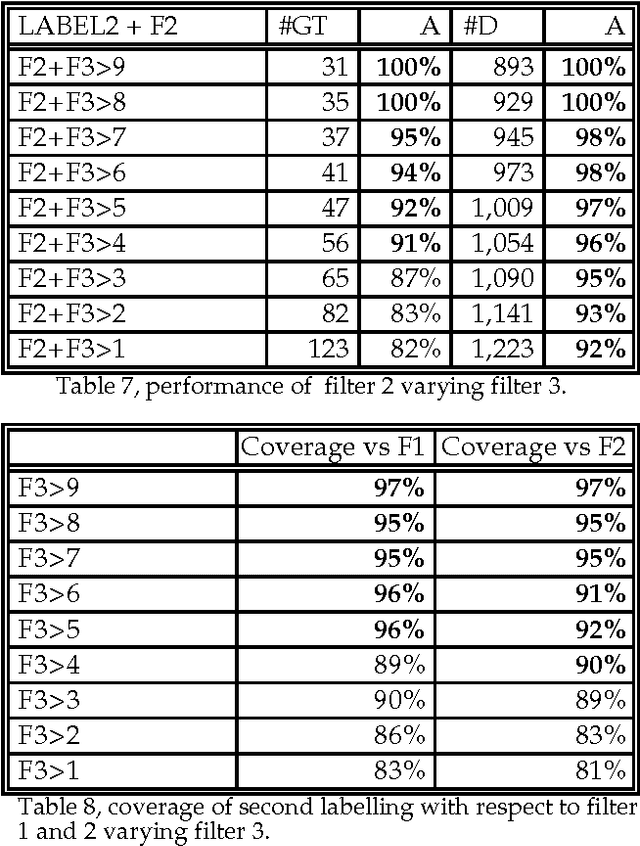
This paper explores the automatic construction of a multilingual Lexical Knowledge Base from preexisting lexical resources. First, a set of automatic and complementary techniques for linking Spanish words collected from monolingual and bilingual MRDs to English WordNet synsets are described. Second, we show how resulting data provided by each method is then combined to produce a preliminary version of a Spanish WordNet with an accuracy over 85%. The application of these combinations results on an increment of the extracted connexions of a 40% without losing accuracy. Both coarse-grained (class level) and fine-grained (synset assignment level) confidence ratios are used and evaluated. Finally, the results for the whole process are presented.
* 7 pages, 4 postscript figures
Combining Unsupervised Lexical Knowledge Methods for Word Sense Disambiguation
Apr 21, 1997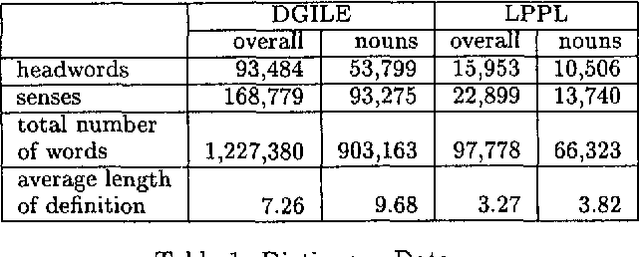
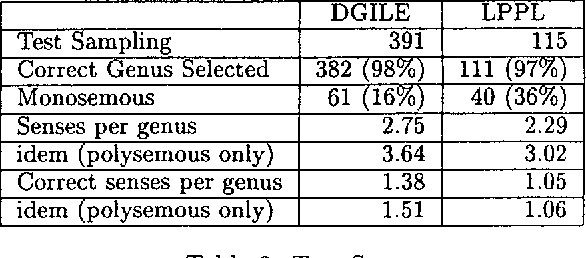
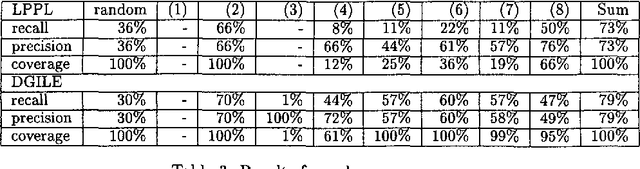
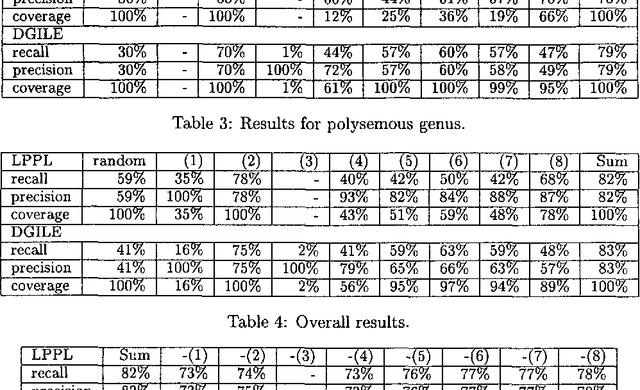
This paper presents a method to combine a set of unsupervised algorithms that can accurately disambiguate word senses in a large, completely untagged corpus. Although most of the techniques for word sense resolution have been presented as stand-alone, it is our belief that full-fledged lexical ambiguity resolution should combine several information sources and techniques. The set of techniques have been applied in a combined way to disambiguate the genus terms of two machine-readable dictionaries (MRD), enabling us to construct complete taxonomies for Spanish and French. Tested accuracy is above 80% overall and 95% for two-way ambiguous genus terms, showing that taxonomy building is not limited to structured dictionaries such as LDOCE.
* 8 pages, uses aclap.sty