 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGerard Pons-Moll
Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors
Mar 31, 2021
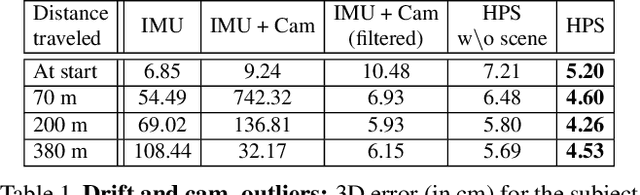
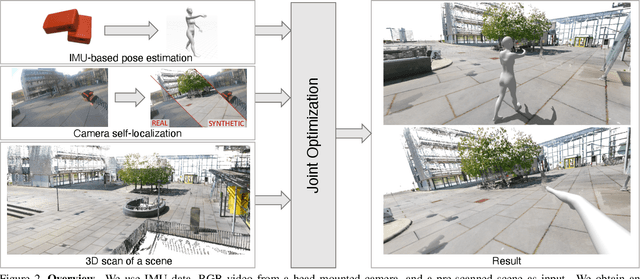
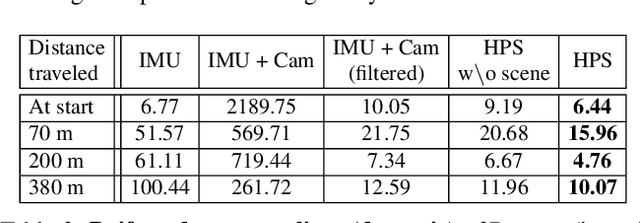
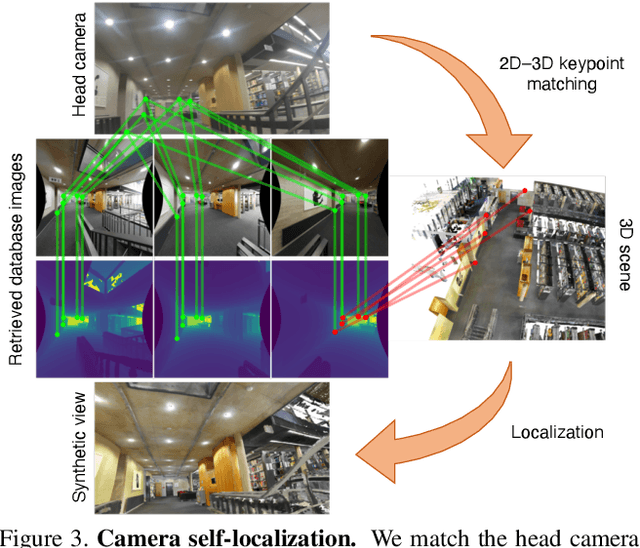
We introduce (HPS) Human POSEitioning System, a method to recover the full 3D pose of a human registered with a 3D scan of the surrounding environment using wearable sensors. Using IMUs attached at the body limbs and a head mounted camera looking outwards, HPS fuses camera based self-localization with IMU-based human body tracking. The former provides drift-free but noisy position and orientation estimates while the latter is accurate in the short-term but subject to drift over longer periods of time. We show that our optimization-based integration exploits the benefits of the two, resulting in pose accuracy free of drift. Furthermore, we integrate 3D scene constraints into our optimization, such as foot contact with the ground, resulting in physically plausible motion. HPS complements more common third-person-based 3D pose estimation methods. It allows capturing larger recording volumes and longer periods of motion, and could be used for VR/AR applications where humans interact with the scene without requiring direct line of sight with an external camera, or to train agents that navigate and interact with the environment based on first-person visual input, like real humans. With HPS, we recorded a dataset of humans interacting with large 3D scenes (300-1000 sq.m) consisting of 7 subjects and more than 3 hours of diverse motion. The dataset, code and video will be available on the project page: http://virtualhumans.mpi-inf.mpg.de/hps/ .
SMPLicit: Topology-aware Generative Model for Clothed People
Mar 11, 2021
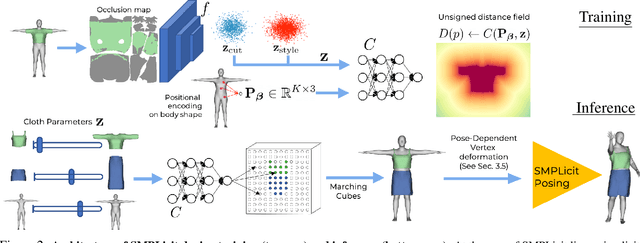
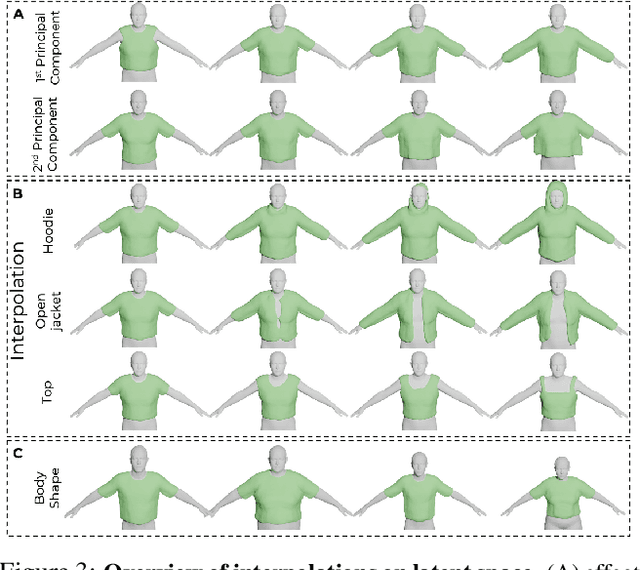
In this paper we introduce SMPLicit, a novel generative model to jointly represent body pose, shape and clothing geometry. In contrast to existing learning-based approaches that require training specific models for each type of garment, SMPLicit can represent in a unified manner different garment topologies (e.g. from sleeveless tops to hoodies and to open jackets), while controlling other properties like the garment size or tightness/looseness. We show our model to be applicable to a large variety of garments including T-shirts, hoodies, jackets, shorts, pants, skirts, shoes and even hair. The representation flexibility of SMPLicit builds upon an implicit model conditioned with the SMPL human body parameters and a learnable latent space which is semantically interpretable and aligned with the clothing attributes. The proposed model is fully differentiable, allowing for its use into larger end-to-end trainable systems. In the experimental section, we demonstrate SMPLicit can be readily used for fitting 3D scans and for 3D reconstruction in images of dressed people. In both cases we are able to go beyond state of the art, by retrieving complex garment geometries, handling situations with multiple clothing layers and providing a tool for easy outfit editing. To stimulate further research in this direction, we will make our code and model publicly available at http://www.iri.upc.edu/people/ecorona/smplicit/.
Learning Speech-driven 3D Conversational Gestures from Video
Feb 13, 2021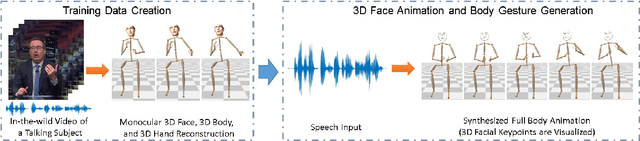
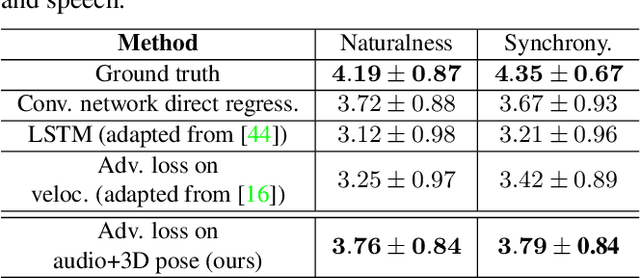
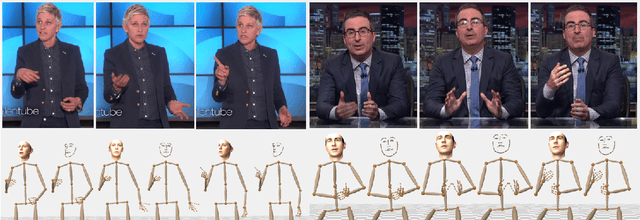
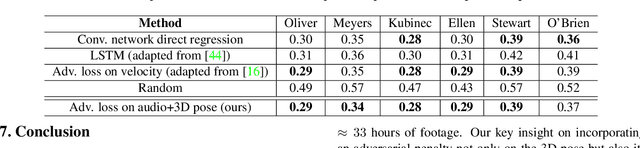
We propose the first approach to automatically and jointly synthesize both the synchronous 3D conversational body and hand gestures, as well as 3D face and head animations, of a virtual character from speech input. Our algorithm uses a CNN architecture that leverages the inherent correlation between facial expression and hand gestures. Synthesis of conversational body gestures is a multi-modal problem since many similar gestures can plausibly accompany the same input speech. To synthesize plausible body gestures in this setting, we train a Generative Adversarial Network (GAN) based model that measures the plausibility of the generated sequences of 3D body motion when paired with the input audio features. We also contribute a new way to create a large corpus of more than 33 hours of annotated body, hand, and face data from in-the-wild videos of talking people. To this end, we apply state-of-the-art monocular approaches for 3D body and hand pose estimation as well as dense 3D face performance capture to the video corpus. In this way, we can train on orders of magnitude more data than previous algorithms that resort to complex in-studio motion capture solutions, and thereby train more expressive synthesis algorithms. Our experiments and user study show the state-of-the-art quality of our speech-synthesized full 3D character animations.
Adjoint Rigid Transform Network: Self-supervised Alignment of 3D Shapes
Feb 01, 2021
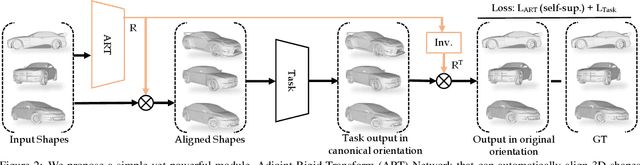
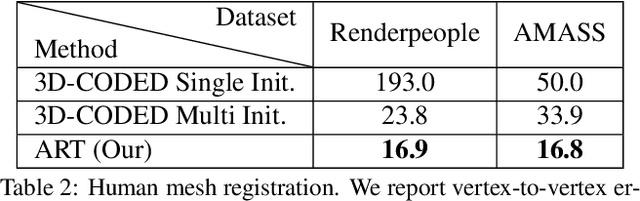
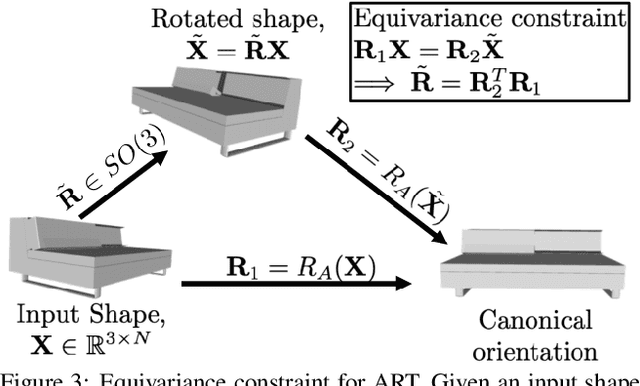
Most learning methods for 3D data (point clouds, meshes) suffer significant performance drops when the data is not carefully aligned to a canonical orientation. Aligning real world 3D data collected from different sources is non-trivial and requires manual intervention. In this paper, we propose the Adjoint Rigid Transform (ART) Network, a neural module which can be integrated with existing 3D networks to significantly boost their performance in tasks such as shape reconstruction, non-rigid registration, and latent disentanglement. ART learns to rotate input shapes to a canonical orientation that is crucial for a lot of tasks. ART achieves this by imposing rotation equivariance constraint on input shapes. The remarkable result is that with only self-supervision, ART can discover a unique canonical orientation for both rigid and nonrigid objects, which leads to a notable boost in downstream task performance. We will release our code and pre-trained models for further research.
D-NeRF: Neural Radiance Fields for Dynamic Scenes
Nov 27, 2020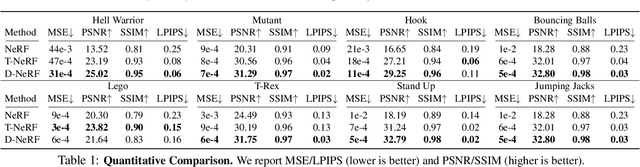
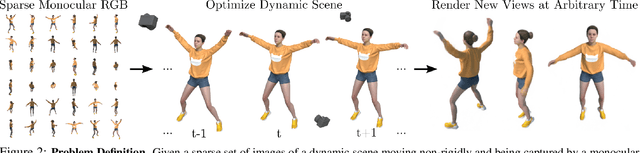
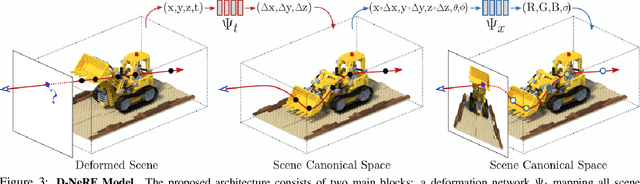

Neural rendering techniques combining machine learning with geometric reasoning have arisen as one of the most promising approaches for synthesizing novel views of a scene from a sparse set of images. Among these, stands out the Neural radiance fields (NeRF), which trains a deep network to map 5D input coordinates (representing spatial location and viewing direction) into a volume density and view-dependent emitted radiance. However, despite achieving an unprecedented level of photorealism on the generated images, NeRF is only applicable to static scenes, where the same spatial location can be queried from different images. In this paper we introduce D-NeRF, a method that extends neural radiance fields to a dynamic domain, allowing to reconstruct and render novel images of objects under rigid and non-rigid motions from a \emph{single} camera moving around the scene. For this purpose we consider time as an additional input to the system, and split the learning process in two main stages: one that encodes the scene into a canonical space and another that maps this canonical representation into the deformed scene at a particular time. Both mappings are simultaneously learned using fully-connected networks. Once the networks are trained, D-NeRF can render novel images, controlling both the camera view and the time variable, and thus, the object movement. We demonstrate the effectiveness of our approach on scenes with objects under rigid, articulated and non-rigid motions. Code, model weights and the dynamic scenes dataset will be released.
SelfPose: 3D Egocentric Pose Estimation from a Headset Mounted Camera
Nov 02, 2020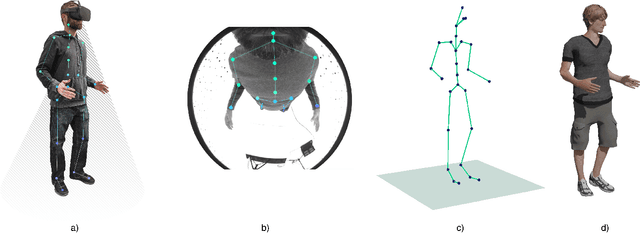


We present a solution to egocentric 3D body pose estimation from monocular images captured from downward looking fish-eye cameras installed on the rim of a head mounted VR device. This unusual viewpoint leads to images with unique visual appearance, with severe self-occlusions and perspective distortions that result in drastic differences in resolution between lower and upper body. We propose an encoder-decoder architecture with a novel multi-branch decoder designed to account for the varying uncertainty in 2D predictions. The quantitative evaluation, on synthetic and real-world datasets, shows that our strategy leads to substantial improvements in accuracy over state of the art egocentric approaches. To tackle the lack of labelled data we also introduced a large photo-realistic synthetic dataset. xR-EgoPose offers high quality renderings of people with diverse skintones, body shapes and clothing, performing a range of actions. Our experiments show that the high variability in our new synthetic training corpus leads to good generalization to real world footage and to state of theart results on real world datasets with ground truth. Moreover, an evaluation on the Human3.6M benchmark shows that the performance of our method is on par with top performing approaches on the more classic problem of 3D human pose from a third person viewpoint.
* 14 pages. arXiv admin note: substantial text overlap with arXiv:1907.10045
Neural Unsigned Distance Fields for Implicit Function Learning
Oct 26, 2020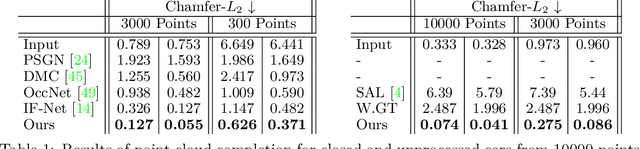
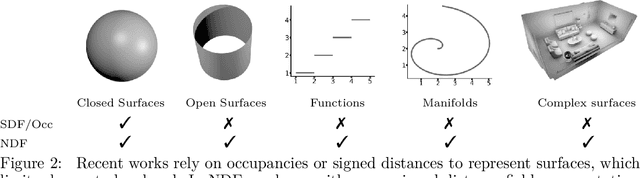
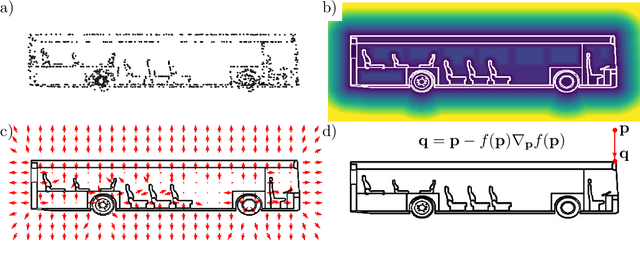

In this work we target a learnable output representation that allows continuous, high resolution outputs of arbitrary shape. Recent works represent 3D surfaces implicitly with a Neural Network, thereby breaking previous barriers in resolution, and ability to represent diverse topologies. However, neural implicit representations are limited to closed surfaces, which divide the space into inside and outside. Many real world objects such as walls of a scene scanned by a sensor, clothing, or a car with inner structures are not closed. This constitutes a significant barrier, in terms of data pre-processing (objects need to be artificially closed creating artifacts), and the ability to output open surfaces. In this work, we propose Neural Distance Fields (NDF), a neural network based model which predicts the unsigned distance field for arbitrary 3D shapes given sparse point clouds. NDF represent surfaces at high resolutions as prior implicit models, but do not require closed surface data, and significantly broaden the class of representable shapes in the output. NDF allow to extract the surface as very dense point clouds and as meshes. We also show that NDF allow for surface normal calculation and can be rendered using a slight modification of sphere tracing. We find NDF can be used for multi-target regression (multiple outputs for one input) with techniques that have been exclusively used for rendering in graphics. Experiments on ShapeNet show that NDF, while simple, is the state-of-the art, and allows to reconstruct shapes with inner structures, such as the chairs inside a bus. Notably, we show that NDF are not restricted to 3D shapes, and can approximate more general open surfaces such as curves, manifolds, and functions. Code is available for research at https://virtualhumans.mpi-inf.mpg.de/ndf/.
* Neural Information Processing Systems (NeurIPS) 2020
SHARP 2020: The 1st Shape Recovery from Partial Textured 3D Scans Challenge Results
Oct 26, 2020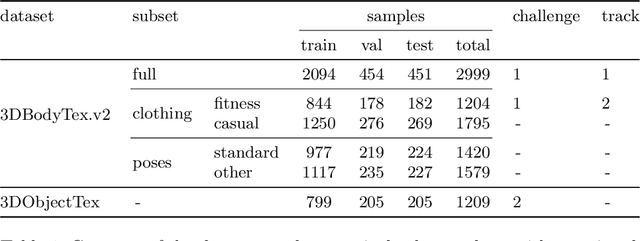


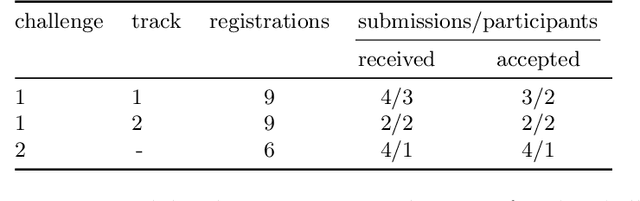
The SHApe Recovery from Partial textured 3D scans challenge, SHARP 2020, is the first edition of a challenge fostering and benchmarking methods for recovering complete textured 3D scans from raw incomplete data. SHARP 2020 is organised as a workshop in conjunction with ECCV 2020. There are two complementary challenges, the first one on 3D human scans, and the second one on generic objects. Challenge 1 is further split into two tracks, focusing, first, on large body and clothing regions, and, second, on fine body details. A novel evaluation metric is proposed to quantify jointly the shape reconstruction, the texture reconstruction and the amount of completed data. Additionally, two unique datasets of 3D scans are proposed, to provide raw ground-truth data for the benchmarks. The datasets are released to the scientific community. Moreover, an accompanying custom library of software routines is also released to the scientific community. It allows for processing 3D scans, generating partial data and performing the evaluation. Results of the competition, analysed in comparison to baselines, show the validity of the proposed evaluation metrics, and highlight the challenging aspects of the task and of the datasets. Details on the SHARP 2020 challenge can be found at https://cvi2.uni.lu/sharp2020/.
LoopReg: Self-supervised Learning of Implicit Surface Correspondences, Pose and Shape for 3D Human Mesh Registration
Oct 23, 2020
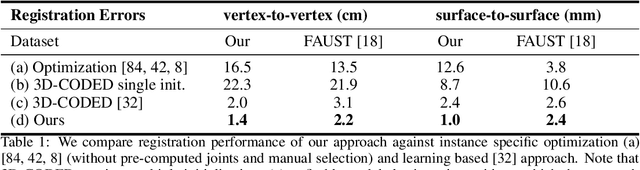

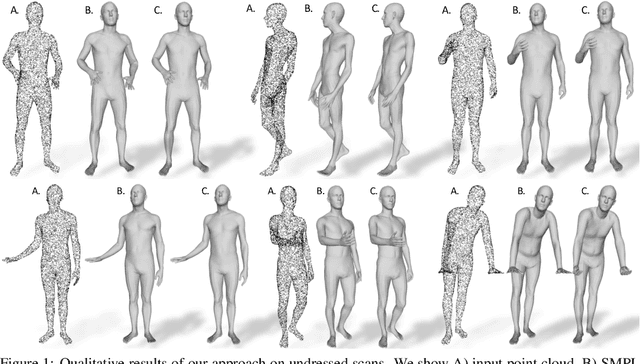
We address the problem of fitting 3D human models to 3D scans of dressed humans. Classical methods optimize both the data-to-model correspondences and the human model parameters (pose and shape), but are reliable only when initialized close to the solution. Some methods initialize the optimization based on fully supervised correspondence predictors, which is not differentiable end-to-end, and can only process a single scan at a time. Our main contribution is LoopReg, an end-to-end learning framework to register a corpus of scans to a common 3D human model. The key idea is to create a self-supervised loop. A backward map, parameterized by a Neural Network, predicts the correspondence from every scan point to the surface of the human model. A forward map, parameterized by a human model, transforms the corresponding points back to the scan based on the model parameters (pose and shape), thus closing the loop. Formulating this closed loop is not straightforward because it is not trivial to force the output of the NN to be on the surface of the human model - outside this surface the human model is not even defined. To this end, we propose two key innovations. First, we define the canonical surface implicitly as the zero level set of a distance field in R3, which in contrast to morecommon UV parameterizations, does not require cutting the surface, does not have discontinuities, and does not induce distortion. Second, we diffuse the human model to the 3D domain R3. This allows to map the NN predictions forward,even when they slightly deviate from the zero level set. Results demonstrate that we can train LoopRegmainly self-supervised - following a supervised warm-start, the model becomes increasingly more accurate as additional unlabelled raw scans are processed. Our code and pre-trained models can be downloaded for research.
* NeurIPS'20 (Oral)
Implicit Feature Networks for Texture Completion from Partial 3D Data
Sep 20, 2020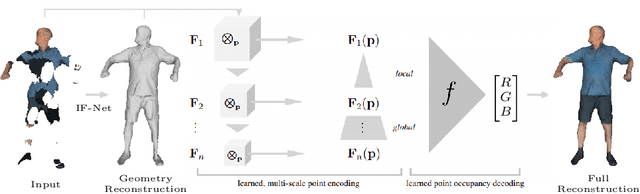
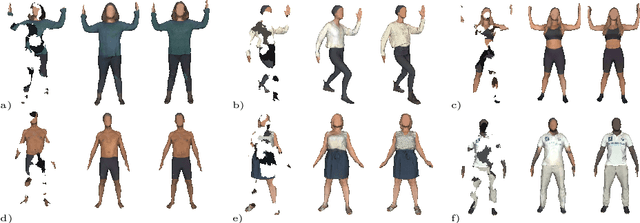

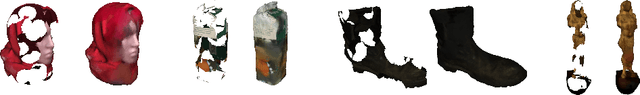
Prior work to infer 3D texture use either texture atlases, which require uv-mappings and hence have discontinuities, or colored voxels, which are memory inefficient and limited in resolution. Recent work, predicts RGB color at every XYZ coordinate forming a texture field, but focus on completing texture given a single 2D image. Instead, we focus on 3D texture and geometry completion from partial and incomplete 3D scans. IF-Nets have recently achieved state-of-the-art results on 3D geometry completion using a multi-scale deep feature encoding, but the outputs lack texture. In this work, we generalize IF-Nets to texture completion from partial textured scans of humans and arbitrary objects. Our key insight is that 3D texture completion benefits from incorporating local and global deep features extracted from both the 3D partial texture and completed geometry. Specifically, given the partial 3D texture and the 3D geometry completed with IF-Nets, our model successfully in-paints the missing texture parts in consistence with the completed geometry. Our model won the SHARP ECCV'20 challenge, achieving highest performance on all challenges.
* SHARP Workshop, European Conference on Computer Vision (ECCV), 2020