 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeorgios B. Giannakis
Semi-Blind Inference of Topologies and Dynamical Processes over Graphs
May 16, 2018
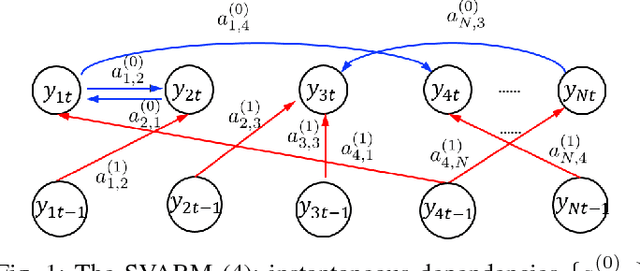
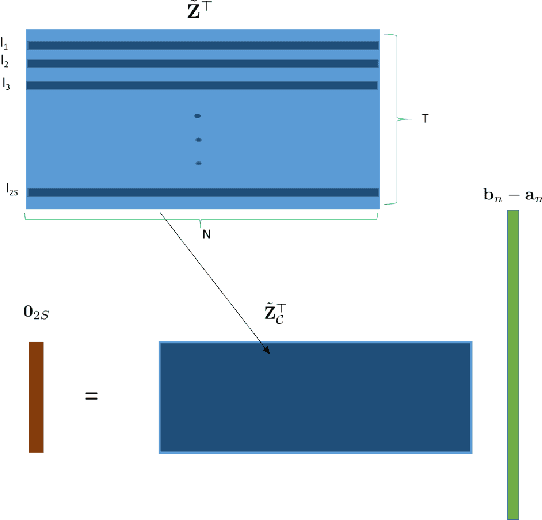
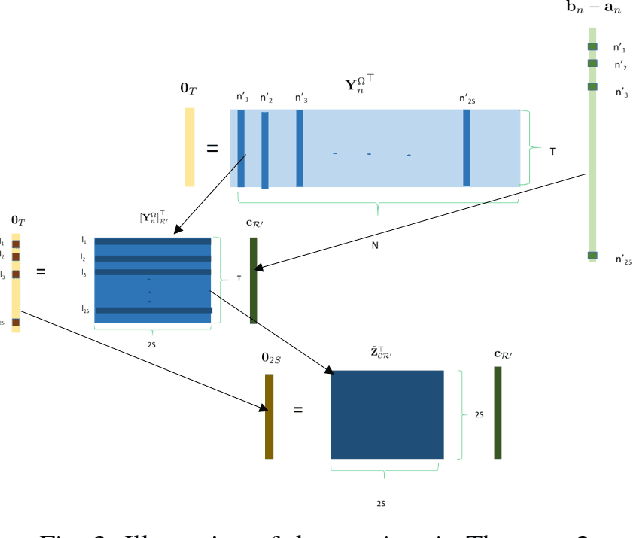
Network science provides valuable insights across numerous disciplines including sociology, biology, neuroscience and engineering. A task of major practical importance in these application domains is inferring the network structure from noisy observations at a subset of nodes. Available methods for topology inference typically assume that the process over the network is observed at all nodes. However, application-specific constraints may prevent acquiring network-wide observations. Alleviating the limited flexibility of existing approaches, this work advocates structural models for graph processes and develops novel algorithms for joint inference of the network topology and processes from partial nodal observations. Structural equation models (SEMs) and structural vector autoregressive models (SVARMs) have well-documented merits in identifying even directed topologies of complex graphs; while SEMs capture contemporaneous causal dependencies among nodes, SVARMs further account for time-lagged influences. This paper develops algorithms that iterate between inferring directed graphs that "best" fit the data, and estimating the network processes at reduced computational complexity by leveraging tools related to Kalman smoothing. To further accommodate delay-sensitive applications, an online joint inference approach is put forth that even tracks time-evolving topologies. Furthermore, conditions for identifying the network topology given partial observations are specified. It is proved that the required number of observations for unique identification reduces significantly when the network structure is sparse. Numerical tests with synthetic as well as real datasets corroborate the effectiveness of the novel approach.
Secure Mobile Edge Computing in IoT via Collaborative Online Learning
May 09, 2018
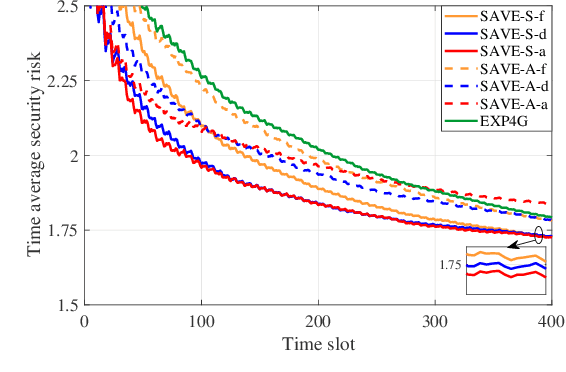
To accommodate heterogeneous tasks in Internet of Things (IoT), a new communication and computing paradigm termed mobile edge computing emerges that extends computing services from the cloud to edge, but at the same time exposes new challenges on security. The present paper studies online security-aware edge computing under jamming attacks. Leveraging online learning tools, novel algorithms abbreviated as SAVE-S and SAVE-A are developed to cope with the stochastic and adversarial forms of jamming, respectively. Without utilizing extra resources such as spectrum and transmission power to evade jamming attacks, SAVE-S and SAVE-A can select the most reliable server to offload computing tasks with minimal privacy and security concerns. It is analytically established that without any prior information on future jamming and server security risks, the proposed schemes can achieve ${\cal O}\big(\sqrt{T}\big)$ regret. Information sharing among devices can accelerate the security-aware computing tasks. Incorporating the information shared by other devices, SAVE-S and SAVE-A offer impressive improvements on the sublinear regret, which is guaranteed by what is termed "value of cooperation." Effectiveness of the proposed schemes is tested on both synthetic and real datasets.
Kernel-based Inference of Functions over Graphs
Apr 10, 2018
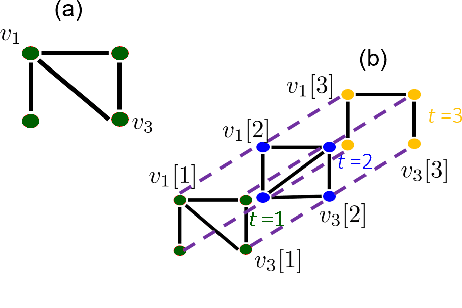
The study of networks has witnessed an explosive growth over the past decades with several ground-breaking methods introduced. A particularly interesting -- and prevalent in several fields of study -- problem is that of inferring a function defined over the nodes of a network. This work presents a versatile kernel-based framework for tackling this inference problem that naturally subsumes and generalizes the reconstruction approaches put forth recently by the signal processing on graphs community. Both the static and the dynamic settings are considered along with effective modeling approaches for addressing real-world problems. The herein analytical discussion is complemented by a set of numerical examples, which showcase the effectiveness of the presented techniques, as well as their merits related to state-of-the-art methods.
Nonlinear Dimensionality Reduction on Graphs
Mar 29, 2018
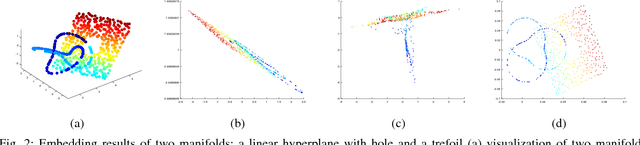

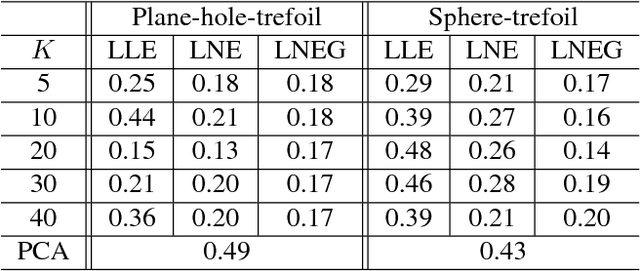
In this era of data deluge, many signal processing and machine learning tasks are faced with high-dimensional datasets, including images, videos, as well as time series generated from social, commercial and brain network interactions. Their efficient processing calls for dimensionality reduction techniques capable of properly compressing the data while preserving task-related characteristics, going beyond pairwise data correlations. The present paper puts forth a nonlinear dimensionality reduction framework that accounts for data lying on known graphs. The novel framework encompasses most of the existing dimensionality reduction methods, but it is also capable of capturing and preserving possibly nonlinear correlations that are ignored by linear methods. Furthermore, it can take into account information from multiple graphs. The proposed algorithms were tested on synthetic as well as real datasets to corroborate their effectiveness.
Canonical Correlation Analysis of Datasets with a Common Source Graph
Mar 27, 2018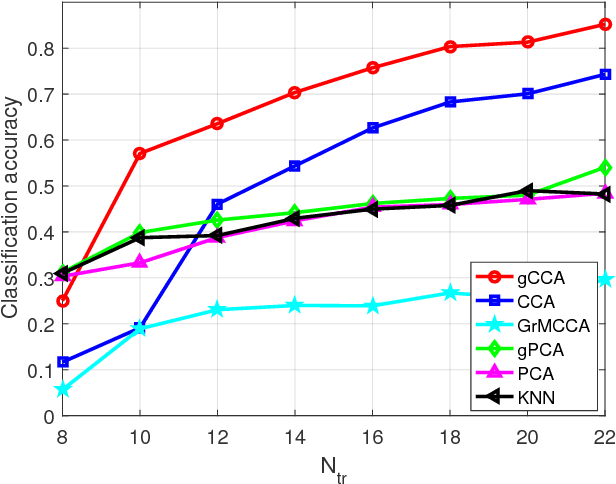
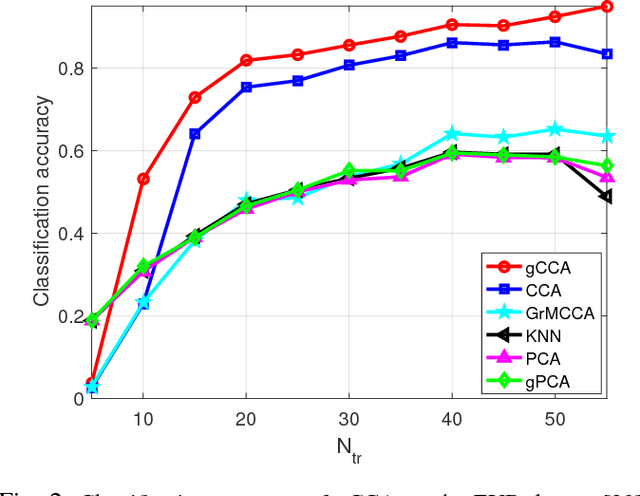
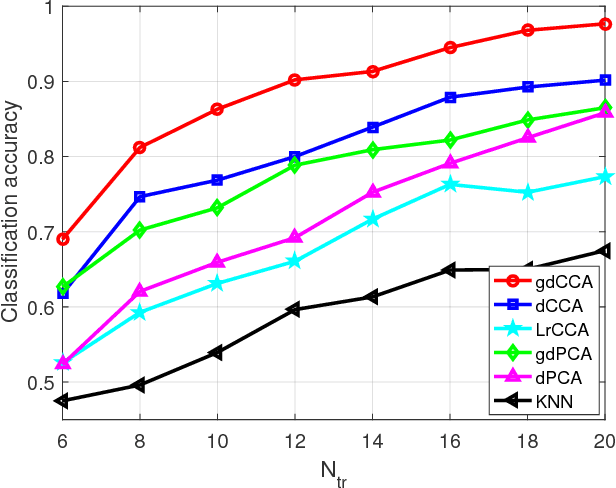
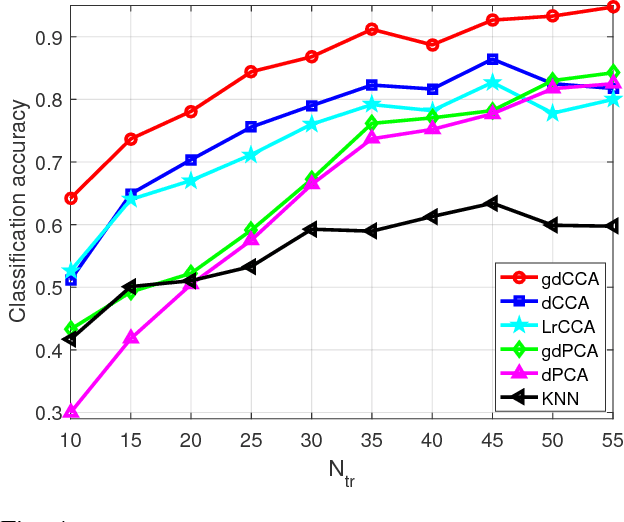
Canonical correlation analysis (CCA) is a powerful technique for discovering whether or not hidden sources are commonly present in two (or more) datasets. Its well-appreciated merits include dimensionality reduction, clustering, classification, feature selection, and data fusion. The standard CCA however, does not exploit the geometry of the common sources, which may be available from the given data or can be deduced from (cross-) correlations. In this paper, this extra information provided by the common sources generating the data is encoded in a graph, and is invoked as a graph regularizer. This leads to a novel graph-regularized CCA approach, that is termed graph (g) CCA. The novel gCCA accounts for the graph-induced knowledge of common sources, while minimizing the distance between the wanted canonical variables. Tailored for diverse practical settings where the number of data is smaller than the data vector dimensions, the dual formulation of gCCA is also developed. One such setting includes kernels that are incorporated to account for nonlinear data dependencies. The resultant graph-kernel (gk) CCA is also obtained in closed form. Finally, corroborating image classification tests over several real datasets are presented to showcase the merits of the novel linear, dual, and kernel approaches relative to competing alternatives.
Sketched Subspace Clustering
Feb 07, 2018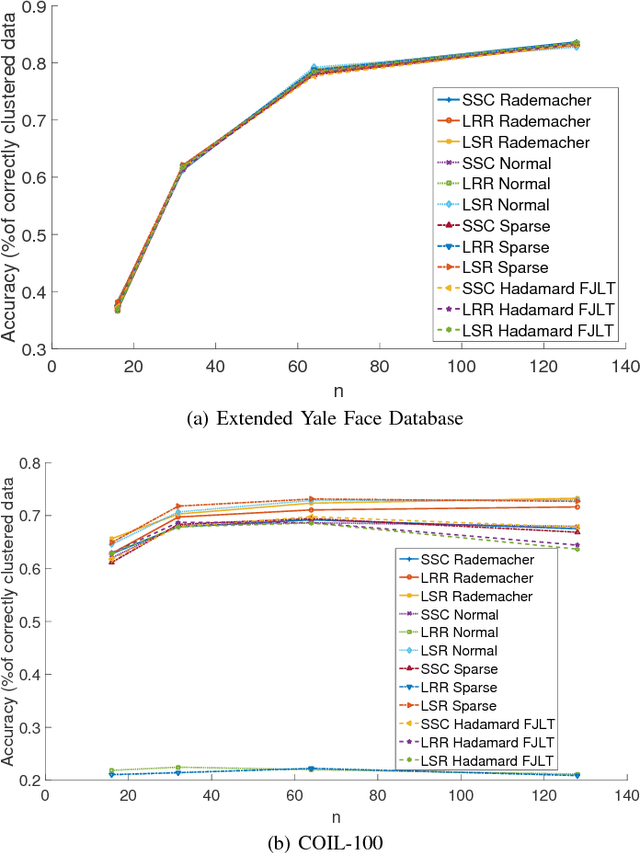
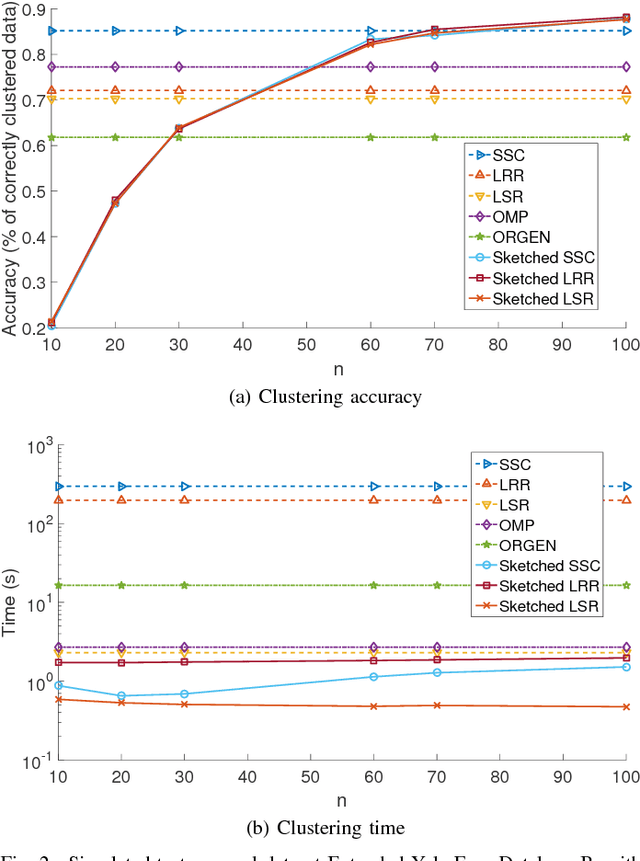
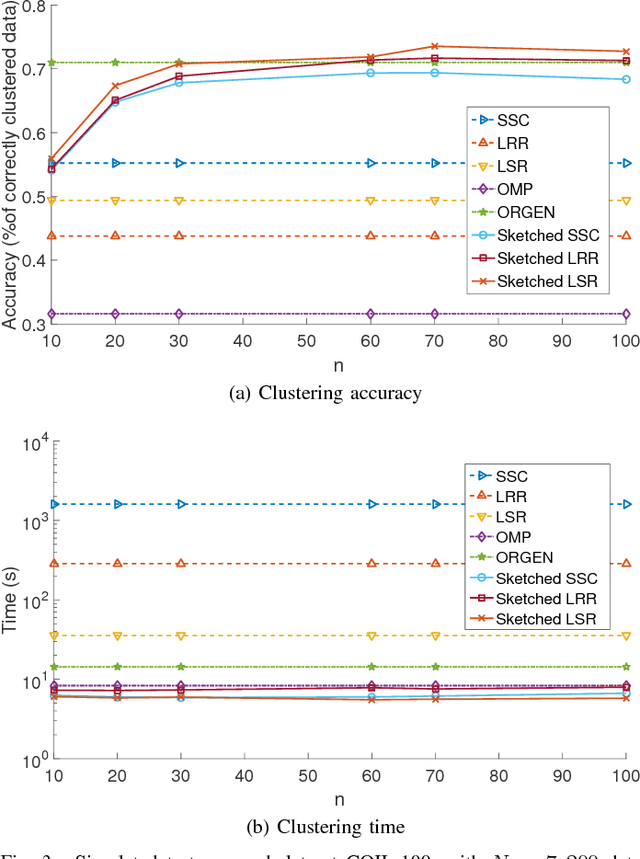
The immense amount of daily generated and communicated data presents unique challenges in their processing. Clustering, the grouping of data without the presence of ground-truth labels, is an important tool for drawing inferences from data. Subspace clustering (SC) is a relatively recent method that is able to successfully classify nonlinearly separable data in a multitude of settings. In spite of their high clustering accuracy, SC methods incur prohibitively high computational complexity when processing large volumes of high-dimensional data. Inspired by random sketching approaches for dimensionality reduction, the present paper introduces a randomized scheme for SC, termed Sketch-SC, tailored for large volumes of high-dimensional data. Sketch-SC accelerates the computationally heavy parts of state-of-the-art SC approaches by compressing the data matrix across both dimensions using random projections, thus enabling fast and accurate large-scale SC. Performance analysis as well as extensive numerical tests on real data corroborate the potential of Sketch-SC and its competitive performance relative to state-of-the-art scalable SC approaches.
Random Feature-based Online Multi-kernel Learning in Environments with Unknown Dynamics
Jan 17, 2018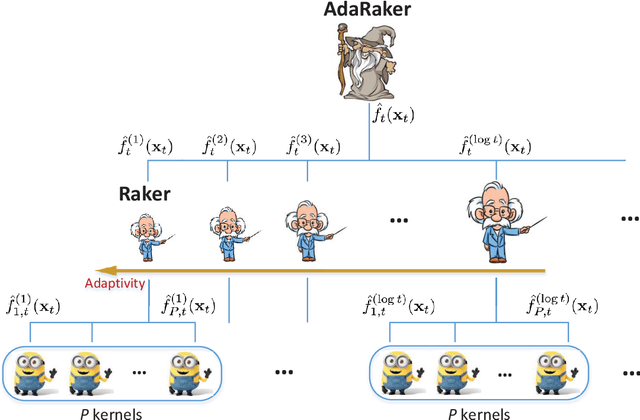

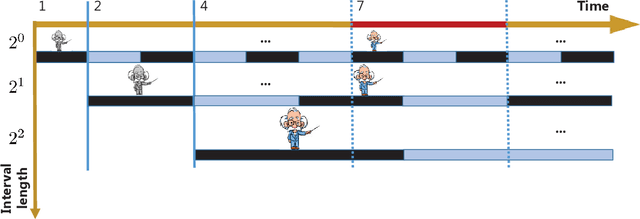
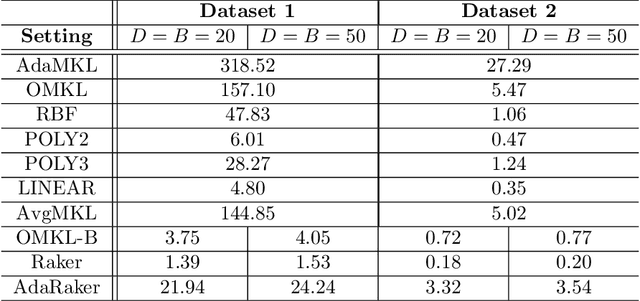
Kernel-based methods exhibit well-documented performance in various nonlinear learning tasks. Most of them rely on a preselected kernel, whose prudent choice presumes task-specific prior information. Especially when the latter is not available, multi-kernel learning has gained popularity thanks to its flexibility in choosing kernels from a prescribed kernel dictionary. Leveraging the random feature approximation and its recent orthogonality-promoting variant, the present contribution develops a scalable multi-kernel learning scheme (termed Raker) to obtain the sought nonlinear learning function `on the fly,' first for static environments. To further boost performance in dynamic environments, an adaptive multi-kernel learning scheme (termed AdaRaker) is developed using weighted combinations of advices from hierarchical ensembles of experts. The weights account not only for each kernel's contribution to the learning, but also for the unknown dynamics. Performance is analyzed in terms of both static and dynamic regrets. AdaRaker is uniquely capable of tracking nonlinear learning functions in environments with unknown dynamics, with analytic performance guarantees. Tests with synthetic and real datasets are carried out to showcase the effectiveness of the novel algorithms, and their performance.
Data-adaptive Active Sampling for Efficient Graph-Cognizant Classification
Dec 26, 2017
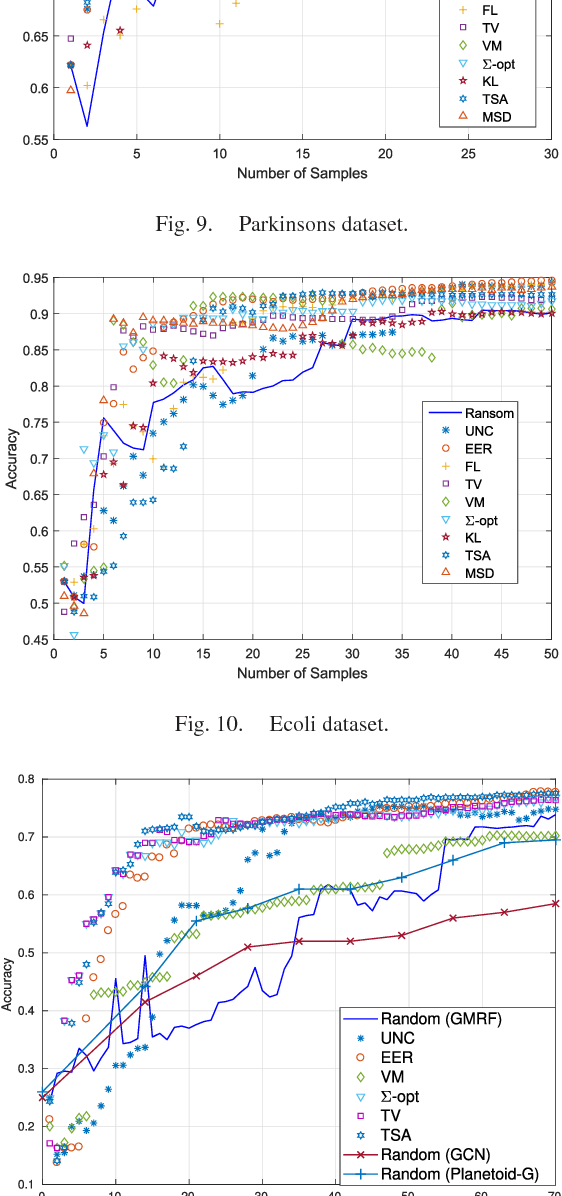
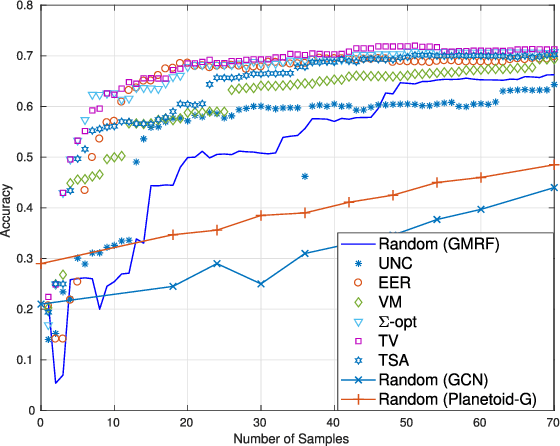
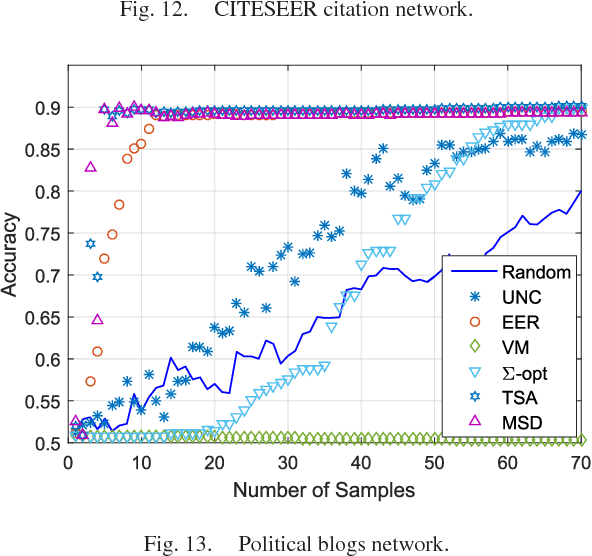
The present work deals with active sampling of graph nodes representing training data for binary classification. The graph may be given or constructed using similarity measures among nodal features. Leveraging the graph for classification builds on the premise that labels across neighboring nodes are correlated according to a categorical Markov random field (MRF). This model is further relaxed to a Gaussian (G)MRF with labels taking continuous values - an approximation that not only mitigates the combinatorial complexity of the categorical model, but also offers optimal unbiased soft predictors of the unlabeled nodes. The proposed sampling strategy is based on querying the node whose label disclosure is expected to inflict the largest change on the GMRF, and in this sense it is the most informative on average. Such a strategy subsumes several measures of expected model change, including uncertainty sampling, variance minimization, and sampling based on the $\Sigma-$optimality criterion. A simple yet effective heuristic is also introduced for increasing the exploration capabilities of the sampler, and reducing bias of the resultant classifier, by taking into account the confidence on the model label predictions. The novel sampling strategies are based on quantities that are readily available without the need for model retraining, rendering them computationally efficient and scalable to large graphs. Numerical tests using synthetic and real data demonstrate that the proposed methods achieve accuracy that is comparable or superior to the state-of-the-art even at reduced runtime.
Large-scale Kernel-based Feature Extraction via Budgeted Nonlinear Subspace Tracking
Dec 26, 2017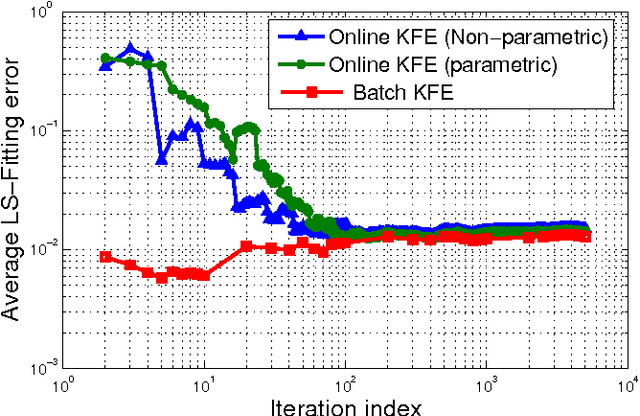
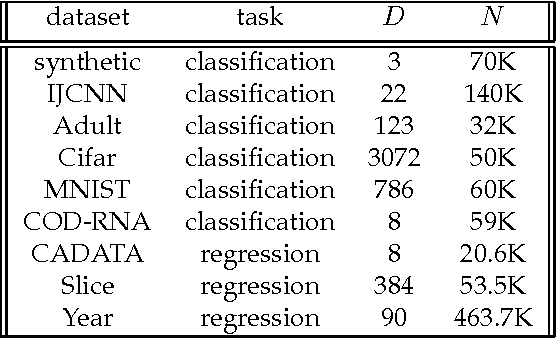
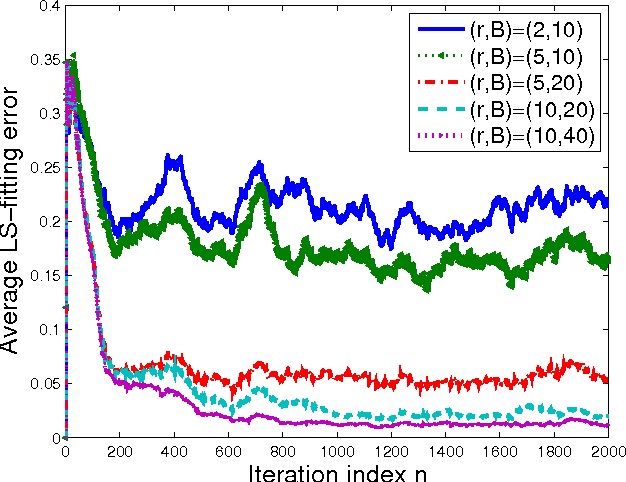
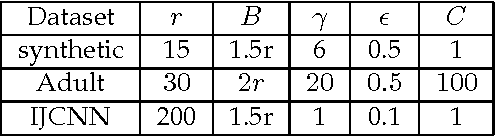
Kernel-based methods enjoy powerful generalization capabilities in handling a variety of learning tasks. When such methods are provided with sufficient training data, broadly-applicable classes of nonlinear functions can be approximated with desired accuracy. Nevertheless, inherent to the nonparametric nature of kernel-based estimators are computational and memory requirements that become prohibitive with large-scale datasets. In response to this formidable challenge, the present work puts forward a low-rank, kernel-based, feature extraction approach that is particularly tailored for online operation, where data streams need not be stored in memory. A novel generative model is introduced to approximate high-dimensional (possibly infinite) features via a low-rank nonlinear subspace, the learning of which leads to a direct kernel function approximation. Offline and online solvers are developed for the subspace learning task, along with affordable versions, in which the number of stored data vectors is confined to a predefined budget. Analytical results provide performance bounds on how well the kernel matrix as well as kernel-based classification and regression tasks can be approximated by leveraging budgeted online subspace learning and feature extraction schemes. Tests on synthetic and real datasets demonstrate and benchmark the efficiency of the proposed method when linear classification and regression is applied to the extracted features.
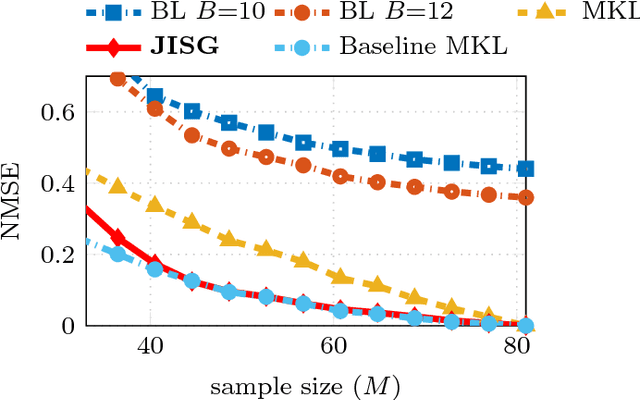
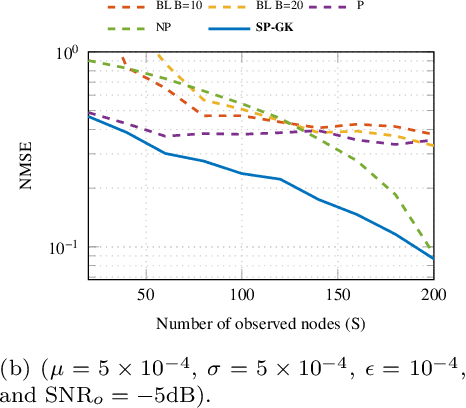
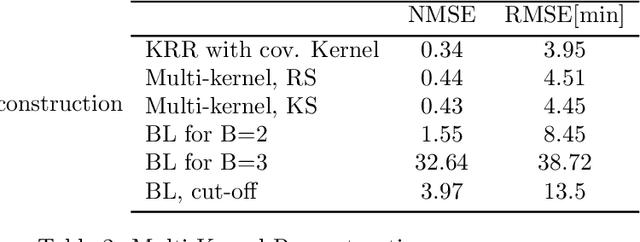
Inference of Spatio-Temporal Functions over Graphs via Multi-Kernel Kriged Kalman Filtering
Nov 25, 2017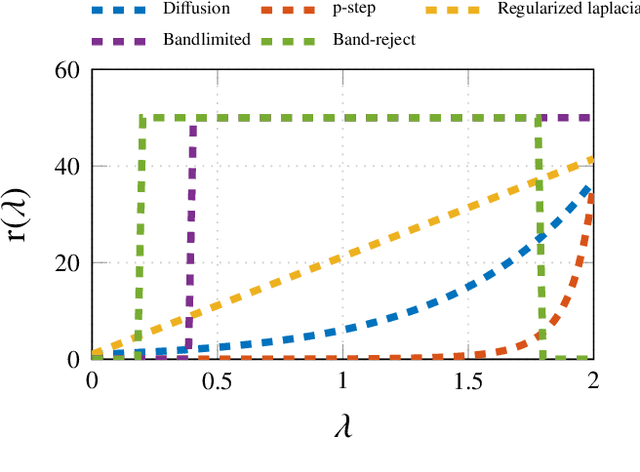
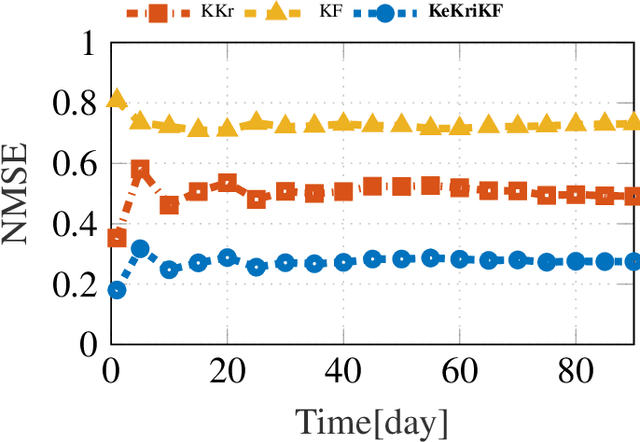
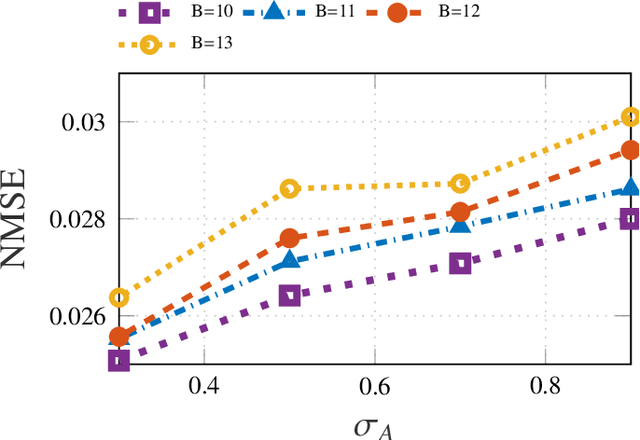
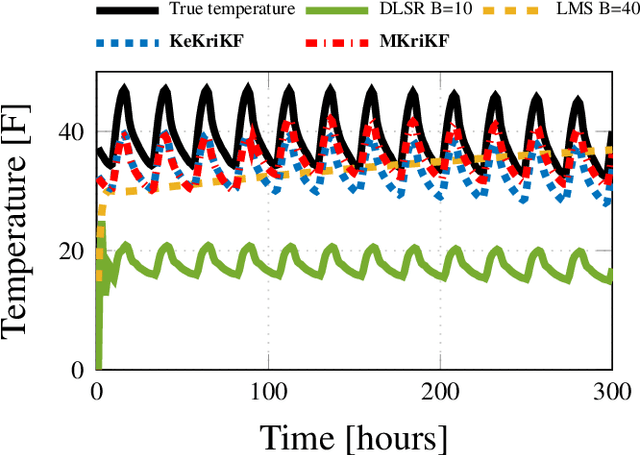
Inference of space-time varying signals on graphs emerges naturally in a plethora of network science related applications. A frequently encountered challenge pertains to reconstructing such dynamic processes, given their values over a subset of vertices and time instants. The present paper develops a graph-aware kernel-based kriged Kalman filter that accounts for the spatio-temporal variations, and offers efficient online reconstruction, even for dynamically evolving network topologies. The kernel-based learning framework bypasses the need for statistical information by capitalizing on the smoothness that graph signals exhibit with respect to the underlying graph. To address the challenge of selecting the appropriate kernel, the proposed filter is combined with a multi-kernel selection module. Such a data-driven method selects a kernel attuned to the signal dynamics on-the-fly within the linear span of a pre-selected dictionary. The novel multi-kernel learning algorithm exploits the eigenstructure of Laplacian kernel matrices to reduce computational complexity. Numerical tests with synthetic and real data demonstrate the superior reconstruction performance of the novel approach relative to state-of-the-art alternatives.